本文参考学习Java并发编程的艺术
第5章 Java中的锁
5.1 Lock接口
- synchronized没有的特性
- 尝试非阻塞获取锁
- 能够中断获取锁
- 超时获取锁

5.2 队列同步器
- 队列同步器AbstractQueuedSynchronizer用来构建锁,或者其它同步组件。用一个int成员变量表示同步状态。通过内置的FIFO队列完成资源获取线程的排队工作。
- 同步器的实现主要是继承,同步器需要提供(getState()、setState(int newState)和compareAndSetState(int expect,int update))方法来获取同步的状态。
- 同步器支持独占或者是共享地获取锁。
5.2.1 队列同步器的接口与示例
- 同步器的实现基于模板方法。继承并重写。
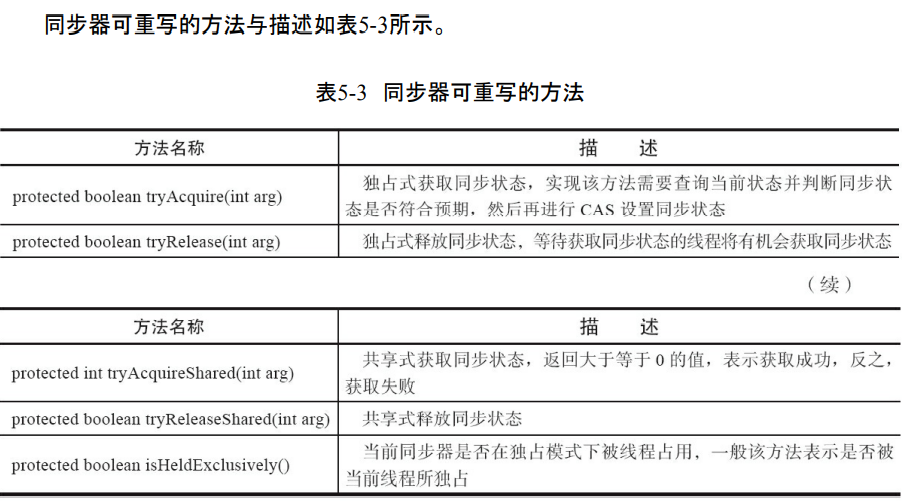
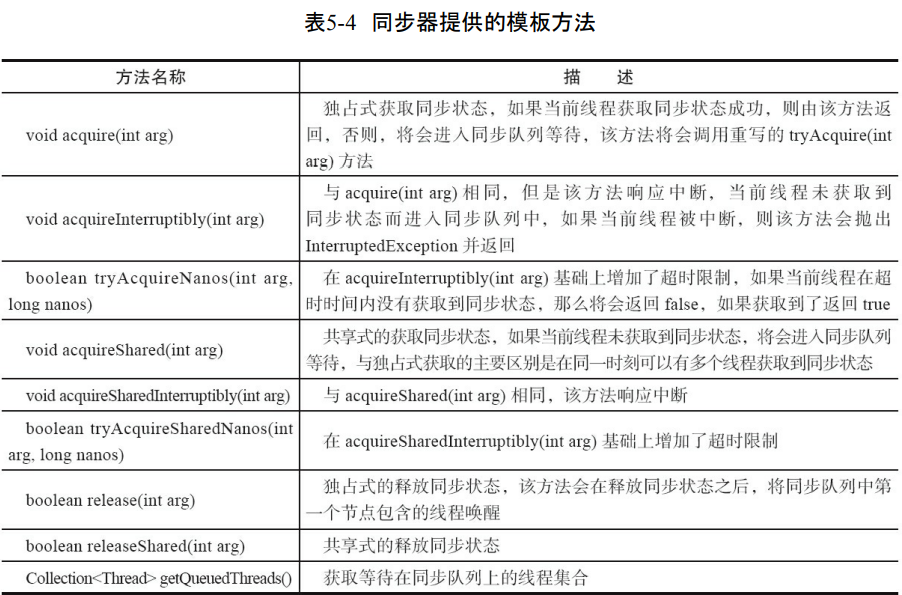
- 模板方法包括3类,独占式的获取和释放同步状态,共享式的获取和释放同步状态,查询同步队列的等待状态线程情况。
通过独占锁来说明情况
- 独占锁只能一个线程获取锁。其它线程只能进入到同步队列。
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
class Mutex implements Lock {
// 静态内部类,自定义同步器
private static class Sync extends AbstractQueuedSynchronizer {
// 是否处于占用状态
protected boolean isHeldExclusively() {
return getState() == 1;
}
// 当状态为0的时候获取锁
public boolean tryAcquire(int acquires) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 释放锁,将状态设置为0
protected boolean tryRelease(int releases) {
if (getState() == 0) throw new
IllegalMonitorStateException();
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// 返回一个Condition,每个condition都包含了一个condition队列
Condition newCondition() {
return new ConditionObject(); }
}
// 仅需要将操作代理到Sync上即可
private final Sync sync = new Sync();
public void lock() {
sync.acquire(1); }
public boolean tryLock() {
return sync.tryAcquire(1); }
public void unlock() {
sync.release(1); }
public Condition newCondition() {
return sync.newCondition(); }
public boolean isLocked() {
return sync.isHeldExclusively(); }
public boolean hasQueuedThreads() {
return sync.hasQueuedThreads(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
- 上面的Mutex只有在tryAcquire的CAS设置成功才能够说明获取了同步状态。
- tryRelease把同步状态设置为0。
- 获取状态失败就会进入到阻塞队列。
5.2.2 队列同步器的实现分析
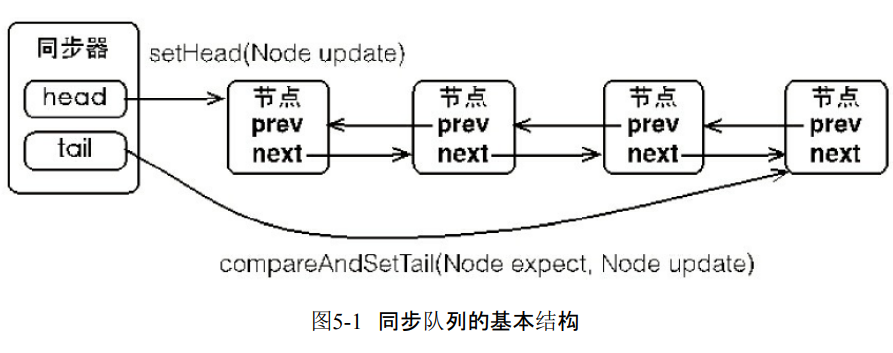
1.同步队列
- 同步器依赖内部的同步队列完成同步状态管理。线程获取同步状态失败,同步器就会把当前的线程以及等待状态信息构成节点Node存入到同步队列。
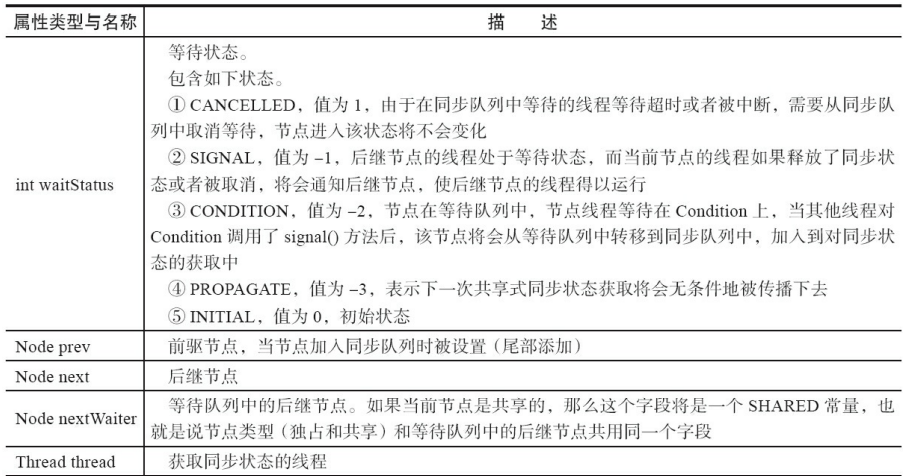
- 节点是构成队列的基础,有首尾节点。如果线程没有获取同步状态成功就会进入到队列的尾部
- 加入到尾部的时候一定要是一个线程安全的状态,所以有方法compareAndSetTail(Node expect,Node update)。
- 每次唤醒都是先从头部开始。
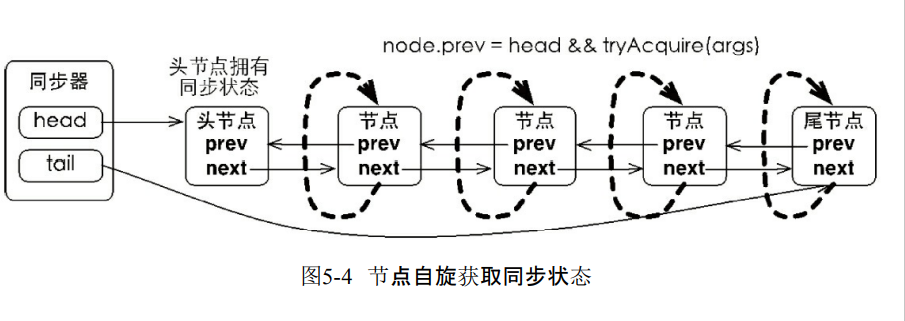
2.独占式同步状态获取与释放
- 同步器acquire(int arg)可以去获取同步状态。对中断不敏感。也就是线程不会从同步队列中移出去。
- 首先是调用tryAcquire(int arg)保证线程安全获取同步状态。
- 如果失败构造同步节点Node.EXCLUSIVE,并且通过addWaiter(Node node)加入到同步队列的尾部。
- 再通过acquireQueued(Node node,int arg)进入死循环获取同步状态。
- 只有前驱的节点头才能够获取同步状态
- 头结点获取同步状态的节点,释放之后会唤醒下一个节点
- 维护FIFO原则。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
- compareAndSetTail(Node expect,Node update)保证了节点线程安全加入。enq通过死循环保证节点被正确添加。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 快速尝试在尾部添加
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) {
// Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
- acquireQueued(final Node node,int arg)死循环获取同步状态。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
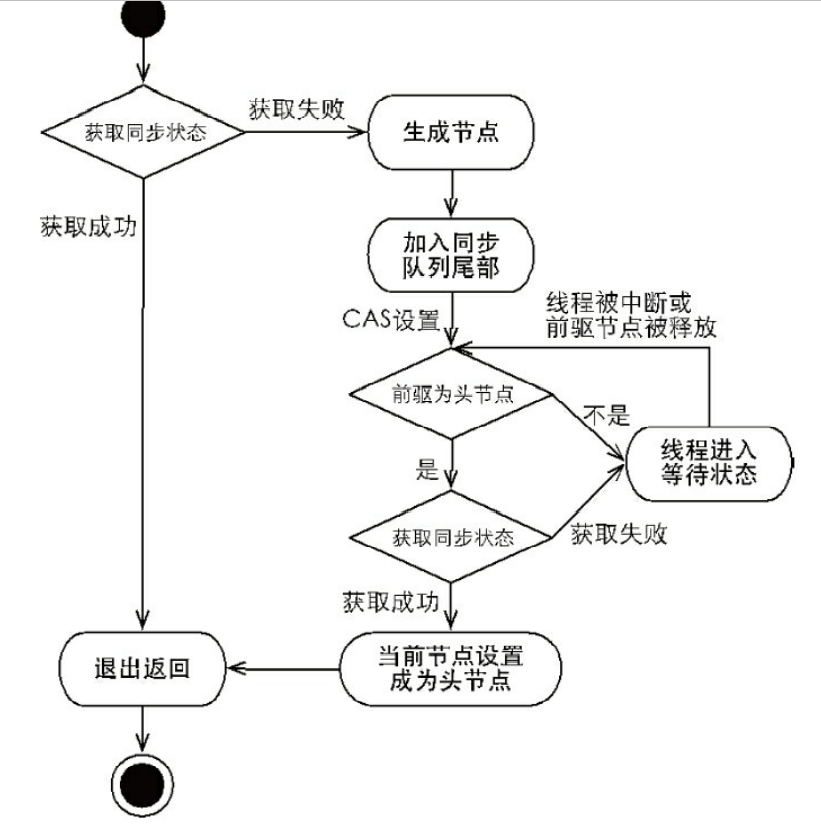
- 接着就是release,唤醒头结点后面的一个节点
3.共享式同步状态获取与释放
- 共享锁可以多线程获取同步状态。
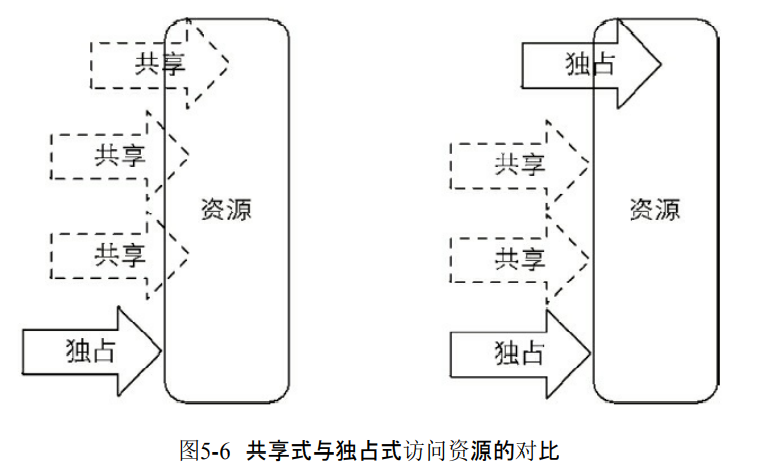
- acquireShared(int arg)共享式获取同步状态。
- 同步器调用tryAcquireShared(int arg)来获取同步状态,返回值大于等于0说明获取成功。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null;
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
4.独占式超时获取同步状态
- 可以通过调用同步器的doAcquireNanos(int arg,long nanosTimeout)可以超时获取同步状态。
- 如果是调用了acquireInterruptibly(int arg),那么只要线程被中断就会报InterruptedException。
- 但是doAcquireNanos(int arg,long nanosTimeout)能够中断,而且可以计算出需要睡眠的时间。nanosTimeout-=now-lastTime如果是大于0说明还没有超时。否则就是超时了。
- 如果 nanosTimeout小于等于spinForTimeoutThreshold(1000纳秒)的时候,线程就不会进入到超时等待了。而是进入到快速自旋。直到超时。
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
long lastTime = System.nanoTime();
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
if (nanosTimeout <= 0)
return false;
if (shouldParkAfterFailedAcquire(p, node)
&& nanosTimeout > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
long now = System.nanoTime();
//计算时间,当前时间now减去睡眠之前的时间lastTime得到已经睡眠
//的时间delta,然后被原有超时时间nanosTimeout减去,得到了
//还应该睡眠的时间
nanosTimeout -= now - lastTime;
lastTime = now;
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
5.3 重入锁
- 支持一个线程多次获取锁。
- 公平锁效率未必比非公平的高。
1.实现重进入
- 线程再次获取锁,需要锁去识别当前获取锁的线程是不是和锁的持有线程一样。
- 锁的释放,要求的就是计数重复获取锁的数量减低为0。
- 下面的方法就增加了线程的判断。增加了同步状态的值。
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
- 同样要求在释放的时候,减去状态的值。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
2.公平与非公平获取锁的区别
- 锁是公平那么一定符合FIFO请求的绝对时间顺序。
- 对于非公平锁来说只要CAS成功,那么就算是同步状态成功。
- 对于公平锁,每次获取锁的时候还需要判断队列是不是有线程等待,才能够获取。
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
- 非公平锁只要CAS状态成功就算是获取锁,所以可能会导致一个线程连续获取锁。
- 而且公平锁每次获取锁的线程不同每次都要切换,但是非公平锁可以连续一个线程获取锁,减少切换的成本。
5.4 读写锁
- 读写锁允许同一个时刻多个读线程访问。
- 读写锁维护了一对锁。
- ReentrantReadWriteLock的特性
- 公平性选择:支持公平和非公平获取
- 可重入
- 锁降级
5.4.1 读写锁的接口与示例

5.4.2 读写锁的实现分析
1.读写状态的设计
- 同样是依靠同步器实现同步的功能。
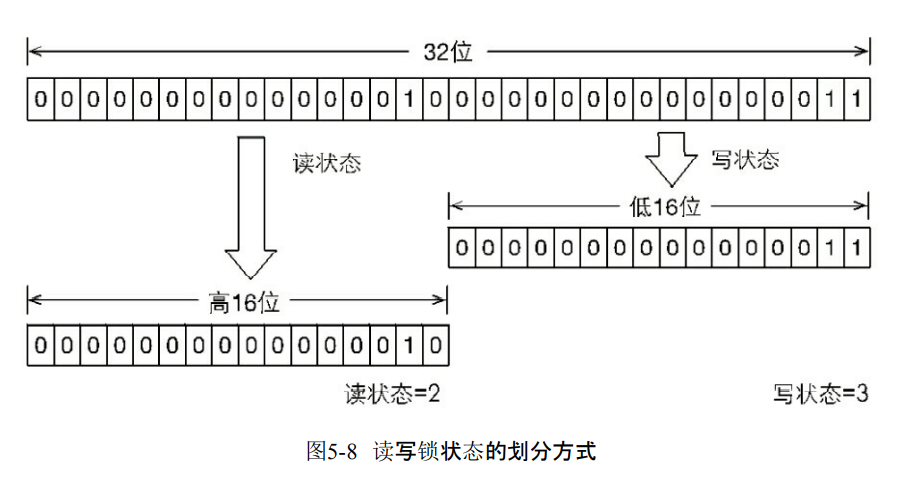
- 维护读写锁的同步状态有多个状态。所以通过按位切割使用。高16位是读,低16位是写。
- 当前的同步状态是读锁被同一个线程获取了写锁,重入了两次,而且还获取了两次读锁。
2.写锁的获取与释放
-
写锁是支持可重入的排它锁。
-
如果当前线程获取了写锁,那么就增加写状态,如果当前线程在获取写锁时,读锁已经被获取或者该线程不是已经获取写锁的线程,那么线程进入到等待状态。
-
这里除了判断可重入,还判断是否存在读锁。如果存在读锁,那么写锁就不能被获取。
-
因为读写锁需要保证写锁的操作对读锁是可见的。因为读锁被获取的状况,去获取写锁,那么当前运行的线程是没有办法感知当前写线程的操作。
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// 存在读锁或者当前获取线程不是已经获取写锁的线程
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
setState(c + acquires);
return true;
}
if (writerShouldBlock() || !compareAndSetState(c, c + acquires)) {
return false;
}
setExclusiveOwnerThread(current);
return true;
}
3.读锁的获取与释放
- 支持可重入的共享锁。
- 能被多个线程获取,在没有别的写线程访问的情况下,读锁会被成功获取。
- 如果当前线程已经获取了读锁,那么就增加读状态。
- 如果当前线程获取读锁的时候,发现写锁被获取,那么就会进入到等待状态。
protected final int tryAcquireShared(int unused) {
for (;;) {
int c = getState();
int nextc = c + (1 << 16);
if (nextc < c)
throw new Error("Maximum lock count exceeded");
if (exclusiveCount(c) != 0 && owner != Thread.currentThread())
return -1;
if (compareAndSetState(c, nextc))
return 1;
}
}
4.锁降级
- 锁降级指的是写锁降级成为读锁。意思是拿到写锁之后再获取读锁
- 锁降级的获取读锁是否有必要?如果不获取读锁,直接释放写锁的问题就是另一个线程获取写锁并且修改数据,那么当前线程无法感知线程T的数据更新。
5.5 LockSupport工具
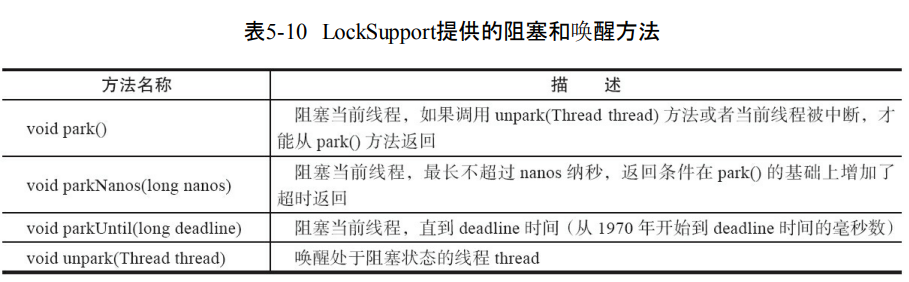
- park(Object blocker)、parkNanos(Object blocker,long nanos) 和parkUntil(Object blocker,long deadline)阻塞当前线程,blocker是标识线程等待的对象。
5.6 Condition接口
5.6.2 Condition的实现分析
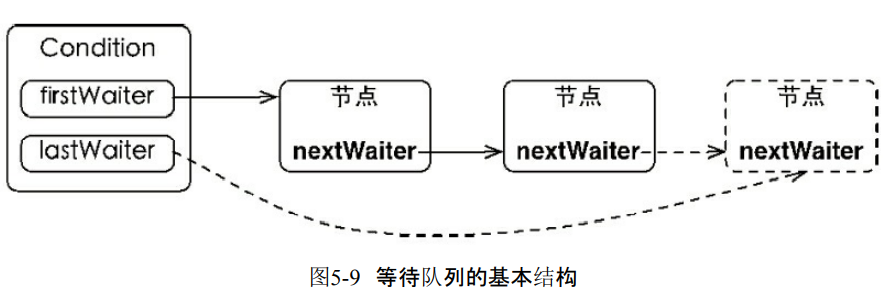
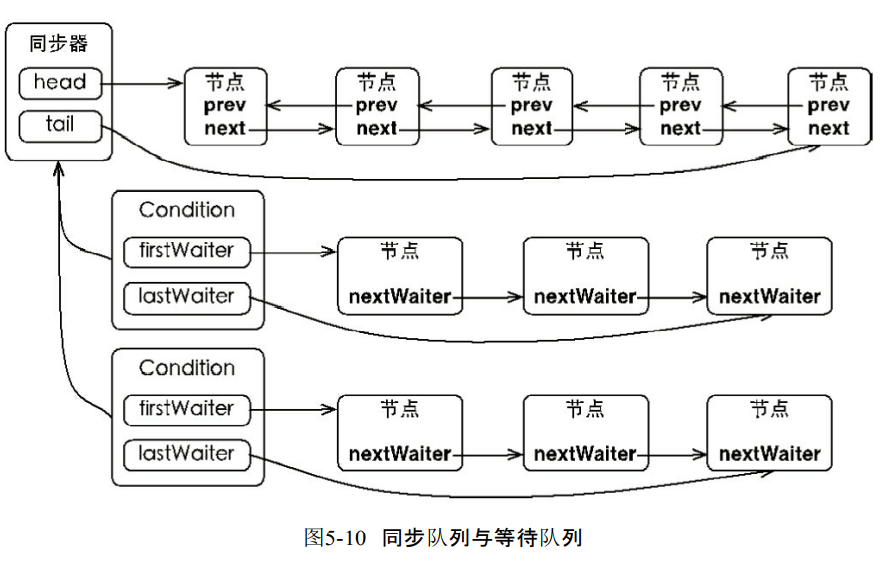
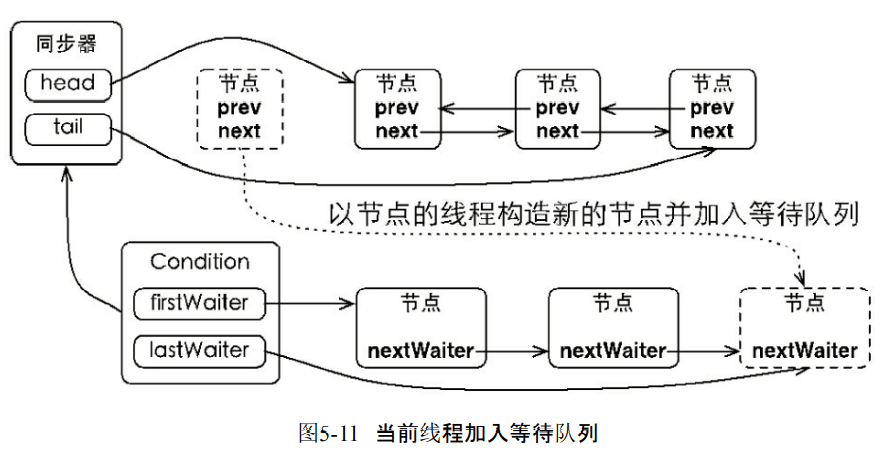
1.等待队列
- 是一个FIFO队列。如果线程调用await就会进入Condition的等待队列。
- 由于await一定是在获取锁的情况执行,所以不需要CAS保证线程安全性。
2.等待
- 释放锁,并且线程进入到等待队列。
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 当前线程加入等待队列
Node node = addConditionWaiter();
// 释放同步状态,也就是释放锁
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
3.通知
- 唤醒之后回到同步队列。
第6章 Java并发容器和框架
6.1 ConcurrentHashMap的实现原理与使用
6.1.1 为什么要使用ConcurrentHashMap
- 并发编程的HashMap容易产生死循环,而且HashTable效率太低。
- (1)线程不安全的HashMap
- 多线程下的put会造成死循环。
- HashMap会进入到一个环形Enrty链表,next永远不是空的。
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
t.join();
- (2)效率低下的HashTable
- 由于使用synchronized所以效率会比较差一些。
- (3)ConcurrentHashMap锁分段技术有效提高了并发访问率。
- 多线程可以访问容器不同数据段的数据,而且线程之间不存在锁竞争。
- ConcurrentHashMap把数据分段,分配多把锁。
6.1.2 ConcurrentHashMap的结构
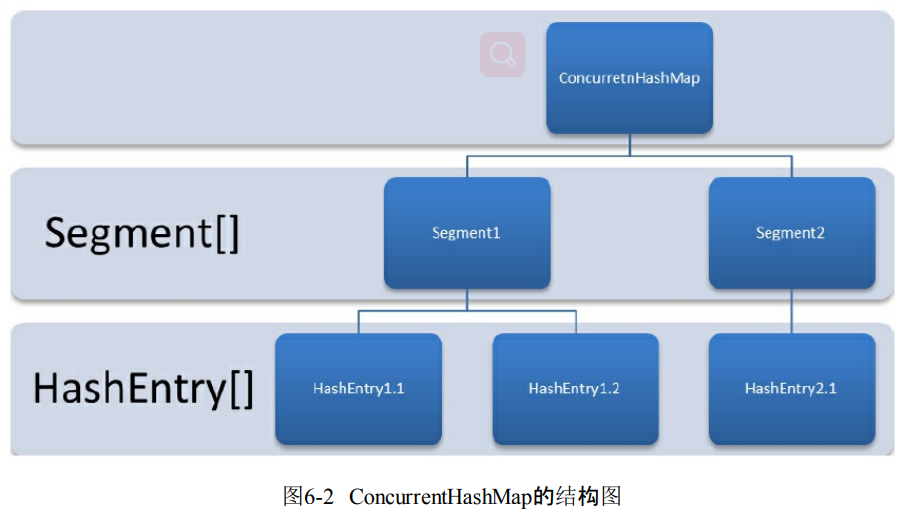
- ConcurrentHashMap通过Segment数组结构和HashEntry数组结构组成。
- Segment是可重入锁,HashEntry用于键值对存储数据。修改HashEntry数组必须先获取这段锁。
6.1.3 ConcurrentHashMap的初始化
1.初始化segments数组
- segments长度必须是2^N
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
2.初始化segmentShift和segmentMask
- sshift等于ssize左移位数。默认concurrencyLevel=16,也就是需要移动4次。
- segmentShift等于32减sshift,等于的是28。32是因为ConcurrentHashMap里的hash()方法输出最大是32.也就是算法输出的二进制数的长度是32位。
- segmentMask是散列运算的掩码,等于ssize-1。
- sshift的意思就是ssize的1向左移动的次数,由于ssize一定是2n,所以只有一个1存在。也就是取高位的几位。取决于Segment的大小的2n占了多少位。
3.初始化每个segment
-
initialCapacity是ConcurrentHashMap的初始化容量。loadfactor是每个segment的负载因子。
-
c就是初始容量initialCapacity/ssize,也就是除以Segment数组的大小,可以发现初始的倍数就是1.
-
cap就是等于c。
-
cap是Segment里面HashEntry数组的长度。
-
可以看到一开始的扩容阈值是threshold=(int)cap*loadFacto=0,也就是只要插入数据就会扩容。
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
6.1.4 定位Segment
- 让元素能够均匀分配到每个Segment,所以需要再一次进行hash操作。避免散列冲突严重。主要根据元素定位Segment的位置。
- 默认下segmentShift为28,segmentMask为15,所以每次散列之后的值,右移28位,相当于就是高4位来进行散列运算。避免了大量的散列冲突。相当于hash算法一次,+右移segmentShift与Segment数组大小相与一次一次。
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
6.1.5 ConcurrentHashMap的操作
1.get操作
- 首先经过一次散列,然后找到segment。然后再次通过散列找到对应的HashEntry数组的元素。
- get不加锁,只有值是空的时候才会加锁重读。
- get不加锁的原因是计算segment大小的count和存储值的value都是定义为volatile对象。保证了不会读到过期的值。但是只能被单线程写。
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
- HashEntry是直接重新散列,并没有使用元素的hashCode防止Segment和HashEntry的散列是一样的。
hash >>> segmentShift) & segmentMask // 定位Segment所使用的hash算法
int index = hash & (tab.length - 1); // 定位HashEntry所使用的hash算法
2.put操作
- put的时候必须加锁,先定位Segment。然后进行插入操作。插入的步骤
- 判断Segment的HashEntry是否需要扩容。
- 第二步就是添加元素的位置,把它放到HashEntry上面。
- 是否需要扩容。
- 首先判断HashEntry的大小是不是大于threshold。如果是那么就扩容。
- 如何扩容
- 创建两倍大的数组,然后把之前数组的元素进行再散列插入到新的数组。ConcurrentHashMap只会对部分的Segment进行扩容。
3.size操作
- 现在是不是把所有Segment的size相加就是能够得到ConcurrentHashMap的大小?
- 可能相加的时候Segment已经发生了变化。最安全的办法就是把put、remove、clean都给锁住。但是做法的效率非常低下。
- ConcurrentHashMap的做法是先尝试两次统计各个Segment大小。如果count发生变化,那么才会加锁。
- 那么ConcurrentHashMap如果判断容器变化了。主要是看modCount也就是put和clean还有remove操作的时候这个变量都会发生变化+1。所以统计size的时候比较前后的modCount是否发生变化。就能够得知容器是否发生变化。
6.2 ConcurrentLinkedQueue
- 实现线程安全的队列的两种方式阻塞和非阻塞。
- 阻塞算法使用的是一把锁或者两个锁实现入队和出队。
- 非阻塞可以使用CAS解决。
- 那么非阻塞是如何做到的?
- ConcurrentLinkedQueue基于链表的节点的无界线程安全队列。先进先出进行的排序。每次加入都加入到队列的尾部。
6.2.1 ConcurrentLinkedQueue的结构
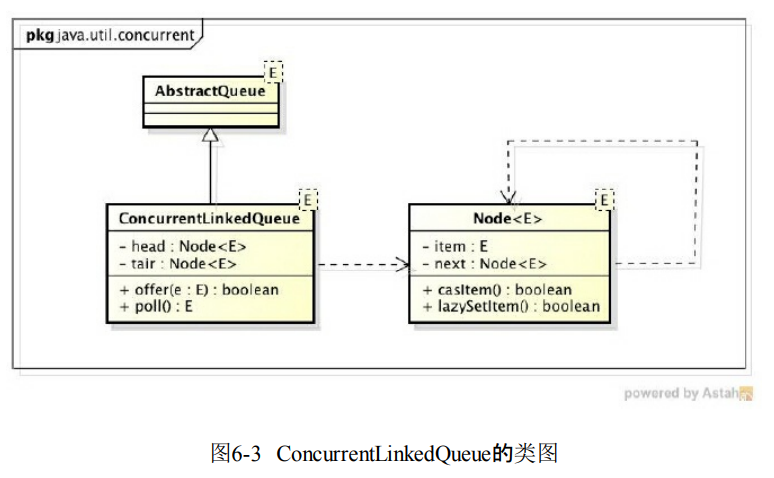
- 有head和tail节点。每个节点通过next关联起来。默认head是空节点,tail指向head节点。
6.2.2 入队列
1.入队列的过程
- 入队就是把节点加入到队列的末尾。并且把末尾指针指向最后一个节点。
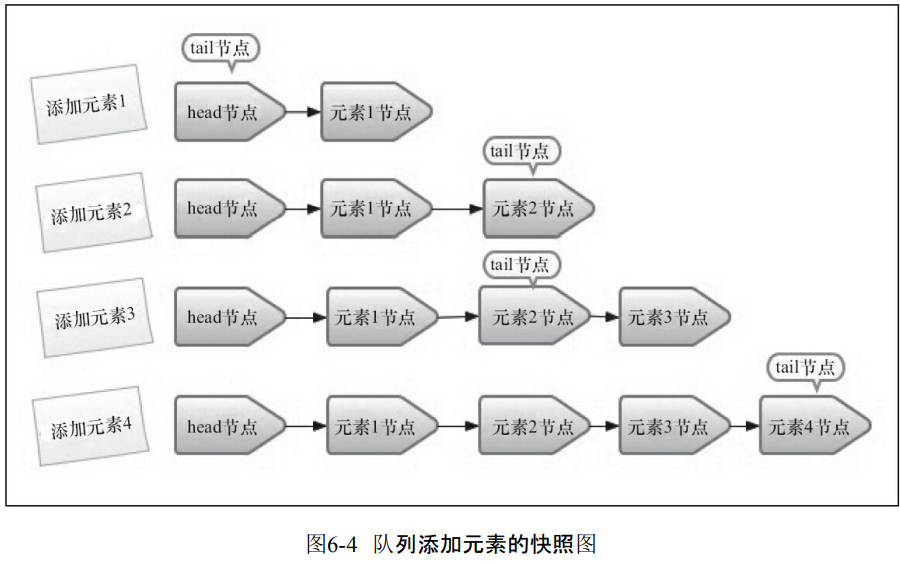
- 那么如果发生插队是如何抢占和插入节点的?
- 入队之前会创建一个节点
- 创建一个指向末尾节点的临时节点。
- 然后开始先去检查p是否有下一个节点,如果没有下一个节点,那么就能够把n设置为下一个节点。
- 如果有那么就循环指向下一个节点。说明已经被别人抢先插入。hops++
- 接着如果循环发现next是空的,那么就插入n进去,这个插入是一个CAS,允许失败,也就是可能会多个线程争抢这个位置,如果成功,那么就结束循环。
- 如果失败,那么就p指向下一个节点再一次进入循环。
- 总结来说就是判断是不是尾节点,如果不是就循环,如果是那么就CAS插入。
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
// 入队前,创建一个入队节点
Node<E> n = new Node<E>(e);
retry:
// 死循环,入队不成功反复入队。
for (;;) {
// 创建一个指向tail节点的引用
Node<E> t = tail;
// p用来表示队列的尾节点,默认情况下等于tail节点。
Node<E> p = t;
for (int hops = 0; ; hops++) {
// 获得p节点的下一个节点。
Node<E> next = succ(p);
// next节点不为空,说明p不是尾节点,需要更新p后在将它指向next节点
if (next != null) {
// 循环了两次及其以上,并且当前节点还是不等于尾节点
if (hops > HOPS && t != tail)
continue retry;
p = next;
}
// 如果p是尾节点,则设置p节点的next节点为入队节点。
else if (p.casNext(null, n)) {
/*如果tail节点有大于等于1个next节点,则将入队节点设置成tail节点,
更新失败了也没关系,因为失败了表示有其他线程成功更新了tail节点*/
if (hops >= HOPS)
casTail(t, n); // 更新tail节点,允许失败
return true;
}
// p有next节点,表示p的next节点是尾节点,则重新设置p节点
else {
p = succ(p);
}
}
}
}
2.定位尾节点
- 通过succ方法来定位。因为可能尾节点是tail节点,也可能是next。
final Node<E> succ(Node<E> p) {
Node<E> next = p.getNext();
return (p == next) head : next;
}
3.设置入队节点为尾节点
- p.casNext(null,n),就是把入队节点设置为p.next的指向节点。
4.HOPS的设计意图
- 下面的意思就是循环去找到tail节点,并且设置next节点是n。并且重新设置tail节点。这样可行吗?
- 这样的问题其实就是CAS的次数太多,每次进来都需要CAS。那么如何减少CAS?
- 使用hops变量,并不是每次都把tail节点更新为尾节点,而是tail节点和尾节点大于等于常量HOPS的时候才会更新。距离越长,那么CAS更新的次数就会越少。带来一个问题就是距离越长,定位的时间也就越长。本质上就是增加volatile的读来减少volatile的写。因为写volatile消耗更大,需要增加屏障。
- 那么为什么会增加了volatile的读?原因就是CAS的操作是volatile读写一起的,但是纯粹的succ访问下一节点只是一个volatile读操作,前面是知道volatile写操作还需要加上一个StoreLoad屏障,但是volatile读已经不需要加任何屏障,因为X86不允许读写和读读的重排序。
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
Node<E> n = new Node<E>(e);
for (;;) {
Node<E> t = tail;
if (t.casNext(null, n) && casTail(t, n)) {
return true;
}
}
}
6.2.3 出队列
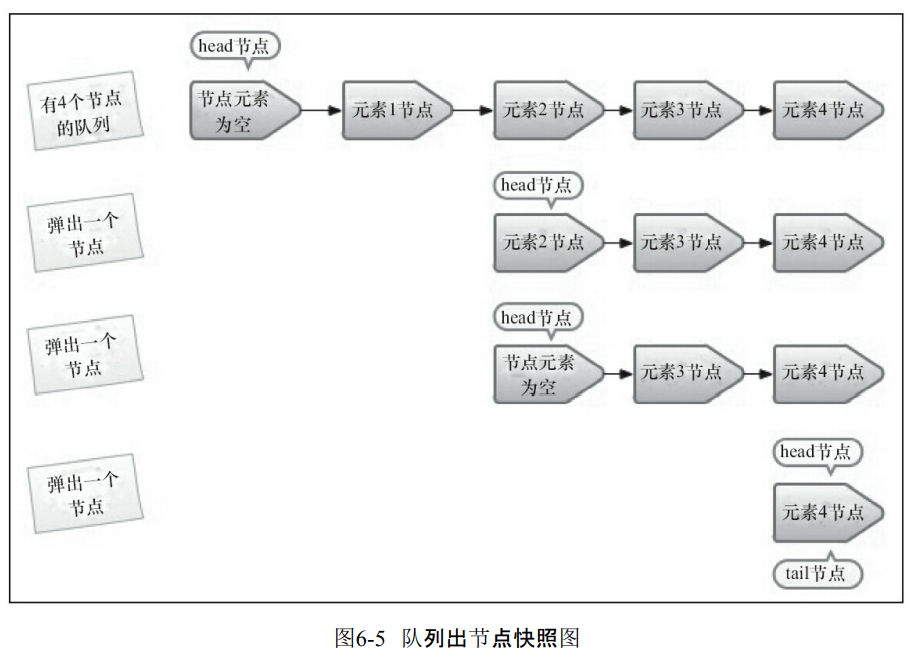
- 出队也是利用了hops。
- 首先是p指向了head节点。
- 然后获取p的元素。
- 如果元素不是空的,那么就设置p的元素是null。而且不是每次都会直接更新头节点,而是等待头结点和真正的头结点有一段距离的时候才会更新。
- 总结来说就是判断头节点的元素是不是空,如果是,那么就找到下一个头结点循环判断。如果不是空,那么就设置为空,并且等待超过HOPS的时候才能够重新设置头节点。也是通过增加volatile读的方式来减少volatile的写。
public E poll() {
Node<E> h = head;
// p表示头节点,需要出队的节点
Node<E> p = h;
for (int hops = 0;; hops++) {
// 获取p节点的元素
E item = p.getItem();
// 如果p节点的元素不为空,使用CAS设置p节点引用的元素为null,
// 如果成功则返回p节点的元素。
if (item != null && p.casItem(item, null)) {
if (hops >= HOPS) {
// 将p节点下一个节点设置成head节点
Node<E> q = p.getNext();
updateHead(h, (q != null) q : p);
}
return item;
}
// 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外
// 一个线程修改了。那么获取p节点的下一个节点
Node<E> next = succ(p);
// 如果p的下一个节点也为空,说明这个队列已经空了
if (next == null) {
// 更新头节点。
updateHead(h, p);
break;
}
// 如果下一个元素不为空,则将头节点的下一个节点设置成头节点
p = next;
}
return null;
}
6.3 Java中的阻塞队列
6.3.1 什么是阻塞队列
- 支持阻塞的插入:队列满的时候会阻塞插入元素的线程
- 支持阻塞的移除:队列是空的时候,队列阻塞移除的线程。等待非空。
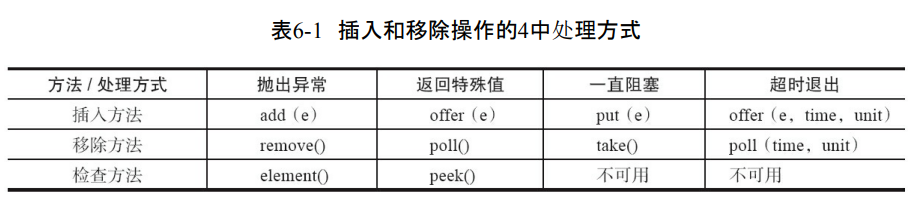
遇到队列满和队列空的处理方式。
-
抛出异常:队列满的时候插入元素就会抛出异常
-
返回特殊值:当往队列插入元素的时候,成功true。移除方法取出失败返回null。
-
一直阻塞:阻塞队列满的时候,继续put的线程会被阻塞。如果是空的时候get,那么也会被阻塞,直到不空的时候
-
超时退出:阻塞队列满的时候,生产者线程往队列里面插入元素,队列就会阻塞生产者线程一段时间,如果超出一段时间生产者线程就会退出。
6.3.2 Java里的阻塞队列
- ArrayBlockingQueue:数组有界阻塞队列
- LinkedBlockingQueue链表有界阻塞队列
- PriorityBlockingQueue:支持优先级的无界阻塞队列
- DelayQueue:使用优先级队列的无界阻塞队列。
- SynchronousQueue:不存储元素的无界阻塞队列。
- LinkedTransferQueue:链表组成的无界阻塞队列
- LinkedBlockingDeque:链表组成的双向阻塞队列。
- ArrayBlockingQueue
- 数组实现的有界阻塞队列,遵循FIFO
- 默认不保证线程公平访问队列。也就是阻塞和新进来的线程都能够争夺资源。
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
- LinkedBlockingQueue
- 链表实现的有界阻塞队列,也是FIFO
- PriorityBlockingQueue
- 支持优先级的无界阻塞队列,默认是升序。
- DelayQueue
- 支持延时获取元素的无界阻塞队列。使用的是优先级队列实现的。
- 队列接口必须实现Delayed接口。创建元素多久才能够被获取。
- 应用
- 缓存系统设计:队列保存缓存的有效期。并且线程轮询。
- 定时任务调度:一旦能够获取任务,就可以执行。
- (1)如何实现Delayed接口
- 初始化基本数据,time记录对象延迟什么时候可以使用。
- 实现getDelay方法,返回当前元素还需要延时的时间。
- compareTo指定元素的顺序。把延时比较长的放到末尾。
- (2)如何实现延时阻塞队列
- 获取元素的时候没有达到延时时间就会被阻塞。
- SynchronousQueue
- 不存储元素的阻塞队列。
- 每个put必须等待一个take。否则不能继续添加元素。
- 支持公平访问队列。默认是非公平的。
- 传递的速度非常快
- LinkedTransferQueue
- 由链表结构组成的无界阻塞TransferQueue队列
- 多出tryTransfer和transfer方法。
- (1)transfer方法
- transfer可以把元素立刻传输给消费者。如果没有消费者,那么就存放到尾部。
- 下面的关键代码
- 第一行尝试把s当前节点作为tail节点。
- 第二行是CPU自旋等待消费者消费元素。自旋一定次数会调用yield来切换元素。
Node pred = tryAppend(s, haveData);
return awaitMatch(s, pred, e, (how == TIMED), nanos);
- (2)tryTransfer方法
- 试探生产者的元素是否能够传给消费者。
- 可以设置时间等待。tryTransfer(E e,long timeout,TimeUnit unit)如果没有指定的消费者消费,那么就会返回false。
- LinkedBlockingDeque
- 由链表结构组成的双向阻塞队列
6.3.3 阻塞队列的实现原理
-
消费者和生产者如何知道队列的情况?
-
如何高效通信?
-
使用通知模式实现。生产者添加元素的时候阻塞住生产者,消费者消费了一个元素之后会通知生产者队列可用。可以看到ArrayBlockingQueue使用了Condition实现。
private final Condition notFull;
private final Condition notEmpty;
public ArrayBlockingQueue(int capacity, boolean fair) {
// 省略其他代码
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return extract();
} finally {
lock.unlock();
}
}
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
- 而且这里的await的原理实际上就是LockSupport的阻塞。park的原理是unsafe的park来阻塞当前的线程。这是一个native的方法。
//await的原理。
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
//Lock.park
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(false, 0L);
setBlocker(t, null);
}
//Unsafe.park
public native void park(boolean isAbsolute, long time);
- 只有在park对应的unpark执行的时候才会返回。
- 或者是线程中断
- 或者是park超时
- 或者是出现了异常。
JVM如何实现park。
- Linux系统的pthread_cond_wait实现的。
6.4 Fork/Join框架
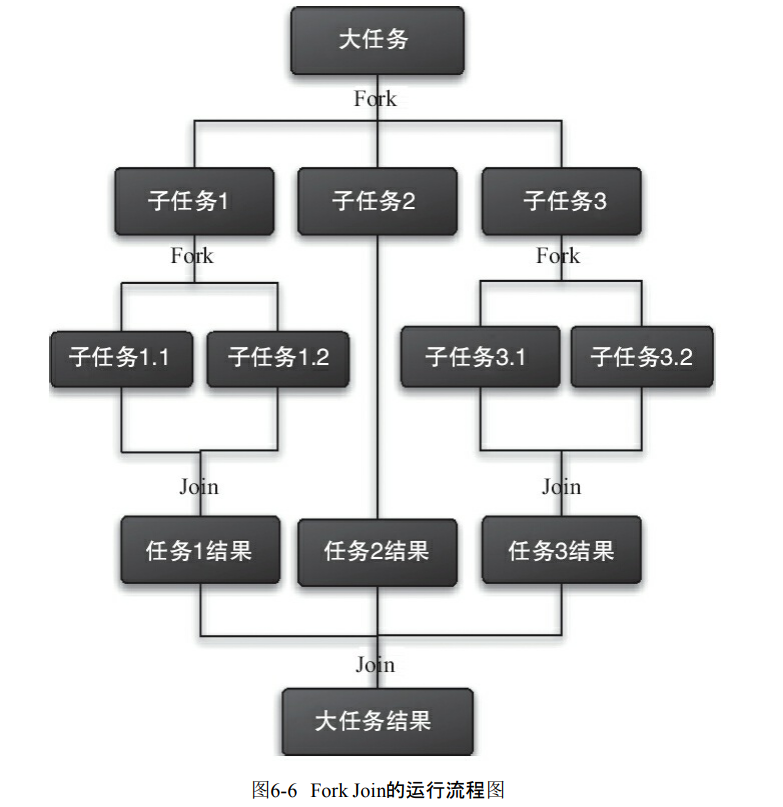
6.4.1 什么是Fork/Join框架
- 把大任务切分成各种小任务,并且最后把结果汇总的框架。
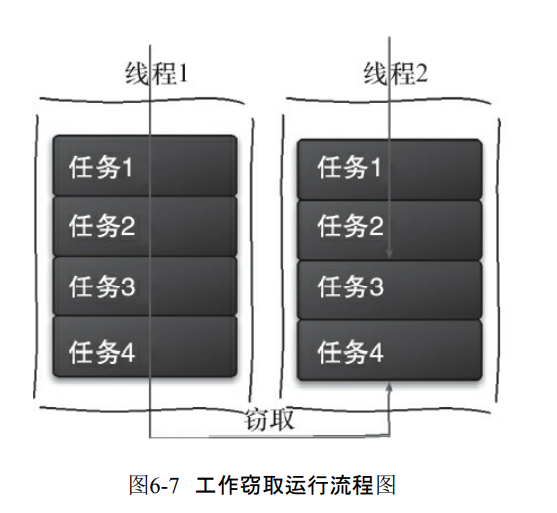
6.4.2 工作窃取算法
- 某个线程从其它队列窃取任务执行。
- 为了减少竞争我们会把各个切分的子任务放到不同的队列。并且一个队列创建一个线程来执行。
- 但是有的线程把任务执行完之后去帮助别的线程处理。所以为了减少两个线程竞争,它会把队列弄成双端的。
- 优点是充分利用线程计算,减少线程间的竞争
- 缺点是双端队列只有一个任务的时候,仍然存在竞争。算法消耗资源,创建多个线程和队列。
6.4.3 Fork/Join框架的设计
- 分割任务
- 执行并合并任务。分割的任务放到双端队列,结果统一放到一个队列。
- 启动线程并且从队列拿出数据合并。
Fork/Join使用两个类来完成以上两件事情
- 使用ForkJoinTask的子类
- RecursiveAction:没有结果的任务
- RecursiveTask:有返回结果的任务。
- ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行。
6.4.4 使用Fork/Join框架
- 实际上就是一个二分递归算法。
public class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult=leftTask.join();
int rightResult=rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
CountTask task = new CountTask(1, 4);
// 执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}
6.4.5 Fork/Join框架的异常处理
- 可以通过isCompletedAbnormally()检查任务是否出现异常。
6.4.6 Fork/Join框架的实现原理
- ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成。一个表示任务,一个就是线程执行任务。
- (1)ForkJoinTask的fork方法实现原理
- 实际上就是异步执行这个任务。调用了一个thread。
- pushTask把任务存放到task数组上,并且调用ForkJoinPool的signalWork方法唤醒一个线程执行。
public final ForkJoinTask<V> fork() {
((ForkJoinWorkerThread) Thread.currentThread())
.pushTask(this);
return this;
}
- (2)ForkJoinTask的join方法实现原理
- 阻塞当前线程并且等待结果。
- 调用了doJon方法。得到任务的状态。判断任务是否完成。任务的分为三个状态。已完成(NORMAL)、被取消(CANCELLED)、信号(SIGNAL)和出现异常 (EXCEPTIONAL)。
- 如果发现任务没有完成,那么就去拿出线程来执行
- 如果完成那么就返回
- 如果出现异常那么就抛出异常。
//join
public final V join() {
if (doJoin() != NORMAL)
return reportResult();
else
return getRawResult();
}
private V reportResult() {
int s; Throwable ex;
if ((s = status) == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL && (ex = getThrowableException()) != null)
UNSAFE.throwException(ex);
return getRawResult();
}
//doJoin
private int doJoin() {
Thread t; ForkJoinWorkerThread w; int s; boolean completed;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
if ((s = status) < 0)
return s;
if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}
else
return externalAwaitDone();
}
第7章 Java中的13个原子操作类
7.1 原子更新基本类型类
- ·AtomicBoolean:原子更新布尔类型。
- ·AtomicInteger:原子更新整型。
- ·AtomicLong:原子更新长整型。
提供的方法
- int addAndGet(int delta)输入值与实例的值相加。并且返回结果
- boolean compareAndSet(int expect,int update):输入的值与预期的一样,那么就会把原来的值设置为新的值。
- int getAndIncrement():原子的方式自增。
- void lazySet(int newValue):最终会设置为新值,可能会延迟。
- ·int getAndSet(int newValue):原子的方式设置新的值。并且返回旧的值。
getAndIncrement如何实现原子操作
- 首先是获取原来Atomoic存储的值
- 然后进行加一。
- compareAndSet(current, next)进行原子操作。检查当前的值是否等于current,如果没有被修改就能赋值。
public final int getAndIncrement() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
- Atomic的类基本是Unsafe实现的。
/**
* 如果当前数值是expected,则原子的将Java变量更新成x
* @return 如果更新成功则返回true
*/
public final native boolean compareAndSwapObject(Object o,
long offset,
Object expected,
Object x);
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
public final native boolean compareAndSwapLong(Object o, long offset,
long expected,
long x);
7.2 原子更新数组
-
·AtomicIntegerArray:原子更新整型数组里的元素。
-
·AtomicLongArray:原子更新长整型数组里的元素。
-
·AtomicReferenceArray:原子更新引用类型数组里的元素。
-
·AtomicIntegerArray类主要是提供原子的方式更新数组里的整型
他们的方法与api
- int addAndGet(int i,int delta):原子方式把delta与索引是i的值相加
- boolean compareAndSet(int i,int expect,int update):是否等于预期的值,如果是才能够修改。
7.3 原子更新引用类型
- ·AtomicReference:原子更新引用类型。
- ·AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
- ·AtomicMarkableReference:原子更新带有标记位的引用类型。
- 主要是能够原子更新AtomicReference也就是它指向的引用。
7.4 原子更新字段类
-
·AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
-
·AtomicLongFieldUpdater:原子更新长整型字段的更新器。
-
·AtomicStampedReference:原子更新带有版本号的引用类型。
-
使用方式就是定位位置,然后调用方法即可。
public class AtomicIntegerFieldUpdaterTest {
// 创建原子更新器,并设置需要更新的对象类和对象的属性
private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.
newUpdater(User.class, "old");
public static void main(String[] args) {
// 设置柯南的年龄是10岁
User conan = new User("conan", 10);
// 柯南长了一岁,但是仍然会输出旧的年龄
System.out.println(a.getAndIncrement(conan));
// 输出柯南现在的年龄
System.out.println(a.get(conan));
}
public static class User {
private String name;
public volatile int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
第9章 Java中的线程池
线程池的好处
- 降低资源消耗。利用已经创建线程,减少线程的创建和销毁带来的性能消耗。
- 提高响应速度。当任务到达的时候,任务可以不需要线程创建就能够立即执行。
- 提高线程的可管理性。
9.1 线程池的实现原理
- 线程池判断核心线程池里面的线程是否都在执行任务。如果不是那么就创建一个新的线程来执行任务。如果核心线程池线程都在执行任务,那么进入下一个流程。
- 线程池判断工作队列是不是满了,如果没有满,那么就把任务存储在队列。如果满了,那么进入到下一个流程
- 线程池判断线程池的线程是不是都处于工作状态,如果没有就创建一个执行任务,否则只能执行饱和策略来执行任务了。
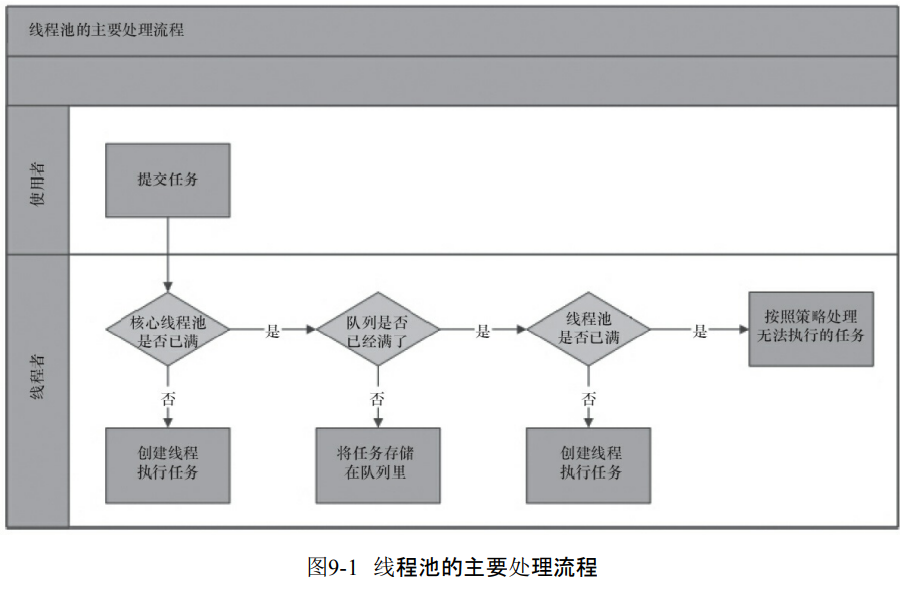
ThreadPoolExecutor执行execute方法分四种。
- 当前运行的线程数少于corePoolSize,那么创建新的线程工作。
- 如果当前运行线程数大于corePoolSize,那么就把任务加入到BlockingQueue。
- 如果无法将任务加入到BlockingQueue也就是队列满的情况,那么就要创建新的线程执行。
- 如果线程超出了maximumPoolSize那么执行执行饱和策略了。
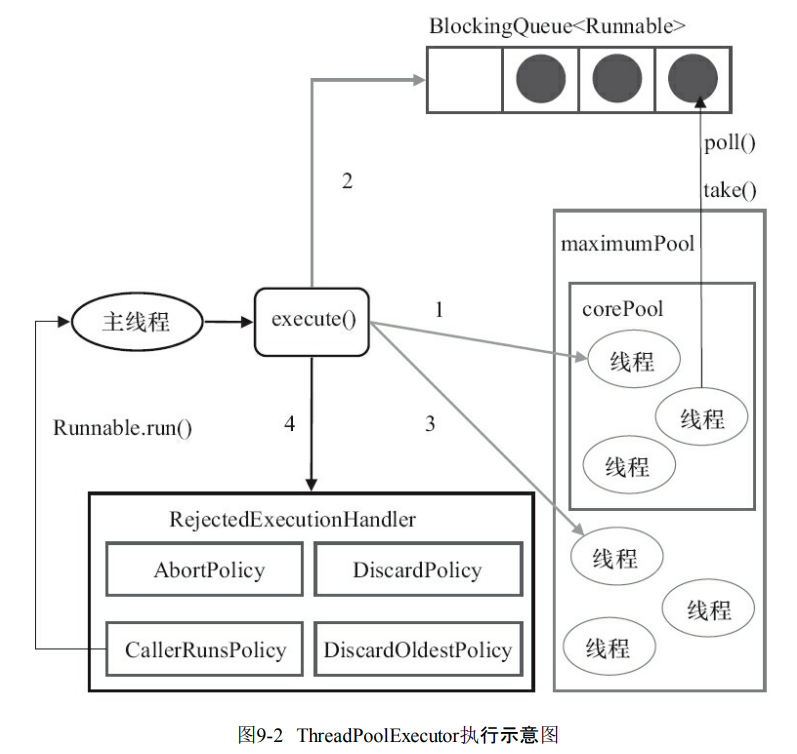
源码分析
- command就是任务,判断逻辑基本上是和上面是一模一样的。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 如果线程数小于基本线程数,则创建线程并执行当前任务
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
// 如线程数大于等于基本线程数或线程创建失败,则将当前任务放到工作队列中。
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
// 如果线程池不处于运行中或任务无法放入队列,并且当前线程数量小于最大允许的线程数量,
// 则创建一个线程执行任务。
else if (!addIfUnderMaximumPoolSize(command))
// 抛出RejectedExecutionException异常
reject(command); // is shutdown or saturated
}
}
工作线程
- 线程会被封装为Worker。Worker执行任务之后还会循环获取工作队列里面的任务执行。
- 可以看看run方法。就是不断循环,并且获取任务执行。
public void run() {
try {
Runnable task = firstTask;
firstTask = null;
while (task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this);
}
}
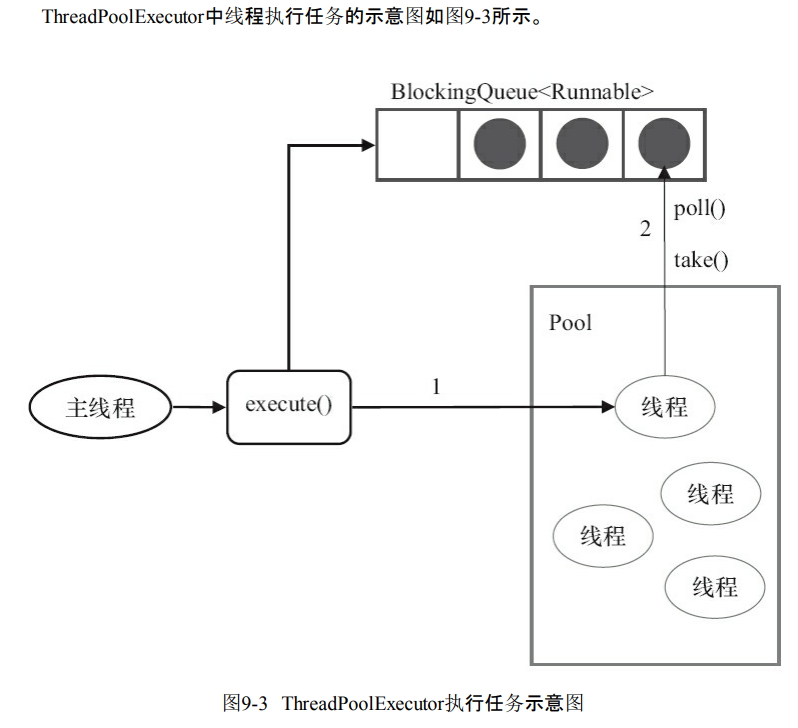
- 线程池执行任务分为两种情况
- execute方法创建线程,并且执行任务
- 线程执行任务之后,会取到BlockingQueue获取任务执行。
9.2 线程池的使用
9.2.1 线程池的创建
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime,
milliseconds,runnableTaskQueue, handler);
- corePoolSize:核心线程数
- runnableTaskQueue:任务队列。也就是上面提到的各种阻塞队列。比如ArrayBlockingQueue。
- ArrayBlockingQueue
- ·LinkedBlockingQueue
- ·SynchronousQueue
- PriorityBlockingQueue
- maximumPoolSize:线程的最大数量。
- ThreadFactory:创建线程的工厂。线程工厂可以给线程赋予名字。
- RejectedExecutionHandler:饱和策略。队列和线程池都已经满的情况如何处理任务。
- AbortPolicy:抛出异常
- CallerRunsPolicy:调用者所在的线程执行任务
- DiscardOldestPolicy:丢弃队列最近的一个任务
- DiscardPolicy:直接丢弃。
- keepAliveTime:超过corePoolSize的线程空闲存活时间。
- TimeUnit:上面存活时间的一个单位。
9.2.2 向线程池提交任务
- execute不需要返回值。只需要输入一个Runnable任务。
threadsPool.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
}
});
- submit返回一个Future对象。相当于就是数据封装到了Future这里。
Future<Object> future = executor.submit(harReturnValuetask);
try {
Object s = future.get();
} catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池
executor.shutdown();
}
9.2.3 关闭线程池
- 调用线程池的shutdown或者是shutdownNow方法关闭线程池。原理是遍历工作线程,发出中断信号。
- shutdownNow设置线程状态是STOP然后尝试停止所有线程
- shutdown只是设置线程状态SHUTDOWN,中断所有没有执行任务的线程。
- 所有任务关闭,那么线程池关闭成功。
9.2.4 合理地配置线程池
从哪方面考量?
- 任务性质:CPU密集型还是IO密集型
- 任务的优先级
- 任务执行时间
- 任务的依赖性。
如何选择线程池
- CPU密集型选择线程尽可能少一点的。
- 对于IO密集型的选择线程多一些,因为IO密集说明不是所有线程都能工作。有的被阻塞导致CPU无法很好被使用。
- 优先级不同可以使用PriorityBlockingQueue来进行处理。能够让优先级更高的任务先执行。
- 依赖数据库连接池的任务,线程提交SQL之后会进入阻塞,所以使用更多线程会更好使用CPU。
- 建议使用有界队列,避免任务的积压。任务积压导致的内存撑满的问题,会导致程序直接结束。
9.2.5 线程池的监控
如何监控?
- 通过各种线程池参数
- taskCount:线程池需要执行的任务数量
- completedTaskCount:线程池完成任务的数量
- largestPoolSize:创建过的线程池最大的数量。
- getPoolSize:线程池的线程数量。
- getActiveCount:获取活动的线程数。
第10章 Executor框架
10.1 Executor框架简介
10.1.1 Executor框架的两级调度模型
- 在HotSpot VM模型里面,java线程被一对一映射为本地操作系统的线程。操作系统可以调度线程,分配给CPU。
- java多线程会把应用分成多个任务,然后使用用户级的调度器。把任务映射为固定数量的线程。操作系统内核会把这些线程映射到硬件处理器上。
- 也就是说Executor把任务分配给线程执行,线程通过操作系统内核来映射到CPU的调度。
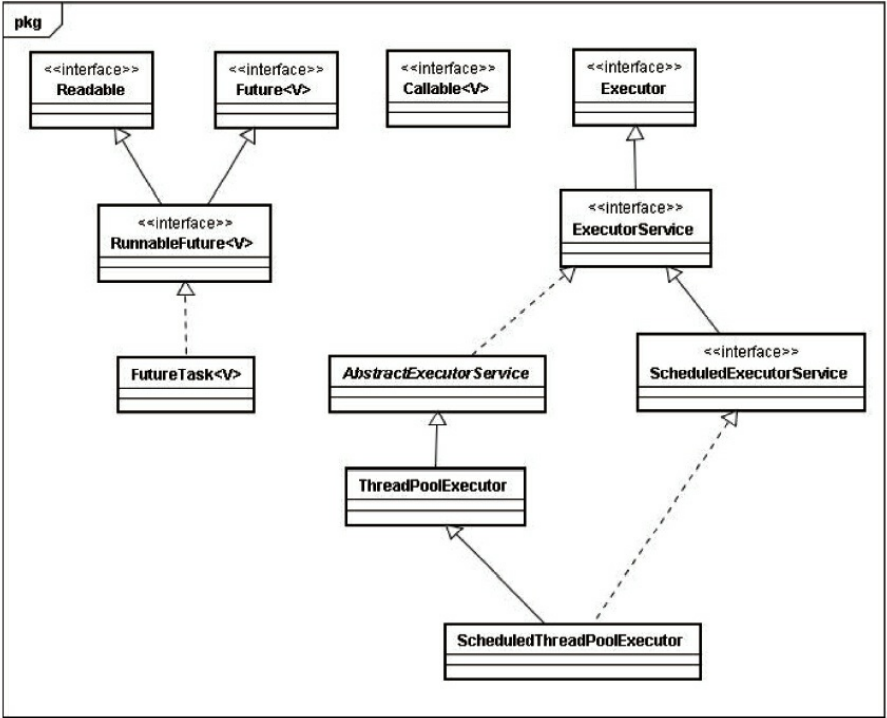
10.1.2 Executor框架的结构与成员
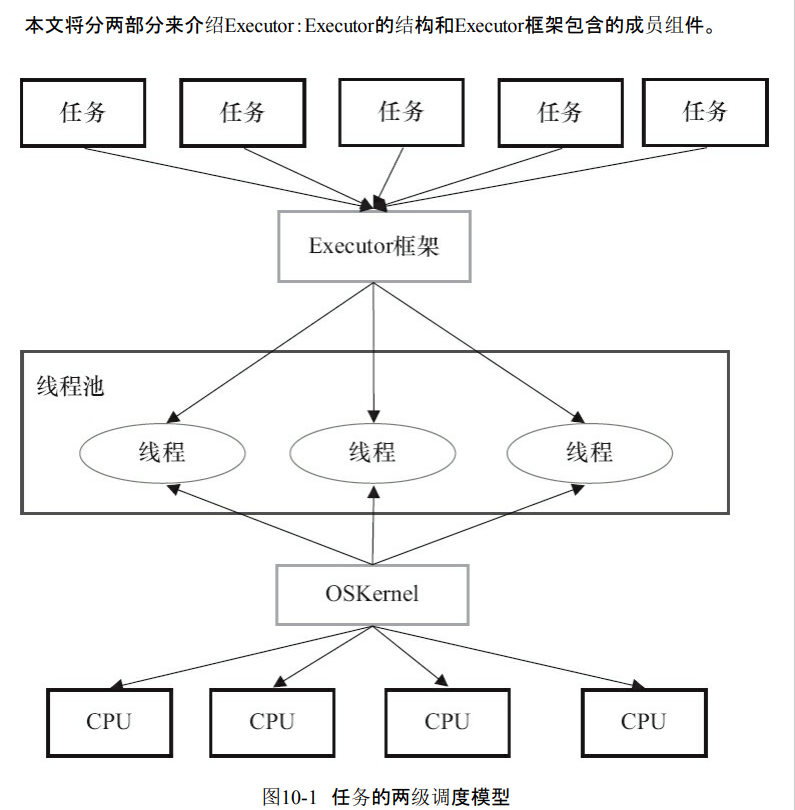
1.Executor框架的结构
组成部分
- 任务:实现任务的Callable和Runnable接口
- 任务执行:任务执行机制的核心接口Executor,以及集成Executor的ExecutorService。还有两个实现了ExecutorService接口的ThreadPoolExecutor和ScheduledThreadPoolExecutor。
- 异步计算的结果。也就是Future接口和实现Future接口的FutureTask类
类和接口的简介
- Executor是Executor框架的基础,把任务的提交和任务的执行分离开。
- ThreadPoolExecutor:线程池的核心实现类。执行被被提交的任务。
- ScheduledThreadPoolExecutor:延迟执行命令。或者定期执行命令。
- Future:代表异步计算结果。
- Runnable和Callable的实现类可以被ThreadPoolExecutpor和ScheduledThreadPoolExecutor。
Executor框架的使用。
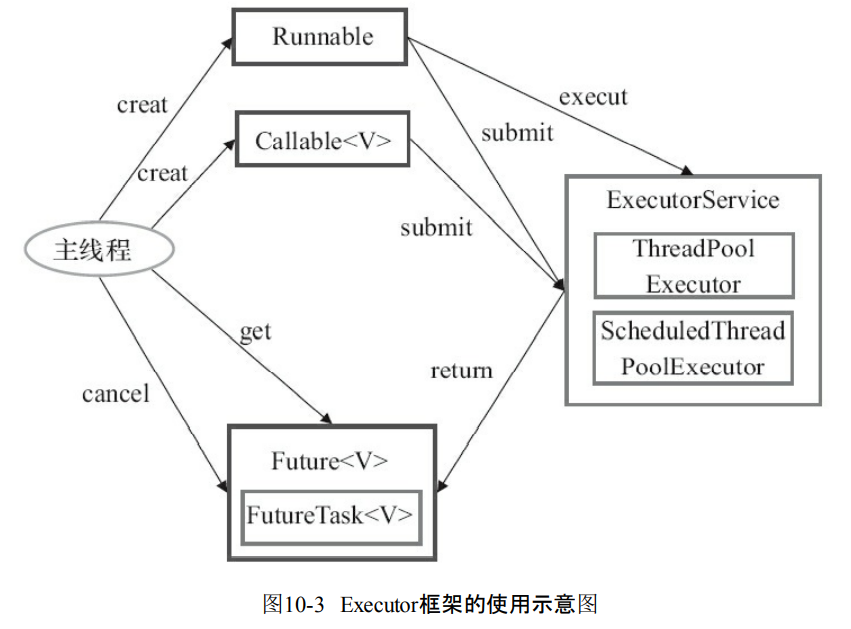
- 首先是主线程要创建Runnable或者是Callable的实现对象,
- 然后把任务对象Runnable交给ExecutorService执行execute。
- 如果任务对象是Callable那么就是执行submit。返回一个Future异步结果。
- 主线程可以通过Future的get来等待任务执行结束。
2.Executor框架的成员
- (1)ThreadPoolExecutor
- 这个通常直接通过工厂类Executors直接创建。
- Executors创建3种类型的ThreadPoolExecutor:SingleThreadExecutor、FixedThreadPool和CachedThreadPool。
- 1)FixedThreadPool。:创建固定线程的线程池。适用负载比较重的服务器。
- 2)SingleThreadExecutor:顺序完成任务,所以只有一个线程在执行。
- 3)CachedThreadPool。:根据需要创建线程,线程数量是无限的。可以执行很多小任务。适用于负载比较轻的。
- (2)ScheduledThreadPoolExecutor
- 两种类型。
- ScheduledThreadPoolExecutor包含若干个线程的类型
- 适合多个后台的周期执行任务。
- SingleThreadScheduledExecutor包含一个线程的类型
- 适合单个后台的周期执行任务。
- (3)Future接口
- 能够表示异步计算的结果,通过FutureTask。
- (4)Runnable接口和Callable接口
- 就是任务的实现接口。
10.2 ThreadPoolExecutor详解
- corePool:核心线程池的大小
- ·maximumPool:最大线程池的大小。
- ·BlockingQueue:用来暂时保存任务的工作队列。
- ·RejectedExecutionHandler:饱和策略。
10.2.1 FixedThreadPool详解
- corePool和maximumPool都被设置为nThreads
- 说明不能够有多余的线程。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
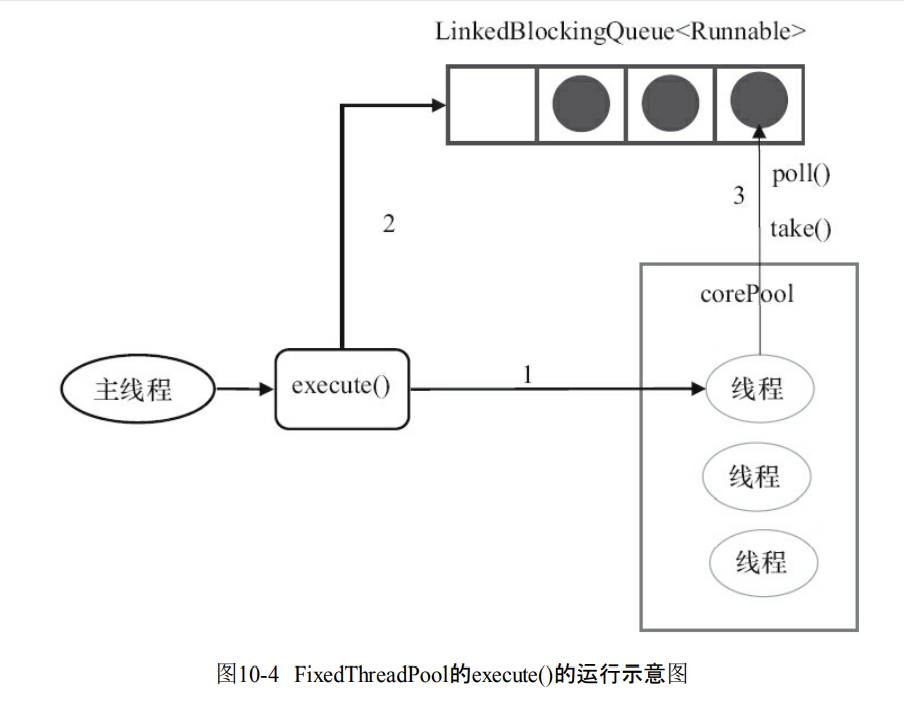
- 如果当前线程少于core那么就创建线程执行任务
- 线程池完成预热之后,把任务加入到LinkedBlockingQueue。
- 执行完1的任务之后,会反复去到队列获取任务。
- 这个线程池不拒绝新任务
10.2.2 SingleThreadExecutor详解
- core和max线程数量都是1。
- 与无界队列LinkedBlockingQueue配合。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
10.2.3 CachedThreadPool详解
- 这里没有core但是max是被设置为无界的。说明可以不断创建线程。
- 使用的队列是SynchronousQueue。也就是来一个任务必须要快速找到线程处理
- 如果任务太多可能会导致内存不足。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
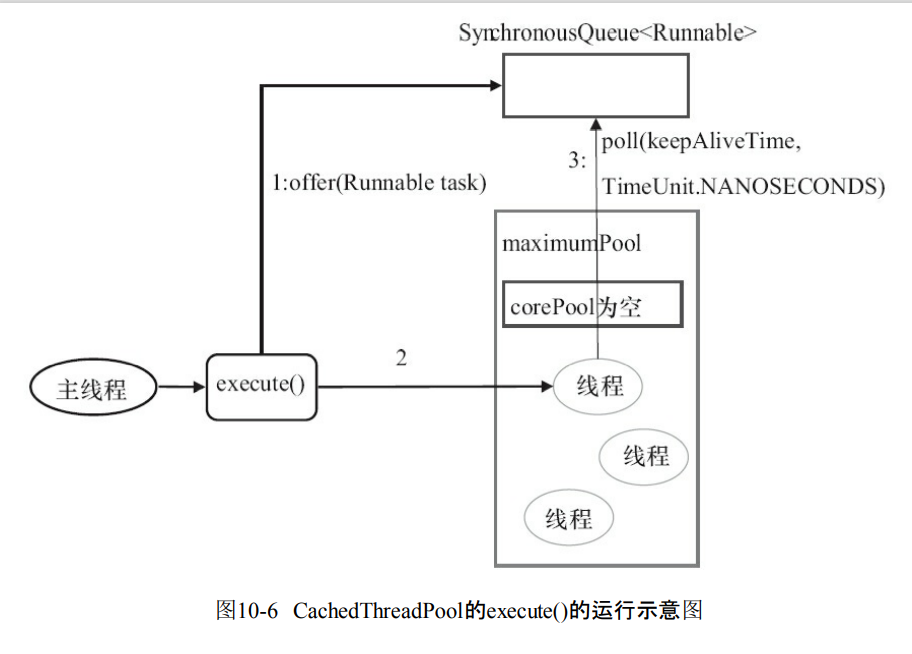
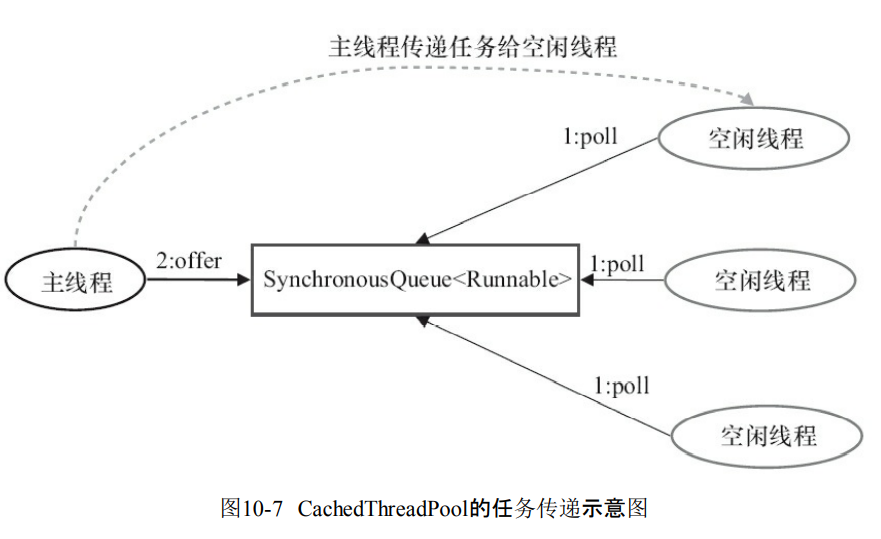
- 首先执行的是SynchronousQueue.offer(Runnable task)如果有空闲线程,线程立刻执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)。
- 如果maximumPool为空,说明没有空闲线程,那么就会创建一个新的线程执行任务
- 创建线程成功之后,线程开始执行SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS),也就是要在60s之内空闲线程要接收任务并且执行。如果60s之后,那么空闲线程就会结束。
10.3 ScheduledThreadPoolExecutor详解
- 继承了ThreadPoolExecutor,定期任务和延迟任务。
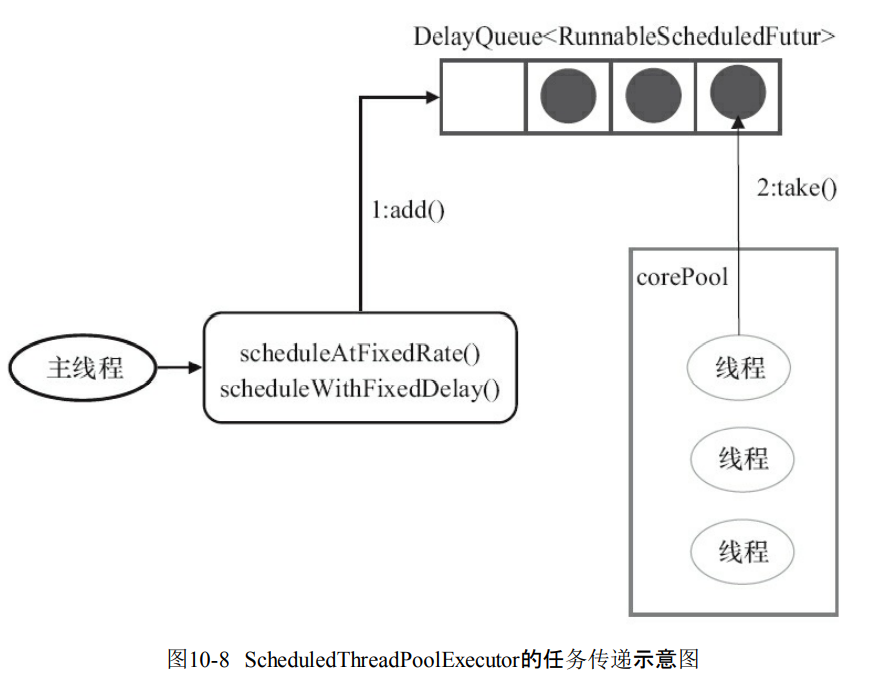
10.3.1 ScheduledThreadPoolExecutor的运行机制
- ScheduledThreadPoolExecutor使用的是DelayQueue无界队列,所以maximumPoolSize没有意义。
- scheduleAtFixedRate()和scheduleAtFixedDelay()会向DelayQueue添加一个实现了RunnableScheduledFutur的接口。
- 然后就是线程获取任务和执行。
10.3.2 ScheduledThreadPoolExecutor的实现
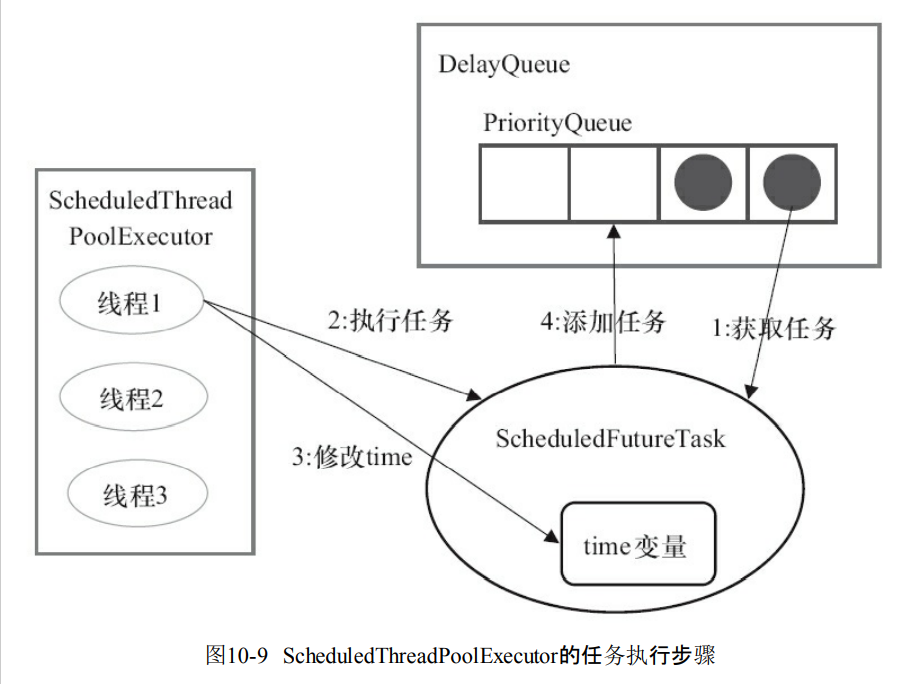
ScheduledFutureTask任务包含三个成员变量
- ·long型成员变量time,这个任务执行的具体时间
- long型成员变量sequenceNumber,表示这个任务被添加到ScheduledThreadPoolExecutor的序号。
- long型成员变量period表示任务执行的间隔周期。
- DelayQueue封装了一个PriorityQueue队列。能够对里面的任务进行排序。time小的放到前面。然后对比序号。
执行任务的四个步骤
- 线程从队列获取到期的任务
- 线程执行任务
- 线程修改任务的time变量为下次的执行时间。
- 重新把任务放回去。
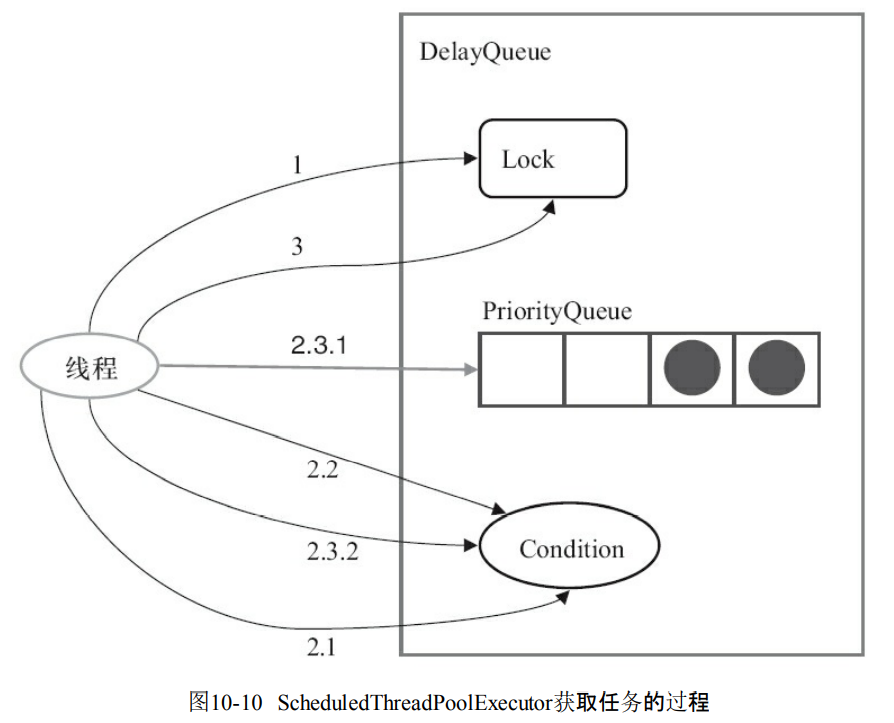
- 这个就是take任务的代码
- 获取Lock
- 获取周期任务
- 如果PriorityQueue是空的,那么进入到Condition等待
- 如果PriorityQueue的time时间比当前时间大,那么就到Condition等待time时间。
- 获取PriorityQueue的头元素。如果不是空,那么唤醒Condition的等待线程。
- 释放Lock。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 1
try {
for (;;) {
E first = q.peek();
if (first == null) {
available.await(); // 2.1
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
long tl = available.awaitNanos(delay); // 2.2
} else {
E x = q.poll(); // 2.3.1
assert x != null;
if (q.size() != 0)
available.signalAll(); // 2.3.2
return x;
}
}
}
} finally {
lock.unlock(); // 3
}
}
10.4 FutureTask详解
10.4.1 FutureTask简介
- 实现了Future还实现了Runnable接口。可以交给线程池执行。
- 三种状态
- 未启动
- 已经启动
- 已经完成。
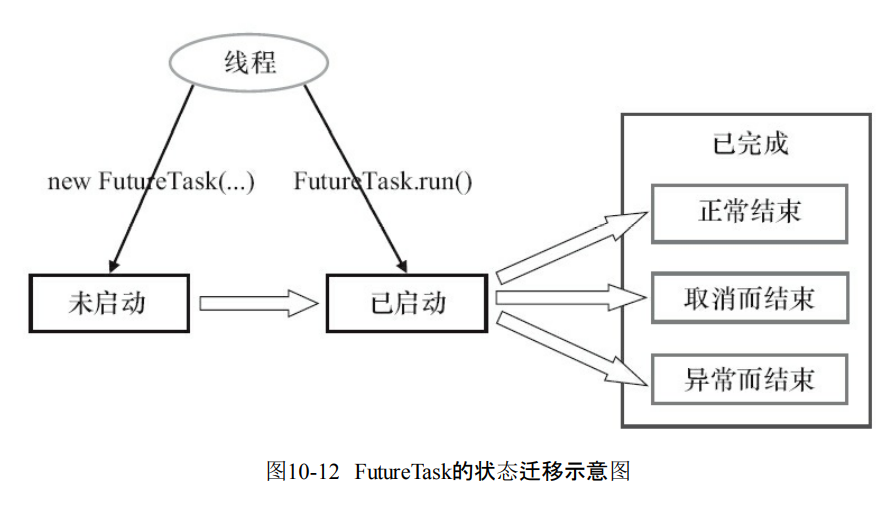
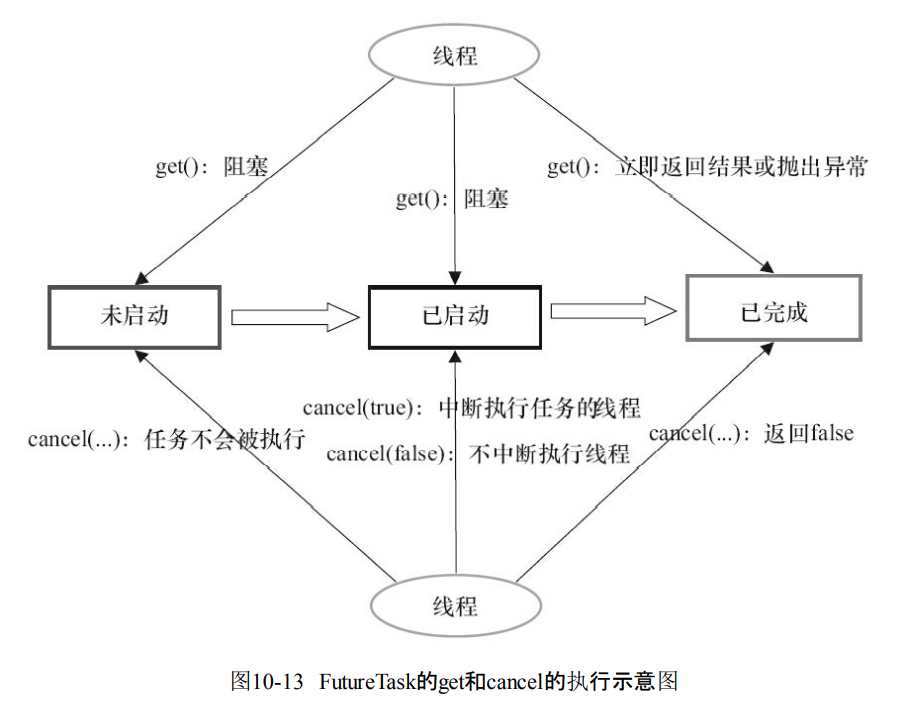
- 当FutureTask是未启动或者是已经启动的时候,那么就会调用get方法导致调用线程的阻塞。
- 如果处于已完成,那么就会返回结果或者抛出异常。
- 如果FutureTask处于未启动状态的时候,可以调用cancel导致任务不会被执行。
- 如果是启动的时候调用cancel(true),那么就会试图中断执行这个任务。
- 如果是启动的时候调用cancel(false),那么不会对正在执行的任务线程产生影响。
- 如果是已经完成的任务,那么就会返回false。
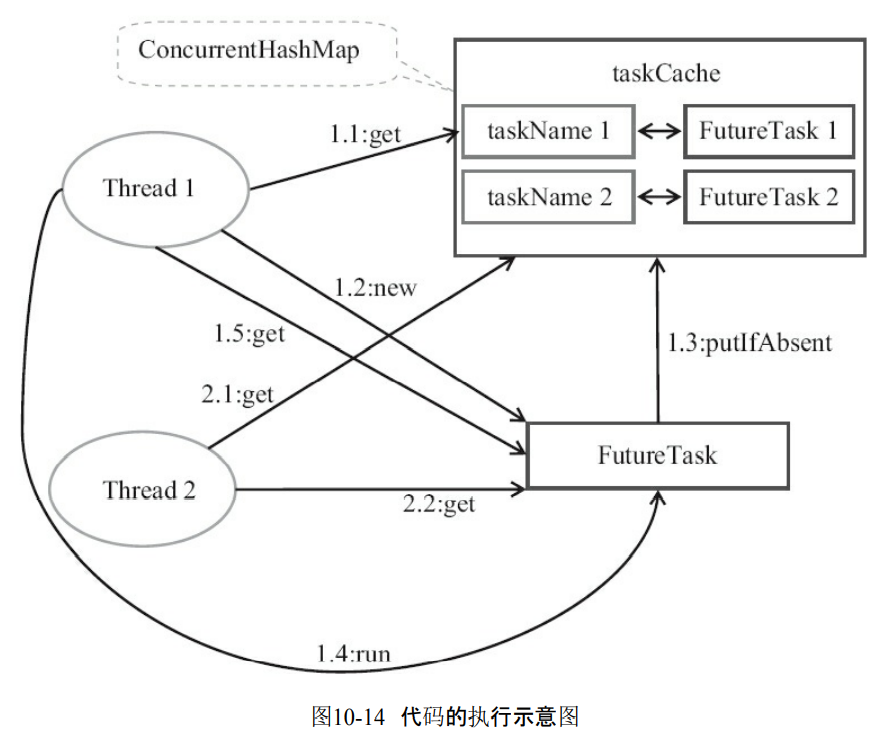
10.4.2 FutureTask的使用
- 循环创建和执行任务。
- 线程会去到taskCache里面获取任务
- 如果发现没有,那么就创建任务,并且存入taskCache里面。
- 然后获取并执行任务。
private final ConcurrentMap<Object, Future<String>> taskCache =
new ConcurrentHashMap<Object, Future<String>>();
private String executionTask(final String taskName)
throws ExecutionException, InterruptedException {
while (true) {
Future<String> future = taskCache.get(taskName); // 1.1,2.1
if (future == null) {
Callable<String> task = new Callable<String>() {
public String call() throws InterruptedException {
return taskName;
}
}; // 1.2创建任务
FutureTask<String> futureTask = new FutureTask<String>(task);
future = taskCache.putIfAbsent(taskName, futureTask); // 1.3
if (future == null) {
future = futureTask;
futureTask.run(); // 1.4执行任务
}
}
try {
return future.get(); // 1.5,2.2线程在此等待任务执行完成
} catch (CancellationException e) {
taskCache.remove(taskName, future);
}
}
}
10.4.3 FutureTask的实现
- FutureTask基于AQS
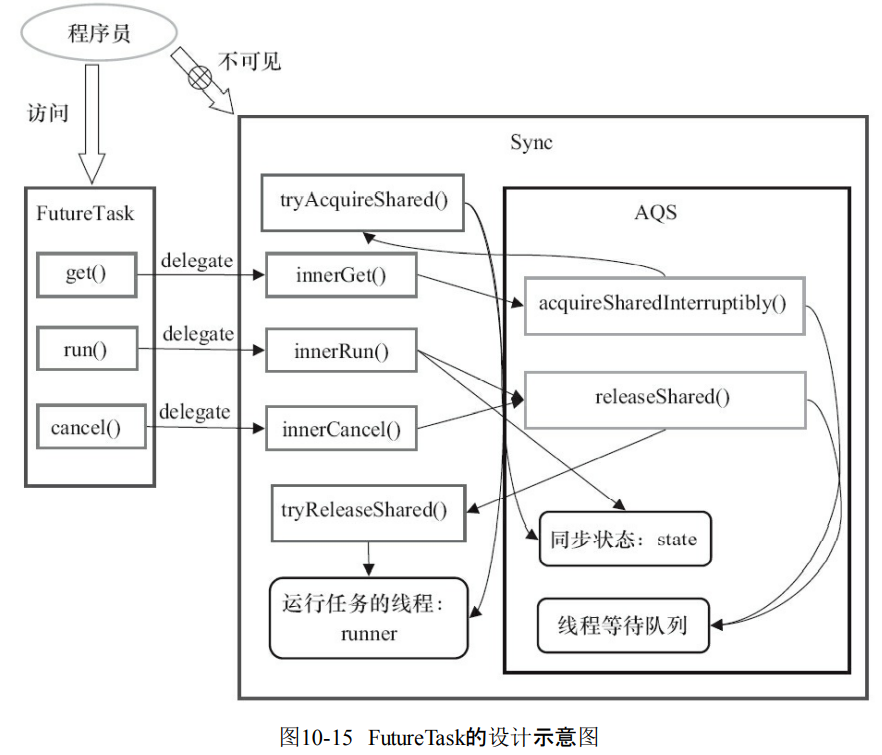
-
FutureTask的get调用AQS.acquireSharedInterruptibly(int arg)
- 调用AQS.acquireSharedInterruptibly(int arg)也就是去争抢锁。获取成功的条件是state=RAN或者是CANCELLED
- 如果get成功立刻返回。否则就要等待其它线程释放release。
- 其它线程release。唤醒当前线程,再次去获取锁
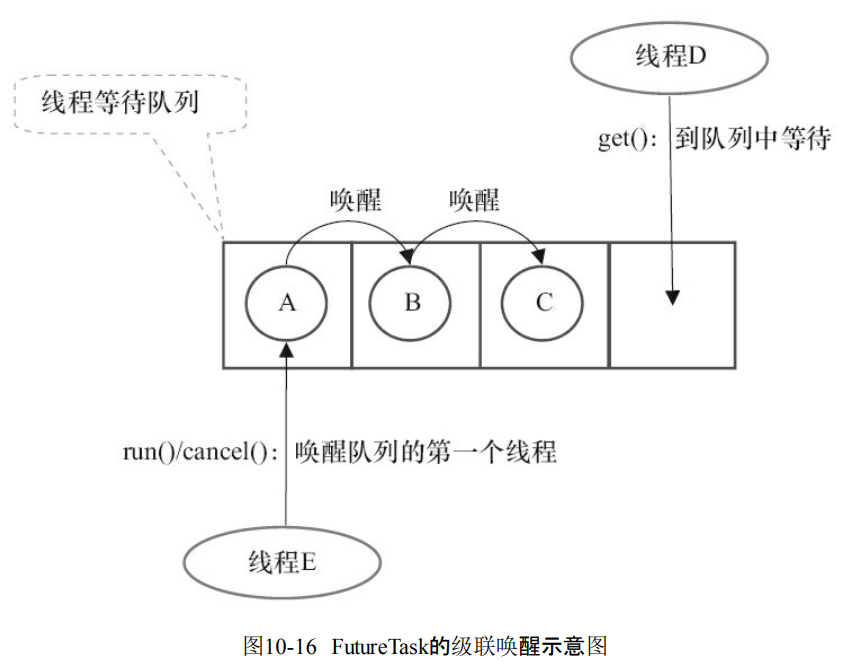
- 最后返回计算结果。
-
run过程
- 执行构造函数的任务
- 原子方式更新同步状态。AQS.compareAndSetState(int expect,int update)设置为state=RAN如果设置成功,代表计算结果的值是Callable.call()的返回值。然后释放锁AQS.releaseShared(int arg),其实就是修改同步状态。
- AQS.releaseShared(int arg)之后会调用tryReleaseShared(arg)来release。然后唤醒第一个线程。
- 调用FutureTask.done()。执行FutureTask.get()的时候如果task不是出于已经完成RAN或者是CANCELLED。那么线程就只能去到AQS的同步队列等待。如果某个线程执行run或者cancel,那么就会唤醒下一个线程。