
create table t (
id int,
p_date date,
quantity int
);
insert into t values(1001,'2021-01-01',122);
insert into t values(1002,'2021-01-01',41);
insert into t values(1003,'2021-01-01',56);
insert into t values(1001,'2021-01-02',165);
insert into t values(1001,'2021-01-04',165);
insert into t values(1001,'2021-01-06',165);
insert into t values(1002,'2021-01-02',85);
insert into t values(1001,'2021-01-03',123);
insert into t values(1001,'2021-01-04',45);
insert into t values(1002,'2021-01-07',223);
insert into t values(1002,'2021-01-08',213);
insert into t values(1002,'2021-01-09',243);
insert into t values(1003,'2021-01-09',243);
insert into t values(1003,'2021-01-10',243);
insert into t values(1003,'2021-01-12',243);
select * from t;
-- 取出大于100 的数据
select id,p_date,quantity from t where quantity > 100 order by id ;
select
id,
date_sub(t1.p_date, t1.rn),
count(1)
from (
select id,p_date,
row_number() over(partition by id order by p_date) as rn
from t where quantity > 100
) t1
group by id,date_sub(t1.p_date, t1.rn) -- 这里的一个思路就是按照 用户 差值进行分组
having count(1)>=3 -- 判断每一个分组的数据个数
上面这种写法也应该是最能想到的一种思路,也是网上比较多的一种答案

提炼:lag窗口函数 + 累加器思想
-- 数据准备
create table t(
id int,
ts bigint
) ;
insert into t values(1001, 17523641234);
insert into t values(1001, 17523641256);
insert into t values(1002, 17523641278);
insert into t values(1001, 17523641334);
insert into t values(1002, 17523641434);
insert into t values(1001, 17523641534);
insert into t values(1001, 17523641544);
insert into t values(1002, 17523641634);
insert into t values(1001, 17523641638);
insert into t values(1001, 17523641654);
select * from t order by id,ts ;
--
-- 前置知识
select
id,
ts,
lag(ts,1,ts) over(partition by id order by ts) , -- 取上一行 lag(字段,向上第几行,默认值)
lead(ts,1,ts) over(partition by id order by ts) -- 取下一行 lead(字段,向上第几行,默认值)
from t
order by id,ts ;
select
id,
ts,
ts - lag(ts,1,ts) over(partition by id order by ts) -- 取上一行 lag(字段,向上第几行,默认值)
from t
order by id,ts ;
这个就能得到每个点距离上一个点的时间是多久 ,
分组从1开始,那么从第一个点开始一旦 距离上一个时间点的间隔 大于60,计数从0开始一次 累加 1
最终SQL:
select
id,
ts,
sum(if(ts_interval >= 60 ,1,0) ) over(partition by id order by ts) as rn
from (
select
id,
ts,
ts - lag(ts,1,0) over(partition by id order by ts) as ts_interval -- 取上一行 lag(字段,向上第几行,默认值)
from t
order by id,ts
) t1
有这样一个规律当遇到时间间隔大于60的数据进行 累加一 操作,也就是我们通常所说的累加器思想。
类似于流式数据(按时间序列进行排序后)进入累加器中当满足某种条件后(或发生了某种变化后)计数器就加1,这样就把连续的时序数据就区分开了,因为我需要的是把每一次变化都分别放在一个组里,不变的放一个组里,我需要的是观察截止当前发生变化了的次数,那么计数器里面保留的就是截止当前发生变化的次数(可以理解为截止当前在线人数),如果按照这种思想去分组,那么中间没变化的会发生持续一段时间,如果有变化,会显示新增人数,这样不变的数据就被区分出来。
参考:https://blog.csdn.net/godlovedaniel/article/details/118856415

select
id,
dayss
from (
select
id,
dayss,
row_number() over(partition by id order by dayss desc ) as rn
from (
select
id,
days,
datediff(lv, fv) +1 as dayss
from (
select
id,
days,
fv,
lv
from (
select
id,
dt,
days,
first_value(dt) over(partition by id,days order by dt) as fv ,
first_value(dt) over(partition by id,days order by dt desc) as lv
from (
select
id,
dt,
sum(if(rn/86400 >2,1,0)) over(partition by id order by dt) as days
from (
select
id,
dt,
unix_timestamp(dt) - lag(unix_timestamp(dt),1,0) over(partition by id order by dt ) as rn
from t
) t1
order by id,dt
) t1
) t1 group by
id,
days,
fv,
lv
)t1
)t1
)t1 where t1.rn = 1
上面差不多是我花了半个小时写的 ,思路差不多就是按照第二题的思路,按照 >2分组 累加的思想,然后我看了网上的答案,确实后半段搞复杂了 ,hai…
这里主要用了 一些不常用的窗口函数 first_value lag等
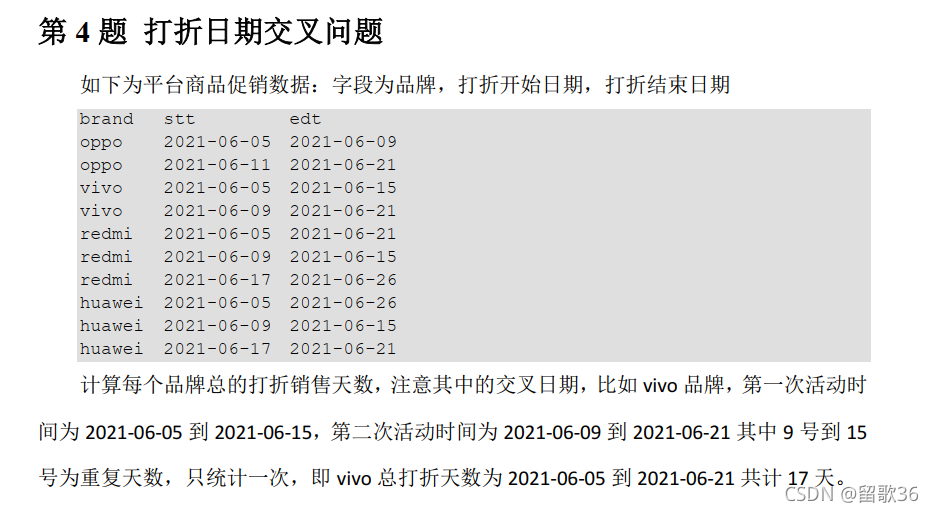
create table t (
brand string,
stt date,
edt date
);
insert into t values('oppo', '2021-06-05','2021-06-09');
insert into t values('oppo', '2021-06-11','2021-06-21');
insert into t values('vivo', '2021-06-05','2021-06-15');
insert into t values('vivo', '2021-06-09','2021-06-21');
insert into t values('redmi', '2021-06-05','2021-06-21');
insert into t values('redmi', '2021-06-09','2021-06-15');
insert into t values('redmi', '2021-06-17','2021-06-26');
insert into t values('huawei', '2021-06-05','2021-06-26');
insert into t values('huawei', '2021-06-09','2021-06-15');
insert into t values('huawei', '2021-06-17','2021-06-21');
select
brand,
datediff(max_edt,min_stt) + 1 as duration
from (
select
brand,
min_stt,
max_edt
from (
select
brand,
min(stt) over(partition by brand)as min_stt,
max(edt) over(partition by brand)as max_edt
from t
) t1 group by brand,min_stt,max_edt
)t1
这道题目还是比较简单,我觉得需要注意两个点吧:1. 使用group 一定要确保其余列也只能有一行数据,有时候不注意就会忘记了 2.datediff(max,min) 其实 得到的结果是天数差值,最后还需要+1

create table t (
id int,
stt timestamp,
edt timestamp
);
insert into t values(1001,'2021-06-14 12:12:12','2021-06-14 18:12:12');
insert into t values(1003,'2021-06-14 13:12:12','2021-06-14 16:12:12');
insert into t values(1004,'2021-06-14 13:15:12','2021-06-14 20:12:12');
insert into t values(1002,'2021-06-14 15:12:12','2021-06-14 16:12:12');
insert into t values(1005,'2021-06-14 15:18:12','2021-06-14 20:12:12');
insert into t values(1001,'2021-06-14 20:12:12','2021-06-14 23:12:12');
insert into t values(1006,'2021-06-14 21:12:12','2021-06-14 23:15:12');
insert into t values(1007,'2021-06-14 22:12:12','2021-06-14 23:10:12');
-- 这题讲真 我没能做出来,我本来的思路是:看每一个时间点有多少人在线,但是感觉又有点麻烦
看了网上的答案,就是新增一列用于标记主播上线线状态: 上线人数+1 下线人数-1
这种思路是我之前没有遇到过得,学习到了 ,挺好的,于是开干:
-- 主要是依据自然时间排序,上线+1 下线-1 ==》 每个时间点的在线人数
select
max(line_count)
from (
select
id,
tt,
sum(action) over(order by tt) as line_count
from
(
select id,stt as tt ,1 as action from t t1
union all
select id,edt as tt,-1 as action from t t2
) t1
) t1
这道题目就给我一种新的思路,可以通过新增列的操作来达到最后的计算目的;