Collection 集合概览
https://blog.csdn.net/weixin_34743057/article/details/113082889
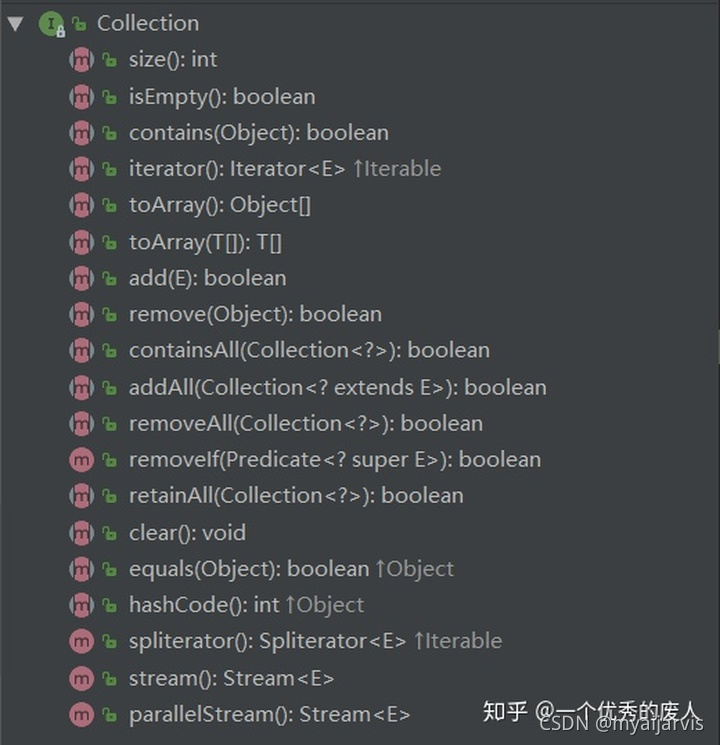
Collection 接口定义了以上待实现的方法。比如:
size() 计算容器长度
isEmpty() 是否为空
contains() 是否包含某个对象
containsAll() 是否包含另一个集合的所有对象
iterator() 上层接口 iterable 的方法,用于生成迭代对象,遍历对象
add() 添加一个对象
add() 添加另一个集合的所有对象
remove() 移除一个对象
removeAll() 移除所有对象
toArray() 把集合转换成数组
retainAll() 是否与另一个集合有交集
教程 https://www.bilibili.com/video/BV1sy4y1q79M?p=6
总结
length //数组长度
//length() 字符串长度 char charAt(下标) 取字符串中的某一个字符
//Char[] toCharArray() 将字符串变成的字符数组
size() //数组,链表,队列,栈的长度
add(值) //默认加在最后一个 数组,链表,队列
add(下标,值) //数组,链表,队列
get(下标) //获取该下标的元素 数组,链表
indexOf(元素) // 获取元素的下标 链表
peek() //获取队头or栈顶元素
poll() //队头元素出队并返回该元素
push() //入栈
pop() //出栈并返回栈顶元素
// 堆为优先队列
数组
package 基础;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Iterator;
public class ArrayTest {
/*
//Arrays是针对数组的工具类,可以进行 排序,查找,复制填充等功能
1.copyOfRange 数组复制
copyOfRange(int[] original, int from, int to)
// 第一个参数表示源数组
// 第二个参数表示开始位置(取得到)
// 第三个参数表示结束位置(取不到)
int[] b = Arrays.copyOfRange(a, 0, 3);
2.toString() 转换为字符串
Arrays.toString(a);
3.sort 排序
Arrays.sort(a);
4.binarySearch 搜索
查询元素出现的位置
使用binarySearch进行查找之前,必须使用sort进行排序
如果数组中有多个相同的元素,查找结果是不确定的
System.out.println("数字 62出现的位置:"+Arrays.binarySearch(a, 62));
5.equals 判断是否相同
Arrays.equals(a, b)
6.fill 填充
Arrays.fill(a, 5);//[5,5,5,...]
*/
public static void main(String[] args) {
/**
* 传统方法创建数组
*/
//省略了new int[],效果一样
int[] a = {
1, 2, 3};
System.out.println("a:" + Arrays.toString(a));
//分配空间同时赋值 不介意指定长度
int[] b = new int[]{
1, 2, 3};
System.out.println("b:" + Arrays.toString(b));
int[] c = new int[3];//作为int类型的数组,默认值是0
for (int i = 0; i < a.length; i++) {
c[i] =(int) (Math.random() * 100)//随机1到100
}
System.out.println("c:" + Arrays.toString(c));
//二维数组类似
int d[][] = new int[][]{
{
1,2,3},
{
4,5,6},
{
7,8,9}
};
/**
* Java数据结构创建数组
*/
/*
基本数据类型: boolean,char,byte,short,int,long,float,double
封装类类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
为了能够将这些基本数据类型当成对象操作,Java为每 一个基本数据类型都引入了对应的包装类型(wrapper class),
int的包装类就是Integer
<>里面的是java里的泛型,泛型就是基本类型的封装类,<>作用就是确定到底存放什么类型
*/
//动态数组列表 不用担心数组长度,系统会自动分配
ArrayList<Integer> arrayList = new ArrayList<>();
/*
初始化:
1、不初始化容量
ArrayList arr1 = new ArrayList(); //不初始化刚开始的数组容量,当数组容量满时数组会自动一当前数组容量的2倍扩容
2、初始化容量
ArrayList arr2 = new ArrayList(3);//初始容量为3
3、用一个集合或数组初始化
ArrayList arr3 = new ArrayList(a); //a为集合或数组
*/
for (int i = 0; i < a.length; i++) {
arrayList.add(i+1);
}
System.out.println("arrayList:" + arrayList.toString());
//添加元素
arrayList.add(99);//默认添加在末尾
arrayList.add(3,100);//add(下标,值) 数组下标从0开始
System.out.println("arrayList添加元素:" + arrayList.toString());
//获取元素
System.out.println("arrayList[0]:" + arrayList.get(0));//get(下标)
System.out.println("99在数组中的下标:"+arrayList.indexOf(99));//indexOf(值)
//更新元素
arrayList.set(0,101);//set(下标,值)
System.out.println("arrayList更新元素:" + arrayList.toString());
//删除元素
arrayList.remove(0);//remove(下标)或者remove(值)
System.out.println("arrayList删除元素:" + arrayList.toString());
//数组长度
System.out.println("c length:" + c.length);
System.out.println("arrayList length:" + arrayList.size());
//遍历数组
for (int i = 0; i < arrayList.size(); i++) {
System.out.println("arrayList["+i+"]:" + arrayList.get(i));
}
// 使用iterator遍历
Iterator<Integer> it = arrayList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// 使用增强for循环进行遍历 只能取值,不能修改数组里的值
for (Integer num : arrayList) {
System.out.println(num);
}
//java8 lambda表达式
arrayList.forEach(item->System.out.println(item));
//查找元素
System.out.println("arrayList contains 99 ?:" + arrayList.contains(99));//contains(值)
//数组排序
Arrays.sort(a);//有s
Collections.sort(arrayList); //有s
System.out.println("arrayList 正序:" + arrayList.toString());
Collections.sort(arrayList,Collections.reverseOrder()); //倒序
System.out.println("arrayList 倒序:" + arrayList.toString());
}
}
链表
package 基础;
import java.util.LinkedList;
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list);
list.add(2,99);
System.out.println(list);
System.out.println(list.get(2));
System.out.println(list.indexOf(2));
list.set(1,100);
System.out.println(list);
list.remove(1);
System.out.println(list);
System.out.println(list.size());
}
}
队列
Queue只是一个接口
用LinkedList实现修改队列比较快
peek() 获取队头元素
poll() 队头元素出队并返回该元素
package 基础;
import java.util.LinkedList;
import java.util.Queue;
public class QueueTest {
public static void main(String[] args) {
/*
Queue只是一个接口,用LinkedList实现修改队列比较快
peek() 获取队头元素,poll() 队头元素出队并返回该元素
*/
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
queue.add(2);
queue.add(3);
System.out.println(queue);
System.out.println("peek() 获取队头元素:"+queue.peek());
System.out.println("poll() 队头元素出队并返回该元素:"+queue.poll());
System.out.println(queue);
while (!queue.isEmpty()){
System.out.println(queue.poll());
}
}
}
栈
package 基础;
import java.util.ArrayList;
import java.util.Stack;
public class StackTest {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println(stack);
System.out.println("peek() 获取队头元素:" + stack.peek());
System.out.println("pop() 队头元素出队并返回该元素:" + stack.pop());
System.out.println(stack);
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
哈希表
map
package 基础;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class HashMapTest {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1,"hanweiwei");
map.put(2,"lihua");
map.put(3,"xiaohong");
System.out.println(map);
//修改
map.put(2,"jack");
System.out.println(map);
System.out.println(map.get(2));//get(键)
System.out.println(map.containsKey(2));
System.out.println(map.containsValue("jack"));
//遍历
// for (int i = 1; i < map.size(); i++) {
// System.out.println(map.get(i));
// }
// 1. entrySet遍历,在键和值都需要时使用(最常用)
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
// 2. 通过keySet或values来实现遍历,性能略低于第一种方式
// 遍历map中的键
for (Integer key : map.keySet()) {
System.out.println("key = " + key);
}
// 遍历map中的值
for (String value : map.values()) {
System.out.println("key = " + value);
}
// 3. 使用Iterator遍历
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
// 4. java8 Lambda
// java8提供了Lambda表达式支持,语法看起来更简洁,可以同时拿到key和value,
// 不过,经测试,性能低于entrySet,所以更推荐用entrySet的方式
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
/*
如果只是获取key,或者value,推荐使用keySet或者values方式;
如果同时需要key和value推荐使用entrySet;
如果需要在遍历过程中删除元素推荐使用Iterator;
*/
}
}
set
package 基础;
import java.util.HashSet;
public class HashSetTest {
public static void main(String[] args) {
//不重复
HashSet<Integer> set = new HashSet<>();
set.add(10);
set.add(8);
set.add(9);
set.add(1);
set.add(1);
set.add(5);
System.out.println(set);
System.out.println(set.contains(9));
set.remove(10);
System.out.println(set);
}
}
堆
package 基础;
import java.util.*;
public class PriorityQueueTest {
public static void main(String[] args) {
//PriorityQueue本身的逻辑结构是一棵完全二叉树,而它的存储结构是一个数组。因为完全二叉树层次遍历的结果刚好是一个数组。
//PriorityQueue 优先队列
PriorityQueue<Integer> minHeap = new PriorityQueue<>();//小顶堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());//大顶堆
minHeap.add(10);
minHeap.add(8);
minHeap.add(9);
minHeap.add(11);
minHeap.add(2);
maxHeap.add(10);
maxHeap.add(8);
maxHeap.add(9);
maxHeap.add(11);
maxHeap.add(2);
System.out.println(minHeap);
System.out.println(maxHeap);
//取堆顶元素
System.out.println(minHeap.peek());
System.out.println(maxHeap.peek());
//删除堆顶元素并返回该值
System.out.println(minHeap.poll());
System.out.println(maxHeap.poll());
//遍历
while (!minHeap.isEmpty()) {
System.out.println(minHeap.poll());
}
}
}
双指针
- 普通双指针:两个指针往同一个方向移动
- 对撞双指针:两个指针面对面移动(一个向左,一个向右)
- 快慢双指针:s slow,f fast
滑动窗口
解决数组定长连续子串的问题
比如求某个数组中k个连续的元素组成最大值是多少?
递归
四要素
- 接收的参数
- 返回值
- 终止条件
- 递归拆解:如何递归下一层
先递归进入最底层,然后回过来再来处理问题。
//206.反转链表
public ListNode reverseList(ListNode head) {
if(head==null||head.next==null)
return head;
ListNode p=reverseList(head.next);
head.next.next=head;
head.next=null;
return p;
}
结合
- 回溯su法
- DFS
- 分治法
分治法
大问题切割成一个个不可再分的小问题,然后求出小问题的解,最后把小问题的解合并起来就是大问题的解。

回溯法

//22.括号生成
class Solution {
public List<String> generateParenthesis(int n) {
List<String> res=new ArrayList<>();
backTracking(n,res,0,0,"");
return res;
}
//left 左括号的个数,right 右括号的个数
public void backTracking(int n,List<String> res,int left,int right,String str){
if(left<right) return;
if(left==n&&right==n){
res.add(str);
return;
}
if(left<n) //左括号的个数小于总括号个数
backTracking(n,res,left+1,right,str+"(");
if(left>right) //左括号的个数大于右括号个数
backTracking(n,res,left,right+1,str+")");
}
}
DFS
应用:二叉树搜索,图搜索
回溯法=DFS+剪枝
DFS:每一条路径走完再回溯
BFS
//938.二叉搜索树的范围和
public int rangeSumBST(TreeNode root, int low, int high) {
if(root==null) return 0;
int result=0;
Queue<TreeNode> queue=new LinkedList<>();
queue.add(root);
while(queue.size()>0){
int size=queue.size();
while(size>0){
TreeNode cur=queue.poll();
if(cur.val>=low&&cur.val<=high){
result+=cur.val;
}
if(cur.left!=null){
queue.add(cur.left);
}
if(cur.right!=null){
queue.add(cur.right);
}
size--;
}
}
return result;
}
//102.二叉树的层序遍历
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) {
return result;
}
Queue<TreeNode> q = new LinkedList<>();
q.add(root);
while (q.size() > 0) {
int size = q.size();
ArrayList<Integer> list = new ArrayList<>();
while (size > 0) {
TreeNode cur = q.poll();
list.add(cur.val);
if (cur.left != null) {
q.add(cur.left);
}
if (cur.right != null) {
q.add(cur.right);
}
size--;
}
result.add(new ArrayList<>(list));
}
return result;
}
并查集
- union:合并两个元素为一个节点
- find:找到某个元素的根节点
贪心算法
核心思想:每一步做出的都是当前看起来最好的选择(只是局部的最优选择,而不是整理的最优条件)
记忆化搜索
目的:减少重复计算,降低时间复杂度
例如 509.斐波那契数列
//使用一个map把计算过的值存起来,每次计算的时候先看map中有没有,如果有就表示计算过,直接从map中取,如果没有就先计算,计算完之后再把结果存到map中。
class Solution {
public int fib(int n) {
return fib(n, new HashMap());
}
public int fib(int n, Map<Integer, Integer> map) {
if (n < 2)
return n;
if (map.containsKey(n))
return map.get(n);
int first = fib(n - 1, map);
int second = fib(n - 2, map);
int res = (first + second);
map.put(n, res);
return res;
}
}
动态规划
三要素
- 初始条件
- 状态转移方程式
- 终止状态
详细教程:https://leetcode-cn.com/problems/fibonacci-number/solution/dong-tai-gui-hua-tao-lu-xiang-jie-by-labuladong/
//509.斐波那契数列
class Solution {
// 动态规划的四个步骤
public int fib(int n) {
if (n <= 1) return n;
// 1. 定义状态数组,dp[i] 表示的是数字 i 的斐波那契数
int[] dp = new int[n + 1];
// 2. 状态初始化
dp[0] = 0;
dp[1] = 1;
// 3. 状态转移
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
// 4. 返回最终需要的状态值
return dp[n];
}
}
// 状态数组空间压缩
public int fib(int n) {
if (n <= 1) return n;
// 只存储前两个状态
int prev = 0;
int curr = 1;
for (int i = 2; i <= n; i++) {
int sum = prev + curr;
prev = curr;
curr = sum;
}
return curr;
}