1.PPOCRLabel 标注工具
官方文档:
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.3/PPOCRLabel/README_ch.md
1.1.安装pyqt5
本地whl下载路径 https://pypi.tuna.tsinghua.edu.cn/simple/pyqt5/
1.2.安装本地文件
pip install E:\PaddleOcr\whl\PyQt5-5.15.6-cp36-abi3-win_amd64.whl
1.3.执行命令
切换到Paddle ocr 的PPOCRLabel目录 cd PPOCRLabel
python PPOCRLabel.py --lang ch 打开工具
1.4.工具执行步骤
1.安装与运行:使用上述命令安装与运行程序。
2.打开文件夹:在菜单栏点击 “文件” - “打开目录” 选择待标记图片的文件夹[1].
3.自动标注:点击 ”自动标注“,使用PPOCR超轻量模型对图片文件名前图片状态[2]为 “X” 的图片进行自动标注。
4.手动标注:点击 “矩形标注”(推荐直接在英文模式下点击键盘中的 “W”),用户可对当前图片中模型未检出的部分进行手动绘制标记框。点击键盘Q,则使用四点标注模式(或点击“编辑” - “四点标注”),用户依次点击4个点后,双击左键表示标注完成。
5.标记框绘制完成后,用户点击 “确认”,检测框会先被预分配一个 “待识别” 标签。
6.重新识别:将图片中的所有检测画绘制/调整完成后,点击 “重新识别”,PPOCR模型会对当前图片中的所有检测框重新识别[3]。
7.内容更改:双击识别结果,对不准确的识别结果进行手动更改。
8.确认标记:点击 “确认”,图片状态切换为 “√”,跳转至下一张(此时不会直接将结果写入文件)。
9.删除:点击 “删除图像”,图片将会被删除至回收站。
10.保存结果:用户可以通过菜单中“文件-保存标记结果”手动保存,同时程序也会在用户每确认5张图片后自动保存一次。手动确认过的标记将会被存放在所打开图片文件夹下的Label.txt中。在菜单栏点击 “文件” - "保存识别结果"后,会将此类图片的识别训练数据保存在crop_img文件夹下,识别标签保存在rec_gt.txt中[4]。
1.5.工具保存结果

1.6.工具快捷键
快捷键 说明
Ctrl + shift + R 对当前图片的所有标记重新识别
W 新建矩形框
Q 新建四点框
Ctrl + E 编辑所选框标签
Ctrl + R 重新识别所选标记
Ctrl + C 复制并粘贴选中的标记框
Ctrl + 鼠标左键 多选标记框
Backspace 删除所选框
Ctrl + V 确认本张图片标记
Ctrl + Shift + d 删除本张图片
D 下一张图片
A 上一张图片
Ctrl++ 缩小
Ctrl-- 放大
↑→↓← 移动标记框
2.准备数据字典
ppocr/utils/ppocr_keys_v1.txt 是一个包含6623个字符的中文字典
ppocr/utils/ic15_dict.txt 是一个包含36个字符的英文字典
ppocr/utils/dict/french_dict.txt 是一个包含118个字符的法文字典
ppocr/utils/dict/japan_dict.txt 是一个包含4399个字符的日文字典
ppocr/utils/dict/korean_dict.txt 是一个包含3636个字符的韩文字典
ppocr/utils/dict/german_dict.txt 是一个包含131个字符的德文字典
ppocr/utils/en_dict.txt 是一个包含96个字符的英文字典
用系统的字典或者自己写字典,配置在后面的配置文件的character_dict_path字段
3.下载训练模型
模型下载地址 :
https://gitee.com/paddlepaddle/PaddleOCR/blob/v2.1.1/doc/doc_ch/models_list.md
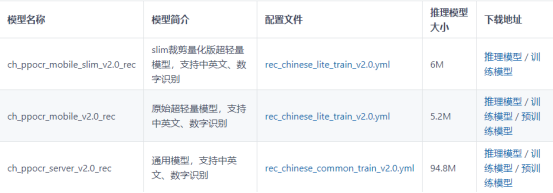
这里我选取 rec_chinese_lite_train_v2.0的预训练模型,
下载解压到pretrain_modles 目录下
Windows 下解压如果没有三个文件,需要把解压后的文件重新命名为zip再解压
像这种文件
4.修改配置
修改配置文件,ch_ppocr_mobile_v2.0_rec_pre.yml 在configs\rec\ch_ppocr_v2.0 下
use_gpu: False //True 代表使用gpu False 代表不使用gpu
character_dict_path: ./ppocr/utils/ppocr_keys_v1.txt //选取数据字典路径
use_space_char: True//空格
Train - data_dir : data_dir: ./train_data/ //训练集路径
Train : label_file_list: ["./train_data/rec_gt_train.txt"] 训练集标签文件路径
Eval : data_dir: ./train_data/ //测试集文件路径
EVal : label_file_list: ["./train_data/rec_gt_test.txt"] //测试集标签文件路
配置详解
https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.0/doc/doc_ch/config.md
5.开始训练
python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./pretrain_models/ch_ppocr_mobile_v2.0_rec_pre/best_accuracy
6.预测结果
python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.checkpoints=output/rec_chinese_lite_v2.0/best_accuracy Global.load_static_weights=false Global.infer_img=train_data/
注:如果没有best_accuracy 用 latest
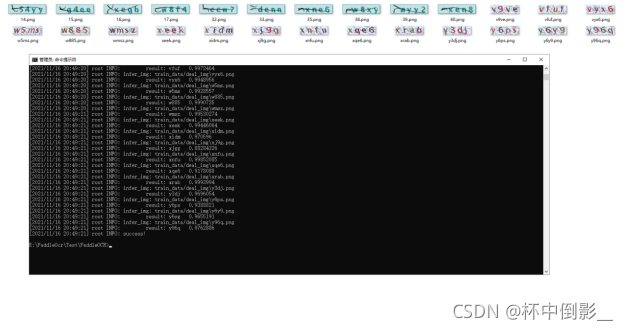
预测效果:
7.转化为推理模型
python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.checkpoints=output/rec_chinese_lite_v2.0/best_accuracy Global.save_inference_dir=output/inference
最终文件:
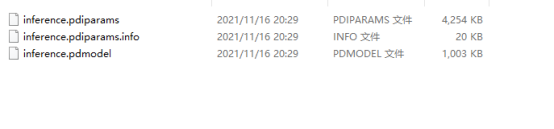
8.代码调用
9.遇到问题
9.1.Config use_gpu cannot be set as true while you are using paddlepaddle cpu version !
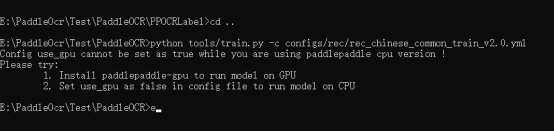
解决方案:修改rec_chinese_lite_train_v2.0.yml 的use_gpu 字段为false
9.2.No Images in train dataset, please ensure
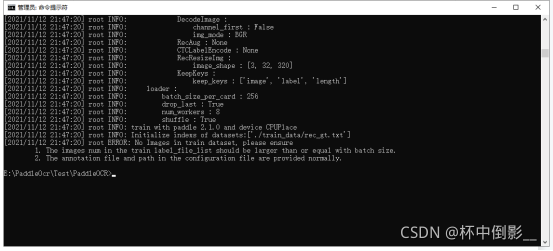
解决方案:1.标注工具识别结果没有内容, 2.修改batch_size_per_card字段