目录
R-GCN: Modeling Relational Data with GCN(2017)[1]
HetGNN:Heterogeneous Graph Neural Network(2019-KDD)[2]
CompGCN: COMPOSITION-BASED MULTI-RELATIONAL GRAPH CONVOLUTIONAL NETWORKS(ICLR-2020)[6]
1、简介
2、内容
Background Knowledge
异构(质)图定义:

翻译成人话就是:在一个图上节点与边的种类都不止一类。二者类别数之和大于2即可被称为异质图。一个经典的例子是引文数据:论文,作者,发表会议这三者均被作为图中节点。
图卷积网络GCN在这些年的成功有目共睹,上至推荐系统,下至点云分割在各行业落地广泛,首先我们需要知道的是所有这些图网络本质上都是试图对图上的信息进行聚合,来更新出节点新的Embedding,这个向量可以更好的体现出图在空间结构(与周围的节点关系)和与自身的特性属性上的特质。从GraphSAGE到GAT到今天我们说的model,无一例外。

那这玩意能做我们今天的异构图吗? 否。
那为什么不能做呢? 上式中所有特征都可以被全部放到 矩阵内的原因是他们是一类节点!而这里显然不是,这就涉及到了第一个需要处理的问题:如何处理多类节点的情况。
R-GCN: Modeling Relational Data with GCN(2017)[1]
“简单粗暴但有效”
需要指出的是,这里标题中的Relational会让新手误会,认为是egde上的信息,其实在本文中edge只作为一种标注目标节点类别的属性的工具,edge上没有向量(信息),真正的特征全部被具象化为节点。以下图[1]中USA举例,事实上信息仅存在于'U.S.A.'上,'citizen of' 上并不存在。

关于异质图信息存储位置的解释
OK,知道了我们需要建模多类别节点的网络情况,那么应该如何做呢?R-GCN的方案相当简单粗暴。针对多类别的问题,R-GCN说:
行,你关系多是吧?爷一个类别给你弄一个矩阵算embedding,不就是参数吗,就往上楞堆,爷全部梭哈。当然要讲武德啊,你们一个关系对一整张图共用一个矩阵,多了架不住。
于是现在的图景变成了这样:


这样硬train一发真的管用吗?还真管用了,但很遗憾没有完全管用。
问题的来源正是参数矩阵 W ,这个稠密矩阵事实上完全由节点向量长度与特征个数决定,一旦relation过多,文中指出模型就会出现过拟合稀缺边的情况。即一旦某类边变的稀有,他们很容易在决定最终label时起到关键作用。作者给出了两张解决方案,这两者也很直接,都是直接拿 W 开刀:
- basis decomposition: 这一方案退回了原来GCN的方式,但将各个relation之间的weights共享,而对于每一个关系只有唯一的一个参数
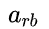

- block-diagonal-decomposition:上一种方案显得将模型的灵活度收缩的过窄,那么有无折中的办法呢?这里作者将 W 矩阵分块对角化,
 即是分块矩阵,其数目为一个超参数,由人设定。这使得参数减少的同时获得了一定的可变性,写作
即是分块矩阵,其数目为一个超参数,由人设定。这使得参数减少的同时获得了一定的可变性,写作

本文使用的损失函数也是常规的交叉熵函数,先看下一篇,最后再总结。
HetGNN:Heterogeneous Graph Neural Network(2019-KDD)[2]
'All you need is 老办法+胶水' /狗头保命
相对于始祖级别的R-GCN来说,HetG来的显然要高明的多,命名也十分直接,各种之前State-of-the-art的工作也都囊括在内,虽有胶水嫌疑,但总体上也不影响是篇好工作。
作者在PROBLEM DEFINITION部分指出,本文要解决的问题只有一个:
给出一个模型 F,如何让其学到每个节点上embedding(每个节点的特征表示),这个embedding可以充分反映出异质图的结构信息和节点上的非结构信息。
作者开篇认为之前工作有着三类问题,这里简单罗列一下
- 在不同节点做聚合时,有些节点之间并没有相连,但二者之间的关系十分重要。例如下图中的author和venue,这两者并没有相连,而在传统方式中,包括上述的R-GCN中这两者之间的关系传播依赖于一个至少两层的图神经网络结构来propogation,更远的节点则需要一个更深的结构。这一传播在作者看来可能会削弱原本应该带来的影响。进一步的,对于中心某些连接紧密的节点而言,周围其实并不与其关联度有多少的邻居在聚合时会趋向于变成‘noise node’。

e.g. 引文异构图
- 节点所携带的信息可能是多元的:语音、图像、数值等都有可能,那么如何解决embedding问题也是需要考虑的,本文的算法也定义在一个单个节点可以表示多类信息的异构图上。
- Node Tpye Matter!过去的文章中没有考虑各个节点的类型在标签传播过程中产生的影响。一个典型的例子是上图中对于一个author节点而言,一个paper或author邻居对其产生的影响不可以被以同样的模式处理。
Well,作者是如何解决这三个问题呢?
问题1解决非相连节点信息聚合
1.首先我们需要知道,GNN的发展中,我们一直希望能找到网络结构的一种优良表述,即如何完成graph to sequence这一过程, 翻译成大白话就是:在标签传播中这一过程中关于邻居的选择问题. 事实上在数年前,并不是一开始就是对于其一阶直接邻居做处理(GAT计算attention,GraphSAGE计算LSTM等),更古老的一种办法就是今天作者使用的:Random Walk, 本质上是shallow embedding的一种.
这里不对随机游走算法本身的意义做过多叙述,详见Stanford CS224W[3]
作者认为对于异构图而言,这样的办法远胜标签传播,原因详见文章3.1部分开头,主要是因为当前的办法在异构图中不能分辨类别带来的影响,对邻居采样范围也过于限制。
对于每类节点邻居取出现频率最高的n个的,无向异构图的随机游走,可以被描述为:
#伪代码
for node in node_list:
neighbour_of_this_node = [] #所有采样的邻居节点
selected_node = [] #真正确定的邻居节点
while (current_collect_number < need_to_collect) and (kinds_in_collection < all_kinds_number)
walk_around(neighbour_of_this_node)
if p #以p几率返回初始点
back_to_init()
for type in all_node_type:
node_id = top_k(select_type(neighbour_of_this_node,type),n)
selected_node.append(node_id)
save(selected_node)最后可以得到每个节点的邻居,覆盖周围所有可能出现的各个类型的节点,且每一类都取n个。这里一个小问题需要指出的是,在3.4部分作者给出了这样的random walk的另一个小限制,即邻居的选择应该在图中二阶相邻节点以内。
问题2&3 处理节点上多种特征和节点信息聚合的问题
对于一个节点上有着多种特征这个问题上,事实上这里的方案十分明确:用各个领域公认较强的特征抽取模型即可,换言之
你是图片,那就用CNN结构,你是文本,那就用Par2Vec,你是类别,那就直接one-hot编码,你是音频数据,那就....,如此将各个类型转换为向量表示
在这些特征抽取完成之后,现在在我手上的就是一堆向量,他们来自于单个节点上的不同的data feature。对于这些不同长度的feature,简单的将其输入到一个多层全连接结构的网络中,以获得最后统一长度的向量。在拿到表示各个特征的多个同一维度向量后,那我要如何将其融合呢?
简单,一个双向的RNN(LSTM)就可以。

事实上作者这里依旧是如同做单个节点信息聚合一样的操作,用一个双向的LSTM加均值池化操作完成每一种类的邻居信息聚合,即一个类别邻居上的信息只用一个向量表示。这里需要注意,第二次使用LSTM聚合不同类别节点邻居信息时应该对每一个类别使用一个LSTM。这一过程如下图所示:
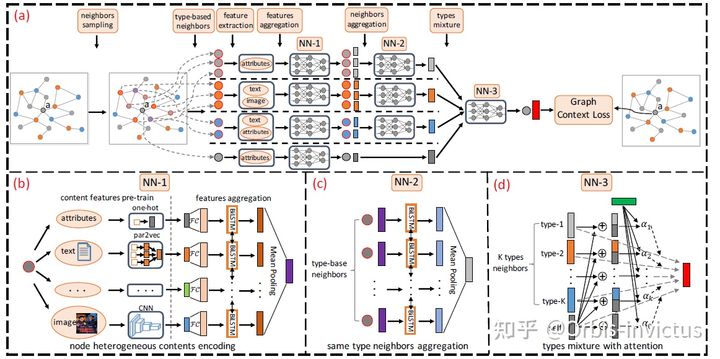
FrameWork of HetG
这个过程事实上有点绕,作者分别使用了两次聚合,尽管方式均为LSTM加均值池化的操作,但含义并不相同,前者是节点层面信息的聚合,后者是不同种类内部各个邻居的聚合。
 , 现在大功即将告成,我们回头来看这两篇文章的训练模块。
, 现在大功即将告成,我们回头来看这两篇文章的训练模块。
HetGNN下游任务的训练
首先对图上的问题的常用训练思路做简单总结:
- 节点分类:网络产生的Embedding直接投影到类别数目长度,经过Softmax即可得到评分,这一评分与有label的结点即可计算损失, 或是将embedding另拿出来,使用评估.
这里还应该做一个Inductive和Transductive的细分,即测试时是否加入新的节点(训练时未见过的), 说白了就是整个图的结构是否变化了, 多提一句: 事实上当今基于 message pass的GNN均支持这两类任务.
1. Transductive: 即图的结构不变化, test时预测之前在train网络时被故意遮住标签的节点
2. Inductive: 即预测新节点, 根据其在过去网络中的空间位置来聚合并获得embedding
- 链接预测:加入不存在的边,以某种方式从节点feature构建出一个score(如两个点上feature相乘获得一个数)来反应该边的存在概率,这一概率与边的label计算损失
- 图分类:以图池化等操作维持输出的embedding为类别长度,再由Softmax后与目标类别计算损失
R-GCN下游任务的训练
针对节点预测任务,其直接使用了上述方式(投影+Softmax), 计算损失时使用交叉熵函数,式子写作:

针对链接预测任务,R-GCN使用的edge score生成方式相较上述不太一致,其使用了一个encoder-decoder结构。这一部分原作者的代码较为复杂,有兴趣可以参考这篇文章[4]
关于如何使用两个节点的embedding来获得关系的评分,原文使用的是DistMult,这是一个简化的Rescal模型,这里涉及到知识图谱嵌入的相关概念,进一步了解可参看这篇文章[5]。
本质上而言DistMult属于语义匹配模型,这里引用一段定义
语义匹配模型是利用基于相似性的评分函数。他们主要是通过匹配实体的潜在语义和 向量空间表示中包含的关系来度量事实的可信度 [5]。
原文中给出的评分函数

作者事实上在代码中还给出了其他聚合方式,这里不做赘述,详见[5]

HetGNN需要注意的点
在HetGNN中,作者做了Inductive和非Inductive(Transductive)两类实验(见原文P7的RQ1-3和RQ2部分),具体方案与刚刚说的一致:对于非inductive实验, 在网络提取完特征之后直接使用一个逻辑回归器来进行分类,inductive实验中根据位置关系来聚合周围邻居信息获得embedding。
但在HetG中作者并没有分别给出节点预测,分类等下游任务的Loss,也就是说它并不是端到端训练的。在网络做完encoding后的embedding直接丢到逻辑回归器中取做节点分类;这个embedding和连接关系一起用来训练一个二分类器来预测连接是否存在。所以我们要关心的只是如何使网络得出的embedding最优。

翻译成更白的大白化(不太准确)就是你给我一个节点,我知道它周围的所有邻居,那这是不是就意味着我的网络捕捉到了其所有结构信息?是不是就是最优的效果?

CompGCN: COMPOSITION-BASED MULTI-RELATIONAL GRAPH CONVOLUTIONAL NETWORKS(ICLR-2020)[6]
文主要工作是将边的信息考虑到整个关系的计算中,联合的学习图中节点和边的向量表示。
之所以要把这篇单独拿出来说,是因为它事实上较为倾向于知识图谱邻域,边的embedding聚合在常用的异质图网络中并不常见。本文代码开源
首先要给出的是论文中的第一张图,它很好的诠释了本文要解决的问题。

在传统的图结构中,正如在R-GCN中提到的,事实上即使是异构图中,edge上也并不存储任何信息,而在知识图谱等领域中这样‘边上的信息’是相当普遍的,那么如何整合异构图上的这些信息的问题需要被解决,这也是本文的初始动机。
编码
在上图右侧中可以清晰看到edge和node上的向量(特征)是由一个 ![]() 函数连接起来,考虑在某些图中到边和节点的数目过于巨大,如果采用有参数的聚合形式(如RNN,线性映射等)参数量一定会爆炸,给训练造成困难,于是作者只采用三种非参数的聚合方式:
函数连接起来,考虑在某些图中到边和节点的数目过于巨大,如果采用有参数的聚合形式(如RNN,线性映射等)参数量一定会爆炸,给训练造成困难,于是作者只采用三种非参数的聚合方式:
- 二者相减
- 二者相乘
- 二者做Circular-correlation(相关系数的一种,油管教程在这[7])
但是请注意,这三种无参做法都需要一个共同的事实——两向量等长。

那如何解决它呢,这就又回到了类似在R-GCN中的方案,取基向量!(R-GCN中为分块对角化以简化参数),但这里这个向量的是如何替代边上feature并协同运算的坑尚我还不太明确,先留着,等有空看完源码之后再补。
OK,这就是CompGCN在encoder端(编码位置信息)做的所有工作了,现在再简单过一下文章中的理论公式部分,这里文章中是倒叙分解来说的,我们把顺序倒过来。


和R-GCN的对比
| CompGCN | R-GCN | |
|---|---|---|
| edge-level information | √ | × |
| edge type-wise weight | √ | × |
| 参数优化方案 | 在输入的首层定义基向量,后续以基向量参数区分不同关系,基向量可训练 | 1.分块对角化 2.所有relation共享参数,不同关系只用一个系数区分 |
| 邻居选择方式 | directly neighbor | directly neighbor |
解码
在本文的decoder部分(将编码信息变为不同任务的预测目标),作者使用了多种Score function,包括在上一篇文章中提到的DistMult,TransE来评估,最后得出在基向量长度为50,采用Circular-correlation做聚合,以TransE做评估函数时的效果最佳,详见Table4。
在Fb15k-237数据集上的评估显示即使基向量只取5,其效果已经显著超越R-GCN。
本文完,留了一个坑,下一篇将开始完整介绍metapath系列在异构图上的发展。
参考
- R-GCN https://arxiv.org/abs/1703.06103
- HetGNN https://www3.nd.edu/~dial/publications/zhang_2019_heterogeneous.pdf
- 【双语字幕】斯坦福CS224W《图机器学习》课程(2021) by Jure Leskovec
- R-GCN 关系图卷积神经网络链路预测任务论文复现总结
- 知识图谱嵌入技术浅析
- CompGraph https://arxiv.org/abs/1911.03082
- Circular-Correlation的计算 https://www.youtube.com/watch?v=VIrPrT1WaUg
转载