文章目录
一、算法介绍
K最近邻(k-Nearest Neighbors,KNN)算法是一种基本的分类和回归算法,也是最简单易懂的机器学习算法。
应用场景有字符识别、文本分类、图像识别等领域
二、算法原理
存在一个训练样本集合A,在给定测试样本b时,基于某种距离度量,找出训练集A中与测试样本b最靠近的k个训练样本(通常k<=20且为整数),之后,基于这k个训练样本的结果信息来预测种类或值。
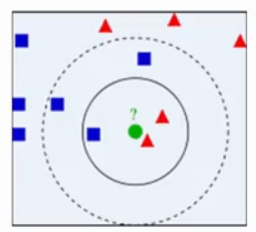 上图,绿色点为测试样本
上图,绿色点为测试样本
三、算法流程

1、计算测试样本和所有训练样本特征的相似度
如何计算相似度?使用距离衡量相似度:一般使用欧式距离
 点1(x1,y1)
点1(x1,y1)
点2(x2,y2)
 点1(x1,y1,z1)
点1(x1,y1,z1)
点2(x2,y2,z2)
2、按照相似度从大到小排序(按照距离从小到大排序)
距离越小,相似度越大
距离越大,相似度越小
3、选择K个最相似的样本
K由自己设定:K=5
4、根据K个最近的邻居 的结果:预测测试样本的结果
取众数 作为预测结果
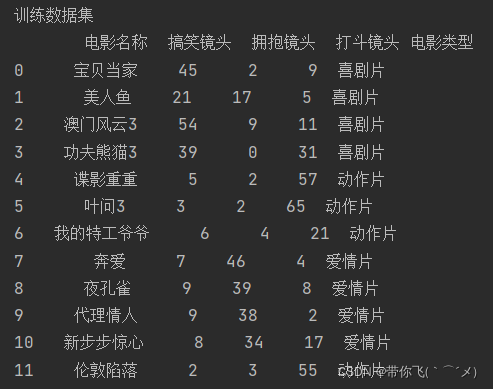
四、KNN电影分类的实现

import pandas as pd
import numpy as np
df = pd.read_excel("D:\pycharm\pythonProject\KNN算法./电影分类数据.xlsx")
# print(df)
# 1. 准备训练数据集
train_dataset = df.loc[:, "电影名称":"电影类型"]
# print("训练数据集\n", train_dataset)
# 2. 准备 测试样本
test_sample = df.columns[-3:].values # 测试样本特征值
# 特征一般使用X表示,标签使用y表示
# 拆分训练集为训练集的特征和标签
train_X = train_dataset.loc[:, "搞笑镜头":"打斗镜头"] # 训练集的特征
train_y = train_dataset["电影类型"] # 训练集的标签
# 算法阶段
# (1)计算测试样本和训练集中所有样本之间的相似度(使用距离表征相似度)
# print(train_X)
# print(test_sample)
dis = np.sqrt(np.sum((train_X-test_sample)**2, axis=1))
# (2) 按照距离递增排序
# df_final= pd.DataFrame({"类型":train_y, "距离":dis})
# print("df_final\n", df_final)
train_dataset["距离"] = dis
train_dataset.sort_values(by="距离", inplace=True)
# print(train_dataset)
#(3)选择与测试样本距离最近的k个训练样本
k = 5
result = train_dataset.head(k)
# print(result)
# (4) 根据前K个训练样本的标签,进行投票或者求平均
# 电影类型的众数 mode返回的结果是series
print("唐人街探案的类型", result["电影类型"].mode()[0])

五、KNN算法特点
1、自定义K值 (K<=20)
2、惰性学习算法 (边测试边训练)
3、计算复杂度高 (每个测试样本 需要和所有训练样本 进行距离计算 排序)
4、优势:简单
六、KNN电影类型预测-sklearn实现
sklearn:机器学习算法工具
安装sklearn
安装命令: pip install scikit-learn
from sklearn.neighbors import KNeighborsClassifier # KNN分类
import pandas as pd
df = pd.read_excel("D:\pycharm\pythonProject\KNN算法./电影分类数据.xlsx")
# 1. 准备训练数据集
train_dataset = df.loc[:, "电影名称":"电影类型"]
# print("训练数据集\n", train_dataset)
# 特征一般使用X表示,标签使用y表示
# 拆分训练集为训练集的特征和标签
train_X = train_dataset.loc[:, "搞笑镜头":"打斗镜头"] # 训练集的特征
train_y = train_dataset["电影类型"] # 训练集的标签
# 2. 准备 测试样本
test_sample = df.columns[-3:].values # 测试样本特征值
# 1. 实例化算法对象
# n_neighbors K值,默认是5
#metric 距离的计算方式,默认是闵可夫斯基距离,但是当闵可夫斯基距离中p=2时,就是欧式距离
knn = KNeighborsClassifier(n_neighbors=3)
# 2. 训练算法
# fit 拟合;拟合可以称为学习、训练
# 拟合(学习/训练)特征和标签之间的关系;
# 传入的参数 训练集特征和标签
knn.fit(train_X, train_y) # fit过程,简单存储所有训练集特征和标签
# 3. 预测
# 传入新数据特征,输出对应的标签
# 传入的必须是数据集
# y_pred = knn.predict( [[23,3,17]] )
y_pred = knn.predict(test_sample.reshape(1, -1))
# print(test_sample)
print("预测结果", y_pred) # 预测结果 ['喜剧片']
七、KNN手写数字识别
1、sklearn手写数字集认识
from sklearn.datasets import load_digits # 手写数字数据集
import matplotlib.pyplot as plt
# 加载手写数字数据集
x, y = load_digits(return_X_y=True)
# 打开动画开关
plt.ion()
for sample, label in zip(x, y):
plt.cla() # 清理画布
# sample 每行的数据,即每个样本
img = sample.reshape(8,8)
# print(sample)
plt.title(label)
plt.imshow(img)
plt.pause(2) # 每张图像之间间隔4秒
plt.ioff() # 关闭动画开关
plt.show()
2、实现
1>KNN-sklearn实现
from sklearn.datasets import load_digits # 手写数字数据集
# import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 数据拆分
from sklearn.neighbors import KNeighborsClassifier
# 加载手写数字数据集
x, y = load_digits(return_X_y=True)
# print("特征的shape", x.shape) # (1797, 64)
# 1797个样本 64个特征值
# print("标签", y.shape, y)
# 拆分数据集
# 训练集 和 测试集; 拆分比例通常是7:3 8:2
X_train, X_test, y_train, y_test = train_test_split(
x, # 特征
y, # 标签
test_size=0.2, # 给测试集分多少比例的样本
random_state=1, # 随机种子,设置随机种子后,可以保证多次运行结果是固定的
)
"""
import numpy as np
X, y = np.arange(10).reshape((5, 2)), range(5)
print(X)
print(y)
X_train, X_test, y_train, y_test = train_test_split(
X, # 特征
y, # 标签
test_size=0.2, # 给测试集分多少比例的样本
random_state=1 # 随机种子,设置随机种子后,可以保证多次运行结果是固定的
)
print("拆分后训练集\n", X_train)
print("拆分后测试集\n", X_test)
"""
print("拆分后", X_train.shape, X_test.shape)
# 算法阶段
# 实例化算法对象
knn = KNeighborsClassifier()
# 传入的参数 训练集特征和标签
knn.fit(X_train, y_train)
# 预测
"""
y_pred = knn.predict(X_test)
print("预测结果", y_pred)
print("真实结果", y_test)
print("正确识别的数目", (y_pred == y_test).sum())
print("在测试集上准确率", round(100*(y_pred == y_test).sum() / len(y_test), 2))
"""
# 得分
# 输入:测试集X_test 测试集标签y_test
# 根据X_test 获得预测结果
# 根据预测结果和真实结果y_test 计算准确率
acc = knn.score(X_test, y_test)
print("acc", round(acc*100, 2))
2>自实现
from sklearn.datasets import load_digits # 手写数字数据集
from sklearn.model_selection import train_test_split # 数据拆分
import numpy as np
import pandas as pd
# 加载手写数字数据集
x, y = load_digits(return_X_y=True)
# 拆分数据集
# 训练集 和 测试集; 拆分比例通常是7:3 8:2
X_train, X_test, y_train, y_test = train_test_split(
x, # 特征
y, # 标签
test_size=0.2, # 给测试集分多少比例的样本
random_state=1, # 随机种子,设置随机种子后,可以保证多次运行结果是固定的
)
print("拆分后", X_train.shape, X_test.shape) # (1437, 64) (360, 64)
# 每个测试样本 和 所有训练样本进行距离计算
acc_num = 0 # 记录正确识别的数目
for test_sample, label in zip(X_test, y_test):
# test_sample是测试样本
dis = np.sqrt(np.sum((X_train-test_sample)**2, axis=1))
df = pd.DataFrame({
"标签":y_train, "距离":dis})
y_pred = df.sort_values(by="距离").head(5)["标签"].mode()[0]
# label是真实结果
if y_pred == label:
acc_num += 1
else:
print("预测结果是{} 真实结果{}".format(y_pred, label))
print("正确的数目{} 准确率{}".format(acc_num, acc_num*100/len(y_test)))
3、手写数字文件读取
import os
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
"""
# 训练集路径下包含1934个文件
train_path = "../KNN算法/digit_data/trainingDigits" # 训练数据集路径
all_files = os.listdir(train_path)
# 建立一个空二维数组 用来存放训练数据集
train_data = np.zeros((len(all_files), 1025), dtype=int)
for ind, i in enumerate(all_files):
# 路径拼接
file_path = os.path.join(train_path, i)
# print(file_path)
# 使用numpy的方法读文件
arr = np.loadtxt(file_path, dtype=str) # arr包含32个元素,每个元素是一个字符串
arr = "".join(arr) # 拼接为一个大字符串
arr = [int(num) for num in arr] # 调整为包含1024个元素的的列表
# print(arr, type(arr))
train_data[ind,:-1] = arr
# print("文件名", i.split("_")[0])
label = int(i.split("_")[0]) # 获取对应的标签
train_data[ind, -1] = label
"""
def build_dataset(data_path=""):
"""
输入参数:训练集 或 测试集的路径
输出参数:训练集或测试集二维数据
:return:
"""
all_files = os.listdir(data_path)
# 建立一个空二维数组 用来存放数据集
dataset = np.zeros((len(all_files), 1025), dtype=int)
for ind, i in enumerate(all_files):
# 路径拼接
file_path = os.path.join(train_path, i)
# 使用numpy的方法读文件
arr = np.loadtxt(file_path, dtype=str) # arr包含32个元素,每个元素是一个字符串
arr = "".join(arr) # 拼接为一个大字符串
arr = [int(num) for num in arr] # 调整为包含1024个元素的的列表
# print(arr, type(arr))
dataset[ind, :-1] = arr
# print("文件名", i.split("_")[0])
label = int(i.split("_")[0]) # 获取对应的标签
dataset[ind, -1] = label
return dataset
train_path = "D:\pycharm\pythonProject\KNN算法\digit_data./trainingDigits" # 训练数据集路径
test_path = "D:\pycharm\pythonProject\KNN算法\digit_data./testDigits" # 测试数据集路径
train_dataset = build_dataset(train_path)
test_dataset = build_dataset(test_path)
k_list = [3, 4, 5, 6, 7, 8]
score_list = []
for k in k_list:
# 实例化
knn = KNeighborsClassifier(n_neighbors=k)
# 传入的参数 训练集特征和标签
knn.fit(train_dataset[:, :-1], train_dataset[:, -1])
# 输入:测试集特征 测试集标签
acc = knn.score(test_dataset[:, :-1], test_dataset[:, -1])
print("K={} acc是{}".format(k, round(acc * 100, 2)))
score_list.append(acc)
import matplotlib.pyplot as plt
plt.plot(k_list, score_list, marker='o')
plt.show()
# k=5 97.99
# k=3 98.52
八、KNN算法API
def init(self, n_neighbors=5, *,
weights=‘uniform’, algorithm=‘auto’, leaf_size=30,
p=2, metric=‘minkowski’, metric_params=None, n_jobs=None,
**kwargs):
n_neighbors:表示K值,K个近邻
weights:表示权重的计算方式{‘uniform’, ‘distance’} 默认是uniform
uniform:近邻的点的权重都一样,所以主要看点的个数
distance:距离的倒数表示权重
algorithm:算法{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}
auto:自动选择最优算法
ball_tree:建立球树
kd_tree:建立k维的平衡二叉树
brute:穷举法,暴力搜索
brute:在测试样本寻找最近的k个邻居时,需要较长时间
ball_tree和kd_tree:可以在搜索k近邻时,降低搜索时间;
是以空间换时间(提前需要构建、存储一个树)
leaf_size:叶子节点,针对ball_tree和kd_tree
p和metric:决定了距离的计算方式
metric_params
n_jobs:并行
九、寻找最好的参数
1、交叉验证
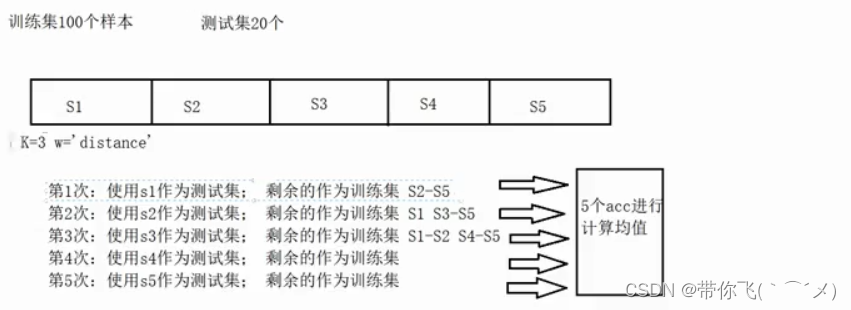
"""
寻找最好的参数:交叉验证
"""
from sklearn.datasets import load_digits # 手写数字数据集
from sklearn.model_selection import train_test_split # 数据拆分
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score # 交叉验证
# 加载手写数字数据集
x, y = load_digits(return_X_y=True)
# 拆分数据集
# 训练集 和 测试集; 拆分比例通常是7:3 8:2
X_train, X_test, y_train, y_test = train_test_split(
x, # 特征
y, # 标签
test_size=0.2, # 给测试集分多少比例的样本
random_state=1, # 随机种子,设置随机种子后,可以保证多次运行结果是固定的
)
"""
best_acc = 0
best_k = 0
best_w = ""
k_list = [2, 3, 4, 5, 6, 7]
weights = ["uniform", "distance"]
for k in k_list:
for w in weights:
knn = KNeighborsClassifier(n_neighbors=k, weights=w)
knn.fit(X_train, y_train)
acc = knn.score(X_test, y_test)
if acc > best_acc:
best_k = k
best_w = w
best_acc = acc
print("最好的参数k={}, w={} 准确率{}".format(best_k, best_w, best_acc))
"""
# knn = KNeighborsClassifier(n_neighbors=7, weights='uniform')
# acc = cross_val_score(knn, x, y, cv=6).mean()
# print(acc)
best_acc = 0
best_k = 0
best_w = ""
k_list = [2, 3, 4, 5, 6, 7]
weights = ["uniform", "distance"]
for k in k_list:
for w in weights:
# 使用特定参数的算法对象
knn = KNeighborsClassifier(n_neighbors=k, weights=w)
# 训练集(X)拆分为cv(5)份
# 使用knn每次选择一份作为测试集
acc = cross_val_score(knn, x, y, cv=5).mean()
if acc > best_acc:
best_k = k
best_w = w
best_acc = acc
print("最好的参数k={}, w={} 准确率{}".format(best_k, best_w, best_acc))
2、网格搜索
from sklearn.datasets import load_digits # 手写数字数据集
from sklearn.model_selection import train_test_split # 数据拆分
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.model_selection import GridSearchCV # 网格搜索
# 加载手写数字数据集
x, y = load_digits(return_X_y=True)
# 拆分数据集
# 训练集 和 测试集; 拆分比例通常是7:3 8:2
X_train, X_test, y_train, y_test = train_test_split(
x, # 特征
y, # 标签
test_size=0.2, # 给测试集分多少比例的样本
random_state=1, # 随机种子,设置随机种子后,可以保证多次运行结果是固定的
)
knn = KNeighborsClassifier()
# estimator 算法对象
# param_grid 参数
grid = GridSearchCV(knn, param_grid={
"n_neighbors": [2, 3, 4, 5, 6, 7],
"weights": ["uniform", "distance"]
},
cv=5)
# grid.fit(X_train, y_train)
grid.fit(x, y)
print("最好的得分", grid.best_score_)
print("最好的参数", grid.best_params_)
3、总结
网格搜索 是 交叉验证的 封装
交叉验证和网格搜索本质上:都是在选择参数
选择好参数后,该文件没有意义,后续不再使用