前言
这里的方法同样可以保存数组或者别的数组,这里主要以字典为主要对象。
正文
pickle,numpy都可以进行文件持久化。
编写以下代码测试性能
import numpy as np
import pickle as pkl
import time
a = {
'a': np.random.randn(8000, 2, 30, 160),
'b': np.random.randn(8000, 2, 30, 160),
'c': np.random.randn(8000, 2, 30, 160),
'd': np.random.randn(8000, 2, 30, 160),
'e': np.random.randn(8000, 2, 30, 160),
}
time_a = time.time()
np.save('data.npy', a)
time_b = time.time()
np.save('data.npy', a)
time_c = time.time()
print('numpy 保存耗时:{}'.format(time_b-time_a))
print('numpy 读取耗时:{}'.format(time_c-time_b))
time_a = time.time()
with open('data.pkl', 'wb') as f:
pkl.dump(a, f, protocol=pkl.HIGHEST_PROTOCOL)
time_b = time.time()
with open('data.pkl', 'rb') as f:
a = pkl.load(f)
time_c = time.time()
print('pickle 保存耗时:{}'.format(time_b-time_a))
print('pickle 读取耗时:{}'.format(time_c-time_b))
运行结果为:
numpy 保存耗时:3.349184274673462
numpy 读取耗时:4.978081941604614
pickle 保存耗时:6.070725202560425
pickle 读取耗时:2.0159759521484375
文件大小比较,首先是numpy的大小为:

pickle大小为:
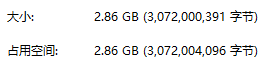
pickle的保存性能比numpy慢两倍,读取快两倍。最后保存的文件大小一样。
然后探究保存后的文件大小与存取性能之间的关系,首先更改代码为:
import numpy as np
import pickle as pkl
import time
import matplotlib.pyplot as plt
import os
x = []
np_save = []
np_load = []
pkl_save = []
pkl_load = []
s = time.time()
for i in range(25):
size = 1000 * (i + 1)
a = {
'a': np.random.randn(size, 2, 30, 160),
'b': np.random.randn(size, 30, 160),
'c': np.random.randn(size, 2, 30, 160),
'd': np.random.randn(size, 2, 30, 160),
'e': np.random.randn(size, 2, 30, 160),
}
time_a = time.time()
np.save('data.npy', a)
time_b = time.time()
np.save('data.npy', a)
time_c = time.time()
np_save.append(time_b-time_a)
np_load.append(time_c-time_b)
time_a = time.time()
with open('data.pkl', 'wb') as f:
pkl.dump(a, f, protocol=pkl.HIGHEST_PROTOCOL)
time_b = time.time()
with open('data.pkl', 'rb') as f:
a = pkl.load(f)
time_c = time.time()
pkl_save.append(time_b-time_a)
pkl_load.append(time_c-time_b)
x.append(os.path.getsize('data.npy') / (1024. * 1024. * 1024.))
plt.figure()
ax1 = plt.subplot(211)
ax1.plot(x, np_save, label='numpy')
ax1.plot(x, pkl_save, label='pickle')
plt.xlabel('size (G)')
plt.ylabel('save time (s)')
plt.legend()
ax2 = plt.subplot(212)
ax2.plot(x, np_load, label='numpy')
ax2.plot(x, pkl_load, label='pickle')
plt.xlabel('size (G)')
plt.ylabel('load time (s)')
plt.legend()
print(time.time()-s)
plt.show()
结果为:

可以看出,pickle在读取上一直占优,即使文件较大,读取时间上升也较为平缓。在保存上两者拉不开明显差距,但一般来看numpy是有优势的,比如我们不管后面的剧烈上升,而是看较为平缓的一段:

可以看出numpy在读取上,6g以下是明显占优的,6g以上两者会难分难解

观察发现,大文件还是使用pickle比较好
扫描二维码关注公众号,回复:
13466709 查看本文章
