原文:Understanding Black-box Predictions via
Influence Functions
目标:训练数据的某一个数据改变,预测结果会有怎样的变化(影响)?
设:input space X X X,output space Y Y Y, 训练集: z i = ( x i , y i ) ∈ X × Y , i = 1 , 2 , … , n z_i =(x_i,y_i) \in X \times Y,i=1,2,\dots,n zi=(xi,yi)∈X×Y,i=1,2,…,n;对于一个点 z z z以及模型参数 θ ∈ Φ , L ( z , θ ) \theta \in \Phi,L(z,\theta) θ∈Φ,L(z,θ)为损失函数。最小化经验函数为:
θ ^ = arg min θ ∈ Φ 1 n ∑ i = 1 n L ( z i , θ ) (1) \hat{\theta}=\arg \min_{\theta \in \Phi} \frac{1}{n} \sum_{i=1}^{n}L(z_i,\theta) \tag 1 θ^=argθ∈Φminn1i=1∑nL(zi,θ)(1)
再理一遍目标:某一个数据变化,即 z z z变化,可以视为 z z z从有到无,预测结果发生的变化;换句话说:训练时, z z z从有到无,导致模型参数 θ ^ \hat{\theta} θ^发生变化,从而引起预测结果的变化,如何衡量影响的大小?(求导)
模型参数的变化: θ ^ − z − θ ^ \hat{\theta}_{-z}-\hat{\theta} θ^−z−θ^;(移除 z z z的参数减去未移除时的参数)
其中: θ ^ − z = arg min θ ∈ Φ 1 n ∑ i = 1 , z i ≠ z n L ( z i , θ ) (2) \hat{\theta}_{-z}=\arg \min_{\theta \in \Phi} \frac{1}{n} \sum_{i=1,z_i \neq z}^{n}L(z_i,\theta) \tag 2 θ^−z=argθ∈Φminn1i=1,zi=z∑nL(zi,θ)(2)
问题1:原文作者写法(下面截图)与上式不一致,不知道是不是我没有深刻理解作者的思路,还是作者有意为之,那作者为何不要求平均了呢?按照最小化经验函数是需要求平均啊,emmm…所以应该怎样理解?
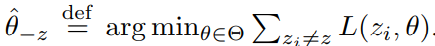
继续换个思路: n n n个 z z z,一个一个移除观察参数的变化,太慢了,根据influence function:可以在 z z z上加一个小小的权重 ϵ \epsilon ϵ来计算参数的变化.更神奇的是,移除 z z z相当于加权 ϵ = − 1 n \epsilon=-\frac{1}{n} ϵ=−n1.
加权后的参数定义为: θ ^ ϵ , z = arg min θ ∈ Φ 1 n ∑ i = 1 n L ( z i , θ ) + ϵ L ( z , θ ) (3) \hat{\theta}_{\epsilon,z}=\arg \min_{\theta \in \Phi}\frac{1}{n}\sum_{i=1}^{n}L(z_i,\theta)+\epsilon L(z,\theta) \tag 3 θ^ϵ,z=argθ∈Φminn1i=1∑nL(zi,θ)+ϵL(z,θ)(3)
对 z z z加权后,对模型参数 θ ^ \hat{\theta} θ^的影响(梯度)定义为:
I u p , p a r a m s ( z ) = d θ ^ ϵ , z d ϵ ∣ ϵ = 0 = − H θ ^ − 1 ∇ θ L ( z , θ ^ ) (4) I_{\mathrm{up,params}}(z)=\frac{\mathrm{d}\hat{\theta}_{\epsilon,z}}{\mathrm{d}\epsilon}\vert _{\epsilon=0}=-\mathbf{H}^{-1}_{\hat{\theta}}\nabla_{\theta}L(z,\hat \theta) \tag 4 Iup,params(z)=dϵdθ^ϵ,z∣ϵ=0=−Hθ^−1∇θL(z,θ^)(4)
其中: H θ ^ = 1 n ∑ i = 1 n ∇ θ 2 L ( z i , θ ^ ) \mathbf{H}_{\hat \theta}=\frac{1}{n}\sum_{i=1}^{n}\nabla^2_{\theta} L(z_i, \hat \theta) Hθ^=n1∑i=1n∇θ2L(zi,θ^)为正定海瑟矩阵.
问题2:用 ϵ \epsilon ϵ对 z z z加权重,为什么加在loss上?
问题3:为什么式子 ( 3 ) (3) (3)对 ϵ \epsilon ϵ求导得到式子 ( 4 ) (4) (4)的结果?原文表示是根据经典的结果,引用是一本书,所以还没有深入探究结果的由来。
问题4: 根据牛顿法 x ( k + 1 ) = x ( k ) + α k d k x^{(k+1)}=x^{(k)}+\alpha_k d_k x(k+1)=x(k)+αkdk,下降方向 d k = − H k − 1 g k , α k = 1 d_{k}=-H_k^{-1}g_k,\alpha_k=1 dk=−Hk−1gk,αk=1,其中 d k d_{k} dk为第k步的方向, H k H_k Hk为函数的第k步海瑟矩阵, g k g_k gk为函数的第k步梯度, α k \alpha_k αk为第k步步长。表达式含义:根据第k步的位置 x ( k ) x^{(k)} x(k),往方向 d k d_k dk移动步长 α k = 1 \alpha_k=1 αk=1为距离得到下一步的迭代点 x ( k + 1 ) x^{(k+1)} x(k+1);
将牛顿法的下降方向与 I u p , p a r a m s ( z ) I_{\mathrm{up,params}}(z) Iup,params(z)类比,即 I u p , p a r a m s ( z ) I_{\mathrm{up,params}}(z) Iup,params(z)为在 θ ^ \hat \theta θ^附近二次逼近经验风险函数,且步长为1.
原文也说明了是经验风险函数的二次逼近且步长为1,虽然论文说有附录证明,但是论文中并没有找到证明的附录,所以以上是我个人的理解。
移除 z z z相当于加权 ϵ = − 1 n \epsilon=-\frac{1}{n} ϵ=−n1,即当 ϵ = − 1 n \epsilon=-\frac{1}{n} ϵ=−n1时,式子 ( 2 ) (2) (2)和 ( 3 ) (3) (3)相等,线性近似移除 z z z后的参数变化:
θ ^ − z − θ ^ ≈ − 1 n I u p , p a r a m s ( z ) (5) \hat \theta_{-z}-\hat \theta \approx -\frac{1}{n}I_{\mathrm{up,params}}(z) \tag 5 θ^−z−θ^≈−n1Iup,params(z)(5)
问题5:其实这一步没看懂,线性近似怎么就得到了式子 ( 5 ) (5) (5)呢?
补充: 如果式子 ( 2 ) (2) (2)所对应的原文截图是无歧义的,那么可否这样理解:
由: f ( x + Δ x ) − f ( x ) = Δ x ∇ f ( x ) f(x+\Delta x)-f(x)=\Delta x \nabla f(x) f(x+Δx)−f(x)=Δx∇f(x)
θ ^ − 1 n , z − θ ^ ≈ − 1 n I u p , p a r a m s ( z ) θ ^ − 1 n , z ≈ θ ^ − z θ ^ − z − θ ^ ≈ − 1 n I u p , p a r a m s ( z ) \begin{aligned}\hat \theta_{-\frac{1}{n},z}-\hat \theta &\approx -\frac{1}{n}I_{\mathrm{up,params}}(z)\\ \hat\theta_{-\frac{1}{n},z}& \approx \hat \theta_{-z}\\ \hat \theta_{-z}-\hat \theta &\approx -\frac{1}{n}I_{\mathrm{up,params}}(z)\end{aligned} θ^−n1,z−θ^θ^−n1,zθ^−z−θ^≈−n1Iup,params(z)≈θ^−z≈−n1Iup,params(z)
似乎这样的理解是错误的(勿看)
在对 z z z加权训练后,对于测试集中的某一个 z t e s t z_{\mathrm{test}} ztest有什么变化呢?即求导:
I u p , l o s s ( z , z t e s t ) = d L ( z t e s t , θ ^ ϵ , z ) d ϵ ∣ ϵ = 0 = ∇ θ L ( z t e s t , θ ^ ) T d θ ^ ϵ , z d ϵ ∣ ϵ = 0 = − ∇ θ L ( z t e s t , θ ^ ) T H θ ^ − 1 ∇ θ L ( z , θ ^ ) (6) \begin{aligned}I_{\mathrm{up,loss(z,z_{test})}} &=\frac{\mathrm{d}L(z_{\mathrm{test}},\hat \theta_{\epsilon,z})}{\mathrm{d}\epsilon} \vert_{\epsilon=0} \\ &=\nabla_{\theta}L(z_{\mathrm{test},\hat \theta})^{\mathrm{T}} \frac{\mathrm{d}\hat \theta_{\epsilon,z}}{\mathrm{d}\epsilon}\vert_{\epsilon=0} \\ &=- \nabla_{\theta}L(z_{\mathrm{test},\hat \theta})^{\mathrm{T}}\mathbf{H}^{-1}_{\hat{\theta}}\nabla_{\theta}L(z,\hat \theta) \tag 6\end{aligned} Iup,loss(z,ztest)=dϵdL(ztest,θ^ϵ,z)∣ϵ=0=∇θL(ztest,θ^)Tdϵdθ^ϵ,z∣ϵ=0=−∇θL(ztest,θ^)THθ^−1∇θL(z,θ^)(6)
那么,由于删去一个样本等同于权重增加 − 1 n -\frac{1}{n} −n1,因此,删除一个样本z后,模型在测试样本 z t e s t z_{\mathrm{test}} ztest上的loss会增加 − 1 n I u p , l o s s ( z , z t e s t ) -\frac{1}{n}I_{\mathrm{up,loss(z,z_{test})}} −n1Iup,loss(z,ztest).
以上都是铺垫,下面才是主题:
个人理解:对某个点 z z z添加扰动 δ \delta δ: z = ( x , y ) → z δ = ( x + δ , y ) , z=(x,y)\rightarrow z_{\delta}=(x+\delta,y), z=(x,y)→zδ=(x+δ,y),找到此扰动对测试集的某个点 z t e s t z_{\mathrm{test}} ztest的影响,如果影响大,则 z z z的改变对数据来说很敏感,对于APT那篇paper来说,希望找到的是EMR用户("正向"用户,是不敏感的数据)来通过对抗性训练达到增强推荐系统鲁棒性的作用
δ \delta δ从无到有,参数变成了: θ ^ z δ , − z \hat \theta_{z_\delta,-z} θ^zδ,−z;
移除 δ \delta δ或者增加 δ \delta δ相当于对它加权:
θ ^ ϵ , z δ , − z = arg min θ ∈ Φ 1 n ∑ i = 1 n L ( z i , θ ) + ϵ L ( z δ , θ ) − ϵ L ( z , θ ) (7) \hat \theta_{\epsilon,z_{\delta},-z}=\arg \min_{\theta \in \Phi}\frac{1}{n}\sum_{i=1}^{n}L(z_i,\theta)+\epsilon L(z_{\delta,\theta})-\epsilon L(z,\theta) \tag 7 θ^ϵ,zδ,−z=argθ∈Φminn1i=1∑nL(zi,θ)+ϵL(zδ,θ)−ϵL(z,θ)(7)
由式子(4)的形式得:
I = d θ ^ ϵ , z δ , − z d ϵ ∣ ϵ = 0 = − H θ ^ − 1 ( ∇ θ L ( z δ , θ ^ ) − ∇ θ L ( z , θ ^ ) ) (8) I=\frac{\mathrm{d}\hat \theta_{\epsilon,z_{\delta},-z}}{\mathrm{d}\epsilon}\vert_{\epsilon=0}=-\mathbf{H}_{\hat \theta}^{-1}(\nabla_\theta L(z_{\delta},\hat \theta)-\nabla_\theta L(z,\hat \theta)) \tag 8 I=dϵdθ^ϵ,zδ,−z∣ϵ=0=−Hθ^−1(∇θL(zδ,θ^)−∇θL(z,θ^))(8)
设 x ∈ R d x \in \mathbb{R}^d x∈Rd,由于 ∥ δ ∥ → 0 \| \delta\| \rightarrow 0 ∥δ∥→0,故 ∇ θ L ( z δ , θ ^ ) − ∇ θ L ( z , θ ^ ) ≈ ∇ x ∇ θ L ( z , θ ^ ) δ \nabla_\theta L(z_{\delta},\hat \theta)-\nabla_\theta L(z,\hat \theta) \approx \nabla_x \nabla_{\theta }L(z,\hat \theta)\delta ∇θL(zδ,θ^)−∇θL(z,θ^)≈∇x∇θL(z,θ^)δ
得式子 ( 8 ) (8) (8)为:
d θ ^ ϵ , z δ , − z d ϵ ∣ ϵ = 0 = I u p , p a r a m s ( z δ ) − I u p , p a r a m s ( z ) = − H θ ^ − 1 ∇ x ∇ θ L ( z , θ ^ ) δ (9) \frac{\mathrm{d}\hat \theta_{\epsilon,z_{\delta},-z}}{\mathrm{d}\epsilon}\vert_{\epsilon=0}=I_{\mathrm{up,params}}(z_\delta)-I_{\mathrm{up,params}}(z)=-\mathbf{H}_{\hat \theta}^{-1}\nabla_x \nabla_{\theta }L(z,\hat \theta)\delta \tag 9 dϵdθ^ϵ,zδ,−z∣ϵ=0=Iup,params(zδ)−Iup,params(z)=−Hθ^−1∇x∇θL(z,θ^)δ(9)
根据式子 ( 5 ) (5) (5)同理得:
θ ^ ϵ , z δ , − z − θ ^ ≈ − 1 n ( H θ ^ − 1 ∇ x ∇ θ L ( z , θ ^ ) δ \hat \theta_{\epsilon,z_{\delta},-z}-\hat \theta \approx -\frac{1}{n}(\mathbf{H}_{\hat \theta}^{-1}\nabla_x \nabla_{\theta }L(z,\hat \theta)\delta θ^ϵ,zδ,−z−θ^≈−n1(Hθ^−1∇x∇θL(z,θ^)δ
由式子 ( 6 ) (6) (6)同理可得:
I p e r t , l o s s ( z , z t e s t ) T = ∇ δ L ( z t e s t , θ ^ z δ , − z ) T ∣ δ = 0 = − ∇ θ L ( z t e s t , θ ^ ) T H θ ^ − 1 ∇ x ∇ θ L ( z , θ ^ ) \begin{aligned}I_{\mathrm{pert,loss}}(z,z_{\mathrm{test}})^{\mathrm{T}}&=\nabla_\delta L(z_{\mathrm{test}},\hat \theta_{z_\delta,-z})^{\mathrm{T}} \vert _{\delta=0} \\ &=-\nabla_{\theta}L(z_{\mathrm{test}},\hat \theta)^{\mathrm{T}}\mathbf{H}_{\hat \theta}^{-1}\nabla_x \nabla_{\theta }L(z,\hat \theta)\end{aligned} Ipert,loss(z,ztest)T=∇δL(ztest,θ^zδ,−z)T∣δ=0=−∇θL(ztest,θ^)THθ^−1∇x∇θL(z,θ^)
由此可得结论:
- 当 z → z δ z \rightarrow z_\delta z→zδ时,对 z t e s t z_{\mathrm{test}} ztest的影响近似为 I p e r t , l o s s ( z , z t e s t ) T δ ; I_{\mathrm{pert,loss}}(z,z_{\mathrm{test}})^{\mathrm{T}}\delta; Ipert,loss(z,ztest)Tδ;
- 如果设置 δ \delta δ的方向为 I p e r t , l o s s ( z , z t e s t ) I_{\mathrm{pert,loss}}(z,z_{\mathrm{test}}) Ipert,loss(z,ztest)时,得到在 z t e s t z_{\mathrm{test}} ztest的损失最大.