相关文章
一:《简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项》
二:《继续聊聊DeepFaceLab(DeepFake)不断演进的2.0版本》
三:《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
四:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)》
五:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)》
六:《友情提示DeepFaceLab(DeepFake)目前与RTX3080和3090的兼容问题》
七:《高效使用DeepFaceLab(DeepFake)提高速度和质量的一些方法》
文章目录
一,使用预训练(Pretrain)的模型
1.1 什么是预训练(Quick96已有预训练模型)
预训练就是在开始训练各种模型前,选定一组适合你自己机器配置的参数后,用作者提供的15800多张各种脸先进行训练,这个预训练的结果可以用于后续的多种不同人物的训练,加速出结果。
作者已经提供了quick96预训练好的模型(因为quick96的参数是固定的),模型目录:
<DFL目录>\_internal\pretrain_Quick96\*.npy
所以如果你一开始选的是
- train Quick96.bat
会发现即使是从头训练,偏移数值也下降得特别快,就是预训练模型的功劳。
Hint:预训练时workspace可以是空的,当然里面有任何东西也不影响预训练!
1.2 开始自己的预训练
显然Quick96效果不太好,所以想要最后合成逼真,必须用其它的更高分辨率的模型。而其它模型作者并没有提供一个现成的预训练模型。
那是因为每个人机器配置(主要是显卡)不一样,所以只能自己选择合适的参数进行训练。

PS:这也是为什么你用了别人的一些高分辨率模型,在自己的普通显卡上却跑不起来。最近才知道还有人花钱买模型,蛤?什么操作,跑不起来就更惨了……
预训练怎么开始呢,只需要和普通训练一样开始SAEHD:
- train SAEHD.bat
选好各种参数,最后在回答是否 Enable pretraining mode? 的时候回答 y。
如下图所示,下面这些参数就是模型确定后无法更改的:
[*] Resolution ( 64-640 ?:help ) :128 #分辨率,越大越清晰
[*] Face type ( h/mf/f/wf/head ?:help ) :f #脸类型,半脸,全脸,带额头,整脑袋……
[*] AE architecture ( ?:help ) : df #模型架构,很可惜我的显卡只能选df
'df' keeps more identity-preserved face.
'liae' can fix overly different face shapes.
'-u' increased likeness of the face.
'-d' (experimental) doubling the resolution using the same computation cost.
Examples: df, liae, df-d, df-ud, liae-ud, ...
[*] AutoEncoder dimensions ( 32-1024 ?:help ) :256 #根据你机器配置情况选择或者直接默认值
[*] Encoder dimensions ( 16-256 ?:help ) :64 #根据你机器配置情况选择或者直接默认值
[*] Decoder dimensions ( 16-256 ?:help ) :64 #根据你机器配置情况选择或者直接默认值
[*] Decoder mask dimensions ( 16-256 ?:help ) :22 #根据你机器配置情况选择或者直接默认值
[*] Enable pretraining mode ( y/n ?:help ) : y #这里选y就是预训练
和以前版本花花绿绿的不一样,目前版本的预训练大概这个样子,这个是不到100W次的样子(最开始训练的截图被我不小心删掉了)……和普通训练不一样的地方在于最后一组图,并不是源和目标学习的结果,其它方面差不多。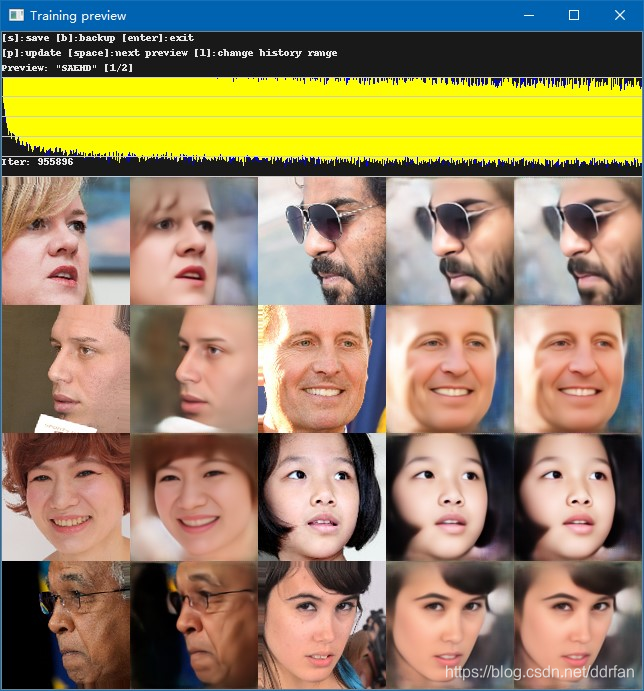
Hint:目前版的预训练是可以停止并重新开始的!
1.3 使用预训练模型
停下预训练后,把源source(data_src)和目标destination(data_dst)都准备好(这方面内容看之前的文章把)。然后再次开始训练:
- train SAEHD.bat
在提示按下回车重新录入模型设置时,果断的按回车。
其它不管,最后在回答是否 Enable pretraining mode? 的时候回答 n。
Press enter in 2 seconds to override model settings. #出现这个提示后赶快按下回车键,重新选一次参数,全回车就可以。
......
[*] Enable pretraining mode ( y/n ?:help ) : n #最后一步一定要选n,不再是预训练模式。
1.4 有无预训练对比
目前版本比较疑惑的是,就算使用预训练,正式训练的迭代计数器也是从0开始的。
1.4.1 无预训练模型
测试嘛,大概训练了500次。
会提示建议你别从白纸开始,用一个预训练模型吧……

1.4.2 用作者提供的Quick96预训练模型
半年多前作者说,Quick96: Now based on df-ud archi and 20% faster.
那么Quick96的500次训练效果如下:
从预览视觉效果和偏低数值来看的确有提升,实际如果继续跑下去,也较快的能出结果。

1.4.3 用自己的预训练模型
因为时间关系,刚才也说了这个预训练模型不到100W次。
正式大概训练了500次。
没有从头开始的提示了,但是效果提升不太明显,也许500次太少了吧。
虽然视觉效果不太明显,但是偏度数值小了一些(严谨一些应该用系统15分钟保存的来对比)。

1.4.4 用自己的预训练模型+拷回*.npy文件
由于用不用预训练似乎都差不多,按照有人说的办法这样弄了一下:
开始正式训练后,立刻保存退出,并把预训练的所有.npy文件拷贝回model目录。
也大概训练了500次。
源和目标脸貌似很清晰了,但是变换的效果完全不像,也许500次真的太少了,或者不应该这么操作。也有人说东方和西方人的五官太不一样……
总之预训练应该不需要拷回文件,具体提升程度还需要自己验证。

二,重复利用你自己训练的模型
如果预训练效果没有想象中那么好,那么重复利用相同Source的模型就有效得多。
之前其实讲过,用图来对比一下吧。
下面这个截图用的是一个重复利用过N次的模型,这个例子开始前模型已经训练了660多万次了。
基本上也是卡着训练500次截图的,但是明显合成后的效果已经像模像样了。
如果仅500次那么合成视频的时候会发现有抖动和闪烁,但是基本能看了。
所以重复利用自己的模型,比囊括一切的预训练模型效果更好。

三,适时的修改某些参数再训练
有两个参数一定要注意,开始训练的时候需要设置成这样:
[*] Use learning rate dropout ( n/y/cpu ?:help ) :n
[*] Enable random warp of samples ( y/n ?:help ) :y
训练到比较充分的程度,你觉得比较清晰了,偏离度数值开始难以下降了,就停下来。
重新开始训练,及时按回车键,把这两个参数换成:
[*] Use learning rate dropout ( n/y/cpu ?:help ) :y
[*] Enable random warp of samples ( y/n ?:help ) :n
具体的意义看下面:
前面的 [*] 实际上你会看到默认或者上次的设定值,因为大家都不一样,此例就不显示了。
[*] Use learning rate dropout ( n/y/cpu ?:help ) : ?
When the face is trained enough, you can enable this option to get extra sharpness and reduce subpixel shake for less amount of iterations. Enabled it before `disable random warp` and before GAN.
n - disabled.
y - enabled
cpu - enabled on CPU. This allows not to use extra VRAM, sacrificing 20% time of iteration.
[*] Enable random warp of samples ( y/n ?:help ) : ?
Random warp is required to generalize facial expressions of both faces. When the face is trained enough, you can disable it to get extra sharpness and reduce subpixel shake for less amount of iterations.
四,另一些关系到质量的参数
#如果你的源脸图片足够覆盖目标的各种角度光照,这个可以不开脸更自然(金城武的对称程度?^o^),否则就打开,脸会被左右镜像着学习。
[*] Flip faces randomly ( y/n ?:help ) : ?
Predicted face will look more naturally without this option, but src faceset should cover all face directions as dst faceset.
#眼和嘴优先,如果没出现很怪异的眼球方向或嘴型,可以不开。
[*] Eyes and mouth priority ( y/n ?:help ) : ?
Helps to fix eye problems during training like "alien eyes" and wrong eyes direction. Also makes the detail of the teeth higher.
#开着吧
[*] Uniform yaw distribution of samples ( y/n ?:help ) : ?
Helps to fix blurry side faces due to small amount of them in the faceset.
#显卡内存够就开着吧
[*] Place models and optimizer on GPU ( y/n ?:help ) : ?
When you train on one GPU, by default model and optimizer weights are placed on GPU to accelerate the process. You can place they on CPU to free up extra VRAM, thus set bigger dimensions.
#显卡内存够就开着吧
[*] Use AdaBelief optimizer? ( y/n ?:help ) : ?
Use AdaBelief optimizer. It requires more VRAM, but the accuracy and the generalization of the model is higher.
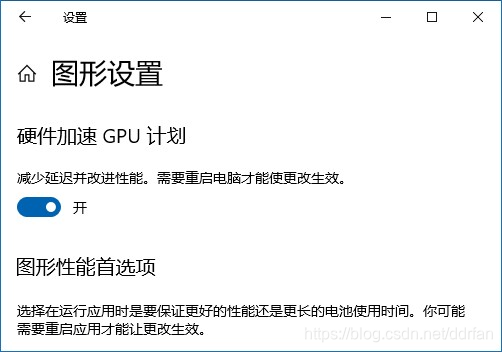
五,Win10用户重要提示
刚才测试截图能看到,每次新训练,都有个重要提示。不少人都反馈说需要打开这个设置才能正常工作。
Windows 10 users important notice!
You should set this setting in order to work correctly.
System – Display – Graphics settings:

正常情况下那个url放的图我们根本看不到,作者也没用文字描述,真是的……
幸好CSDN转存OK。
中文系统就是:
桌面->鼠标右键菜单->显示设置->界面几乎最下面->图形设置->硬件加速GPU计划:
Hint:实际上应该是硬件加速GPU调度,这翻译,和屏幕存储程序有得一拼……
PS:写这些时,用的显卡比较惨,例子迭代次数的确不应该这么少……