tun设备多用来在用户态模拟网络转发设备,比如隧道的端点,路由器,NAT网关等,但作为转发设备的模拟,其编程模型和作为数据始发站的服务器编程模型有着大不同。
我们先看一下最简单的tun程序模型:
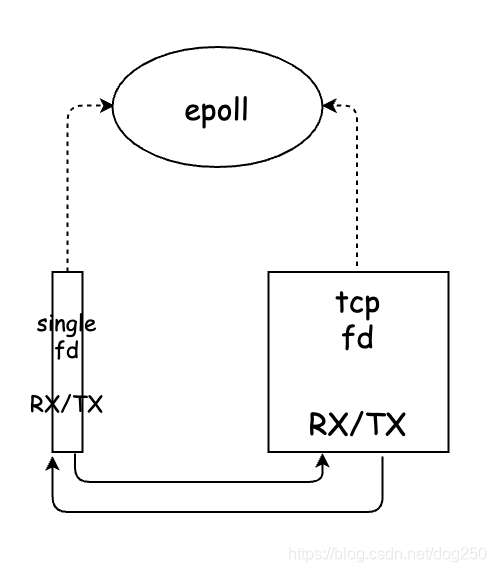
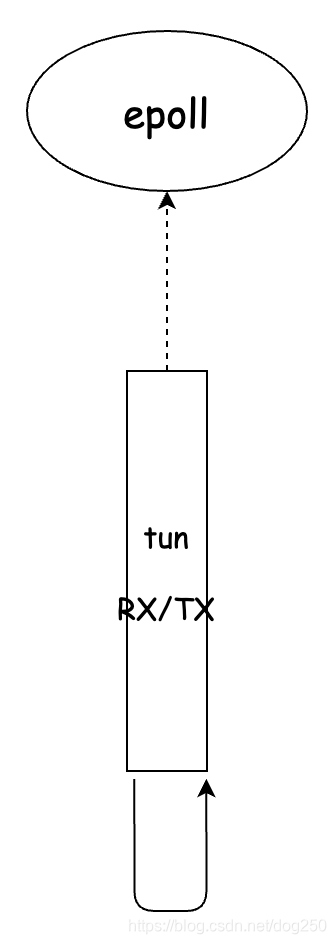
tun字符设备和TCP/UDP socket连接作为文件描述符被均等地poll,将从一个fd收到的数据经过加工之后写入另一个fd。
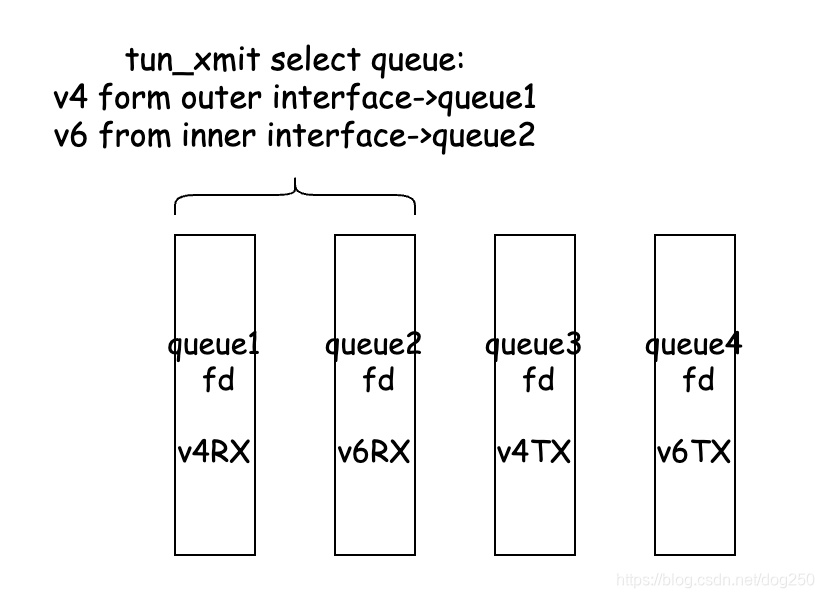
但这种思路是错误的。是不是觉得性能底下,而tun设备有多队列模式,可以将一个tun虚拟网卡打开为多个文件描述符,下面的样子:
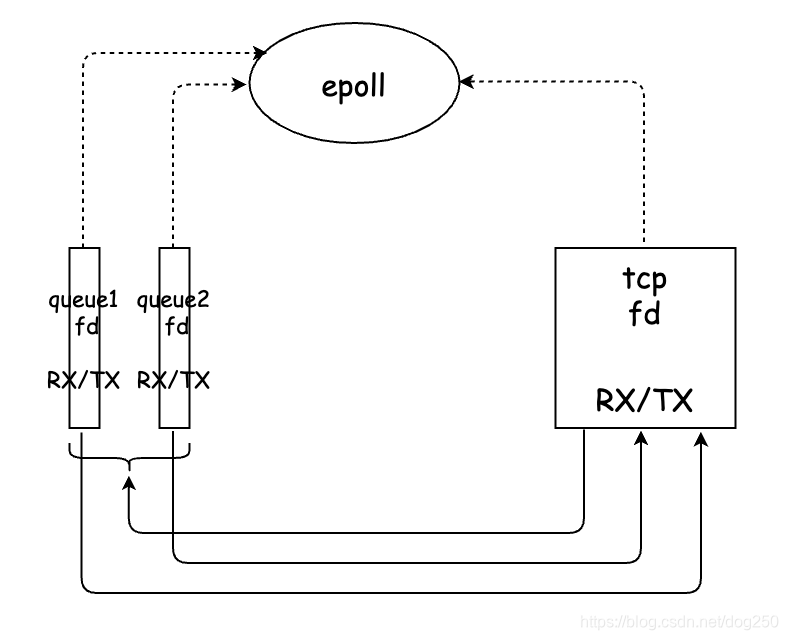
但还是不对。哪里出了问题呢?接下来我基于上述的 单体结构 逐步优化。
所谓的单体结构就是不考虑并发的情况下,如何让一个单独的流(单独的一个五元组)以最高效的方式通过tun模拟的转发路径。
作为转发设备和作为端设备处理数据最大的区别在于:
- 转发设备一定要在不同线程分别处理同一条流的两个方向的数据流,以模拟全双工。
- 端点设备最好在相同的线程处理同一个连接,以最大化cache利用率。
那么,我们把tun的多队列区分成发送(TX)和接收(RX)两个方向,两个文件描述符分别被处理,如此一来,TCP/UDP便需要在单独的线程处理网络接收:

然而还是有问题,TCP的接收和发送并不独立啊。
这里简单说一下TCP全双工的问题。
TCP被设计为一个双向全双工的协议,这是不是意味着在同一个TCP连接中,双向都能跑到带宽极限呢?
我们先看一个标准的TCP管道:
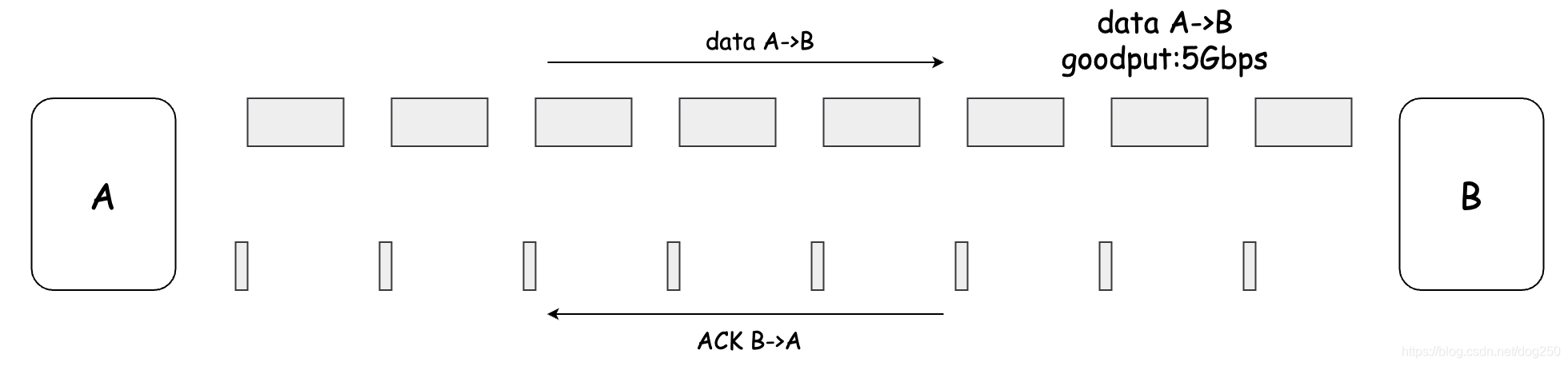
如果希望双向都跑到带宽极限,那就必须让ACK被对向的数据流捎带传输,如下图:
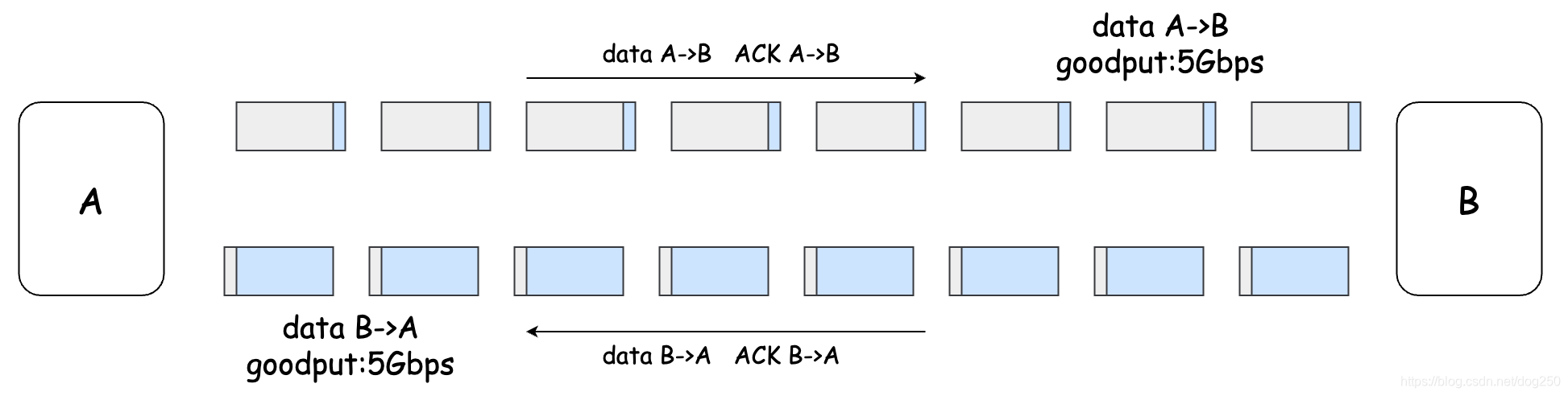
这显然是协议规范里说得很清楚的,并且是可以达到的一种状态。但TCP在实际使用的时候,它是个socket,TCP全双工说的是它实际发送和接收数据,但数据送到发送buffer以及从接收buffer接收数据是通过socket进行的,socket是不能同时send和recv的。除非buffer里数据足够且ACK平滑到来,否则很难控制双向的管道保持满载。
我用下面的程序进行了测试:
...
pthread_create(&threads[0], NULL, receiver, NULL);
pthread_create(&threads[1], NULL, sender, NULL);
sleep(10000);
return 0;
}
void *sender(void *arg)
{
while (1) {
send(csd, buffer, 1400, 0);
}
return 0;
}
void *receiver(void *arg)
{
while (1) {
recv(csd, rbuffer, 1400, MSG_DONTWAIT);
}
return 0;
}
双向带宽相比单向,会折半的。这里之所以使用1400的大小,是考虑到tun设备处理的都是网络报文,并不会按照流式数据进出socket缓冲区。当然,流式的测试你可以用netcat进行:
# 单向
nc -l -p 1234 >/dev/null
pv /dev/zero |nc -w 1 192.168.56.101 1234 >/dev/null
# 双向
nc -l -p 1234 </dev/zero >/dev/null
pv /dev/zero |nc -w 1 192.168.56.101 1234 >/dev/null
使用UDP socket可解这个问题,但是对于TCP,若要解决这个问题,建立两条独立的连接即可,一个负责发送(TX),另一个负责接收(RX),这就和tun字符设备对应了:

单流情形,这就是正确的做法了。如果是一个隧道server,会有多个client接入,那么就需要提高单线程的buffer能力了:
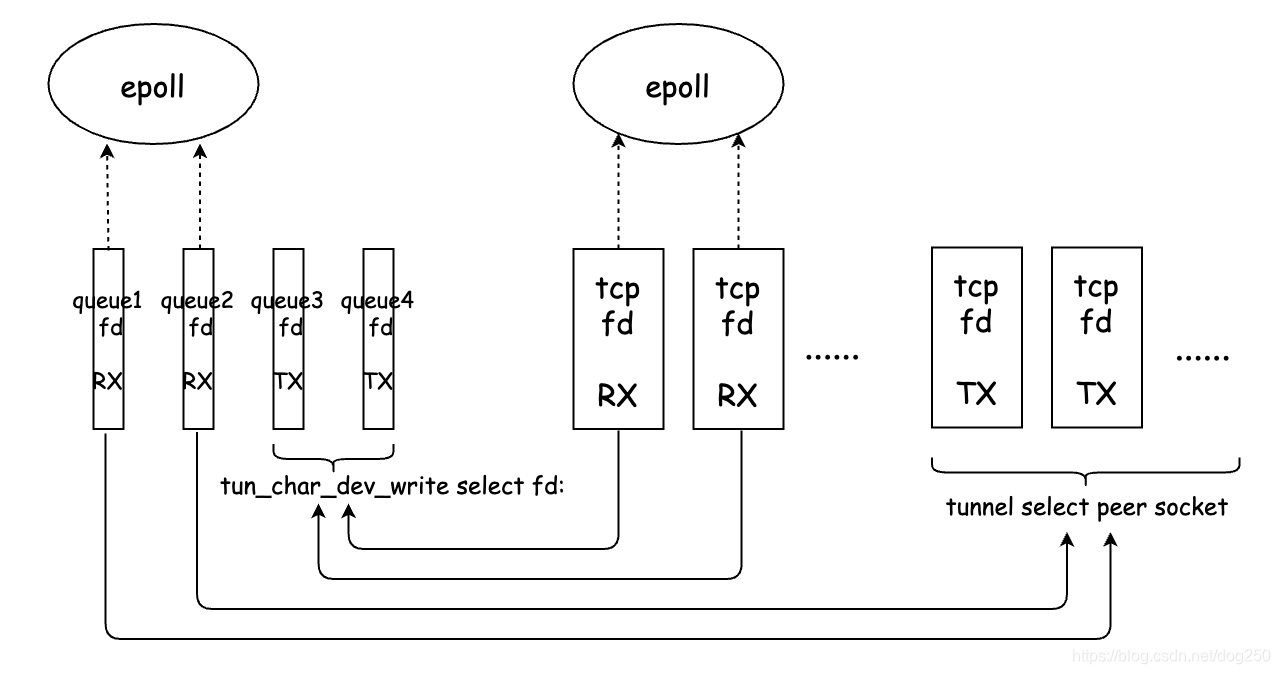
这类似将所有的tun RX队列构建了一个buffer队列,而所有的TCP RX socket则是另一个buffer队列。
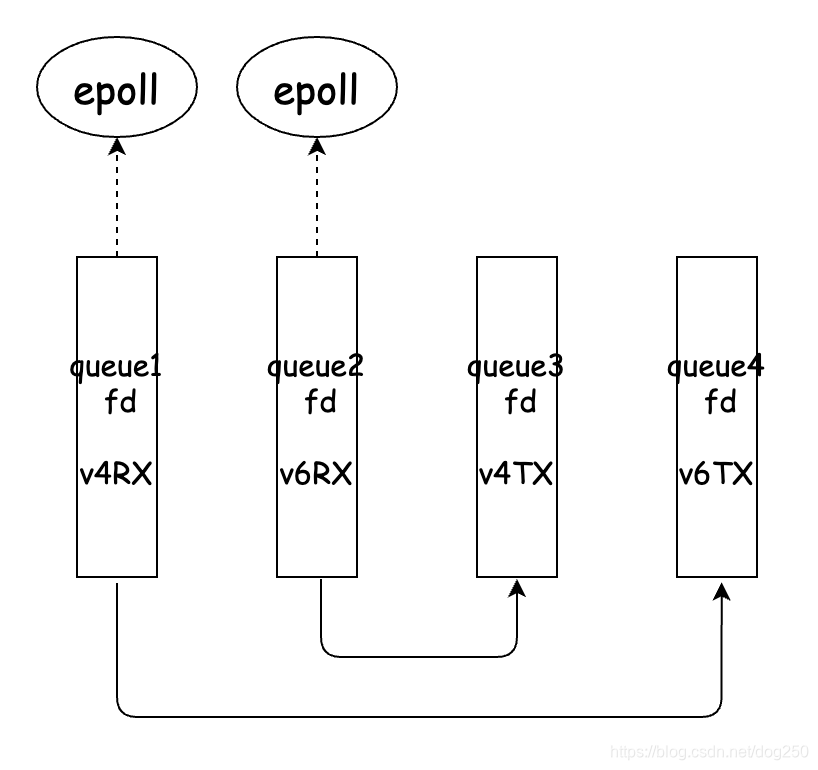
下面是一个队列选择的细节,包括内核xmit时的tun RX队列选择和应用程序write fd时的tun TX队列选择:
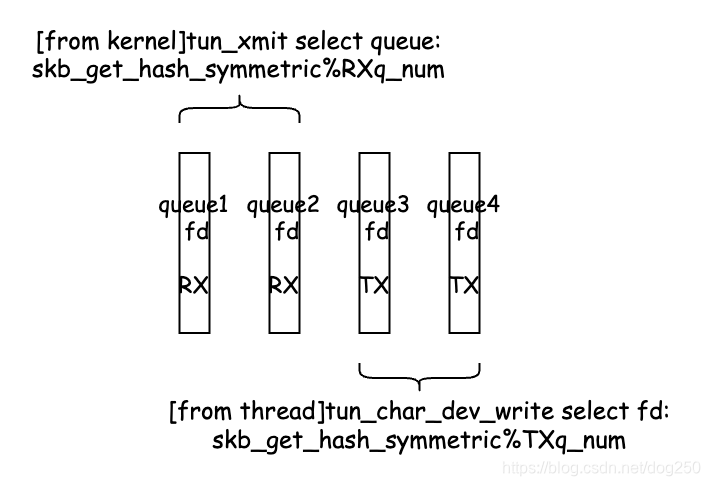
对于同一条流,始终选择同一个队列,这需要多队列tun网卡的steering来协助写队列选择的eBPF程序,该机制详见:
https://lore.kernel.org/patchwork/patch/858162/
虽然以上的布置已经趋于完美,然而现实中让服务器编程框架固化的程序员很难接受创建两个TCP连接独立收发的思路,因此现实的折中是:
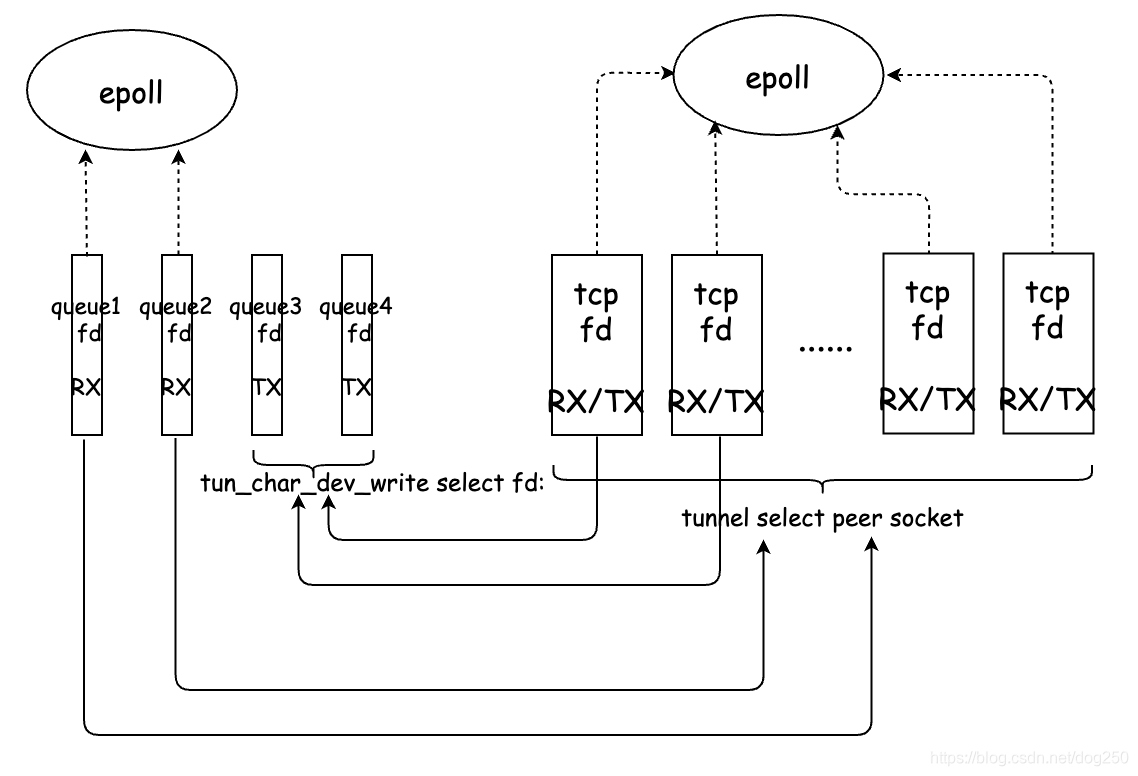
将上述的 单体结构 多线程化就可以应对高并发了,启动多个线程,每个线程执行一个单体逻辑,就可以用tun模拟一个高并发高性能转发设备了。
好了,线程关系摆置好了,接下来呢,绑一下CPU:
- 物理网卡RSS队列向tun队列转交的流程绑在同一个CPU。
- 处理tun RX队列的线程绑在入队CPPU的sibling CPU。
- 处理TCP收包到tun TX fd write流程的线程绑定同一个CPU。
- 处理tun TX队列接收的softirq在tun TX写线程的sibling CPU。
当然了,如果你想用buffer平滑生产和消费,上述任何一个从一个文件描述符到另一个文件描述符的处理流程均可以在buffer处中断并返回,如此一来类似Nginx的那种接力模型就是必须的了。
接下来看另一个tun应用的典型例子,NAT64。
tayga是一个NAT64玩具,它如下:
这个结构侧重数据转发逻辑上来看,是非常错误的,它不光将双向的数据流转发处理串行化了,而且也将多CPU并行处理也串行化了。
NAT64至少需要tun网络的多队列特性:
下面是NAT64单体结构正确的样子:
将上述NAT64单体结构多线程化,就是一个高性能NAT64网关了。(真的是这样吗?不一定,后面会再写一篇单独的文章…)
我常说,转发逻辑编程和服务器编程的思路截然不同,简而言之:
- 服务器编程需要基于连接处理高并发。
- 转发逻辑编程需要基于连接的载荷处理高并发。
如果用服务器编程的思维来看待转发逻辑,多个fd可能代表的是同一条载荷流,如何处理同一条载荷流的不同fd之间的冲突就很重要,稍不慎就会将原本全双工的流退化成半双工,形成畸变。
我也常说,转发逻辑非常适合DPDK/XDP来做,不太适合用服务器框架来做。DPDK直接针对数据流载荷,程序员知道自己在做什么,也就知道应该怎么做。然而,应用服务器处理的是抽象的文件描述符,而程序员对这些文件描述符能做的只是读和写,至于什么时候去读写,就需要更底层的知识而不是更上层的业务逻辑。
耳朵都听出茧子的一句话是 同一个CPU处理同一个连接,以保证cache命中率 ,然而如此处理一个转发流便不对了,对于一个流的转发处理,不同方向的逻辑恰恰要在不同的CPU上处理才能确保不破坏数据流的全双工特征。是吧…
非常令人遗憾的是,现如今绝大多数使用tun的开源软件均未按照正确的方式处理数据流,这可能依然是 会写代码 和 懂网络 之间的隔阂所导致,和大多数人普遍认为的不同,懂协议栈的软件硬件实现细节绝不意味着懂网络,在任何人都可以在简历上写 精通数据面转发 的如今,不知道怎么用tun设备,这是一件憾事。我说的这些当然没有多少人关注,可能也不会得到多少认同,但这恰恰不是在反面印证了什么吗?
是不是见了tun网卡就要构建多线程多队列呢?远远不是!
为了证明这一点,我以我自己为例,以剖析我的愚蠢来说明 代码 和 网络 之间的隔阂。
浙江温州皮鞋湿,下雨进水不会胖。