文章目录
(零)前言
本文记录了从零开始,使用Hadoop(HDFS)+Spark,
建立不同的集群,用Java/Python/Scala语言编写实例程序的过程。

Hadoop® :是一个分布式大数据的计算框架,主要组成:
- HDFS™(Hadoop Distributed File System):高吞吐分布式文件系统。
- MapReduce: 基于YARN的大数据并行计算引擎。
- YARN: 任务调度和集群资源管理框架。

Spark™ :是一个大数据处理分析引擎。它相比Hadoop(MapReduce)效率更高,特别是逻辑运算。
(一)准备集群虚拟机与操作系统
(1.1)准备Master虚拟机
【1】选择CentOS/安装或者复用已有设备
选择虚拟机是最方便的,因为资源有限并且平时需要Windows进行管理开发。当然如果已经有现成的Linux环境无论是RHEL还是CentOS或者ubuntu都可以拿来用。
- 在我实际工作环境中,客户提供的环境通常是从资源池中分配的虚拟机,并安装RHEL系统。 所以我选择CentOS作为测试环境。
- 由作为Master的虚拟机通常是复用的(Eclipse,IDEA,PAServer,FTP/WEB服务器,网页文件浏览等等…),所以一般我们安装带有图形界面的,各种库比较完整的系统。
- 安装CentOS时自带的是gnome桌面,为了方便和好看,我选择了Cinnamon桌面。
【2】下载虚拟机ISO
下载完整的CentOS7 DVD,目前版本是1810。
当然是官网下载最好:https://www.centos.org/download/

以防万一我们通过release notes里面的信息来验证下载的DVD文件。
sha256sum x86_64:
38d5d51d9d100fd73df031ffd6bd8b1297ce24660dc8c13a3b8b4534a4bd291c
CentOS-7-x86_64-Minimal-1810.iso
6d44331cc4f6c506c7bbe9feb8468fad6c51a88ca1393ca6b8b486ea04bec3c1
CentOS-7-x86_64-DVD-1810.iso
【3】准备VMware安装虚拟机
安装前先设置好网络环境,估计好虚拟机的CPU、内存、磁盘空间资源。并去掉不需要的设备。
因为我们需要访问局域网中运行于其它计算机上的虚拟机,所以网络选择桥接模式。
VMware的虚拟网络编辑器和虚拟机本身都要设置好桥接,以及桥接的网络。
虚拟机的磁盘最好是预先分配好空间,避免慢慢扩展带来的外层磁盘碎片。


【4】开始安装虚拟机
咱不是运维,所以通过图形界面,下一步,下一步就可以安装好。
其中可以先指定好root的密码(这里可以设置短一些),顺便新建一个用户。
磁盘可以用自动分区(以后不够了可以扩),设置好网络IP等。
全部完成后大概是这样的:

(1.2)准备Workers虚拟机
【1】最小安装
工作站(Workers)虚拟机和安装Master虚拟机的步骤几乎是一样的,但是为了节约空间(作为HDFS的Datanode)应该进行最小安装,没有必要装图形桌面等,可以下载CentOS Minimal ISO 安装。
先安装一台,全部设置好以后,再拷贝成多台Worker虚拟机。
全部完成后大概是这样的:

【2】要啥啥没有
因为是最小安装,很多常用命令都没有。所以很多东西需要手动装一下,要不然真的是很不方便。

(1.3)设置虚拟机环境
运行Hadoop和Spark至少需要用到SSH,Java环境。
【1】配置主机网络(Master和Slave都要配好)
如果安装过程中没有配置好网络,则需要先配好网络,否则剩下的步骤都无法进行。
根据实际情况配置好网络:IP,掩码,网关,DNS。
文件名有可能不是这个,注意看看。ONBOOT=yes表明开机网络自动启动。
$ sudo vim /etc/sysconfig/network-scripts/ifcfg-ens32 ————根据实际情况配置下述内容
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=no
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens32
DEVICE=ens32
ONBOOT=yes
IPADDR=192.168.2.222
PREFIX=24
GATEWAY=192.168.2.254
DNS1=192.168.2.254
然后重启网络服务吧
$ systemctl restart network
【2】关闭防火墙 (Master和Slave都关闭最方便)
$ systemctl disable firewalld
$ systemctl stop firewalld
【3】安装ssh服务 (Master和Slave都要安装)
网通了就可以直接yum进行安装了,如果安装中发现已经有了就可以跳过。
$ sudo yum install openssh
可以通过指令确定ssh服务的状态,和控制它。
看到 Active: active (running) 就OK了。
$ systemctl status sshd ————查看ssh服务的状态
$ systemctl start sshd ————启动ssh服务
$ systemctl stop sshd ————停止ssh服务
$ systemctl disable sshd ————开机禁用ssh服务
$ systemctl enable sshd ————开机启用ssh服务
【4】配置ssh密钥方式登录(免密码登录)
因为是Master访问各个Worker,所以在Master机器上生成Master的密钥。
$ ssh-keygen -t rsa ————私钥和公钥将生成到用户目录/.ssh中,如下:
Your identification has been saved in /home/Shion/.ssh/id_rsa.
Your public key has been saved in /home/Shion/.ssh/id_rsa.pub.
因为机器有限Master其实也是个Worker,所以自己的公钥也要放入本机的authorized_keys
然后传给刚才装好的Worker机。
$ cat /home/Shion/.ssh/id_rsa.pub >> /home/Shion/.ssh/authorized_keys
$ scp /home/Shion/.ssh/authorized_keys 192.168.2.222:/home/Shion/.ssh/authorized_keys
需要注意.ssh目录和文件都不要让别的用户和组访问,否则不生效:
- ssh目录的权限必须是700
- ssh/authorized_keys文件权限必须是600
试一下,如果没有成功则从Master ssh 到 Worker的时候还需要输入密码(成功就不要密码了)。
【5】安装JDK(Master和Slave都要安装)
如果用OpenJDK的话,直接:
$ sudo yum install java
---> 软件包 java-1.8.0-openjdk.x86_64.1.1.8.0.201.b09-2.el7_6 将被 安装
...
不过我还是选择去Oracle官网下载Java8的JDK,RPM包或者压缩包:
Linux x64 168.05 MB jdk-8u201-linux-x64.rpm
Linux x64 182.93 MB jdk-8u201-linux-x64.tar.gz
下载了RPM后:
$ su
# rpm -ivh jdk-8u201-linux-x64.rpm
# vim /etc/profile ————在文件最后加入
export JAVA_HOME=/usr/java/default
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后重启或者:
# source /etc/profile
【6】随自己喜好更改和设置(可以先略过)
安装vim
$ sudo yum install vim
提示符颜色格式设置
$ vim ~/.bashrc ————在文件最后添加下述内容
PS1='\$\[\033[01;32m\]\u\[\033[01;33m\]@\[\033[01;32m\]\h \[\033[01;34m\]\W\[\033[00m\]> '
export PS1
升级一下软件
$ sudo yum upgrade
去掉多余的内核
传送门: 删除多余的RHEL(CentOS7)虚拟机Linux内核(启动菜单)
安装cinnamon桌面
其实可以先只装一台Master,当其它所有该安装和配置的都完成以后,将Master复制一份作为第一个Worker。最后再在Master上安装桌面(此处以cinnamon为例,其它桌面类似)。
# yum install epel-release ————安装扩展源
# yum install yum-axelget ————提高yum下载速度
# yum -y groupinstall “X Window system”
# yum -y install lightdm
# yum install cinnamon ————这一步只安装了cinnamon桌面本身。
# yum install gnome-terminal ————自动启动图形界面了,如果只装了cinnamon本身,至少装个终端先,要不本机登录啥都干不了。
只安装cinnamon桌面,工具什么的都没有,或者就groupinstall吧:
# yum groupinstall “cinnamon” ————空间占用比较大,有用没用的都装上先。
手动启动图形界面:
$ systemctl isolate graphical.target
自动启动图形界面:
# systemctl set-default graphical.target
如果删错过东西可能启动不了,需要:
# yum -y groupinstall “Server with GUI”
如果正常的进入了图形界面。
但是这时有可能是乱码,因为没有字体,得安装:
# yum groupinstall “fonts”
检查中文环境:
*更新:之前的方法并不是CentOS7下可用的
首先查看当前的系统语言:
# echo $LANG
如果不是中文,再看看有没有语言包
# locale -a|grep zh_CN
不是中文的话:
# localectl set-locale LANG=zh_CN.UTF-8
或者:
# vim /etc/locale.conf
LANG=zh_CN.UTF-8
最后source或者重启机器。
不过我系统语言是中文的情况下,cinnamon登录进去的界面却是英文。
并且可视化的语言设置有问题无法设置。所以只好:
$ vim ~/.bashrc
export LANG=zh_CN.utf8
(二)安装Hadoop和Spark
(2.1)准备好全部计算机
我配置了6台机器:
- shionlnx ——(Hadoop Master/Datanode + Spark Master/Worker )—— 192.168.168.14
- shion1 ——(Hadoop Datanode + Spark Worker ) —— 192.168.168.13
- ac1 ——(Spark Worker )注:空间不足不用于HDFS —— 192.168.168.114
- ac2 ——(Hadoop Datanode + Spark Worker ) —— 192.168.168.113
- ad1 ——(Hadoop Datanode + Spark Worker ) —— 192.168.168.12
- ad2 ——(Hadoop Datanode + Spark Worker )—— 192.168.168.11
master 和 第一台slave可以各自安装,也可以从Master拷贝出各个slave。
到此时每台机器都应该配置好了网络IP地址,机器名(hostname)。
【1】更改hosts文件便于用名称访问主机(每一台主机都需要修改同样内容)
# vim /etc/hosts ——增加如下内容(请按实际情况):
192.168.168.14 shionlnx
192.168.168.114 ac1
192.168.168.113 ac2
192.168.168.13 shion1
192.168.168.12 ad1
192.168.168.11 ad2
【2】更改hostname文(每一台主机都需要分别修改,XXX是具体的名字)
# hostnamectl set-hostname XXX
先在Master机器上配置好Hadoop和Spark,然后再拷贝到其它Worker上。
(2.2)安装配置Hadoop
【1】下载安装包
当然是官网下载最好:https://hadoop.apache.org/releases.html
可以直接下载binary(编译好的)。
保险起见,最好也检查一下下载文件的checksum。

【2】解压到你想放置的目录
$ tar -zxvf hadoop-3.1.2.tar.gz -C /home/Shion ————解压
$ mv /home/Shion/hadoop-3.1.2 /home/Shion/hadoop ————改名
【3】配置环境
先配置HADOOP_HOME:
$ sudo vim /etc/profile ————在文件最后加入
#hadoop
export HADOOP_HOME=/home/Shion/hadoop
export PATH=$PATH:${HADOOP_HOME}/sbin
export PATH=$PATH:${HADOOP_HOME}/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
进入{HADOOP_HOME}目录配置:hadoop-env.sh
$ vim etc/hadoop/hadoop-env.sh ————在文件最后加入(这是hadoop目录下的etc啊)
export JAVA_HOME=/usr/java/default
进入{HADOOP_HOME}目录配置:core-site.xml
$ vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> <!--NameNode 的URI-->
<value>hdfs://shionlnx:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!--hadoop临时文件的存放目录-->
<value>/home/Shion/hadoop/temp</value>
</property>
</configuration>
进入{HADOOP_HOME}目录配置:hdfs-site.xml
$ vim etc/hadoop/hdfs-site.xml
<configuration>
<property> <!--目录无需预先存在,会自动创建-->
<name>dfs.namenode.name.dir</name>
<value>/home/Shion/hadoop/dfs/name</value><!---->
</property>
<property> <!--目录无需预先存在,会自动创建-->
<name>dfs.datanode.data.dir</name>
<value>/home/Shion/hadoop/dfs/data</value>
</property>
<property> <!--数据副本数量,不能大于集群的机器数量,默认为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property> <!--设置为true,可以在浏览器中IP+port查看-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property> <!--dfs文件权限关闭(便于不同用户访问)-->
<name>dfs.permissions</name>
<value>false</value>
</property>
<property> <!--动态下线的主机,配置文件名-->
<name>dfs.hosts.exclude</name>
<value>/home/Shion/hadoop/etc/hadoop/dfs_exclude</value>
</property>
<property> <!--给HBase预留的最大传输线程数-->
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
</configuration>
进入hadoop目录配置:workers(以前叫slaves)
$ vim etc/hadoop/workers
shionlnx
shion1
ac2
ad1
ad2
【4】从master整体拷贝hadoop目录到worker
scp -r /home/Shion/hadoop shion1:/home/Shion/hadoop
scp -r /home/Shion/hadoop ac1:/home/Shion/hadoop
scp -r /home/Shion/hadoop ac2:/home/Shion/hadoop
scp -r /home/Shion/hadoop ad1:/home/Shion/hadoop
scp -r /home/Shion/hadoop ad2:/home/Shion/hadoop
(2.3)安装配置Spark
【1】下载安装包
当然是官网下载最好:http://spark.apache.org/downloads.html
咱的hadoop是3.1了,当然需要下载spark也得prebuilt4 hadoop 2.7+的。

【2】解压到你想放置的目录
$ tar -zxvf spark-2.4.1-bin-hadoop2.7.tgz -C /home/Shion ————解压
$ mv /home/Shion/spark-2.4.1-bin-hadoop2.7 /home/Shion/spark ————改名
【3】配置环境
先配置SPARK_HOME:
$ sudo vim /etc/profile ————在文件最后加入
#Spark
export SPARK_HOME=/home/Shion/spark
export PATH=$PATH:${SPARK_HOME}/bin
进入{SPARK_HOME}目录配置:spark-defaults.conf
$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf
$ vim conf/spark-defaults.conf
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 2g #默认1g,如果driver的内存够则不用设置这项。
# spark.python.worker.memory 768m
spark.executor.memory 2g #一般不用设置。
# spark.driver.memoryOverhead 768m
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.executor.extraJavaOptions -XX:-UseGCOverheadLimit #一般不用设置,Java垃圾回收的预警(自行了解)
# spark.executor.memoryOverhead 512m
# spark.network.timeout 240s
# spark.default.parallelism 33
# spark.sql.shuffle.partitions 800
spark.ui.showConsoleProgress true #控制台显示进度(task/stage),配合log4j显示WARN以上信息用。
进入{SPARK_HOME}目录配置:spark-env.sh
$ cp conf/spark-env.sh.template conf/spark-env.sh
$ vim conf/spark-env.sh
export JAVA_HOME=/usr/java/default
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export SPARK_MASTER_HOST=shionlnx
export SPARK_WORKER_CORES=1 #每个worker用到的cpu核心数
export SPARK_WORKER_MEMORY=2048m #每个worker使用的内存
export SPARK_WORKER_INSTANCES=2 #每个主机的worker实例数(这个是本机生效)
export SPARK_DRIVER_MEMORY=2048m #Driver能使用的内存
注意里面的参数有些是Master上配置就生效,有些是主机自己的配置生效1。
进入{SPARK_HOME}目录配置:workers(这里他们又叫slaves了。。晕。)
$ vim conf/slaves
shionlnx
shion1
ac1
ac2
ad1
ad2
进入{SPARK_HOME}目录配置:log4j.properties
$ cp conf/log4j.properties.template conf/log4j.properties
$ vim conf/log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=WARN, console #主要就是这一句,否者控制台输出的信息多到啥都看不清了。
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{
yy/MM/dd HH:mm:ss} %p %c{
1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
【4】从master整体拷贝spark目录到worker
scp -r /home/Shion/spark shion1:/home/Shion/spark
scp -r /home/Shion/spark ac1:/home/Shion/spark
scp -r /home/Shion/spark ac2:/home/Shion/spark
scp -r /home/Shion/spark ad1:/home/Shion/spark
scp -r /home/Shion/spark ad2:/home/Shion/spark
(三)启动HDFS和文件操作
(3.1)格式化HDFS
HDFS = Hadoop分布式文件系统,是后续Spark或者Mapreduce的基础。
进入{HADOOP_HOME}目录执行:
$ bin/hdfs namenode -format
格式化之后就可以启动HDFS了。
但是需要注意,如果重新格式化需要先将各个主机hdfs-site.xml中配置的数据和Name目录删掉。
对于我就是/home/Shion/hadoop/dfs/目录。
否则会造成DataNode的clusterID不一致,导致出现问题。
clusterID是这样格式的:CID-aaa66aaa-bb77-cc88-dd99-a1b2c3d4e5f6
(3.2)启动HDFS
为啥一定要用HDFS呢?
其实Spark程序是可以读取主机本地目录文件的,但是需要每台worker都有相同的路径和文件。。。
所以还是老老实实的用HDFS吧。
首先需要启动HDFS,在Master服务器启动hadoop,datanode节点会跟着启动的。
进入{HADOOP_HOME}目录执行:
$ sbin/start-dfs.sh
Starting namenodes on [shionlnx]
Starting datanodes
Starting secondary namenodes [shionlnx]
启动完成后,可以输入指令jps,看看NameNode,SecondaryNameNode,DataNode是否都存在。
当然worker机器只有DataNode。2
同理停止HDFS就是进入{HADOOP_HOME}目录执行:
$ sbin/stop-dfs.sh
(3.3)使用HDFS
进入{HADOOP_HOME}目录执行:
$ bin/hdfs dfs -help ——可以查看详细的HDFS操作命令和参数,和本地文件操作其实差不多。
【1】列举目录/文件
比如列举根目录/,刚刚格式化完应该是空的,我这个例子中有几个子目录了。
$ bin/hdfs dfs -ls /
Found 4 items
drwxr-xr-x - Shion supergroup 0 2019-04-10 09:19 /testdir0
drwxr-xr-x - Shion supergroup 0 2019-04-08 09:34 /testdir1
drwxr-xr-x - Shion supergroup 0 2019-04-08 10:30 /testdir2
drwxr-xr-x - Shion supergroup 0 2019-04-08 13:45 /testdir3
【2】新建目录
$ bin/hdfs dfs -mkdir /onemoredir
【3】上传文件
$ bin/hdfs dfs -put .txt /onemoredir/
$ bin/hdfs dfs -ls /onemoredir/.txt
-rw-r--r-- 3 Shion supergroup 147145 2019-04-16 12:28 /onemoredir/LICENSE.txt
-rw-r--r-- 3 Shion supergroup 21867 2019-04-16 12:28 /onemoredir/NOTICE.txt
-rw-r--r-- 3 Shion supergroup 1366 2019-04-16 12:28 /onemoredir/README.txt
(3.4)浏览器查看HDFS情况
访问缺省的HDFS的WEB UI,我这儿是:http://shionlnx:9870
可以查看整个HDFS的概述,数据节点的使用情况,以及文件查看以及上传下载等。


(四)启动Spark独立模式集群和运行程序
(4.1)本地模式执行
在启动集群以前,可以通过Scala Shell交互式执行代码。
也可以Submit程序到Local(小数据测试程序挺有用的)
spark-submit #提交程序的指令
--class Word2AuditTest #类名
--master local #本地模式
/somepath/word2audittest_2.11-1.0.jar #jar包
/mnt/hgfs/ShareFolder/br1/cvm/ #程序的第一个参数,本地目录
200 #程序的第二个参数,类推
(4.2)启动Spark独立模式集群
就是Spark standalone cluster,不使用YARN,Mesos。
进入{SPARK_HOME}目录执行:
$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.master.Master-1-shionlnx.out
shion1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-shion1.out
shionlnx: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-shionlnx.out
ac2: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-ac2.out
ac1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-ac1.out
ad1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-ad1.out
ad2: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-1-ad2.out
ac2: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-2-ac2.out
ac1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-2-ac1.out
shion1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-2-shion1.out
ad1: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-2-ad1.out
ad2: starting org.apache.spark.deploy.worker.Worker, logging to /home/Shion/spark/logs/spark-Shion-org.apache.spark.deploy.worker.Worker-2-ad2.out
启动集群以后,就可以将程序提交到集群来执行了,那么刚才那个提交到本地执行的程序,就可以改写成这样:
spark-submit #提交程序的指令
--class Word2AuditTest #类名
--master spark://shionlnx:7077 #集群模式
/somepath/word2audittest_2.11-1.0.jar #jar包
hdfs://shionlnx:9000/testdir2/ #程序的第一个参数,HDFS目录
200 #程序的第二个参数,类推
同理停止Spark集群就是进入{SPARK_HOME}目录执行:
$ sbin/stop-all.sh
(4.3)独立集群提交:部署模式
对于提交任务,spark-submit还有一个参数deploy-mode。
当不指定的时候,缺省是client模式。意思是driver运行在你提交任务的这台主机上。
如果指定了cluster模式,那么driver就会运行在某一台worker主机上。
单个任务的时候感觉区别不大,但是多个任务同时执行时,client模式那台提交任务的主机就要同时运行N个driver。这时候在cluster模式下,driver会自动分配到不同的worker主机,负载更加平衡呢。
官网是这么说的:
--deploy-mode: Whether to deploy your driver on the worker nodes (cluster),
or locally as an external client (client) (default: client)
那么刚才那个提交的例子,就又可以改写成这样:
spark-submit #提交程序的指令
--class Word2AuditTest #类名
--master spark://shionlnx:7077 #独立模式集群
--deploy-mode cluster #集群部署模式driver
hdfs://shionlnx:9000/bin/Word2AuditTest-1.1.jar #jar包
hdfs://shionlnx:9000/testdir2/ #程序的第一个参数,HDFS目录
200 #程序的第二个参数,类推
hdfs://shionlnx:9000/output/ #程序的第三个参数,输出目录
(4.4)查看Spark和程序的状态
【1】控制台输出
用上面的语句提交和执行程序时,控制台输出的信息比较少,因为我们将log4j输出做了设置,只输出告警和错误信息。
当然也可以保持缺省设置INFO级别,那么控制台就会输出全部信息,很多而且难以快速看到想要的信息。
log4j.rootCategory=WARN, console
我设置了这个参数:
spark.ui.showConsoleProgress true
所以控制台输出差不多是这样的(可以看到当前Stage和进度):

20分钟后执行完了:

如果在cluster部署模式下的(–deploy-mode cluster),则因为driver不在本地,命令行会很快返回。
所以这种模式下看不到任何日志和错误输出,需要进入WEB,才能查看Driver的输出信息。
【2】用浏览器访问Spark WEB UI
主页面
访问缺省的Spark的WEB UI,我这儿是:http://shionlnx:8080
可以看到一些基本情况包括Master的地址,Worker数量和列表,核心/内存等等。
下面有正在执行中的程序(应用)。

如果在cluster部署模式下的(–deploy-mode cluster),
则还可以看到正在运行的Driver,这时候的Driver就在一台worker主机上了,并且占用了一个Worker Instance 的Executor的资源。所以如果看运行的APP,就比client部署模式的少一个Executor。

应用(Aplication)页面
点击应用ID,可以看到应用使用的Executor,所属的Worker,
以及输出的日志(在stderr里):
【2】访问应用详情WEB界面
应用详情页面:Jobs
从主页点击应用Name,或者从应用页面点击Application Detail UI,可以进入应用详情网站。
在这个站页面中,一个应用被分为了若干个Job,每个Job又分为几个Stage,每个Stage会分成若干Task:
首先是Jobs页面:

应用详情页面:Stages
然后是Stage页面,点击一个stage旁边的detail,可以看到执行的函数阶段):
应用详情页面:Stage Detail
点击一个Stage的描述文字,可以看到这个Stage的大概流程:
下面是这个Stage已经完成的Task的执行时间,Java资源回收时间,Shuffle读取情况。

也可以展开Event Timeline(事件时间线)仔细查看:

应用详情页面:应用执行环境
这里可以看到Java环境,Spark的各种属性等。
最主要的是可以看到自己设置的一些变量到底设置成功了没有(成功了就会在这里面)。
比如刚才提到的spark.ui.showConsoleProgress,以及我传入的分区参数200:

执行器页面
这里可以看到Executor运行和历史的情况。

(4.5)独立集群的备份高可用性(使用zookeeper)
默认情况下,独立集群对Worker的故障具有弹性(因为Spark可以将工作从断掉的Worker转移到正常Worker上)。 但是,如果调度的Master出现故障,则不能创建新的应用程序。 为了避免这种情况有两个高可用性方案:
- 通过本地文件系统单点恢复。
- 使用zookeeper支持的备用Master。
第一种方式看官方文档就OK了,而zookeeper:
ZooKeeper™ :致力于开发和维护开源服务器,实现高度可靠的分布式协调。
在已经配置好zookeeper的情况下(我在shionlnx+shion1,两台机器上配置了zookeeper。当然考虑到主机故障,其实不应该把zookeeper和spark放一起,但是测试条件有限,将就一下)。
修改shionlnx和shion1主机的spark-env.sh文件。
注释掉SPARK_MASTER_HOST或者SPARK_MASTER_IP,增加下面的项目。
$ vim $SPARK_HOME/conf/spark-env.sh
# export SPARK_MASTER_HOST=shionlnx
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=shionlnx:2181,shion1:2181 -Dspark.deploy.zookeeper.dir=/spark"
然后在shionlnx上正常启动整个集群:
$ $SPARK_HOME/sbin/start-all.sh
然后去shion1上启动一个Master:
$ $SPARK_HOME/sbin/start-master.sh
这时可以看到shion1上的master是standby(准备中)状态。
如果shionlnx上的master没有问题,则它会一直standby。
如果shionlnx上的master崩溃了(为了测试可以故意停掉),则它在几秒钟后就会变成alive状态。
并且可以看到所有的work节点和正在运行的application和driver了。

(4.6)在YARN集群上运行
Spark除了独立集群模式,还可以运行在YARN集群上。
提交任务的命令需要将 master 从 spark 改为 yarn。
那么就不用启动Spark集群了,同时需要保证Yarn集群正常运行中(如下)。
spark-submit #提交程序的指令
--class Word2AuditTest #类名
--master yarn #YARN集群
--deploy-mode cluster #集群部署模式driver
--driver-memory 2g
--executor-memory 2g
--executor-cores 2
hdfs://shionlnx:9000/bin/Word2AuditTest-1.1.jar #jar包
hdfs://shionlnx:9000/testdir2/ #程序的第一个参数,HDFS目录
200 #程序的第二个参数,类推
hdfs://shionlnx:9000/output/ #程序的第三个参数,输出目录
访问Yarn的WEB UI:http://shionlnx:8088/
在Yarn中看到各个节点的资源情况。

在Yarn中看到应用运行列表。(这里的ApplicationMaster,就是Spark Application Detail UI的入口)
在Yarn中看到单个应用运行的情况。

(4.7)在Mesos集群上运行

Mesos:将CPU/内存/存储和其他计算资源从主机中抽象出来,构建成高效的容错和弹性分布式系统。
Spark还可以运行在Mesos集群上:
提交任务的命令需要将 master 从 spark 改为 Mesos。
那么就不用启动Spark集群了,同时需要保证Mesos集群正常运行中。
spark-submit #提交程序的指令
--class Word2AuditTest #类名
--master mesos://shionlnx:5050 #Mesos集群
hdfs://shionlnx:9000/bin/Word2AuditTest-1.1.jar #jar包
hdfs://shionlnx:9000/testdir2/ #程序的第一个参数,HDFS目录
200 #程序的第二个参数,类推
hdfs://shionlnx:9000/output/ #程序的第三个参数,输出目录
上面是client方式提交的,所以启动的控制台能看到运行日志:
可以看到这个临时搭建的集群没有任何授权和凭证。
*** AuditJava JX BOSSvsCRM 1.2 ***
I0424 12:28:28.273195 22215 sched.cpp:232] Version: 1.5.0
I0424 12:28:28.275389 22206 sched.cpp:336] New master detected at [email protected]:5050
I0424 12:28:28.275939 22206 sched.cpp:351] No credentials provided. Attempting to register without authentication
I0424 12:28:28.278688 22206 sched.cpp:751] Framework registered with 8558d550-d3b1-4586-8674-710bb2b22e99-0001
[Stage 7:============================> (105 + 11) / 200]
执行完后:
*** AuditJava JX BOSSvsCRM 1.2 ***
I0424 12:28:28.273195 22215 sched.cpp:232] Version: 1.5.0
I0424 12:28:28.275389 22206 sched.cpp:336] New master detected at [email protected]:5050
I0424 12:28:28.275939 22206 sched.cpp:351] No credentials provided. Attempting to register without authentication
I0424 12:28:28.278688 22206 sched.cpp:751] Framework registered with 8558d550-d3b1-4586-8674-710bb2b22e99-0001
001: 370042
002: 114
存在并不一致: 399004
003: 189745
004: 216903
005: 54
I0424 12:49:54.716717 22157 sched.cpp:2009] Asked to stop the driver
I0424 12:49:54.717633 22208 sched.cpp:1191] Stopping framework 8558d550-d3b1-4586-8674-710bb2b22e99-0001
*** Task done ***
当然Mesos也是可以依靠zookeeper做多master备份的(*更新了一下,例中用zookeeper了)。
Mesos的WEBUI,对于Mesos + zookeeper的方式对用户比较友好,无论你访问哪一个master的地址,都可以看到同样的页面(本身还会自动刷新)。
此例中访问 http://shionlnx:5050 或者 http://shion1:5050 都可以看到Leader为shionlnx:5050的界面。
首页能看到在Mesos中整体的资源情况,以及运行的框架(和分解的任务)。

正在执行的框架的资源情况。

连接上Master的代理(各种不同的用词啊,Worker,Slave,Agent)

正在执行的一个应用的情况,包括资源,任务分解,
以及Spark的WEB UI(相当于Spark独立模式里面的 Application Detail UI)

一个应用各个任务的运行(沙盒)信息。

从一个代理的角度查看资源情况,运行的框架情况。

部署模式
运行在Mesos集群下和运行在Spark独立集群模式下一样,有两种部署模式。
上面看到的都是Client部署模式,也就是Driver运行在本机的模式。
如果需要Driver运行在集群,则也需要使用Cluster部署模式。
这时需要先启动{SPARK_HOME}下的:sbin/start-mesos-dispatcher.sh,
并带上参数–master mesos://shionlnx:5050
spark-submit
--class com.ac.Word2AuditTest
--master mesos://shionlnx:7077 #通过dispatcher
--deploy-mode cluster #集群部署模式
--supervise #如果失败就重启driver
--conf spark.master.rest.enabled=true #没有这一行会报错。。。
hdfs://shionlnx:9000/bin/Word2AuditTest-1.1.jar #程序
hdfs://shionlnx:9000 #参数1
/testdir2/ #参数2
/output/ #参数3
200 #参数4
这时可以在Mesos中看到启动的Framework里面,有driver了:
*hint:不好意思有这么多失败的尝试,具体问题可以看最后一章

并且可以看到Spark Drivers for Mesos Cluser(运行在Mesos上的Spark Drivers列表)

以及每个Driver的详细情况。

(五)三种语言编写示例
(5.1)Python与执行环境
【1】编译环境
Python程序不用编译,需要使用Spark的API:
from pyspark.sql import SparkSession
...
spark = SparkSession.builder.appName("应用的名字").getOrCreate()
...
【2】用Spark-submit提交
提交的方式也稍微不一样,不需要指定类名,直接提交文件就OK。
官网的例子:
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
【3】单独执行程序
单独执行只需要 ./appname.py 就可以了。
前提是Python的环境有PySpark。
当然也可能pip都没有,那么就yum install咯。
# pip install pyspark
然后程序中得指明spark的master(测试才写死,正常可以用参数或者配置文件的形式啊。)
spark = SparkSession.builder
.master("spark://shionlnx:7077")
.appName("AuditPython_JX_BOSSvsCRM_5.6a")
.getOrCreate()
【4】更多内容请自行了解
关于Python本身,或者pip,setup.py就请自行了解吧,spark相关内容可以多看看spark官网。
(5.2)Scala与执行环境
【1】编译环境
Scala程序最终编译成个jar包,需要sbt,官网:https://www.scala-sbt.org/
sbt = simple build tool ,是Scala, Java的编译工具。
# yum install sbt
比较烦的是sbt貌似服务器被天朝的网络限制了。。。
所以yum install sbt后,第一次执行sbt指令,会一直停在那没反应。
我试过网上的教程,配置~/.sbt/repositories,设为国内阿里源。但是第一次sbt中途会报错???
[repositories]
local
ali: https://maven.aliyun.com/repository/public/
于是我从sbt官网下载了安装包sbt-1.2.8.tgz,
发现比yum安装的多一个lib/local-preloaded。。。
最后通过官网的安装包+阿里源(repository)总算是成功安装了。
【2】项目代码/结构/打包
官网写得很清楚,首先是项目目录结构:
# 你的项目目录结构应类似这样
$ find .
.
./build.sbt
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
然后是用sbt进行打包:
# 在你的项目目录中执行,打包成jar
$ sbt package
...
[info] Packaging {
..}/{
..}/target/scala-2.12/simple-project_2.12-1.0.jar
然后向spark提交程序:
# 用spark-submit运行你的程序
$ YOUR_SPARK_HOME/bin/spark-submit \
--class "SimpleApp" \
--master local[4] \
target/scala-2.12/simple-project_2.12-1.0.jar
其中build.sbt内容类似这样:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.8"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.1"
scala文件中必要的代码大概如下(为啥CSDN不高亮scala):
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.PairRDDFunctions
...
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
(5.3)Java与执行环境
【1】编译环境
Spark官网写的用maven
# yum install maven
【2】项目代码/结构/打包
官网写得很清楚,首先是项目目录结构:
# 你的项目目录结构应类似这样
$ find .
./pom.xml
./src
./src/main
./src/main/java
./src/main/java/SimpleApp.java
然后是用maven进行打包:
# 在你的项目目录中执行,打包成jar
$ mvn package
...
[INFO] Building jar: {
..}/{
..}/target/simple-project-1.0.jar
然后向spark提交程序:
# 用spark-submit运行你的程序
$ YYOUR_SPARK_HOME/bin/spark-submit \
--class "SimpleApp" \
--master local[4] \
target/simple-project-1.0.jar
...
其中pom.xml内容类似这样:
<project>
<groupId>edu.berkeley</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
Java文件中必要的代码大概如下:
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
...
SparkSession spark = SparkSession.builder().appName("Simple Application").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
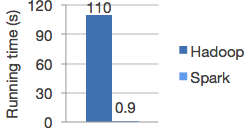
(5.4)测试项目1:GZ_GPRS
GZ_GPRS数据稽核,
BOSS文件格式:ISDN vs HSS文件格式:ISDN|IMSI,
双方共5000w记录,进行存在性稽核。
由于数据量比较小,Win单机32位程序都可以一次性处理,所以仅参考吧。
Spark稽核项结果和一直在用的Windows业务规则输出是一致的。
| 程序类型 | 处理时间 | 单位 |
|---|---|---|
| Windows 单机单进程 | 2 | 分钟 |
| Java@Spark | 2 | 分钟 |
| Scala@Spark | 2.7 | 分钟 |
| Python@Spark | 11 | 分钟 |


(5.5)测试项目2:JX_BOSS/CRM
JX_BOSS/CRM数据稽核,
双方文件格式都是custID|custName|regNbr|regionCode,
双方共27000w记录,
进行存在性稽核,三个子项的差异性稽核。
字段稍长,Win单机64位程序,需要自动拆分3次完成,内存使用峰值12GB多点。
Spark稽核项结果和一直在用的Windows业务规则输出也是一致的。
| 程序类型 | 处理时间 | 单位 |
|---|---|---|
| Windows 单机单进程 | 47 | 分钟 |
| Java@Spark | 20 | 分钟 |
| Scala@Spark | 20 | 分钟 |
| Python@Spark | 84 | 分钟 |
【1】测试项目2:Python源代码
可以命令行直接运行:
#!/usr/bin/python
#coding:utf-8
#
from __future__ import print_function
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
print("*** AuditPython JX BOSSvsCRM 5.6 ***")
if len(sys.argv) < 2:
print("Usage: AuditPython_JX_BOSSvsCRM <HDFS.Path.With/>", file=sys.stderr)
sys.exit(-1)
sparkB = SparkSession.builder.master("spark://shionlnx:7077").appName("AuditPython_JX_BOSSvsCRM_5.6b")
if len(sys.argv) >= 3:
sparkB.config("spark.default.parallelism",sys.argv[2])
spark=sparkB.getOrCreate()
dfboss = spark.read.csv(sys.argv[1]+'zk.cm_customer*.txt',sep='|', encoding='GBK')
rddboss = dfboss.rdd.map(lambda r: (r[0],(r[1],r[2],r[3]))).reduceByKey(lambda x, y: x)
dfhss = spark.read.csv(sys.argv[1]+'zg.crm_customer*.txt',sep='|', encoding='GBK')
rddhss = dfhss.rdd.map(lambda r: (r[0],(r[1],r[2],r[3]))).reduceByKey(lambda x, y: x)
out_b_s = rddboss.fullOuterJoin(rddhss)
g001=0
f001 = open('/mnt/hgfs/ShareFolder/C_CUSTOMER_001_P.TXT', "w")
output001 = out_b_s.filter(lambda k: k[1][1]==None).collect()
for (k,(v1,v2)) in output001:
f001.write("%s|%s|%s|%s\n" % (k,v1[0],v1[1],v1[2]))
g001+=1
f001.close()
g002=0
f002 = open('/mnt/hgfs/ShareFolder/C_CUSTOMER_002_P.TXT', "w")
output002 = out_b_s.filter(lambda k: k[1][0]==None).collect()
for (k,(v1,v2)) in output002:
f002.write("%s|%s|%s|%s\n" % (k,v2[0],v2[1],v2[2]))
g002=g002+1
f002.close()
g0xx=0
g003=0
g004=0
g005=0
f003 = open('/mnt/hgfs/ShareFolder/C_CUSTOMER_003_P.TXT', "w")
f004 = open('/mnt/hgfs/ShareFolder/C_CUSTOMER_004_P.TXT', "w")
f005 = open('/mnt/hgfs/ShareFolder/C_CUSTOMER_005_P.TXT', "w")
output003 = out_b_s.filter(lambda k: k[1][0]!=None and k[1][1]!=None and k[1][0]!=k[1][1]).collect()
for (k,(v1,v2)) in output003:
if v1[0]!=v2[0]:
f003.write("%s|%s|%s\n" % (k,v1[0],v2[0]))
g003=g003+1
if v1[1]!=v2[1]:
f004.write("%s|%s|%s\n" % (k,v1[1],v2[1]))
g004=g004+1
if v1[2]!=v2[2]:
f005.write("%s|%s|%s\n" % (k,v1[0],v2[0]))
g005=g005+1
g0xx=g0xx+1
f003.close()
f004.close()
f005.close()
print("001: %i" % g001)
print("002: %i" % g002)
print("存在并不一致: %i" % g0xx)
print("003: %i" % g003)
print("004: %i" % g004)
print("005: %i" % g005)
vlog = open('/mnt/hgfs/ShareFolder/CvB_SparkPythonLog.log', "w")
vlog.write("001: %i\n" % g001)
vlog.write("002: %i\n" % g002)
vlog.write("存在并不一致: %i\n" % g0xx)
vlog.write("003: %i\n" % g003)
vlog.write("004: %i\n" % g004)
vlog.write("005: %i\n" % g005)
vlog.close()
spark.stop()
print("*** Application jod done ***")
【2】测试项目2:Scala源代码
需要提交运行:
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.PairRDDFunctions
import java.io.PrintWriter
import java.io.File
object Word2AuditTest {
def main(args: Array[String]) {
println("*** AuditScala JX BOSSvsCRM 1.2 ***")
if (args.length < 1) {
System.err.println("Usage: AuditScala_JX_BOSSvsCRM <HDFS.Path.With/>")
System.exit(1)
}
val aPath = args(0)
val sparkB = SparkSession
.builder
.appName("AuditScala_JX_BOSSvsCRM_1.2")
if (args.length >= 2) {
sparkB.config("spark.default.parallelism",args(1))
}
val spark =sparkB
.getOrCreate()
val dfboss = spark.read
.option("sep","|")
.option("encoding","GBK")
.csv(aPath+"zk.cm_customer*.txt")
val rddboss = dfboss.rdd.map(row => (row(0),(row(1),row(2),row(3)))).reduceByKey((x,y)=>(x))
val dfhss = spark.read
.option("sep","|")
.option("encoding","GBK")
.csv(aPath+"zg.crm_customer*.txt")
val rddhss = dfhss.rdd.map(row => (row(0),(row(1),row(2),row(3)))).reduceByKey((x,y)=>(x))
val out_b_s = rddboss.fullOuterJoin(rddhss)
var g001 = 0
val f001 = new PrintWriter("/mnt/hgfs/ShareFolder/C_CUSTOMER_001_S.TXT")
val output1 = out_b_s
.filter(_._2._2==None)
.collect()
for ((word,(value1,value2)) <- output1) {
val (v10,v11,v12) = value1.get;
f001.println(s"$word|$v10|$v11|$v12")
g001=g001+1
}
f001.close()
var g002 = 0
val f002 = new PrintWriter("/mnt/hgfs/ShareFolder/C_CUSTOMER_002_S.TXT")
val output2 = out_b_s
.filter(_._2._1==None)
.collect()
for ((word,(value1,value2)) <- output2) {
val (v10,v11,v12) = value2.get;
f002.println(s"$word|$v10|$v11|$v12")
g002=g002+1
}
f002.close()
var g0xx=0
var g003 = 0
var g004 = 0
var g005 = 0
val f003 = new PrintWriter("/mnt/hgfs/ShareFolder/C_CUSTOMER_003_S.TXT")
val f004 = new PrintWriter("/mnt/hgfs/ShareFolder/C_CUSTOMER_004_S.TXT")
val f005 = new PrintWriter("/mnt/hgfs/ShareFolder/C_CUSTOMER_005_S.TXT")
val output3 = out_b_s
.filter(v => (v._2._1!=None && v._2._2!=None && v._2._2!=v._2._1))
.collect()
for ((word,(value1,value2)) <- output3) {
val (v10,v11,v12) = value1.get;
val (v20,v21,v22) = value2.get;
if (v10!=v20) {
f003.println(s"$word|$v10|$v20")
g003=g003+1
}
if (v11!=v21) {
f004.println(s"$word|$v11|$v21")
g004=g004+1
}
if (v12!=v22) {
f005.println(s"$word|$v12|$v22")
g005=g005+1
}
g0xx=g0xx+1
}
f003.close()
f004.close()
f005.close()
println(s"001: $g001")
println(s"002: $g002")
println(s"存在并不一致: $g0xx")
println(s"003: $g003")
println(s"004: $g004")
println(s"005: $g005")
val flog = new PrintWriter("/mnt/hgfs/ShareFolder/CvB_SparkScalaLog.log")
flog.println(s"001: $g001")
flog.println(s"002: $g002")
flog.println(s"存在并不一致: $g0xx")
flog.println(s"003: $g003")
flog.println(s"004: $g004")
flog.println(s"005: $g005")
flog.close()
spark.stop()
println("*** Task done ***")
}
}
【3】测试项目2:Java源代码
需要提交运行:
*Hint1:Java源代码已经更新,已适应cluster部署模式提交。
*Hint2:如果需要直接运行,请看最下面的问题列表。
package com.ac;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.Optional;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.io.OutputStreamWriter;
import java.net.URI;
import java.util.Arrays;
import java.util.List;
public final class Word2AuditTest {
private static FileSystem getFileSystem(String ahdfs) throws Exception {
return FileSystem.get(new URI(ahdfs),new Configuration());
}
public static void main(String[] args) throws Exception {
System.out.println("*** AuditJava JX BOSSvsCRM 1.2 ***");
if (args.length < 3) {
System.err.println("Usage: Word2AuditTest <HDFS> <Pathin/> <Pathout/> [ParaNum]");
System.exit(1);
}
String aPath = args[0]+args[1];
String aOutPath = args[0]+args[2];
SparkSession.Builder sparkB = SparkSession
.builder()
.appName("AuditJava_JX_BOSSvsCRM_1.2");
if (args.length >= 4) {
sparkB.config("spark.default.parallelism", args[3]);
}
SparkSession spark = sparkB.getOrCreate();
JavaRDD<Row> dfboss = spark.read()
.option("sep", "|")
.option("encoding", "GBK")
.csv(aPath + "zk.cm_customer*.txt")
.javaRDD();
JavaPairRDD<String, String[]> rddboss = dfboss
.mapToPair(s ->
new Tuple2<>(s.getString(0), new String[]{
s.getString(1), s.getString(2), s.getString(3)})
)
.reduceByKey((i1, i2) -> i1);
JavaRDD<Row> dfhss = spark.read()
.option("sep", "|")
.option("encoding", "GBK")
.csv(aPath + "zg.crm_customer*.txt")
.javaRDD();
JavaPairRDD<String, String[]> rddhss = dfhss
.mapToPair(s ->
new Tuple2<>(s.getString(0), new String[]{
s.getString(1), s.getString(2), s.getString(3)})
)
.reduceByKey((i1, i2) -> i1);
JavaPairRDD<String, Tuple2<Optional<String[]>, Optional<String[]>>> out_b_s = rddboss.fullOuterJoin(rddhss);
FileSystem fs = getFileSystem(args[0]);
int g001 = 0;
FSDataOutputStream oFf001 = fs.create(new Path(String.format("%sC_CUSTOMER_001_J.TXT", aOutPath)));
OutputStreamWriter oF001 = new OutputStreamWriter(oFf001);
List<Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>>> output1 = out_b_s.filter(s -> !s._2()._2().isPresent()).collect();
for (Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>> tuple : output1) {
if (tuple._1().length() != 0) {
oF001.write(String.format("%s|%s|%s|%s\n", tuple._1(), tuple._2()._1().get()[0], tuple._2()._1().get()[1], tuple._2()._1().get()[2]));
g001++;
}
}
oF001.close();
int g002 = 0;
FSDataOutputStream oFf002 = fs.create(new Path(String.format("%sC_CUSTOMER_002_J.TXT", aOutPath)));
OutputStreamWriter oF002 = new OutputStreamWriter(oFf002);
List<Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>>> output2 = out_b_s.filter(s -> !s._2()._1().isPresent()).collect();
for (Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>> tuple : output2) {
if (tuple._1().length() != 0) {
oF002.write(String.format("%s|%s|%s|%s\n", tuple._1(), tuple._2()._2().get()[0], tuple._2()._2().get()[1], tuple._2()._2().get()[2]));
g002++;
}
}
oF002.close();
int g0xx = 0;
int g003 = 0;
int g004 = 0;
int g005 = 0;
FSDataOutputStream oFf003 = fs.create(new Path(String.format("%sC_CUSTOMER_003_J.TXT", aOutPath)));
OutputStreamWriter oF003 = new OutputStreamWriter(oFf003);
FSDataOutputStream oFf004 = fs.create(new Path(String.format("%sC_CUSTOMER_004_J.TXT", aOutPath)));
OutputStreamWriter oF004 = new OutputStreamWriter(oFf004);
FSDataOutputStream oFf005 = fs.create(new Path(String.format("%sC_CUSTOMER_005_J.TXT", aOutPath)));
OutputStreamWriter oF005 = new OutputStreamWriter(oFf005);
List<Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>>> output3 = out_b_s.filter(s
-> s._2()._1().isPresent()
&& s._2()._2().isPresent()
&& !Arrays.equals(s._2()._1().get(), s._2()._2().get())
).collect();
for (Tuple2<String, Tuple2<Optional<String[]>, Optional<String[]>>> tuple : output3) {
if (!StringUtils.equals(tuple._2()._1().get()[0], tuple._2()._2().get()[0])) {
oF003.write(String.format("%s|%s|%s\n", tuple._1(), tuple._2()._1().get()[0], tuple._2()._2().get()[0]));
g003++;
}
if (!StringUtils.equals(tuple._2()._1().get()[1], tuple._2()._2().get()[1])) {
oF004.write(String.format("%s|%s|%s\n", tuple._1(), tuple._2()._1().get()[1], tuple._2()._2().get()[1]));
g004++;
}
if (!StringUtils.equals(tuple._2()._1().get()[2], tuple._2()._2().get()[2])) {
oF005.write(String.format("%s|%s|%s\n", tuple._1(), tuple._2()._1().get()[2], tuple._2()._2().get()[2]));
g005++;
}
g0xx++;
}
oF003.close();
oF004.close();
oF005.close();
System.out.printf("001: %d\n", g001);
System.out.printf("002: %d\n", g002);
System.out.printf("存在并不一致: %d\n", g0xx);
System.out.printf("003: %d\n", g003);
System.out.printf("004: %d\n", g004);
System.out.printf("005: %d\n", g005);
FSDataOutputStream fflog = fs.create(new Path(String.format("%sCvB_SparkJavaLog.log", aOutPath)));
OutputStreamWriter flog = new OutputStreamWriter(fflog);
flog.write(String.format("001: %d\n", g001));
flog.write(String.format("002: %d\n", g002));
flog.write(String.format("存在并不一致: %d\n", g0xx));
flog.write(String.format("003: %d\n", g003));
flog.write(String.format("004: %d\n", g004));
flog.write(String.format("005: %d\n", g005));
flog.close();
spark.stop();
System.out.println("*** Task done ***");
}
}
(六)出现问题和解决的记录
(6.1)分区数与executor内存不足
关键参数:spark.default.parallelism
官网文档说明:
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user.
缺省取值说明:
For distributed shuffle operations like reduceByKey and join, the largest number of partitions in a parent RDD. For operations like parallelize with no parent RDDs, it depends on the cluster manager:
- Local mode: number of cores on the local machine
- Mesos fine grained mode: 8
- Others: total number of cores on all executor nodes or 2, whichever is larger
通过无数报错和测试,发现如果数据很大时,分区数会远远大于executor的核心数。具体的数值个人感觉应该是Spark通过输入文件的大小估算的。
输入文件和实际加载到内存中的数据其实并无绝对关联,所以如果估算得不够,那么就可能造成下面的各种内存不足或者通信失败的错误。3
许多文章提到的另一个参数 spark.sql.shuffle.partitions,在官方最新文档2.4.1里面没有找到,不知道是不是取消了。毕竟Spark发展的方向时更加自动的处理。
【1】java.lang.OutOfMemoryError:GC overhead limit exceeded
通过统计GC时间来预测是否要OOM了,提前抛出异常,防止OOM发生。
Sun 官方对此的定义是:并行/并发回收器在GC回收时间过长时会抛出OutOfMemroyError。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存。用来避免内存过小造成应用不能正常工作。
简单说就是一个Out of memory的预警异常,我们可以通过在spark-defaults.conf中:
spark.executor.extraJavaOptions -XX:-UseGCOverheadLimit
把它关掉。当然关掉最可能的后果就是。。。Out of memory。
先看看程序有没有什么问题,排除代码的问题后,就需要考虑是不是分区不够,或者Executor内存分配得太小了。当然Driver内存不足也会报类似的错误,参考前后文可以看出到底是谁在报。
可以适当的增加二者内存的配置。但是注意不要超过物理内存了(我的Master兼做worker就是不小心设错,逼近了物理内存的极限,所以有一阵跑比较大的数据时总是报此类内存不足的错误)
【2】java.lang.OutOfMemoryError: Java heap space
内存不足的另一个表现,可能是Executor或者Driver内存不足。
【3】Issue communicating with driver in heartbeater…: Exception thrown in awaitResult:
由于内存问题造成各种其它问题之一Executor到Driver的心跳信号超时。。。
【4】内存不足时Master控制台未输出报错信息,但结果不正确
这个嘛……真的有点过分了。
不过当分区数设置够了以后,结果每次都正确了。
(6.2)数据返回driver内存不足
类似下面的错误:
Uncaught exception in thread task-result-getter-0
java.lang.OutOfMemoryError: GC overhead limit exceeded
避免它貌似除了增加Driver的内存,就只有减小collect返回的数量了。
那么如果我的确需要返回一个特别大的结果集,怎么办呢???
(6.3)找不到文件的各种原因
开始运行Spark示例程序的时候,我们通常用Spark本地模式,文件路径也是本地路径。
等需要提交到Spark独立集群时就会因为workers上没有路径而报错。
解决办法:
- 用HDFS
- 保证每一台主机拥有同样的目录/文件结构(是不是很傻)
当我们想用cluster部署方式提交到Spark集群时,又会因为driver所在的worker主机找不到程序jar文件。。。
解决办法同样如上。
同理完全集群的方式下,日志文件等都需要放入HDFS,也就是说不要出现任何本机目录了。
(6.4)不提交(Spark-Submit)直接执行程序
考虑到业务系统调度引擎等因素,希望程序能直接运行,而不是只能通过spark-submit。
*提示:如果直接运行,则无法使用集群部署模式(传配置参数也不行),也就是说程序本体(drivier)只能执行在运行命令行的主机上,道理也非常明显,你都用命令行执行程序了,它还能上哪儿呢。
Python程序貌似只要设好Spark Master,就可以直接运行。
$ ./appname.py
而scala和java的jar包却没有那么简单。
提交执行正常的程序,用命令行执行却报错,我遇到的主要几个错误如下:
$ java -jar appname.jar …params…
【1】找不到主类,找不到各种依赖的包…
首先主类mainClass需要指定。
而且似乎直接执行的环境不是spark的java环境,而是系统的java环境。
所以maven打包时候需要修改pom.xml,增加这么一个plugin配置项块。
如下这样才能执行,同时打包出来的jar就不是几kb,而是100多mb了。。。
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>你程序的主类的名字</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
【2】java.io.IOException: No FileSystem for scheme: hdfs …
上网查原因好像是依赖的包重名,被打包成jar时打少了。
解决办法是下面两句,而且需要在spark.read()前执行getFileSystem:
private static FileSystem getFileSystem(String ahdfs) throws Exception {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hadoop.user"); //增加的语句
configuration.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); //增加的语句
return FileSystem.get(new URI(ahdfs),configuration);
}
【3】java.lang.ClassCastException:cannot assign instance of java.lang.invoke.SerializedLambda to …
上网查原因好像是分发到的worker无法解析lambda表达式(为啥spark-submit可以???)。
解决办法是在SparkSession.Builder里面加SparkConf的setJars,当然如果直接用的是SparkConf那么就只有一句。
SparkConf scf = new SparkConf();
scf.setJars(new String[]{
"hdfs://shionlnx:9000/bin/Word2AuditTest-1.1.jar"}); //代码中指定自己jar的位置,不奇怪么?
sparkB.config(scf);
(6.5)Spark on Mesos - Cluster Deploy
【1】assertion failed: Mesos cluster mode is only supported through the REST submission API
需要在spark-submit的时候增加参数:–conf spark.master.rest.enabled=true
【2】Failed to create HDFS client: Hadoop client is not available
以及类似的访问HDFS时找不到Hadoop的错误。
需要在Mesos的每个Agent配置环境变量:hadoop_home=/home/Shion/hadoop
以我的版本为例子则是:
# vim /etc/mesos/mesos-agent-env.sh
增加这么一行:
export MESOS_hadoop_home=/home/Shion/hadoop
其它版本Mesos可能不一样。
本文为工作内容记录,会不定期的修改,
不要着急,更多的内容,待继续补充……