为什么UTF-16需要大端小端
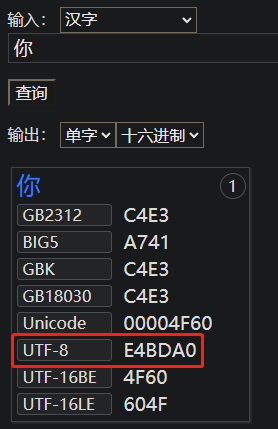
我们使用编码网站查询“你”字的编码。
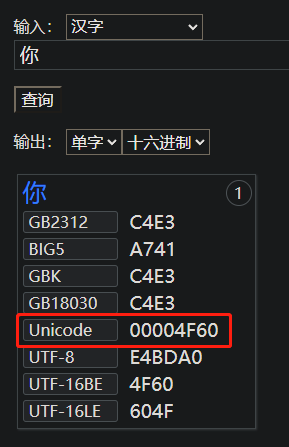
从上面的Unicode来看,我们知道,4F是数据位的高位,60是数据位的低位。数据位的高位低位,就和十进制的百位、十位、个位一样,所以在左边的就是高位,在右边的就是低位。
我们知道一般情况下,一个字符的UTF-16编码会占两个字节,由于大端小端的存在,这两个字节既可以正着放,也可以反着放。
但对于数据位来说,两个字节正着放,和反着放,会对应两个不同字上面去。
- 如果4F是数据高位,60是数据低位:
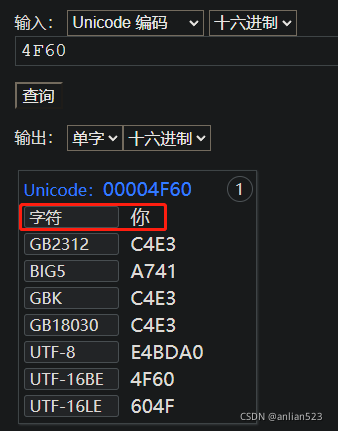
- 如果60是数据高位,4F是数据低位:
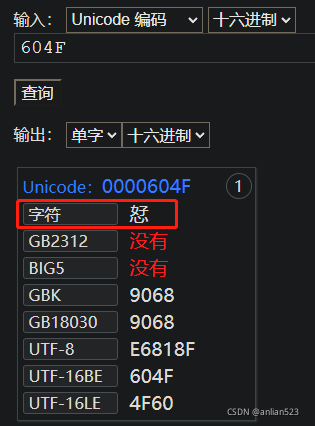
但是由于UTF-16的设计,直接给我们两个字节,我们并不能知道哪个字节是数据高位、哪个字节是数据低位。正如同上面的例子一样,4F既能作为高位,也能作为低位。
什么是大端和小端
- 大端模式:Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
- 小端模式:Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
内存中
我们还是以“你”的UTF16编码——4F60为例,现在有一个指针char* pointer指向的这片内存来保存4F60:
- 如果是大端模式,那么应该:
*pointer = 0x4F;
*(pointer+1) = 0x60;
- 如果是小端模式,那么应该:
*pointer = 0x60;
*(pointer+1) = 0x4F;
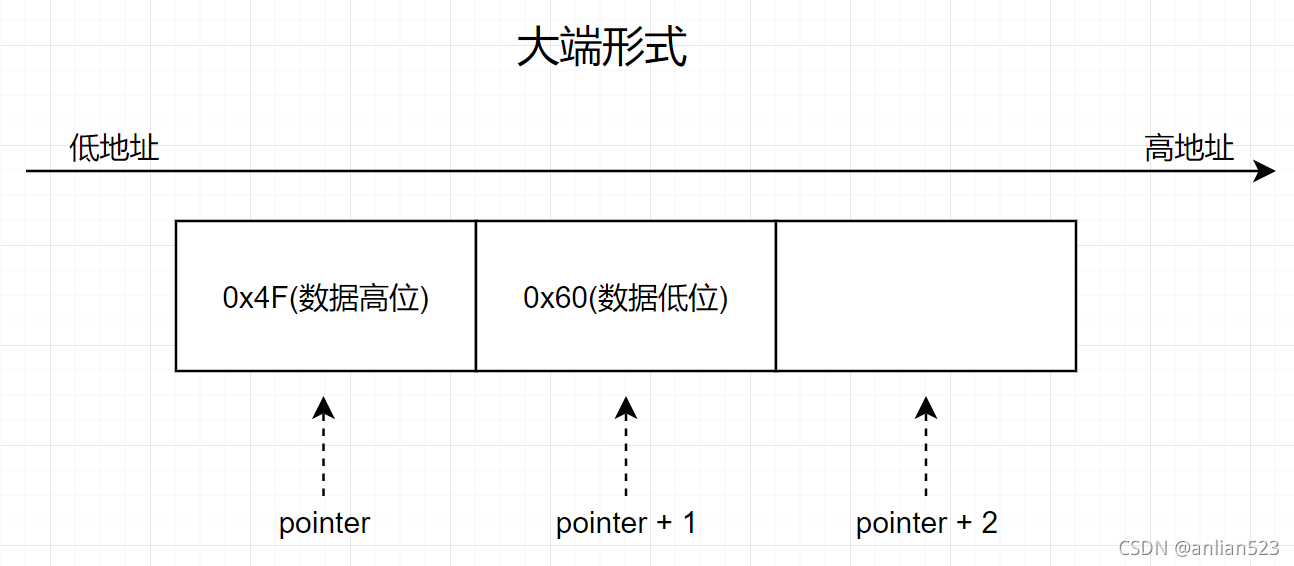
上图则为4F60的大端形式。大端模式才是我们直观上的认为的模式。
文件中
我们这里以一个txt文件为例,使用py3读取文本文件的二进制内容,文件的第一个字节为为低地址,后面的字节为高地址。
f = open("新建文本文档.txt", mode = "rb")
content = f.read()
for i in content:
print("\\x%X"%i, end="")
f.close()
上面的python代码用来读取二进制内容。
大端形式
如上图,如果使用UTF-16大端的编码方式,打印结果为:
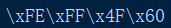
这里先读到4F后读到60,确实是大端模式。文件开头如果依次读到FE和FF,那么接下来的每两个字节,都会被看作大端模式。
小端形式

如上图,如果使用UTF-16小端的编码方式,打印结果为:
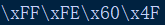
这里先读到60后读到4F,确实是小端模式。文件开头如果依次读到FF和FE,那么接下来的每两个字节,都会被看作小端模式。
为什么UTF-8不需要大端小端

由于UTF-8的设计,一个字符对应的各个字节,是能够区分出 哪个是数据高位、哪个数据低位的,所以不需要。上表中,第一个字节就属于是 数据高位。
使用如下py代码读取如上文本:
f = open("新建文本文档.txt", mode = "rb")
content = f.read()
for i in content:
print("\\x%X"%i, end=" ")
print()
for i in content:
print(bin(i), end=" ")
f.close()
打印结果为:

由于第一个字节的开头符合1110----,可以得知这个字符还剩余两个字节需要读取。
不管是内存、还是文件,程序总是从低地址读到高地址,所以UTF-8必须把 可以指示剩余字节数的那个字节 放到低地址,其余字节依次放到高地址。