作为一款网络编程框架,很多时候,netty的生产使用具有较高的相似性,参考一款成熟的产品如何使用netty进行网络通讯,无疑会加深我们对netty的理解,帮助我们更好的将netty应用于生产实践,本文就跟大家一起分析下RocketMq中是如何使用netty的,希望对你有借鉴意义;
我将从以下几个方面进行讲解:
1.EventLoopGroup的构造原则,线程数多少合适,以及一个EventLoop的高频面试题
2.rocketMq的客户端服务端,分别设置了哪些ChannelOption,各自代表什么含义
3.通用的心跳、会话管理机制是怎样运作的
4.客户端与服务端如何对话,通信协议要考虑哪些东西
5.如何拿到响应结果,同步等待,还是异步回调,超时处理怎么做
代码走起,rocketMq的netty服务端与客户端代码基本集中在
org.apache.rocketmq.remoting.netty.NettyRemotingServer
org.apache.rocketmq.remoting.netty.NettyRemotingClient
先看服务端
1.服务端EventLoopGroup的构造技巧与注意事项,以及一个EventLoop的高频面试题
EventLoopGroup的构造方法,涉及到的几个关键点需要说明下:
1).关于netty有个常见的面试题,EventLoop何时被创建,new一个无参的EventLoopGroup时,netty会创建多少个线程(也即EventLoop),我们跟进EpollEventLoopGroup,看看它的无参构造
明确了,无参构造启动2倍CPU核数的线程数;那在构造时,到底指定多少线程数合适呢?
正常情况下,服务端需要两个EventLoopGroup,boosGroup用于轮询并处理selector连接事件,通常情况下1个线程就够用了,workGroup轮询并处理selector读写事件,也就是真正的业务逻辑,线程处理业务逻辑过程中阻塞的时间越短,线程数应越接近CPU核数,实际操作时,可以参考这个公式:线程数=CPU核数*(任务执行总时间/(任务执行总时间-阻塞时间)),最佳线程数和和CPU数量成正比、和阻塞时间成反比,如果都是计算密集型任务,线程数=cpu核数就好,因为计算密集型任务会打满cpu,线程数再多cpu也来不及调度了,相反如果任务需要等待磁盘操作、网路响应,更多地线程就有助于提高吞吐能力、并发能力;需要说明的是,boosGroup监听到新链接并建立新链接SocketChannel之后,会为该socketChannel分配一个eventLoop线程,这个线程就来源于workGroup,一个eventLoop线程可以对应任意个连接,每个连接只会对应一个eventLoop线程,这意味着netty中每个连接都是单线程处理的,完美的避开了并发问题;
线程处理过程中,如果需要阻塞较长时间,强烈推荐分配一个专门的线程池,因为work线程是所有连接公用的,一旦阻塞较长时间,影响范围很大;netty中,在添加Handler时,可以指定一个EventLoopGroup,该Handler的所有操作都会在该EventLoopGroup的线程中执行,无需我们自己管理线程池了
再看看EventLoop何时被创建,同样是在构造函数中,继续跟到父类
新建的EventLoop都存在children数组中,EventLoop与线程一一对应,其核心逻辑都在run方法中,run方法主要干两件事,1.轮询selector中IO事件并处理 2.处理自身taskQueue中的任务(使用者可以通过EventLoop的execute、schedule方法提交任务,任务就存在其taskQueue中),后面有机会会详细说一说EventLoop;
2).回到第一张图中,EpollEventLoopGroup构造函数的第二个参数是个ThreadFactory,它就干了一件事,给线程起名字,通过一个AtomicInteger成员变量,保证线程名的唯一性;在构造线程时,给它起个名字算是必备操作了,一来规范化线程名,二来通过日志可以明确区分属于哪类线程,对日志分析和问题排查非常有利;




2. rocketMq的服务端客户端,分别设置了哪些ChannelOption,各自代表什么含义
先看服务端:
SO_BACKLOG:用于指定服务端连接队列长度,当服务器连接处理线程全忙时,已完成三次握手的请求会被临时存放在连接队列中(还没来得及被accept),队列满后会拒绝新收到的连接请求。默认情况下,该值为200左右,对于连接数不太多的场景,默认值就够了,像常见RPC框架的服务端就没有设置。RocketMq需要支持更高频的连接请求,所以使用了推荐值1024;
SO_REUSEADDR:TCP四次挥手的最后阶段,主动发起关闭的一端会处于TIME_WAIT状态,该状态下的socket所用端口无法被复用(默认时间2MSL=4分钟);在服务端客户端架构中,通常是服务端主动发起连接关闭,在大量连接的场景中,无论是频繁关闭连接和新建连接,还是服务端重启,都需要端口资源,4分钟太长了,不能忍。SO_REUSEADDR=true就是通知内核,如果端口忙,但socket状态是TIME_WAIT,可以立即重用端口;因为端口资源限制,该配置算是服务端必备的了;
SO_KEEPALIVE:TCP有内置的连接保活机制,保活并不是把挂掉的连接整活,而是只留下有效的连接,及时释放无效连接资源;由于netty提供的IdleStateHandler可以非常方便、灵活的实现心跳维持和会话管理,所以一般不需要使用TCP自带的KEEP_ALIVE;会话管理下面会做专门的介绍;TCP_NODELAY:TCP/IP协议中针对TCP默认开启了Nagle算法,会对包的发送进行限制,至少满足下面任意一个条件才可以发出,1.写缓冲区的字节数超过指定阈值 2.之前发出的所有包都已收到ack
其好处是减少网络开销和发送接收两端的压力,坏处就是存在发送延时,对于延时敏感型、数据传输量比较小的应用,应该选择关闭Nagle算法,关闭方式为设置TCP_NODELAY=trueSO_SNDBUF与SO_RCVBUF:每个socket都有一个receive缓冲区和send缓冲区,在调用socket的read send时,其实仅仅是操作缓冲区,read仅仅从reveive缓冲区拿数据,拿不到就阻塞等待对端数据从网络过来。send仅仅将数据放入send缓冲区,缓冲区满了就等待;对于TCP协议来说,由于有滑动窗口控制,如果接收端read缓冲区已满,还未来的及处理,则会在回复发送端的ack中缩小窗口值,提示发送端降低发送速度,甚至暂时不发;缓冲区的大小影响的是两端发送接收的速度,没有一个标准的参考值,实际生产时应该由测试结果决定,通常情况下,默认的值就够了,也就是不需要设置;
服务端参数小结,可以看到,服务端在设置option时,有两类方法,一类是option(),作用的对象是服务端监听端口的socket(我们称之为父socket),一类是childOption,作用的对象是与客户端连接的socket(我们称之为子socket),哪些参数该设置在父socket哪些设置在子socket上,我没找到一个满意的说法,我自己的推测是子socket只用于数据传输,与数据发送接收有关的option应该设置在子socket上;如果你看到标准答案,记得告诉我一声...
再看客户端:
除了CONNECT_TIMEOUT_MILLS,其他参数在服务端中都已经介绍过,CONNECT_TIMEOUT_MILLS顾名思义,连接超时时间,超过该时间还没连上服务端,则抛出timeout异常,也算是客户端的标配了;由于客户端只与服务端建立少量的连接,所以不需要设置SO_REUSEADDR


3.通用的会话管理机制是怎样运作的
上面说了,netty提供的IdleStateHandler可以用于心跳维持和会话管理,我们先看看IdleStateHandler源码,再看看通用的会话管理机制怎么玩
IdleStateHandler在构造时需要指定三个时间值,单位是秒,分别表示read事件、write事件 、read+write事件的检测周期,正常情况下,指定第三个参数即可,会同时判断读写事件是否超时;
在IdleStateHandler的初始化方法中,启动了一个一次性定时任务
allIdleTimeNanos是allIdleTimeSeconds算出的纳秒值,更精确,从ctx.executor获取到的就是当前channel对应的EventLoop,AllIdleTimeoutTask任务干了啥呢
根据最新读写事件发生的时间,算出与当前时间的差值,如果大于指定的时间间隔,说明超时了,会触发一个IdleStateEvent事件并往channel中传播方便进行超时处理,并再次提交一个一次性定时任务;如果小于指定时间间隔,说明还没超时,则再次提交一个一次性定时任务,这里的延时时间为算出的时间差值,而不是指定的时间间隔,不然就不对了;
channelIdle方法用于传播IdleStateEvent事件,属于入站事件,会往next方向(后添加的)的下一个ChannelInboundHandler传播,传播方向与顺序详细说明参考我上一篇handler事件传播顺序;
接下来的重点就在IdleStateEvent事件的处理上了,IdleStateEvent传播到ChannelInboundHandler时,会调用其userEventTriggered方法,一般情况下,服务端处理方式比较统一,直接关闭连接、释放资源;客户端处理方式分为两种情况,1)如果服务端连接资源可以预估为不太紧缺,则发送心跳包给服务端,保证服务端不会关闭当前连接。2)反之,如果服务端连接资源紧缺,则客户端的方式与服务端一致,直接关闭连接,释放资源,下次请求时重建连接,防止请求频率较低的客户端占用服务端连接资源;对于rocketMq来说,显然属于第2种情况,所以服务端和客户端的方式都是关闭连接;而像rpc框架这种,就属于第1种情况,客户端定时发送心跳包,保持连接活跃。有点需要特别注意的是,第1种情况下,服务端超时时间要>=2*客户端超时时间,为的就是给足客户端发送心跳的时间





4.客户端与服务端如何对话,通信协议要考虑哪些东西
客户端服务端之间要想互相通信,还需要有⼀套传输协议来⽀持,传输协议就是端与端之间对话的语⾔,在设计传输协议时,并没有太多规范和要求,只要是通信双⽅都能正确理解对端传来的内容,并且没有歧义就好了;
既然传输协议是⼀种语⾔,就得考虑如何断句,不然一串话发过去对方都不知道怎么解析了,比如你来一句"我见到你很开心",对端收到后显然不知道到底谁开心;现代语言的断句方式就是标点符号,通讯语言也可以这样玩,http1就是基于分隔符的协议,遇到/r/n就做个断句;但是,分隔符断句必然存在这样一个问题,⽆论定义什么字符作为分隔符,理论上,它都有可能会在传输的数据中出现。为了区分“数据内的分隔符”和真正的分隔符,在加上分隔符之前,必须先对其做转义,收到数据之后再转义回来,这是个⽐较麻烦的过程,还要损失⼀些性能。
更加实⽤的⽅法是,在每句话前⾯加⼀个表示这句话⻓度的数字,收到数据时,按照⻓度来读取就可以了,比如"4我见到你3很开心","3我见到4你很开心"对方就能正确解析了;
事实上,在基于TCP制定网络协议时,必然要面对的粘包拆包问题,其本质原因就是双方没有约定好解析数据包的规则,netty提供的基于分隔符和长度的解码器可以很好地解决上述问题;
当然了,除了定制TCP协议,直接使用http协议也是一个不错的选择,在选型时,通常基于以下几点考虑:
1.选用http,一定是基于其普适和通用的要求,http的使用非常广泛,不管是手机、浏览器、还是现在的物联网设备,都可以非常方便的支持http,http协议可以算作普通话;
2.选用定制tcp,一般是基于性能的需求,由于定制的tcp协议的接入成本更高,所以一般只用作内部交流,不具有普适性,算作内部黑话;
如果你设计一款内部系统的通讯工具,比如公司内部的rpc框架,消息队列,可以考虑定制tcp协议;如果要设计的是一款开放的工具,比如物联网通讯工具,就应该重点考虑http协议。虽然http协议因为报文头废信息比率较多,影响了传输性能,但对大部分场景来说,其性能要求并没有高到对协议本身有要求的程度,这是一个开放的、互联互通的时代,保证基本性能的前提下,通用和兼容性才是最重要的事情;
本文讨论的是rocketMq,出于对性能的高要求,rocketMq采用的是定制tcp协议,所以就绕不开上面说的粘包拆包问题,rocketMq中约定使用基于长度进行数据解码,我们先看看rocketMq的数据包构造,rocketMq通讯都采用的统一结构体类RemotingCommand,分为长度部分、header部分、以及body部分:
header部分:分为两块,第一块是我标红的部分,长度为固定的4byte,第1个byte存的是序列化类型,后3个byte存的是header内容长度的后24位;第二块就是header内容了,设header内容长mbyte,那header的总长度就=(4+m)byte
body部分:设长度为nbyte
长度部分:4byte,就是header部分+body部分的长度之和,也就是(4+m+n)byte
看看怎么解码的:
LengthFieldBasedFrameDecoder是netty提供的基于长度的解码器,通过构造函数告诉它怎么解析数据包,这里一共传了5个参数,第1个:maxFrameLength,代表数据包的最大长度,超过则丢弃;第2个:lengthFieldOffset,表示长度域的偏移量,rocketMq中,长度域从0开始;第3个:长度域的长度,这里是4byte;第4个:要调整的长度,这里不需要调整,是0;第5个:跳过的字节数,这里是4,表示最终解析出的数据包里不需要包含长度域;那解析出来的frame包就是这样:
接下来,就可以从frame中解析出真正需要的信息了,即序列化类型,header内容,body内容;让我们看看RemotingCommand的组成,我们在定制tcp协议时,可以参考这样的设计:
flag:RemotingCommand的类型,0表示请求,1表示响应, 用一个实体类表示请求与响应,可以减少不必要的编解码工作量,算是必备字段了;code:flag为0时,code表示具体的请求类型,flag为1时,code表示响应码,remark表示响应描述; 必备字段;version: 必备字段,多版本共存时,必须有字段可以区分具体是哪个版本,才知道要怎么处理;extFields:如果想要结构体具有很好的扩展性,这个字段也是必备的;language:为了支持多种语言;body:请求体和响应体,二进制数组类型,不同的请求和响应类型,其请求体和响应体一般由不同的实体类表示,发送前序列化为字节流塞到body里,处理时再反序列化出来,也是 必备字段;serializeTypeCurrentRPC:序列化类型,默认为json方式,body的处理一定需要序列化与反序列化,如果要 支持多种序列化方式,这个也是必备字段;opaque:请求ID,唯一标识一个请求的字段,用于收到响应时,匹配到原请求,然后进行处理; 必备字段和通常的方法调用不一样,因为隔着一层网络,请求出去,和响应回来是互相独立的过程,响应回来时必须能匹配到原先的请求,才能正确处理;这就引出了下面的问题




5.如何拿到响应结果,同步等待,还是异步回调
rocketMq中恰巧两种都有,同步方式涉及到 异步转同步处理,其处理方式也是通用的,看代码:
我把它分为4部分,1.构造阻塞体future对象,用上面说的请求ID作为key,存入一个map中;2.发送网络请求 ;3.通过阻塞体阻塞等待结果;4.处理完成或者请求失败后,移除map中的阻塞体对象
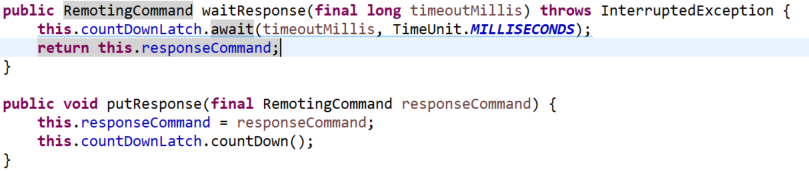
看看阻塞等待的实现方式:
这里用的是CountDownLatch,除此之外,还有个CompletableFuture,异转同场景中,就它哥俩最常用;响应回来时,根据请求ID从map里找到这个阻塞对象,调用图中的putResponse,这样waitResponse就可以返回并拿到响应结果了;需要注意的是,超时处理也相当关键,必须要杜绝无限等待;
异步比同步更简单,构造阻塞体future对象时,传入一个回调对象,请求发出后就不用管了,响应回来时同样是先找到future对象,然后调用其中回调对象的回调方法即可;

先就写这么多了,后面想到其他可写内容再添加.....