相信大家在跑爬虫的过程中,也会好奇自己养的爬虫一分钟可以爬多少页面,多大的数据量,当然查询的方式多种多样。今天我来讲一种可视化的方法。
1.成品图
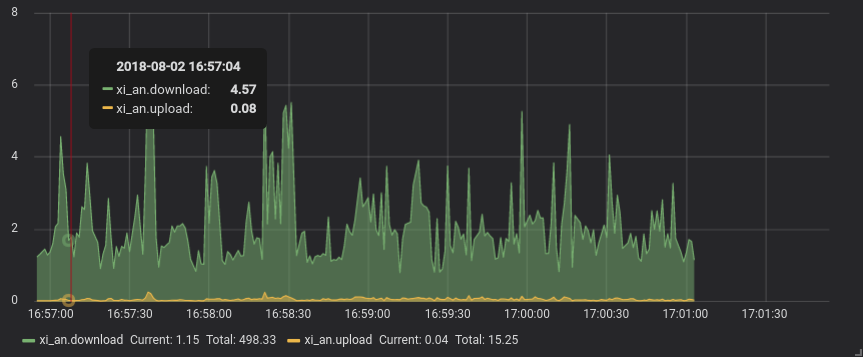
这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为M。爬虫的原理都是一样的,只不过将数据存到InfluxDB的方式不一样而已, 如下图。

可以实现对爬虫数量,增量,大小,大小增量的实时监控。
2. 环境
- InfluxDb,是目前比较流行的时间序列数据库;
- Grafana,一个可视化面板(Dashboard),有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源
- Ubuntu
- influxdb(pip install influxdb)
- Python 2.7
3. 原理
获取要展示的数据,包含当前的时间数据,存到InfluxDb里面,然后再到Grafana里面进行相应的配置即可展示;
想要学习Python?Python学习交流群:1004391443满足你的需求,资料都已经上传群文件,可以自行下载!
4. 安装
4.1 Grafana安装
安装好以后,打开本地的3000端口,即可进入管理界面,用户名与密码都是admin。
4.2 InfulxDb安装
这个安装就网上自己找吧,有很多的配置我都没有配置,就不在这里误人子弟了。
5. InfluxDb简单操作
碰到了数据库,肯定要把增删改查学会了啊, 和sql几乎一样,只有一丝丝的区别,具体操作,大家可以参考官方的文档。
- influx 进入命令行
- CREATE DATABASE test 创建数据库
- show databases 查看数据库
- use test 使用数据库
- show series 看表
- select * from table_test 选择数据
- DROP MEASUREMENT table_test 删表
6. 存数据
InfluxDb数据库的数据有一定的格式,因为我都是利用python库进行相关操作,所以下面将在python中的格式展示一下:
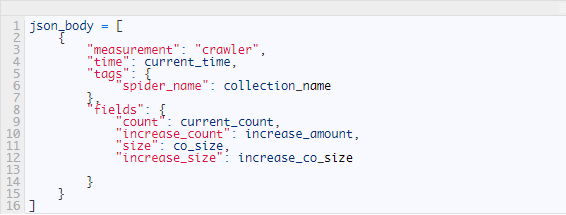
其中:
- measurement, 表名
- time,时间
- tags,标签
- fields,字段
可以看到,就是个列表里面,嵌套了一个字典。 下面是python实现方法:

所以,到这里,如何将爬虫的相关属性存进去呢?以MongoDB为例
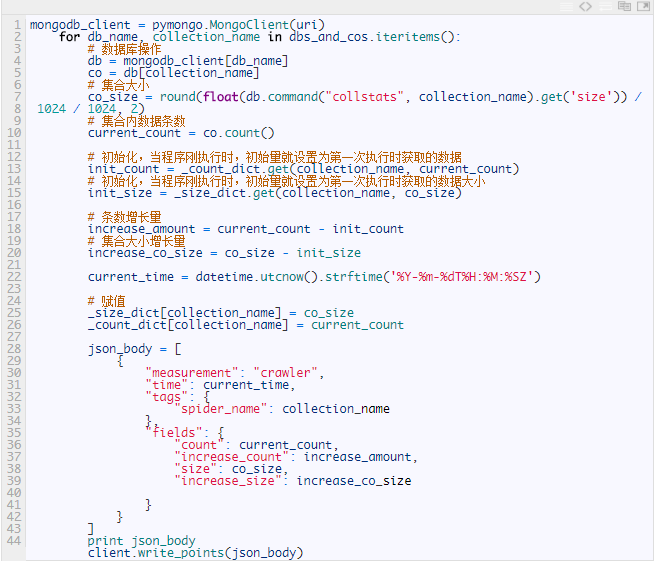
那么现在我们已经往数据里存了数据了,那么接下来要做的就是把存的数据展示出来。
如果你在学习Python的过程当中有遇见任何问题,可以加入我的python交流学习秋秋qun:九三四、一零九、一七零,多多交流问题,互帮互助,群里有不错的学习教程和开发工具。学习python有任何问题(学习方法,学习效率,如何就业),可以随时来咨询我
7.展示数据
7.1 配置数据源
以admin登录到Grafana的后台后,我们首先需要配置一下数据源。点击左边栏的最下面的按钮,然后点击DATA SOURCES,这样就可以进入下面的页面:

点击ADD DATA SOURCE,进行配置即可,如下图:

其中,name自行设定;Type 选择InfluxDB;url为默认的http://localhost:8086, 其他的因为我前面没有进行配置,所以默认的即可。然后在InfluxDB Details里的填入Database名,最后点击测试,如果没有报错的话,则可以进入下一步的展示数据了;
7.2 展示数据
点击左边栏的+号,然后点击GRAPH

接着点击下图中的edit进入编辑页面:


从上图中可以发现:
- 中间板块是最后的数据展示
- 下面是数据的设置项
- 右上角是展示时间的设置板块,在这里可以选择要展示多久的数据
7.2.1 配置数据
- 在Data Source中选择刚刚在配置数据源的时候配置的NAME字段,而不是database名。
- 接着在下面选择要展示的数据。看着就很熟悉是不是,完全是sql语句的可视化。同时,当我们的数据放到相关的字段上的时候,双击,就会把可以选择的项展示出来了,我们要做的就是直接选择即可;
- 设置右上角的时间,则可以让数据实时进行更新与展示
因为下面的配置实质就是sql查询语句,所以大家按照自己的需求,进行选择配置即可,当配置完以后,就可以在中间的面板里面看到数据了。