今天来把pickle搞明白。不搞明白不回家(还是回家了,每一个小问题都可以扯出来一大堆问题)。以下是我在网上搜索的内容加上自己的理解写的博文,如有不正确不准确的地方,希望评论指正。
能百度到的答案都是pickle用于序列化和反序列化。自己想想,不就是将数据保存成文件和读取文件嘛?这个不是很简单吗?也很常见,一个函数就能实现,不同的函数或者类实现不同的文件读取和写入。比如matlab里的audioread和audiowrite函数,比如C里面的fread和fwrite函数,比如python中librosa库里的load等等。。。
序列化、反序列化
- 网络通讯需求,网络传输通常需要二进制。
- 中间结果或者最终结果永久存到磁盘中的需求。
每种编程语言都有自己的序列化和反序列化的库或者函数。如C语言中的fopen fread fwrite,如python中的librosa, model_load等,有针对于特定单一类型的变量等的读写,这种比较简单,但是对于自定义的类型或者类,保存中间结果就需要提前定义好保存的顺序,叫做序列化,当再次加载的时候按照之前的存储顺序依次读取,叫做反序列化。pickle就是python中将变量或者类转成序列化字节,再从字节到类或者变量的库。python中神经网络训练用数据的特征向量和中间结果、网络模型的保存和加载等。
存储字符串比存储对象方便得多——这就是pickle的意义所在。
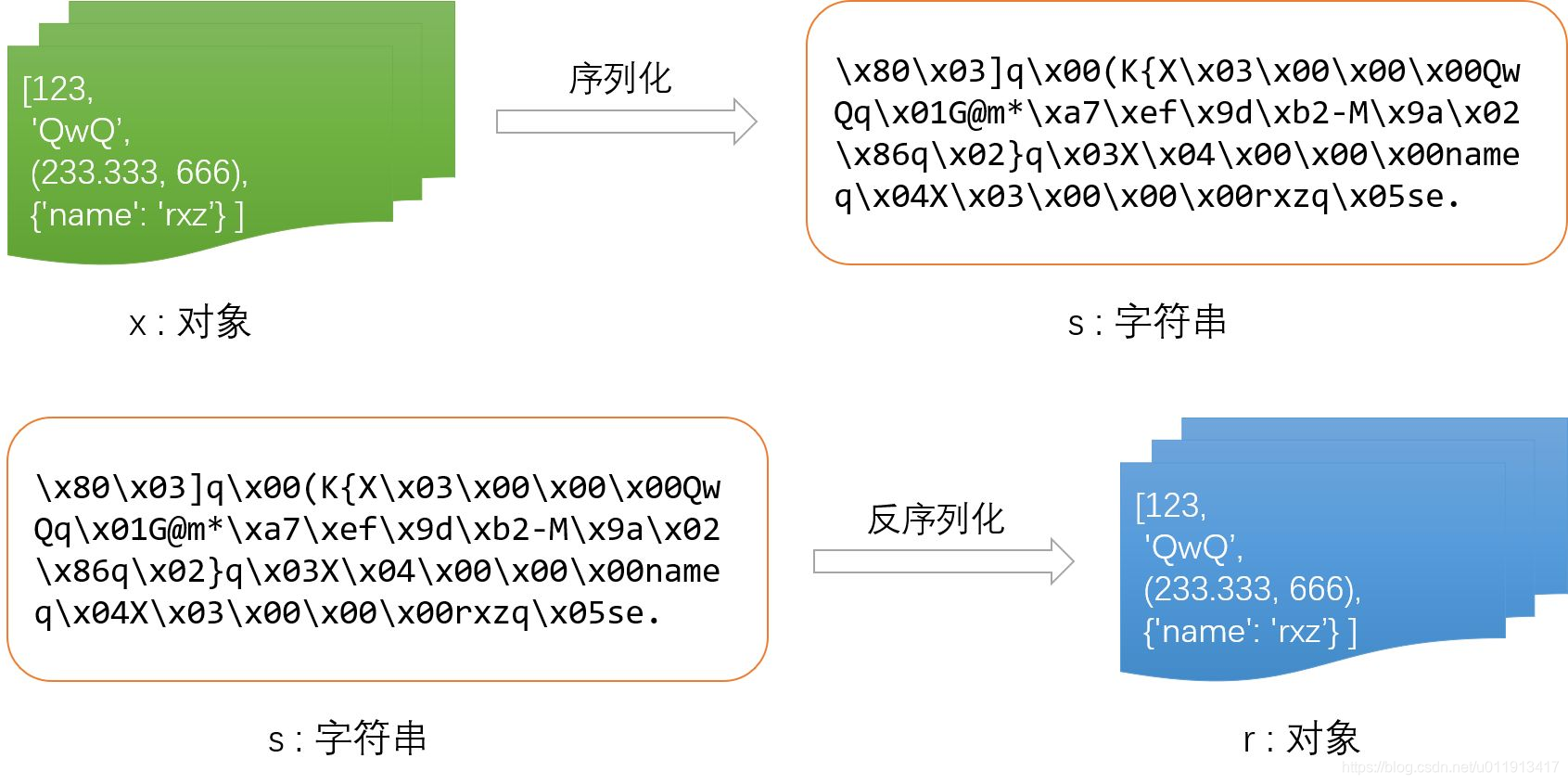
用法
用法参见Python编程(八):json序列化、反序列化、pickle模块和pickle模块应用实例(python的序列化与反序列化)
pickle用法
pickle不仅可以读写字符串,也可以读写文件:只需要采用pickle.dump()和pickle.load()。
pickle.loads机制:调用_Unpickler类
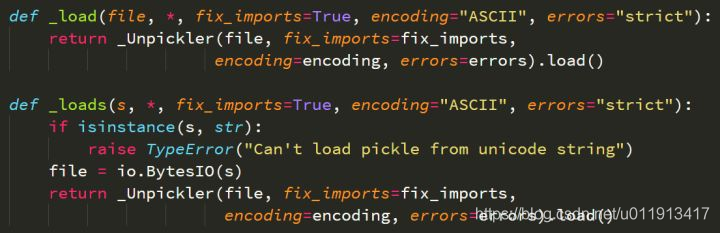
可以看出,_load和_loads基本一致,都是把各自输入得到的东西作为文件流,喂给_Unpickler类;然后调用_Unpickler.load()实现反序列化。
json用法
python自带的json库(无需额外安装), 主要包含了dumps, loads, dump和load四种方法其作用分别如下所示。
- json.loads() - 将json字符串转换为python数据类型
- json.dumps() - 将python数据类型转化为json字符串
- json.dump() - 将python输入转化为json格式存入磁盘文件
- json.load() - 将磁盘文件中json格式数据转换为python数据类型
参考文献来源
感谢原作者们的工作。
特别感谢知乎阮行止的文章,感谢作者。。
从零开始python反序列化攻击:pickle原理解析 & 不用reduce的RCE姿势
pickle模块应用实例(python的序列化与反序列化)
Python编程(八):json序列化、反序列化、pickle模块
序列化/反序列化,我忍你很久了,java语言的序列化和反序列化