
微软研究院
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
paper:https://arxiv.org/pdf/2104.02300.pdf
code:https://github.com/HRNet/DEKR
摘要
文章中采用的是自底向上的范式,准确地回归关键点位置需要学习专注于关键点区域的表征。论文将这种简单而有效的方法,称为解纠缠关键点回归(DEKR)。通过采用像素级空间Transformer的自适应卷积来激活关键点区域中的像素。使用一个多分支结构进行单独的回归:每个分支学习一个具有专用自适应卷积的表示,并回归一个关键点。由此得到的解纠缠表示能够分别关注关键点区域,因此关键点回归在空间上更准确。实验表明,所提出的直接回归方法优于关键点检测和分组方法,在COCO和CrowdPose两个基准数据集上获得了优的自底向上的姿态估计结果。
论文背景
针对人体关键点检测,学术界有两种解决方案,一种是自顶向下的方法,先检测出人体目标框,再对框内的人体完成单人姿态检测,这种方法的优点是更准确,但开销花费也更大;另一种则是自底向上的方法,常常先用热度图检测关键点,然后再进行组合,该方法的优点是其运行效率比较高,但需要繁琐的后处理过程。本文采用的是自底向上。此外,密集关键点回归框架对于每个像素点都会通过回归一个 2K 维度的偏移值向量来估计一个姿态。而DEKR将偏移值向量图是通过一个关键点回归模块处理骨干网络得到的特征而获得的。具体的,是将骨干网络生成的特征分为K份,每份送入一个单独的分支。每个分支用各自的自适应卷积去学习一种关键点的特征,最后用一个卷积输出一个这种关键点的二维偏移值向量。

论文主要思想
DEKR 主要创新点有以下两个方面:
1.用自适应的卷积激活关键点区域周围的像素,并利用这些激活的像素去学习新的特征;
2.利用了多分支的结构,每个分支都会针对某种关键点利用自适应卷积学习专注于关键点周围的像素特征,并且利用该特征回归这种关键点的位置。
关于自适应卷积,论文为每个像素预测仿射变换矩阵和平移矩阵。从而将这两个矩阵作用于普通卷积的卷积核,得到自适应卷积的卷积核,进而激活关键点周围信息的特征。
![]()
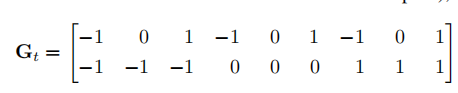
keras实现
以下是根据论文和pytorch源码实现的keras版本的自适应卷积模块(支持Tensorflow1.x)。
from keras.layers import Layer, Conv2D
import tensorflow as tf
class AdaptConv2d(Layer):
def __init__(self, outc, kernel_size=3, stride=1, bias=True, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(AdaptConv2d, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.regular_matrix = tf.constant([[-1, -1, -1, 0, 0, 0, 1, 1, 1],
[-1, 0, 1, -1, 0, 1, -1, 0, 1]], tf.float32, shape=(1, 2, 9))
self.transform_matrix_conv = Conv2D(4, kernel_size=3, padding='same', strides=1, use_bias=True)
self.translation_conv = Conv2D(2, kernel_size=3, padding='same', strides=1, use_bias=True)
self.conv = Conv2D(outc, kernel_size, strides=kernel_size, use_bias=bias) # Offset
self.modulation = modulation
if modulation: # Weights
self.m_conv = Conv2D(kernel_size*kernel_size, kernel_size=3, padding='same', strides=stride)
self.out_shape = None
def compute_output_shape(self, input_shape):
return tuple(self.out_shape)
def build(self, input_shape):
self.conv.build((input_shape[0], input_shape[1]*self.kernel_size, input_shape[2]*self.kernel_size, input_shape[3]))
self._trainable_weights += self.conv._trainable_weights
self.transform_matrix_conv.build(input_shape) # Offset
self._trainable_weights += self.transform_matrix_conv._trainable_weights
self.translation_conv.build(input_shape) # Offset
self._trainable_weights += self.translation_conv._trainable_weights
if self.modulation: # Weights
self.m_conv.build(input_shape)
self._trainable_weights += self.m_conv._trainable_weights
super(AdaptConv2d, self).build(input_shape)
def call(self, x, **kwargs):
transform_matrix = self.transform_matrix_conv(x)
transform_matrix = tf.reshape(transform_matrix, (-1, 2, 2)) # (N*H*W,2,2)
shape = tf.shape(x)
regular_matrix = tf.tile(self.regular_matrix, (shape[0] * shape[1] * shape[2], 1, 1))
offset = tf.reshape(tf.matmul(transform_matrix, regular_matrix), (-1, 2, 9)) # (N*H*W,2,2)
offset = offset - regular_matrix # (N*H*W,2,2)
offset = tf.reshape(offset, (shape[0], shape[1], shape[2], 18)) # (N, H, W, 18)
translation = self.translation_conv(x)
translation = tf.tile(translation, (1, 1, 1, 9))
offset = offset + translation
ks = self.kernel_size
b, h, w, c = offset.get_shape().as_list()
N = c//2
if self.modulation:
m = tf.sigmoid(self.m_conv(x))
# (b, h, w, 2N)
p = self._get_p(offset)
# (b, h, w, 2N)
q_lt = tf.floor(p)
q_rb = q_lt + 1
q_lt = tf.concat([tf.clip_by_value(q_lt[..., :N], 0, h-1), tf.clip_by_value(q_lt[..., N:], 0, w-1)], axis=-1)
q_rb = tf.concat([tf.clip_by_value(q_rb[..., :N], 0, h-1), tf.clip_by_value(q_rb[..., N:], 0, w)-1], axis=-1)
q_lb = tf.concat([tf.clip_by_value(q_lt[..., :N], 0, h-1), tf.clip_by_value(q_rb[..., N:], 0, w)-1], axis=-1)
q_rt = tf.concat([tf.clip_by_value(q_rb[..., :N], 0, h-1), tf.clip_by_value(q_lt[..., N:], 0, w)-1], axis=-1)
# clip p
p = tf.concat([tf.clip_by_value(p[..., :N], 0, h-1), tf.clip_by_value(p[..., N:], 0, w-1)], axis=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N] - p[..., :N])) * (1 + (q_lt[..., N:] - p[..., N:]))
g_rb = (1 - (q_rb[..., :N] - p[..., :N])) * (1 - (q_rb[..., N:] - p[..., N:]))
g_lb = (1 + (q_lb[..., :N] - p[..., :N])) * (1 - (q_lb[..., N:] - p[..., N:]))
g_rt = (1 - (q_rt[..., :N] - p[..., :N])) * (1 + (q_rt[..., N:] - p[..., N:]))
# (b, h, w, N, c)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, h, w, N, c)
x_offset = tf.expand_dims(g_lt, axis=-1) * x_q_lt + \
tf.expand_dims(g_rb, axis=-1) * x_q_rb + \
tf.expand_dims(g_lb, axis=-1) * x_q_lb + \
tf.expand_dims(g_rt, axis=-1) * x_q_rt
# modulation
if self.modulation:
m = tf.expand_dims(m, axis=-1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
self.out_shape = out.get_shape().as_list()
return out
def _get_p(self, offset):
h, w, c = offset.get_shape().as_list()[1:]
N = c // 2
# (1, 1, 1, 2N)
p_n = self._get_p_n(N)
# (1, h, w, 2N)
p_0 = self._get_p_0(h, w, N)
# (1, h, w, 2N)
p = p_0 + p_n + offset
return p
def _get_p_n(self, N):
p_n_x, p_n_y = tf.meshgrid(
tf.range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
tf.range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n_x = tf.reshape(p_n_x, (-1,))
p_n_y = tf.reshape(p_n_y, (-1,))
p_n = tf.concat([p_n_x, p_n_y], 0)
p_n = tf.reshape(p_n, (1, 1, 1, 2*N))
p_n = tf.cast(p_n, tf.float32)
return p_n
def _get_p_0(self, h, w, N):
p_0_x, p_0_y = tf.meshgrid(
tf.range(1, h*self.stride+1, self.stride),
tf.range(1, w*self.stride+1, self.stride))
p_0_x = tf.tile(tf.reshape(p_0_x, (1, h, w, 1)), (1, 1, 1, N))
p_0_y = tf.tile(tf.reshape(p_0_y, (1, h, w, 1)), (1, 1, 1, N))
p_0 = tf.concat([p_0_x, p_0_y], -1)
p_0 = tf.cast(p_0, tf.float32)
return p_0
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, h, w, N, c = x_offset.get_shape().as_list()
x_offset = tf.concat([tf.reshape(x_offset[:, :, :, s:s + ks, :], (-1, h, w * ks, c)) for s in range(0, N, ks)], axis=-2)
x_offset = tf.reshape(x_offset, (-1, h*ks, w*ks, c))
return x_offset
@staticmethod
def _get_x_q(x, q, N):
b, h, w, _ = q.get_shape().as_list()
_, padded_h, padded_w, c = x.get_shape().as_list()
x = tf.reshape(x, (-1, padded_h * padded_w, c))
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, h*w*N, c)
index = tf.reshape(index, (-1, h * w * N))
index = tf.cast(index, tf.int32)
x_offset = tf.batch_gather(x, indices=index)
x_offset = tf.reshape(x_offset, (-1, h, w, N, c))
return x_offset
声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论收藏关注!(想看更多最新的文献欢迎关注浏览我的博客)