目录
四、MAML compared with pretrained-model
动机
介绍
一、What is meta-learning?
meta-learning元学习,又可以叫Learning to learn,是希望模型学会学习,但区别于迁移学习(Transfer Learning)。以往的模型学习指的是模型对具体的数据的学习,给定特定的数据,选好特定的算法,设置好超参数,开始训练,这样模型可以根据给定的数据去学习到输入和输出之间的映射关系,其实这是很手工很人为的操作。
举一个例子,比如你有猫狗分类的数据集。正常的训练过程为,选用一个模型(Resnet50)、设置好超参数(epoch,lr等等)、训练、得到一个解决任务的模型。

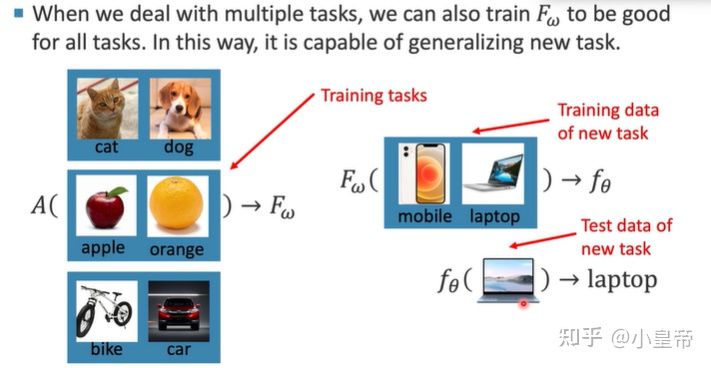
元学习希望将以上功能自动化,完成一个端到端的过程,自动选取合适的方法去学习获得最好的效果,简单来说,元学习获得好的结果是学出来的,而不是试、选出来的,元学习可以作为AutoML的一种手段。

还是上面实现猫狗分类的例子,将元学习会根据训练数据选取一个最合适的模型F,然后依据F来训练得到训练好的模型参数f。总结就是:在元学习中,训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。
接下来进一步学习多任务的元学习。
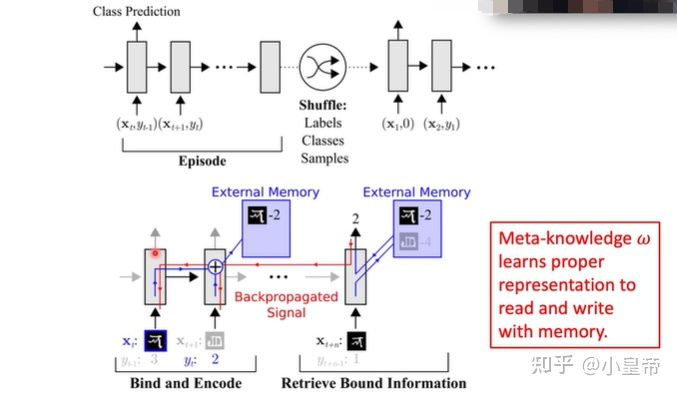
元学习是要去学习任务中的特征表示,从而在新的任务上泛化。
单任务和多任务的元学习区别:

二、meta-learning具体过程
传统的机器/深度学习流程:

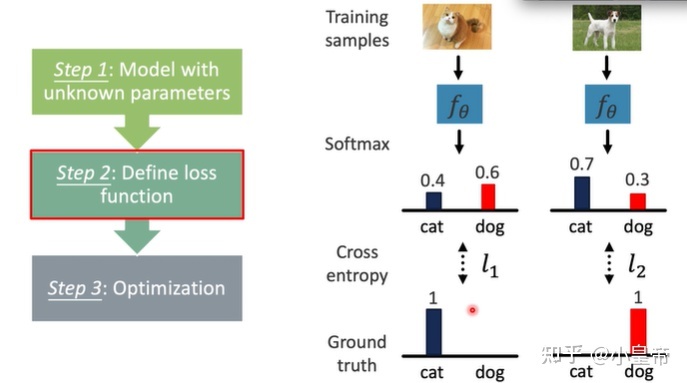

目标类别越策概率越大(与趋近于1),交叉熵损失越小。
元学习追求的不是在某一个特定任务上的效果好,而是追求任务的普遍,它希望学到的算法能够在新的任务上泛化效果好。
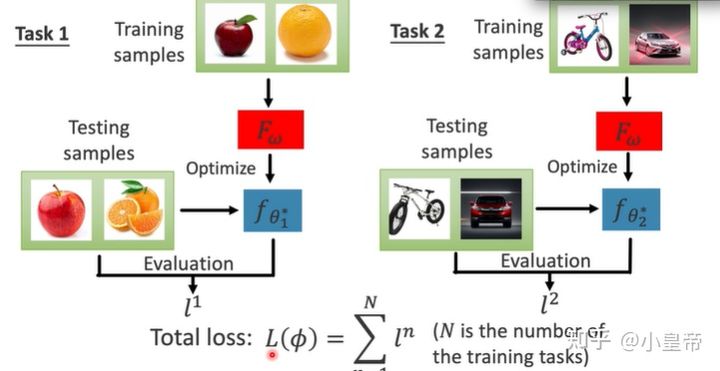
元学习是有一个个训练任务,通过这些相似的任务学习到一个模型F,在得到F的过程中,会使用测试数据对每一个元学习子任务进行评估,各个子任务的损失集合就是整个元学习的损失。

之前的机器/深度学习模型需要在训练数据上计算损失,来完成模型参数的修改,元学习是需要在测试数据上进行损失计算,来得到一个好的模型。实际中我们是并不知道测试集的标签的,因此这里的测试集实际上是训练数据的一部分,完成验证集的功能。


当你根据以往的训练任务,用元学习算法生成一个合适的模型F之后,对于一个新的任务(比如区分bike和car),用support set在F上训练几轮,然后在query set上看结果。
用公式表达上述过程:

三、meta-knowledge





不同的优化器就对应了不同的g函数,在元学习中,原学习知识指导模型选取g,而不是手动设定一个固定的g。这属于learning to optimize。

此外,也可以学习学习率的变化。这也属于learning to optimize。

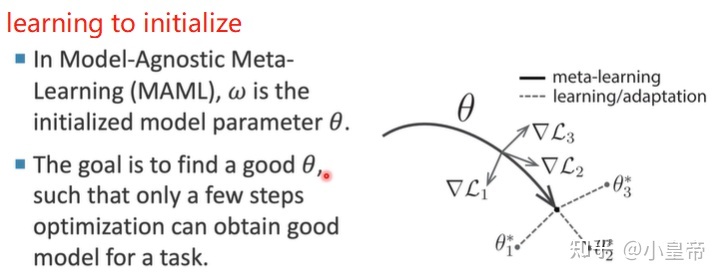

MAML(model-agnostic meta-learning)通过元学习知识来初始化模型,实现快速收敛,MAML是近几年元学习的典型代表方法。

给定一个初始化参数Q,各个元学习训练子任务用各自的support set去训练几轮,更新参数然后得到各自的QI,然后使用各自的query set在各自的QI上进行测试计算损失。用所有子任务的总损失去反向更新初始化参数Q。算法流程如下:

MAML的应用(小样本学习):
对于人而言,对于一个完全没见过的东西,给你看过几张图片之后,你大概就有能分辨这种物体的能力,这就是人具有元学习能力的一个例子。以往我们学习的时候死记硬背,这是不科学的方式,代表我们没有找到窍门,没有使用元学习的思想,元学习的内核是找到本质,有举一反三地能力。



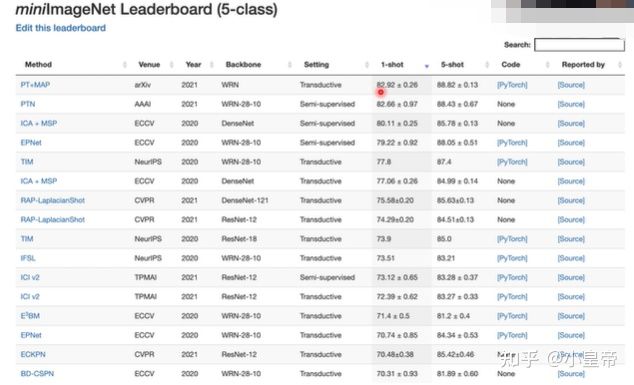
上图效果可以大致解释为,比如元学习方法用MAML,得到一个好的初始化参数,5-way 5-shot,也就是5类,每类用5张图片去finetune初始化参数,模型对这几类的识别精度能达到80%多。
四、MAML compared with pretrained-model
有人可能会问,使用元学习方法MAML得到一个好的初始化参数不就是和加载预训练模型参数一个意思吗?有什么区别呢?

两者的区别:
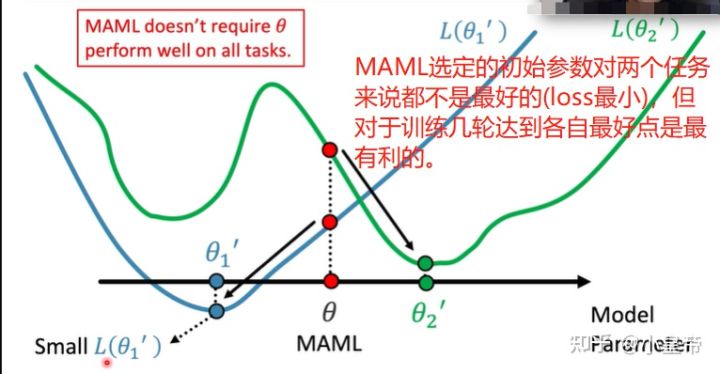
MAML不在乎目前的初始化参数效果如何,它关心的是在此之上训练一步之后的模型表现如何。pretrained model在乎的是在目前的任务上的表现,pretrained model给出的时候本身是没考虑后续的finetune的!也就是说平时用的加载imagenet上的预训练模型进行finetune这种操作只是因为了模型收敛更快。官方给的imagenet预训练参数本身的初衷是提供一个在imagenet上表现比较好的模型。因为很少人有能力去在imagenet上自己训练一个模型。

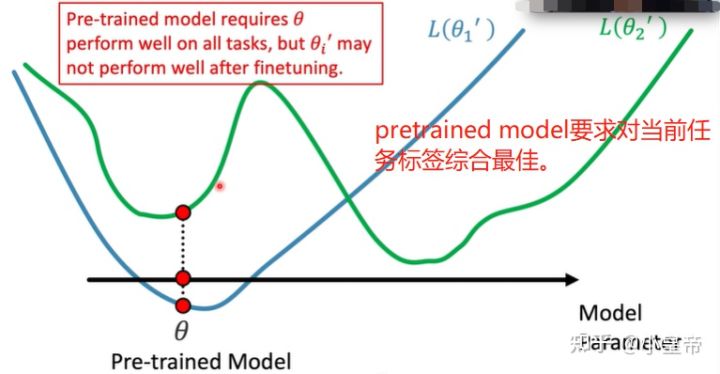
再具体一些解释,如果将MAML、pretrained model比作两个拳击教练。MAML他自己可以不能打不厉害,但要求他教出来的学生很厉害,而要求pretrained model自己很厉害很能打。
但不要将两者看得过于不同:
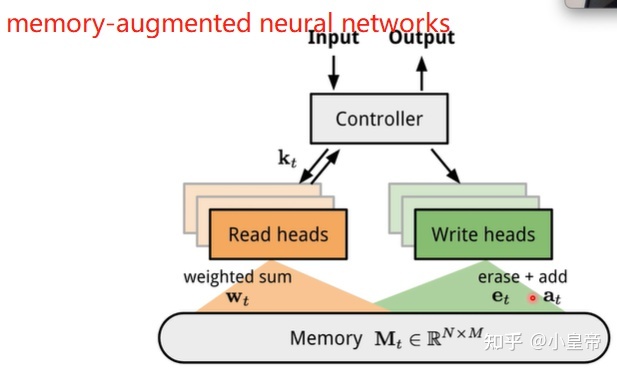
五、other meta-knowledge
1、learning to weight

Focal loss的损失公式其实就是对不同的样本的损失,给予不同的权重修饰,但是手工设计明显。损失加权可以利用元学习方法自动学习。可以加入一个多层感知机进行权重的学习。


2、learning to reward
使用不同的损失计算函数可能训练收敛的速度不同、训出来的模型效果不同。


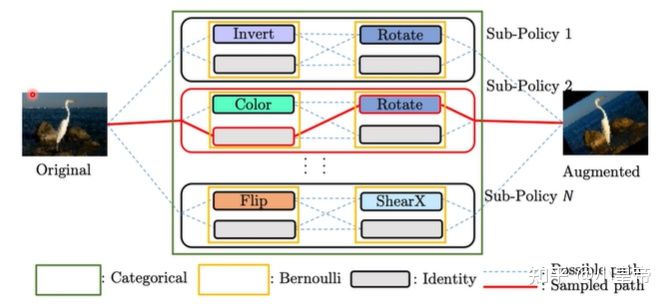
3、learning to augment

将数据增强的手段作为元知识去学习。

4、dataset distillation

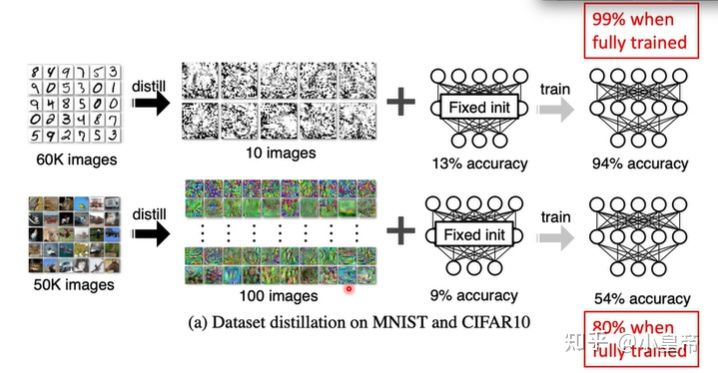

数据集蒸馏和MAML有些相似,都是使用较少的图片完成较好的效果,但是区别为:数据集蒸馏有用的信息包含在图片中,而MAML有用的信息包含在初始化参数里面。
(数据集蒸馏adversarial,进行poisoning的话,会不会少数的图片就attack很强?)
5、Neural architecture search


六、Model base method
以上主要介绍的是基于优化的元学习方式。它们本质上还是选取了模型参数(模型架构、优化方式、初始化参数、数据集蒸馏)之后,用梯度下降去对新的任务进行训练。