目录
一、概述
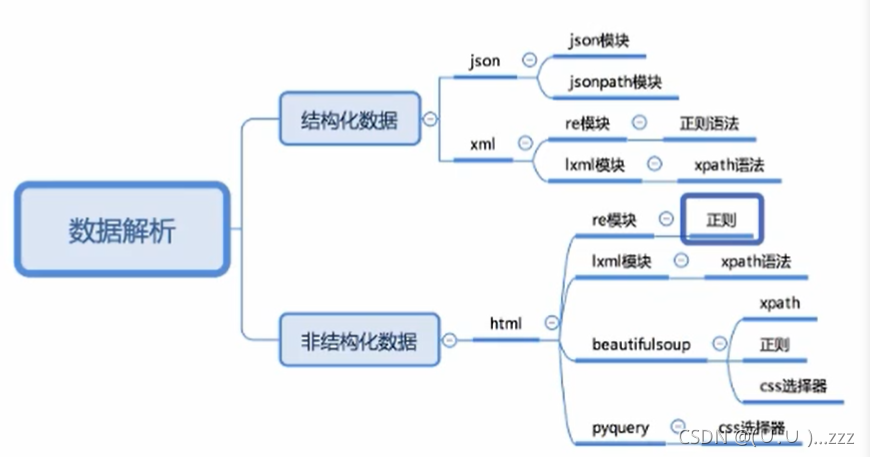
1. 响应内容分类
- 结构化 (json数据、xml数据
- 非结构化 (html
2. xml和html
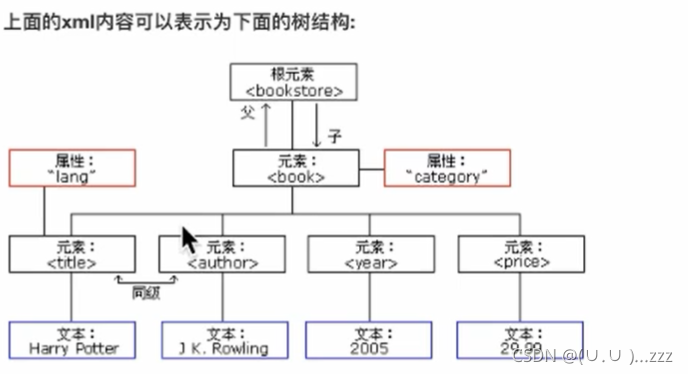
- xml是一种可扩展标记语言Extensible Markup Language,形似html,功能更专注于传输、存储数据,焦点是更好的显示数据
- html 超文本标记语言HyperText Markup Language,更好的显示数据
 -
- 
3. 数据解析
二、jsonpath模块
多层嵌套的复杂字典,jsonpath可以直接提取
- 安装:pip install jsonpath
1. 提取数据的方法
from jsonpath import jsonpath
ret = jsonpath(a, 'jsonpath语法规则字符串')
# a 是那个字典
2. jsonpath语法规则
$ 根节点
. 子节点
.. 内部任意位置
from jsonpath import jsonpath
data = {
'key1':{
'key2':{
'key3': 'nihao'}}}
print(data['key1']['key2']['key3'])
# jsonpath的结果是列表,获取数据需要索引
print(jsonpath(data,'$..key3')[0])
3. jsonpath练习:获取拉钩网城市json文件中城市的名字
http://www.lagou.com/lbs/getAllCitySearchLabels.json

import requests
import jsonpath
import json
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'
}
response = requests.get('https://www.lagou.com/lbs/getAllCitySearchLabels.json',headers=headers)
dict_data = json.loads(response.content) # 先转换为字典,因为jsonpath传入的必须是一个字典
print(jsonpath.jsonpath(dict_data,'$..A..name'))
print(jsonpath.jsonpath(dict_data,'$..name'))
# ['安庆', '安阳', '鞍山', '安顺', '安康', '阿克苏', '澳门', '阿坝藏族羌族自治州', '阿拉善盟', '阿勒泰']
# ['安庆', '安阳', '鞍山', '安顺', '安康', '阿克苏', '澳门', '阿坝藏族羌族自治州', '阿拉善盟', '阿勒泰', '北京', '保定', '包头', '蚌埠', '滨州', '亳州', '宝鸡', '北海', '毕节', '巴中', '保山', '百色', '巴彦淖尔', '白银', '本溪', '巴音郭楞', '白山', '白城', '成都', '重庆', '长沙', '长春', '常州', '沧州', '滁州', '郴州', '赤峰', '常德', '承德', '潮州', '朝阳', '昌吉', '楚雄', '池州', '崇左', '昌都', '东莞', '大连', '德州', '德阳', '大同', '东营', '达州', '大理', '大庆', '丹东', '儋州', '德宏', '定西', '迪庆', '大兴安岭', '鄂州', '鄂尔多斯', '恩施', '佛山', '福州', '阜阳', '抚州', '阜新', '抚顺', '防城港', '广州', '贵阳', '桂林', '赣州', '广元', '贵港', '广安', '甘南', '甘孜藏族自治州', '固原', '杭州', '合肥', '惠州', '哈尔滨', '海口', '呼和浩特', '湖州', '邯郸', '淮安', '菏泽', '衡阳', '衡水', '黄石', '海外', '黄冈', '河源', '淮南', '汉中', '淮北', '鹤壁', '葫芦岛', '红河', '怀化', '黄山', '河池', '哈密', '贺州', '呼伦贝尔', '鹤岗', '黑河', '济南', '嘉兴', '金华', '江门', '济宁', '揭阳', '九江', '焦作', '晋中', '荆州', '吉安', '荆门', '景德镇', '吉林', '锦州', '晋城', '佳木斯', '酒泉', '嘉峪关', '金昌', '济源', '鸡西', '昆明', '开封', '克拉玛依', '喀什', '克孜勒苏', '廊坊', '兰州', '临沂', '洛阳', '聊城', '柳州', '连云港', '泸州', '乐山', '六安', '临汾', '丽水', '拉萨', '龙岩', '漯河', '辽阳', '六盘水', '凉山彝族自治州', '娄底', '吕梁', '丽江', '临夏', '来宾', '辽源', '陇南', '临沧', '林芝', '绵阳', '眉山', '马鞍山', '茂名', '梅州', '牡丹江', '南京', '宁波', '南昌', '南宁', '南通', '南阳', '南充', '宁德', '内江', '南平', '那曲', '怒江', '莆田', '平顶山', '濮阳', '萍乡', '盘锦', '攀枝花', '平凉', '普洱', '青岛', '泉州', '清远', '秦皇岛', '衢州', '曲靖', '齐齐哈尔', '庆阳', '钦州', '黔西南', '黔南', '七台河', '黔东南', '日照', '日喀则', '上海', '深圳', '苏州', '沈阳', '石家庄', '绍兴', '汕头', '三亚', '宿迁', '上饶', '宿州', '韶关', '商丘', '汕尾', '遂宁', '十堰', '邵阳', '三明', '随州', '三沙', '四平', '三门峡', '朔州', '绥化', '松原', '石嘴山', '商洛', '双鸭山', '石河子', '天津', '太原', '唐山', '台州', '泰州', '泰安', '铜仁', '天水', '通辽', '台湾', '铁岭', '铜陵', '通化', '铜川', '天门', '武汉', '无锡', '温州', '潍坊', '乌鲁木齐', '芜湖', '威海', '渭南', '梧州', '武威', '乌兰察布', '吴忠', '文山', '乌海', '西安', '厦门', '徐州', '咸阳', '襄阳', '新乡', '西宁', '香港', '邢台', '孝感', '许昌', '信阳', '湘潭', '咸宁', '宣城', '新余', '湘西土家族苗族自治州', '兴安盟', '西双版纳', '锡林郭勒盟', '忻州', '烟台', '银川', '扬州', '宜昌', '盐城', '宜宾', '岳阳', '阳江', '运城', '雅安', '宜春', '玉林', '益阳', '营口', '永州', '云浮', '榆林', '延边', '延安', '鹰潭', '玉溪', '阳泉', '伊犁', '伊春', '郑州', '珠海', '中山', '淄博', '肇庆', '镇江', '株洲', '湛江', '遵义', '漳州', '枣庄', '张家口', '周口', '驻马店', '长治', '舟山', '资阳', '自贡', '昭通', '张家界', '张掖', '中卫']
三、lxml模块
1. lxml模块和xpath语法
- Xpath(XML path language)在HTML\XML文档中特定元素以及获取节点信息(文本内容,属性值),对元素、属性,进行遍历
2. xpath helper插件
3. xpath 语法_如何找节点
\ 隔开的是标签(节点)
| nodename | 选中该元素 | html |
|---|---|---|
/ |
绝对路径 | /html/head/title |
// |
相对路径 | /html//title |
. |
当前节点 | |
.. |
当前节点的上一节点 | |
@ |
抽取节点后的一个属性 | //title/@href |
text() |
开闭标签之间取文本内容 | //link/text() |
4.xpath语法_节点修饰语法
① 通过索引
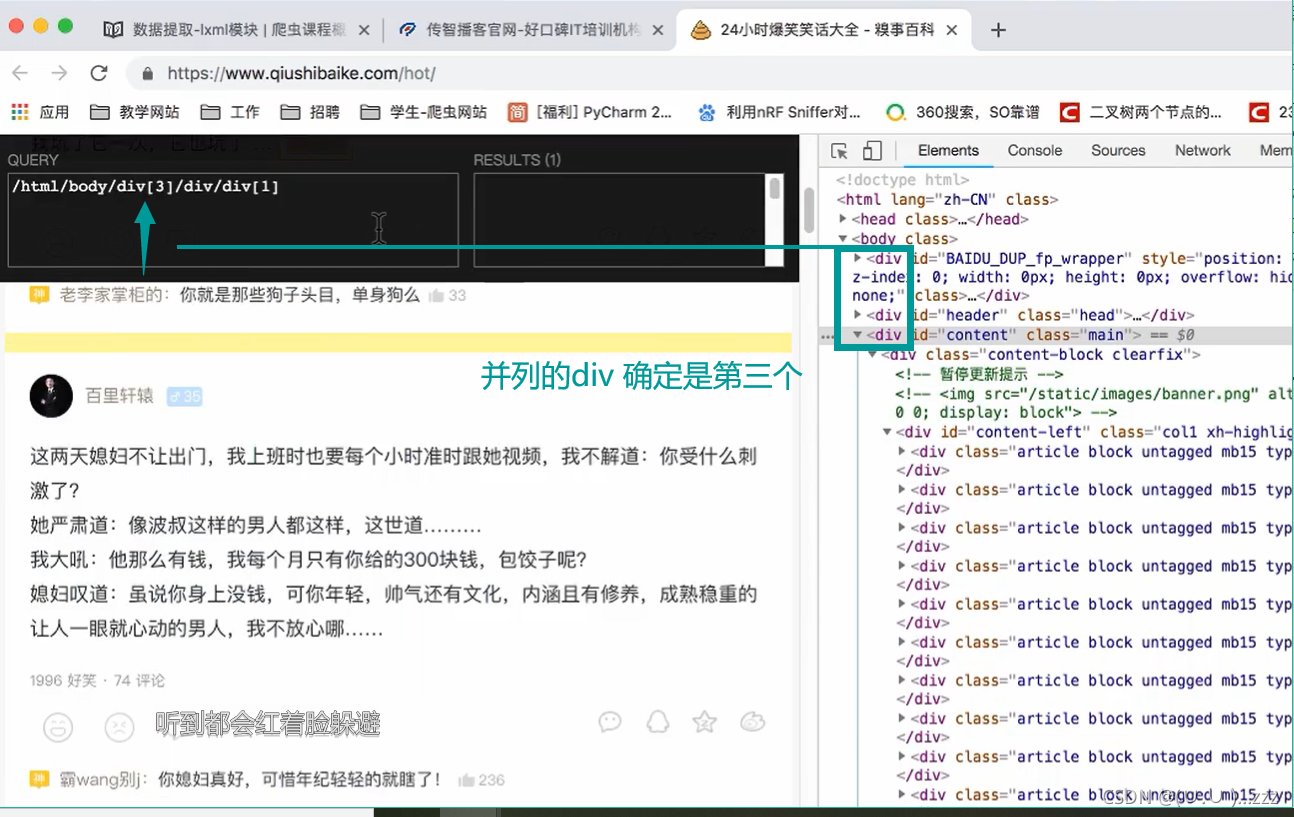
| 路径表达式 | 结果 |
|---|---|
//title[@lang=''eng''] |
选择lang属性值为eng的所有title元素 |
/bookstore/book[1] |
选择属于bookstore子元素的第一个book元素 |
/bookstore/book[last()] |
选择属于bookstore子元素的最后一个book元素 |
/bookstore/book[last()-1] |
选择属于bookstore子元素的倒数第二个book元素 |
/bookstore/book[position()>1] |
选择bookstore下面的book元素,从第二个开始 |
② 通过属性值
| 路径表达式 | 结果 |
|---|---|
//book/title[text()='Harry Potter'] |
选择bookstore下面的title元素,仅选择文本为hp的元素 |
//div[@id="content-left"]/div/@id |
第一个@是使用标签名标签值修饰节点 第二个/@是取属性值 |
③ 通过子节点的值修饰节点
| 路径表达式 | 结果 |
|---|---|
/bookstore/book[price>35.00] |
选择bookstore下面的title元素,仅选择文本为hp的元素 |
④通过包含修饰
| 路径表达式 | 结果 |
|---|---|
//div[contains(@id,"qiushi_tag_")] |
contains(属性名,属性值) |
5. xpath语法_通配符
| 通配符 | |
|---|---|
* |
所有节点 |
@* |
所有节点的属性 |
node() |
匹配任何类型的节点 |
6.使用
from lxml import etree
# html对象 = 模块.类()
html = etree.HTML(text)
List = html.xpath("xpath语法规则字符串")
爬取某个贴吧的评论
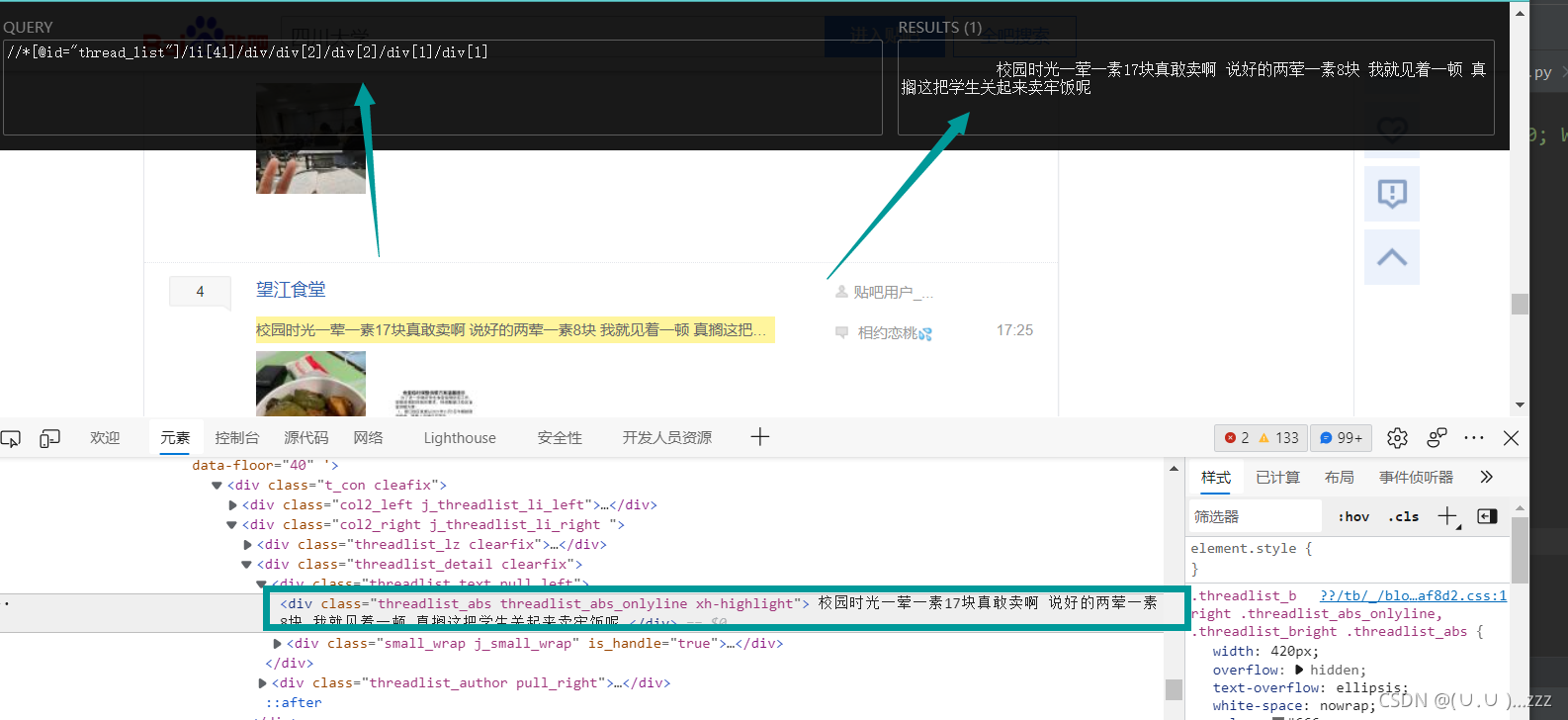
下一页尽量不使用索引

import requests
from lxml import etree
class Tieba(object):
def __init__(self,name):
self.url = "https://tieba.baidu.com/f?kw={}".format(name)
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40"
}
def get_data(self,url):
response = requests.get(url, headers=self.headers)
with open("temp.html","wb")as f:
f.write(response.content)
return response.content
def parse_data(self,data):
# 创建element对象
data = data.decode().replace("<!--","").replace("-->","")
html = etree.HTML(data)
# 筛掉广告的li标签
el_list = html.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')
# print(len(el_list))
# print(el_list)
data_list = []
for el in el_list:
temp = {
}
temp['title'] = el.xpath("./text()")[0]
temp['link'] = 'http://tieba.baidu.com' + el.xpath("./@href")[0]
data_list.append(temp)
# 获取下一页url
# 到最后一页的时候会报错,没有下一页了
try:
next_url = 'https:'+html.xpath('//a[contains(text(),"下一页>")]/@href')[0]
# next_url = 'https:' + html.xpath('//*[@id="frs_list_pager"]/a[12]/@href')[0]
except:
next_url = None
print(next_url)
return data_list, next_url
# 保存数据
def save_data(self, data_list):
for data in data_list:
print(data)
def run(self):
# url
# headers
# 发送请求,获取响应
# 从响应中提取数据( 数据、翻页用的url
# 判断 是否终结
next_url = self.url
while True:
data = self.get_data(next_url)
# 元组接收
data_list, next_url = self.parse_data(data)
self.save_data(data_list)
print(next_url)
if next_url == None:
break
if __name__ == '__main__':
tieba = Tieba(" ")
tieba.run()
改了好久!嘿嘿coding 有趣!