vscode 下 java 中文注释部分报错
解决方法:1.使用-encoding参数指明编码方式:javac -encoding UTF-8 Test.java
解决方法2:文件编码方式修改为GB2312 使之与系统编码一致
建议:暂时可将文件默认编码方式修改为GB2312
设置->文件编辑器-> 文件->encoding
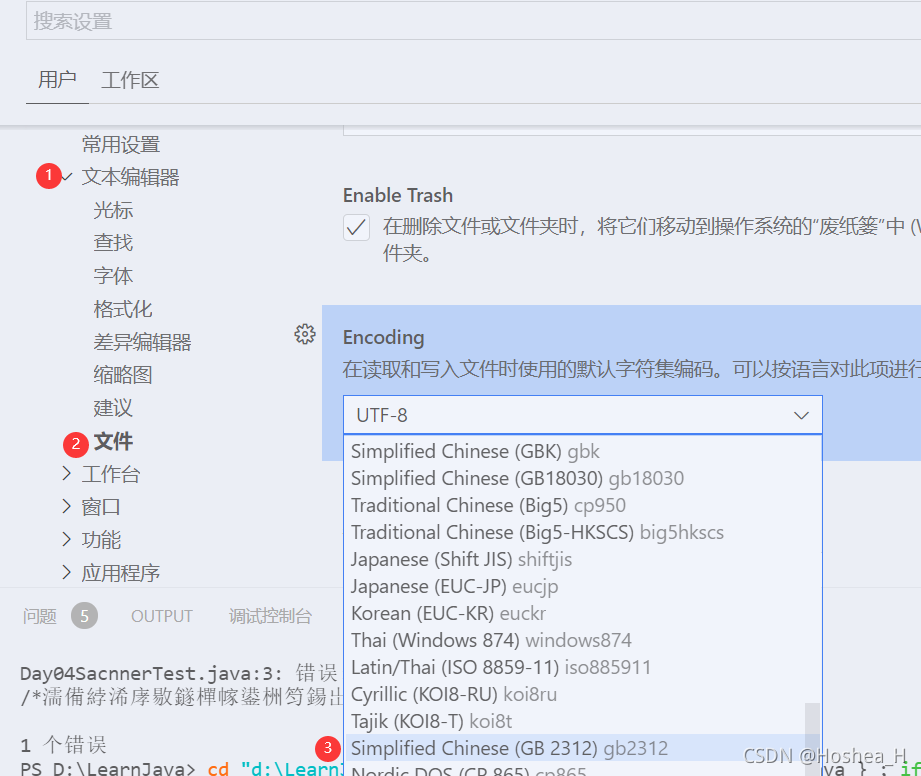
问题所在:由于编码不一致导致错误
问题复现:
环境:jdk8 windows 文件编码默认为UTF-8
问题代码:
System.out.println('*'+'\t'+'*');//93 三者合并
报错信息:
因为使用了chcp 65001 将控制台的编码切换到与文件编码一致。报错显示的乱码
StringTest.java:29: : GBKIJӳַ
System.out.println('*'+'\t'+'*');//93 三?合?
之后使用chcp 936使编码恢复到GB2312
StringTest.java:29: 错误: 编码GBK的不可映射字符
System.out.println('*'+'\t'+'*');//93 涓夎?呭悎骞?
网络搜索信息后得知:
由于JDK是国际版的,我们在用javac编译时,编译程序首先会获得我们操作系统默认采用的编码格式(GBK),然后JDK就把Java源文件从GBK编码格式转换为Java内部默认的Unicode格式放入内存中,然后javac把转换后的Unicode格式的文件编译成class类文件,此时,class文件是Unicode编码的,它暂存在内存中,紧接着,JDK将此以Unicode格式编码的class文件保存到操作系统中形成我们见到的class文件。由于vscode默认是utf-8编码格式,而编译的时候认为文件是GBK编码格式,所以出现了错误。
当我们不加设置就编译时,相当于使用了参数:
javac -encoding GBK Test.java,就会出现不兼容的情况。