文章目录
拓扑图
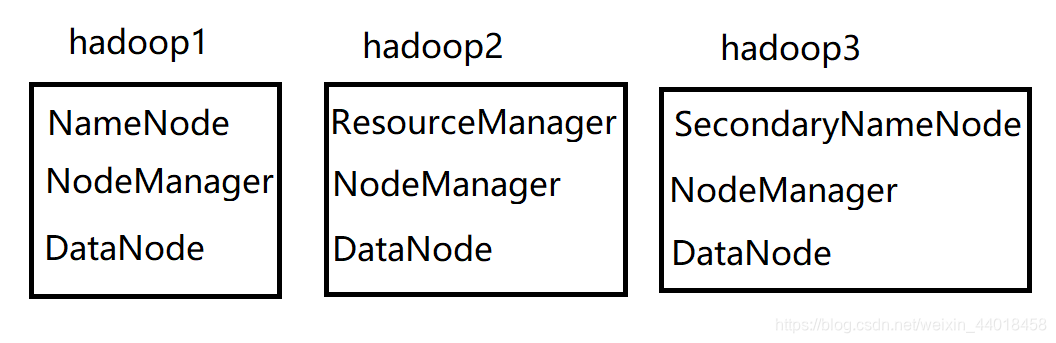
准备工作
- 新建虚拟机 master,安装 Ubuntu
- 配置固定 IP
- 安装必要软件(SSH 服务端、安装 Java 环境、安装 Hadoop,并完成配置)
分布式模式配置
1.修改主机名
先修改一台,克隆虚拟机之后再改其它的
# sudo gedit /etc/hostname
sudo vi /etc/hostname
# hadoop1 虚拟机修改为 hadoop1
# hadoop2 虚拟机修改为 hadoop2
# hadoop3 虚拟机修改为 hadoop3
(注意:只有重启 Linux 系统才能看到主机名的变化)
2.设置 hosts 文件
-
配置 IP 与 HOSTNAME 的映射(IP 根据自己机器情况设置)
# sudo gedit /etc/hosts sudo vi /etc/hosts # 3 台虚拟机都配置一样 # 192.168.13.21 hadoop1 # 192.168.13.22 hadoop2 # 192.168.13.23 hadoop3
3.配置集群/分布式环境
-
slaves
hadoop1 hadoop2 hadoop3 -
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/data/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration> -
hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop3:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
4.ssh 无密码登录
-
生成公钥和密钥
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按 Enter 键就可以了 cd ~/.ssh cat ./id_rsa.pub >> ./authorized_keys # 将公钥赋予给authorized_keys sudo chmod 644 authorized_keys # 修改权限 -
测试是否成功
ssh hadoop1 ssh hadoop2 ssh hadoop3如果不用输入密码,则配置成功
克隆虚拟机
如果启动过伪分布模式
- 删除 tmp 目录(如果有)
- 删除 logs 下的所有文件(如果有)
把上述步骤做完之后再克隆虚拟机会方便很多
更改另外两台主机名
参照 1.修改主机名
更改另外两台虚拟机的 hosts
参照 2.设置 hosts 文件
格式化 namenode
hdfs namenode -format
启动集群
- 在 hadoop1 上运行 start-dfs.sh
- 在 hadoop2 上运行 start-yarn.sh
正确结果如下

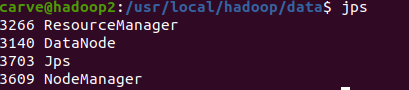

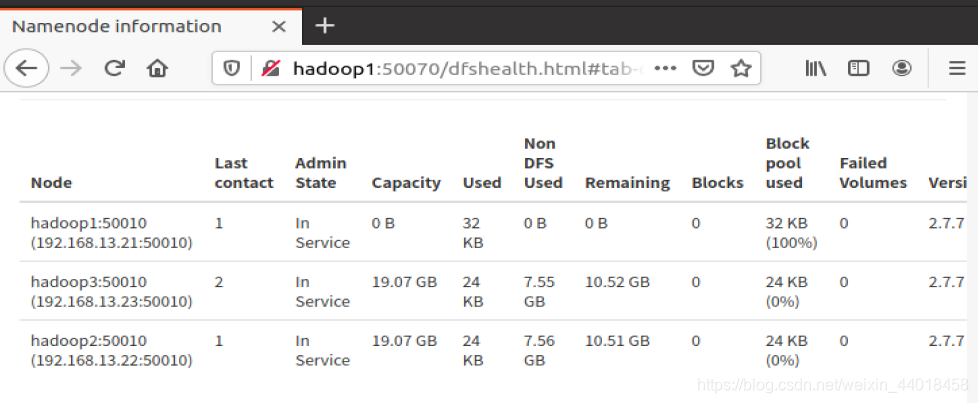
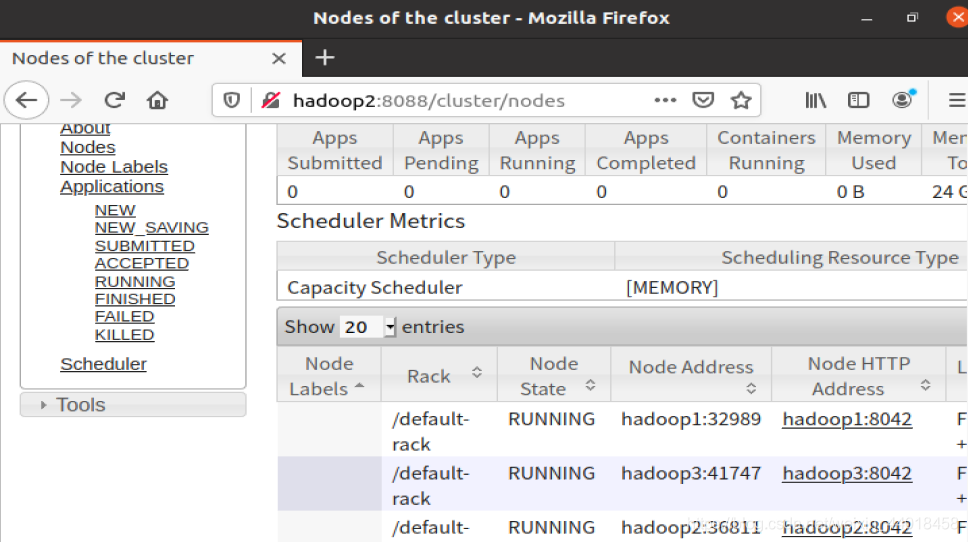
常见错误
-
虚拟机上面的网络图标不见了

解决方法:sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start # 如果出现图标了,则不进行下面步骤 sudo gedit /etc/NetworkManager/NetworkManager.conf # 把false改成true sudo service network-manager restart -
启动集群后 hadoop1 有DataNode,hadoop2、hadoop3 没有 DataNode
解决方法:
编辑 slaves ,看看是否跟下图所示一样

改完之后,把文件复制到另外两台虚拟机上cd $HADOOP_HOME/etc/hadoop rsync -av * hadoop2:$HADOOP_HOME/etc/hadoop rsync -av * hadoop3:$HADOOP_HOME/etc/hadoop并且删除每个 hadoop 虚拟机下的 tmp 目录
cd $HADOOP_HOME/data sudo rm -r tmp在 hadoop1 重新进行格式化
hdfs namenode -format