L28 生磁盘的使用

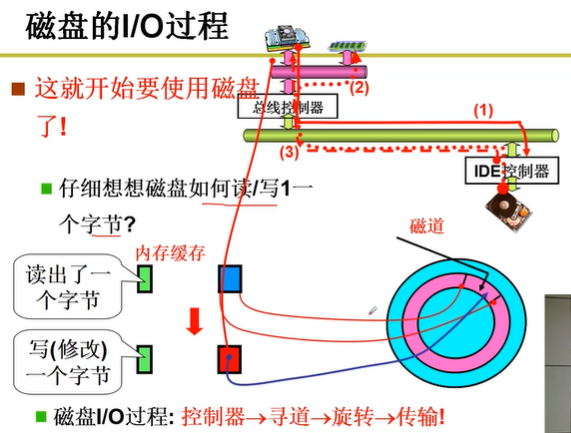
要知道:柱面、盘面、磁道、扇区
磁盘的访问单位是扇区,大小为512字节
磁盘的IO过程:控制器-寻道-旋转-传输

直接使用磁盘的方法:让 CPU 给磁盘控制器发出读写命令,具体就是告诉磁盘控制器读写哪个柱面C、哪个磁头H、哪个扇区S 以及要读写的内存缓存位置和读写长度即可。
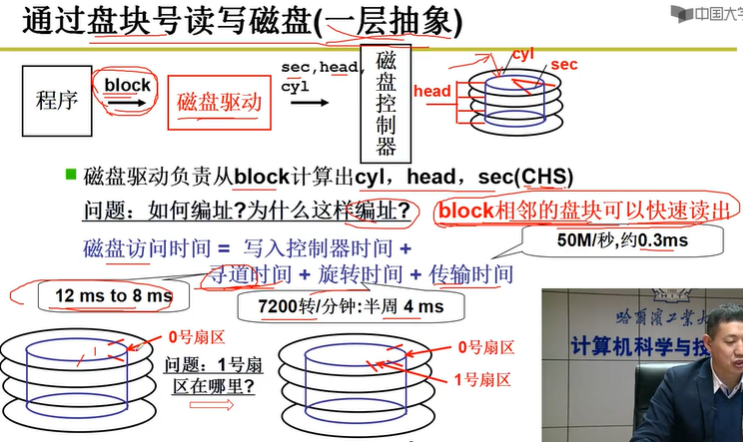
以上方法需要的参数太多,不够方便,应该很自然的想到用将所有扇区编号,这样只需要一个参数即可指定扇区。
磁盘访问时间 = 写入控制器时间 + 寻道时间 + 旋转时间 + 传输时间
其中主要是寻道时间、旋转时间长,同时相邻的盘块应能快速读出
所以编址方式:
1号扇区 应是 0号扇区 旋转方向的 下一扇区
假设一个盘面有六个扇区,则0-5扇区在第一个盘面
6号扇区 应是 0号扇区 竖直方向的 下一扇区

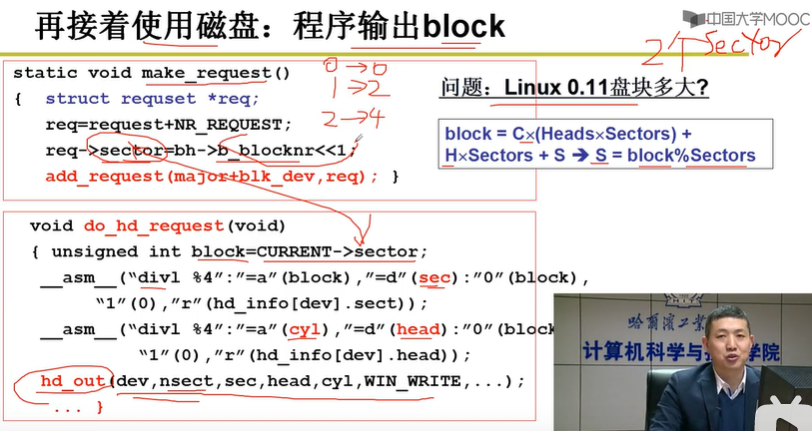
C、H、S 扇区地址对应的扇区号sector = C × (Heads × Sectors) + H × Sectors + S(其中 sector 是扇区号,Sectors 是每个磁道的扇区数,Heads 是磁盘的磁头数量)
扇区号 = 柱面号 × (一个柱面有多少扇区)+ 盘面号 ×(一个盘面有多少扇区)+ 扇区号
根据扇区号 sector 来算出 C、H、S 就很容易了,即:
S = sector%Sectors
H = sector/Sectors%Heads
C = sector/Sectors/Heads
通过编址建立从 C、H、S 扇区地址到扇区号的一个映射,这就是文件系统第一层抽象的中心任务。
扇区号连续的多个扇区就是一个磁盘块。
有了磁盘块以后,用户发出的磁盘读写请求就是盘块号 blocknr 了,由于磁盘块是连续的多个扇区,我们可以很容易地算出扇区号,即:sector = blocknr × blocksize(其中 blocksize 是描述磁盘块大小的一个参数,这是操作系统可以调整的一个参数)
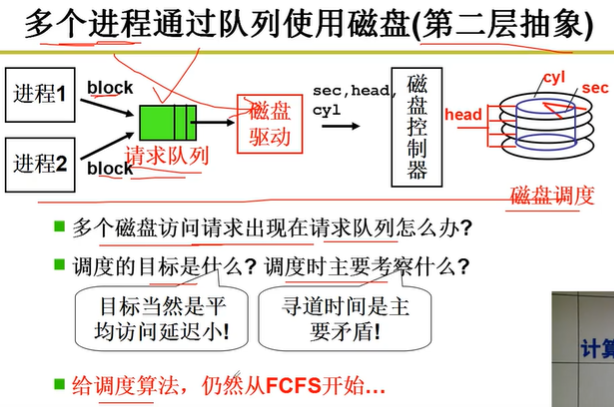
操作系统中有多个进程,每个进程都会提出磁盘块访问请求,所以需要用队列来组织这些请求,这
就是操作系统对磁盘管理的第二层抽象。


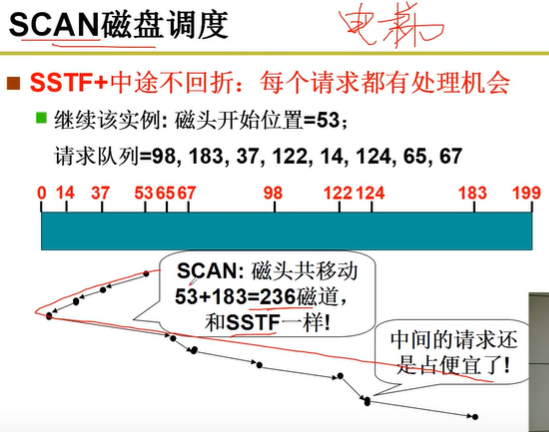



L29 从生磁盘到文件


磁盘使用的第四层抽象——文件,文件是一个连续的字符流。
用户可以在这个字符流上随意操作,操作系统会根据一个映射表找到和字符流位置对应的磁盘块号,操作系统完成了从磁盘块到字符流的映射。
实现文件抽象的关键就在于能根据字符流位置找到对应的盘块号,即字符流和盘块号之间的映射关系。
顺序存储结构,操作系统只需要“文件名、起始块号、文件长度”,就可以算出字符流位置对应的磁盘块号。
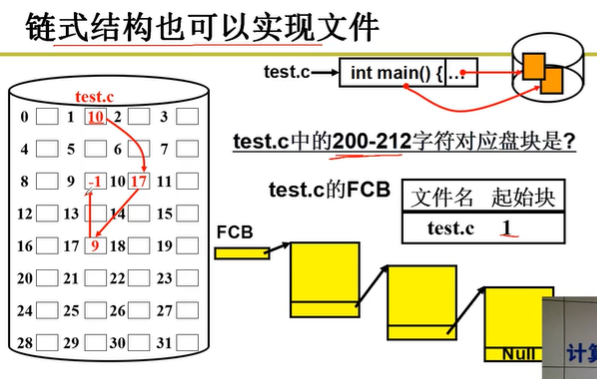

链式存储结构,操作系统在 FCB 中需要存放的主要映射信息仍然是第一个磁盘块的盘块号,利用这个信息可以找到文件的第一个磁盘块,再利用每个磁盘块中存放的下一个盘块号,可以找到第二个磁盘块,依次类推…


索引存储结构,文件字符流被分割成多个逻辑块,在物理磁盘上寻找一些空闲物理盘块(无需连续)将这些逻辑块的内容存放进去,再找一个磁盘块作为索引块,其中按序存放各个逻辑块对应的物理磁盘块号

L30 文件使用磁盘的实现

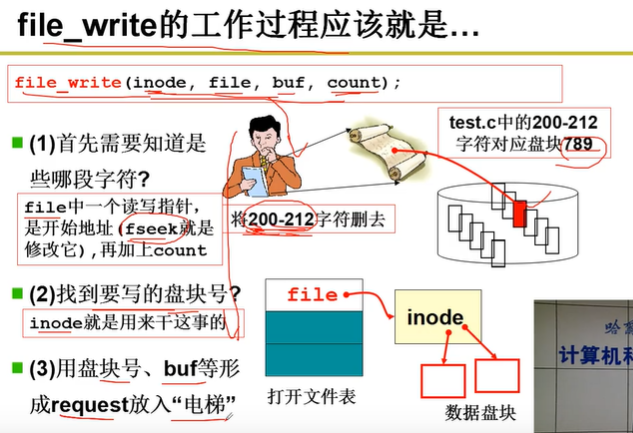
系统调用 sys_write ,参数:fd文件描述符,buf内存缓冲区,count读写字符的个数
根据文件信息 inode 对应的不是字符设备,而是常规文件,跳到 file_write() 去执行
1.根据file中的一个读写指针(文件的当前读写位置)及 count 找到文件读写对应的字符流位置
2.根据 字符流上的读写位置 算出逻辑块号 ,由 inode 找到物理盘块号
3.有了物理盘块号,放入请求队列,就可以读写磁盘了


pos - 先找到 文件的读写位置 (记录在 字段 f_pos 中)。
block - 计算物理盘块号
bread - 向磁盘发出请求
拷贝写出
file->f_pos - 修改pos
如果逻辑盘块号小于等于 6,说明 inode中的直接数据块就能映射出盘块号。
如果这个逻辑盘块没有映射到物理盘块,就调用 new_block() 从磁盘上申请一个空闲物理盘块。
block-=7 后 if(block<512) 说明逻辑盘块号对应的物理盘块号存放在一阶间接索引中。
所以接下来需要 bread(inode->i_dev,inode->i_zone[7]) 读入这个一阶索引块,接下来需要在这个索引块中寻找和逻辑块相对应的物理盘块号。
实验八
L31 目录与文件系统


第五层抽象:将整个磁盘抽象成一个文件系统
一个文件对应一些磁盘块集合
(多个文件)文件系统对应整个磁盘
在用户眼里,操作系统将整个磁盘抽象成一个目录树。
用户可以访问这棵目录树,也可以修改这棵目录树
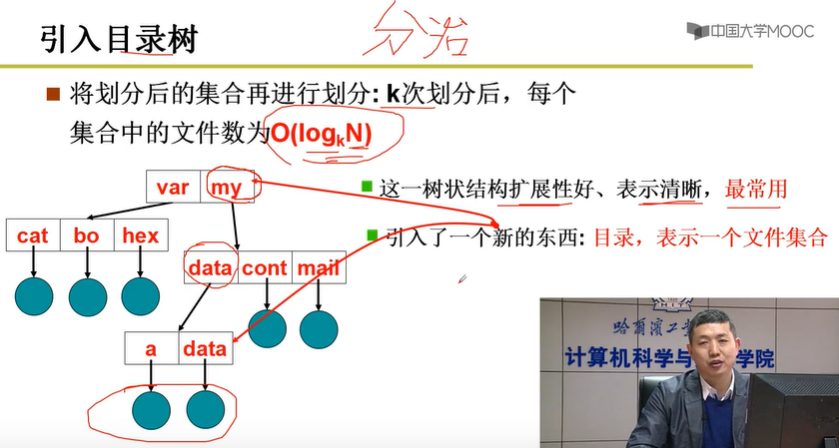
目录树由文件和目录两部分组成。
目录是一个文件集合。通过数据结构表达出“目录包含了一些文件”。
实现目录树的关键就是实现目录。
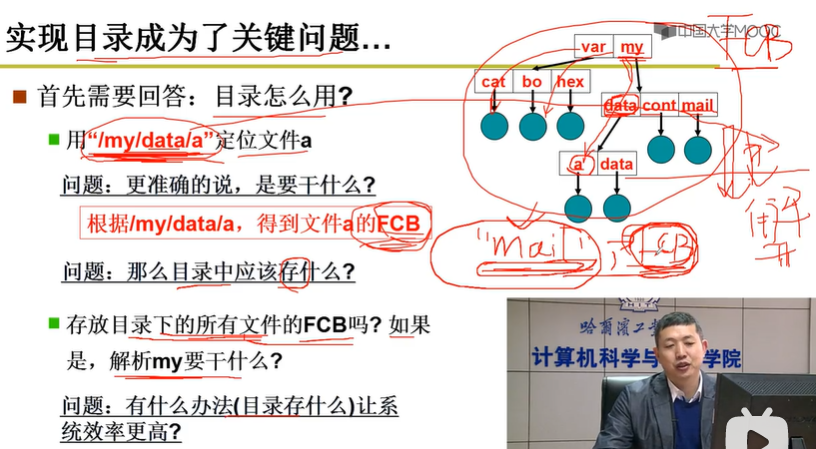
目录帮助用户快速检索文件,更具体的说,是根据用户提供的文件路径来获得文件对应的 FCB 数据结构(文件的基本信息都存放在数据结构 FCB 中)。
因此目录的核心作用就是根据文件路径获得文件的 FCB,这个作用常被称作是 目录解析。
目录内容中存放文件名字符串,“FCB 地址”( FCB 数据结构在这个 FCB 数组里的索引)。
先通过文件名字符串匹配到要找的文件,再通过“FCB 地址”到磁盘上读入文件的 FCB 数据结构,继续向下匹配。
“FCB 地址”,一种常见的处理方法是将磁盘上所有文件的 FCB 数据结构组织成一个数组连续地存放在一个磁盘块序列上,此时一个文件的“FCB 地址”就是这个文件的 FCB 数据结构在这个 FCB 数组里的索引。
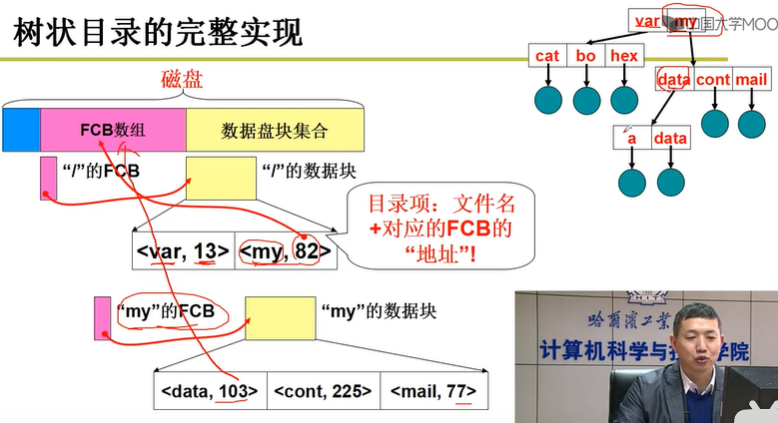
根目录的内容是<文件名字符串,这个文件的 FCB 在 FCB 数组中的索引>,这两个信息形成的结构体常被称做为一个目录项。因此可以得出这样的结论:“目录的内容就是一个目录项数组”。
根目录的也是一个目录文件,规定“/”的 FCB 一定要放在 FCB 数组中的第一项,其内容可以根据“/”的 FCB 中存放的物理盘块号信息从磁盘上读入。
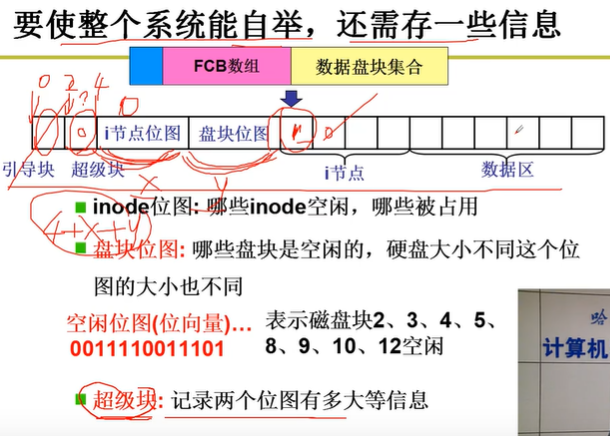
用位图来表达数据项的空闲情况
超级块:记录两个位图大小等信息


L32 目录解析代码实现


目录解释首先要找到一个解析的起点,如果路径名从 / 开始,就从根目录的inode 开始,否则要从当前目录的 inode 开始。
有了起点目录文件的 inode,接下来读出目录文件内容,然后用文件路径上的下一段文件名和和目录中的目录项逐个比对,不断向下解析,直到路径名被全部处理完成。最终找到目标文件 的 inode,返回。
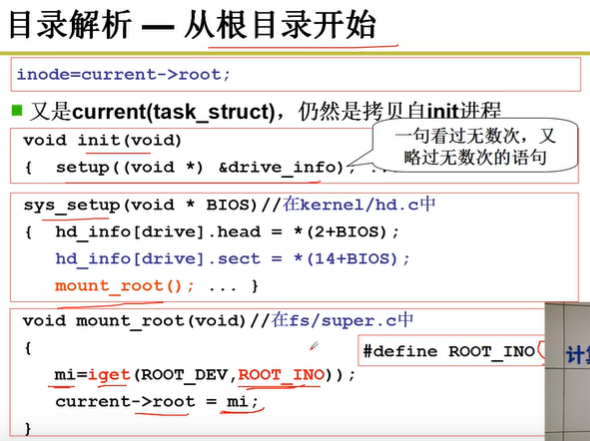
所有进程的 root 都是从 1 号进程那里继承来的,在 1 号进程 init 函数中要执行 mount_root(),该函数用来将根目录的 inode读入到内存中,并且关联到 1 号进程的 PCB 中。
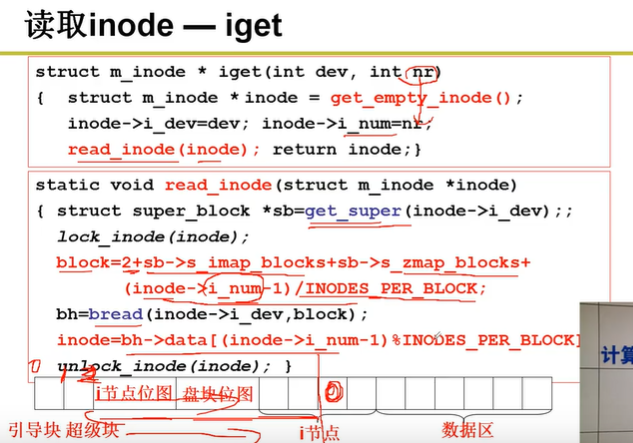
inode 数组的起始位置在引导块、超级块以及两个位图数组之后。
inode 数组在磁盘上的起始位置 = 引导块大小 + 超级块大小 + s_imap_blocks大小 + s_zmap_blocks大小
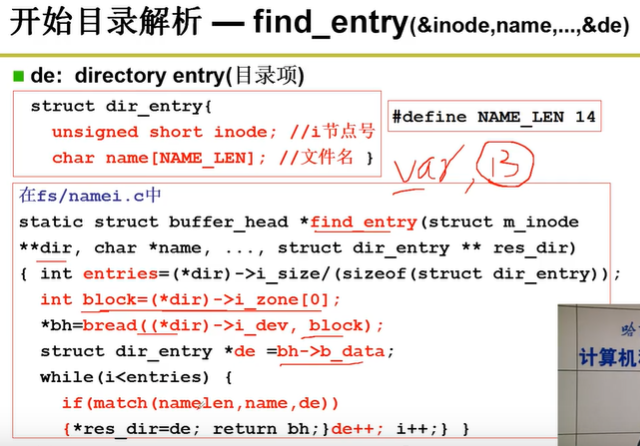

函数 find_entry 根据目录文件的 inode 读取目录项数组,然后逐个目录项进行匹配,即 while(i<entries) if(match(namelen,name,de))。
iget 用来读取索引节点,根据 inode 编号(iget 的参数)和 inode 数组的初始位置计算出该 inode 所在的磁盘块号,再用 bread 发出磁盘读将 inode 读入即可。
————————————————————————————————————————————————————————————
完结撒花