1. 整体思路流程
- 通过URL获取说要爬取的页面的响应信息(Requests库的使用)
- 通过python中的解析库来对response进行结构化解析(BeautifulSoup库的使用)
- 通过对解析库的使用和对所需要的信息的定位从response中获取需要的数据(selecter和xpath的使用)
- 将数据组织成一定的格式进行保存(MongoDB的使用)
- 通过对数据库中的数据进行筛选和组织,进行数据可视化的初步展示(HighCharts库的使用)
2. 简单代码演示
1. 准备工作
下载并安装所需要的python库,包括:
requests库:用于向指定url发起请求
BeautifulSoup库:用于解析返回的网页信息
lxml库:用于解析网页返回结果
pymongo库:用于实现python对MongoDB的操作
HighCharts库:对于数据进行初步可视化的展示
所有以上的库都直接可以使用pip命令进行下载
2. 对所需要的网页进行请求并解析返回的数据
对于想要做一个简单的爬虫而言,这一步其实很简单,主要是通过requests库来进行请求,然后对返回的数据进行一个解析,解析之后通过对于元素的定位和选择来获取所需要的数据元素,进而获取到数据的一个过程。
一个简单的网络爬虫示例
import requests
from bs4 import BeautifulSoup
#58同城的二手市场主页面
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
#定义一个爬虫函数来获取二手市场页面中的全部大类页面的连接
def get_channel_urls(url):
#使用Requests库来进行一次请求
web_data = requests.get(url)
#使用BeautifulSoup对获取到的页面进行解析
soup = BeautifulSoup(web_data.text, 'lxml')
#根据页面内的定位信息获取到全部大类所对应的连接
urls = soup.select('ul.ym-submnu > li > b > a')
#作这两行处理是因为有的标签有链接,但是却是空内容
for link in urls:
if link.text.isspace():
continue
else:
page_url = url_host + link.get('href')
print(page_url)对于定位页面中所需标签位置的方法有很多种,可以自己根据页面的情况多进行尝试。
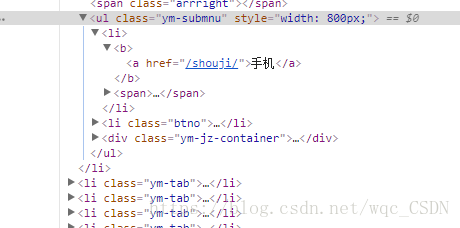
可以看到所有的大类链接都位于ul标签 > li标签 > b标签 > a标签
故此我们可以使用上边代码中的方式来获取全部的大类标签
注 : 在进行标签定位时 ‘>’ 符号表示上一个标签的严格的子标签,而‘空格’ 符号表示上一个标签的子标签或者子孙标签
例如:
对于ul.ym-submnu > li而言,表示class属性为ym-submnu的ul标签的子标签li,则选出来的li只能是ul.ym-submnu的子标签
若是ul.ym-submnu li而言,表示class属性为ym-submnu的ul标签的子孙标签,即选出来的li可能是ul.ym-submnu的子标签或者子孙标签
爬取结果部分截图
以上就是一个简单的网页爬虫的制作过程,我们可以通过定义不同的爬虫来实现爬取不同页面的信息,并通过程序的控制来实现一个自动化爬虫。
3. 对爬取到的数据进行存储和初步的可视化显示
python中用于数据的可视化显示的库有很多,我们可以根据需要来选择不同的库。数据的存储推荐使用MongoDB的方式,比起Mysql来说有很大的便利性,更适合大规模的数据整理。数据的可视化使用了HighCharts,可以直接在网页上显示出数据结果。
关于MongoDB数据库的入门使用可以参看这篇博文—–MongoDB入门及问题总结
关于HighCharts的使用可以参看其官网HighCharts官网使用文档
首先:在程序中创建一个MongoDB的连接用于存储数据
client = pymongo.MongoClient('localhost', 27017)#链接MongoDB
DB_58 = client['DB_58']#创建一个数据库
url_list_tab = DB_58['url_list_tab']#创建用于存储全部商品url的文档
item_detail_tab = DB_58['item_detail_tab']#创建用于存储商品详情的文档然后:通过之前获取到的每个分类的链接,来爬取该分类下的全部的商品链接
# 从每个频道获取全部的商品链接
def get_liks_from(channel, pages, who_sells=0):
# http://bj.58.com/diannao/0/pn5/
list_view = '{}{}/pn{}/'.format(channel, str(who_sells), str(pages))
web_data = requests.get(list_view)
time.sleep(2)
soup = BeautifulSoup(web_data.text, 'lxml')
#爬取个人商家列表
if soup.find('td','t'):
for link in soup.select('.zzinfo > td.t > a.t'):
item_link = link.get('href').split('?')[0]
#去除掉跳转类型的连接
if item_link != 'http://jump.zhineng.58.com/jump':
#得到想要的商品页面链接之后保存在数据库中
url_list_tab.insert_one({'url': item_link})
print(item_link)
else:
pass
#爬取店铺商家列表
if soup.find('div','left'):
for link in soup.select('a.title'):
item_link = link.get('href')
#去除掉跳转类型的连接
if item_link != 'http://jump.zhineng.58.com/jump':
#得到想要的商品页面链接之后保存在数据库中
url_list_tab.insert_one({'url': item_link})
print(item_link)
else:
pass
由于58个人卖家的二手信息会跳转到转转这个平台,所以需要根据页面中的标签来判断是那种类型的页面
第三步:在获取到全部的商品的url之后需要对商品的详情进行爬取,同时保存在数据库中
# 爬取商品详情页的信息
def get_item_info(url):
if 'short.58.com' not in url:
#加一个延时,爬取太快58会出来验证码
time.sleep(1)
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
# 根据页面中的独特元素来辨别是哪个版本的网页
if soup.find('span', 'want_left'):
parse_person_item_info(soup)
else:
parse_shop_item_info(soup)
else:
print('error with url : '+url)
# 解析个人卖家的商品详情
def parse_person_item_info(soup):
item_detail_tab.insert_one({
'title': soup.select('h1.info_titile')[0].text,
'price': soup.select('span.price_now > i')[0].text,
'area': soup.select('div.palce_li > span > i ')[0].text,
})
# 解析商家的商品详情
def parse_shop_item_info(soup):
item_detail_tab.insert_one({
'title': (soup.title.text).split('-')[0],
'price': soup.select('div.su_con > span.price')[0].text,
'area': list(soup.select('.c_25d')[-1].stripped_strings),
})至此,我们所需要的数据就算是获取完毕,接下来我们需要做的就是根据需要来将数据进行整理,然后通过图表的方式来展示数据中包含的信息。
第四步:这一步需要使用Highcharts来进行数据的展示,推荐使用Jupyter Notebook来进行操作,他可以直接将数据展示在网页上,极大地方便了数据查看。
Jupyter Notebook的安装和使用也很方便,网上也有很多的使用教程,直接附上其官网地址Jupyter NoteBook官网大家可以去查看
首先要获取商品的一个地区列表
#首先获取数据库中的全部地区
area_list = []
for i in item_detail_tab.find():
area_list.append(i['area'][0])
#将全部地区放入set中进行去重,这样就得到一个全部地区的列表
area_index = list(set(area_list))然后就是根据地区列表来统计每个地区的二手商品的数量(以发布商品的帖子数为记)
#统计每个地区的发帖数量
post_times = []
for index in area_index:
post_times.append(area_list.count(index))此时我们已经获取了商品的地区列表以及每个地区所对应的商品数量,需要做的就是将数据构造成Highcharts所要求的格式并进行展示
#定义一个迭代器函数来构造Highcharts所需要的数据格式
def data_gen(types):
length = 0
if length <= len(area_index):
for area,times in zip(area_index,post_times):
data = {
'name':area,
'data':[times],
'type':types
}
yield data
length += 1#将构造好的数据放入charts中进行展示
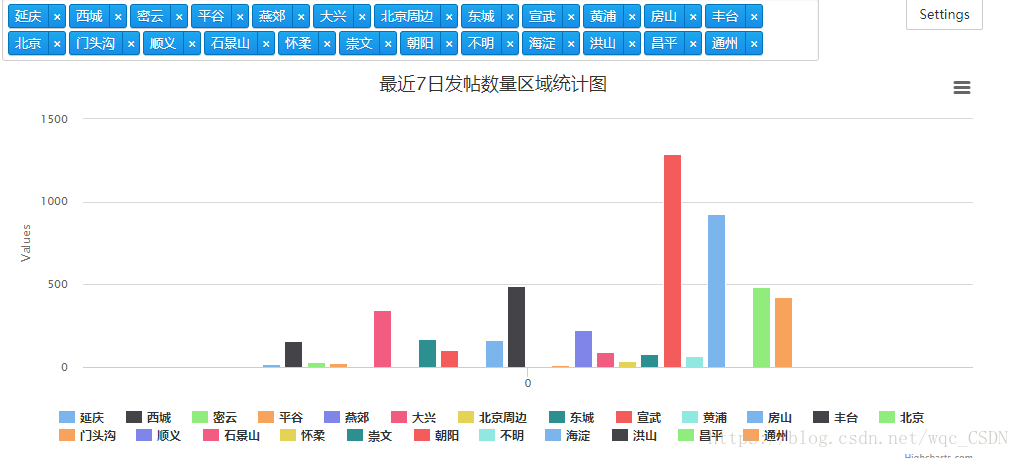
seroes = [data for data in data_gen('column')]
charts.plot(seroes,show='inline',options=dict(title=dict(text='最近7日发帖数量区域统计图')))至此我们就做了一个简易的爬虫来获取了一定的数据,并将结果进行了可视化的展示。
3. 总结回顾
简单的总结一下在这个爬虫中我们所学到的一些东西:
- 使用requests库进行网络请求
- 使用BeautifulSoup解析库对网页数据进行解析
- 学习如何通过selecter的方式选择网页中需要的元素
- 使用MongoDB进行数据的存储和读取
- 使用HighCharts对数据进行可视化的展示