计算机视觉笔记总目录
当我们拥有大量计算资源时,通过使用合适的分布式策略,我们可以充分利用这些计算资源,从而大幅压缩模型训练的时间。针对不同的使用场景,TensorFlow 在 tf.distribute.Strategy中为我们提供了若干种分布式策略,使得我们能够更高效地训练模型。
1 TensorFlow 分布式的分类
图间并行(又称数据并行)
- 每个机器上都会有一个完整的模型,将数据分散到各个机器,分别计算梯度。
图内并行(又称模型并行)
- 每个机器分别负责整个模型的一部分计算任务。
1.1 图间并行用的非常多,会包含两种方式进行更新
同步:收集到足够数量的梯度,一同更新,下图上方
异步: 即同步方式下,更新需求的梯度数量为1,下图下方
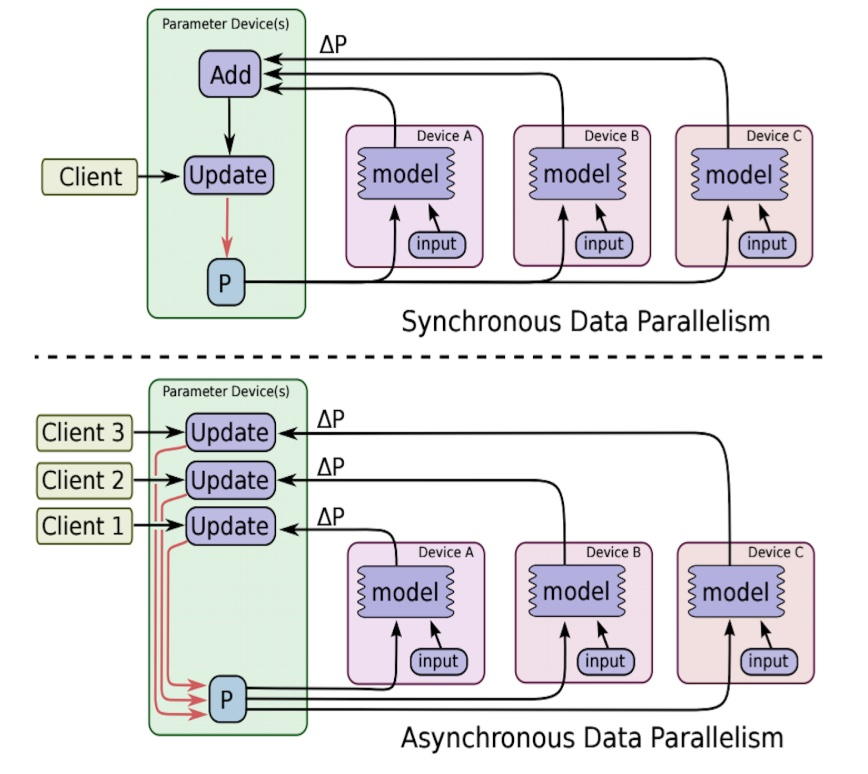
注:PS(parameter server):维护全局共享的模型参数的服务器
1.2 实现方式
- 单机多卡
- 多机单卡
TensorFlow多机多卡实现思路。多机多卡的分布式有很多实现方式,比如:
- 将每个GPU当做一个worker
- 同一个机器的各个GPU进行图内并行
- 同一个机器的各个GPU进行图间并行
比如说第三种:模型实现封装成函数、将数据分成GPU数量的份数、在每个GPU下,进行一次模型forward计算,并使用优化器算出梯度、reduce每个GPU下的梯度,并将梯度传入到分布式中的优化器中
2 单机多卡训练: MirroredStrategy
tf.distribute.MirroredStrategy 是一种简单且高性能的,数据并行的同步式分布式策略,主要支持多个 GPU 在同一台主机上训练。
MirroredStrategy运行原理:
- 1、训练开始前,该策略在所有 N 个计算设备(GPU)上均各复制一份完整的模型
- 2、每次训练传入一个批次的数据时,将数据分成 N 份,分别传入 N 个计算设备(即数据并行)
- 3、使用分布式计算的 All-reduce 操作,在计算设备间高效交换梯度数据并进行求和,使得最终每个设备都有了所有设备的梯度之和,使用梯度求和的结果更新本地变量
- 当所有设备均更新本地变量后,进行下一轮训练(即该并行策略是同步的)。默认情况下,TensorFlow 中的 MirroredStrategy 策略使用 NVIDIA NCCL 进行 All-reduce 操作。
构建代码步骤:
使用这种策略时,我们只需实例化一个 MirroredStrategy 策略:
strategy = tf.distribute.MirroredStrategy()
并将模型构建的代码放入 strategy.scope() 的上下文环境中:
with strategy.scope():
# 模型构建代码
或者可以在参数中指定设备,如:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
即指定只使用第 0、1 号 GPU 参与分布式策略。