关于线段树辅助扫描线的基本思想,已经有很多大佬去详细的解释了,可以去看一下传送门
这里主要说一下线段树辅助扫描线的一些问题以及几种变形
- 关于数据的离散化,离散化很多时候是为了减小空间消耗,但是我认为在线段树辅助扫描线时,基本都是需要进行离散化的,因为在以x(y)为坐标轴时,维护的是[1, m] (m不确定),但是显然坐标轴上的区间点坐标不一定是从1开始的,所以要离散出一个区间其范围是 [1, m]
- 在一般线段树进行区间划分的时候,通常采用下面的方式
mid = l + r >> 1;
(操作函数) (l, mid)
(操作函数) (mid + 1, r)
但是,在线段树辅助扫描线的时候,这样划分是不可以的,由于线段树维护的是连续区间,而上面划分区间的时候 mid 和 mid + 1中间是有距离的,所以会少统计答案导致错误,所以可以给线段树维护的区间换个意义,可以将其理解为维护的是一个个区间
|___|___|___|___|
1 2 3 4 5
比如上面这个图,将[1, 2]定义为1号区间,[2, 3]定义为2号区间…这样的话,每一个叶子节点的意义不再是一个离散的点,而是表示一个长度为1的区间,而上级节点维护的,就是这一个个区间的组成的大区间
在进行维护时可以发现,如果要更新[2, 4]这段区间(这里2,4指的是端点坐标),就等于维护[2, 3]这两个区间(这里的2,3是指的区间编号),可以发现,当要维护节点[l, r]这一段区间时就等同于维护第 l,l + 1… r - 1号区间,也就是[l, r - 1] 范围的区间,所以在更新线段树的时候,传的更新范围参数应该是(l, r - 1),但是如果求区间长度,用 (r - 1) - l 是不正确的,没关系,只要在计算区间长度的时候,给r 加一个1就解决了这个问题
由于我差劲的表达能力以及这种方式自身的抽象性,可能看到这里会觉得,这是什么玩意,看不懂啊,没关系,这只是一种处理方法,下面在讲到其他问题的时候会给出一种简单易懂方式
题目1 Atlantis
这道题目还挺经典的,由于在acwiing上莫名奇妙的MLE所以选择HDU的题目链接,有兴趣的朋友可以去看下acwing上的这道题目,而且数据也加强过了,线段树辅助扫描线的板子题,用的是第一种划分区间的处理方式
#pragma GCC optimize(2)
#include <iostream>
#include <algorithm>
#include <cstdio>
#include <vector>
#define lch rt << 1
#define rch rt << 1 | 1
using namespace std;
const int maxn = 10000 + 5;
int mark[maxn << 2];//该区间是否为可用边,以及覆盖的次数
double sum[maxn << 2];//记录该区间下边的总长度
vector <double> Hash;//对横坐标进行离散化
//以横坐标作为线段(区间),对横坐标线段进行扫描
//扫描的作用是每次更新下底边总长度和下底边个数,增加新面积
//线段
struct seg
{
double l, r, h;
int d;
seg(){}
seg(double x1, double x2, double H, int c) {
l = x1, r = x2, h = H, d = c;
}
bool operator < (const seg &a) const {
return h < a.h;
}
}s[maxn << 1];//边有2n条需要乘2
void pushup(int rt, int l, int r)
{
//如果当前区间是边的一部分,长度直接记为区间长度
if (mark[rt]) sum[rt] = Hash[r + 1] - Hash[l];
else if (l == r) sum[rt] = 0;
else sum[rt] = sum[lch] + sum[rch];
}
void update(int L, int R, int l, int r, int rt, int d)
{
if (L <= l && r <= R) {
mark[rt] += d;
pushup(rt, l, r);
return ;
}
int mid = l + r >> 1;
if (L <= mid) update(L, R, l, mid, lch, d);
if (R > mid) update(L, R, mid + 1, r, rch, d);
pushup(rt, l, r);
}
int search(double key)
{
return lower_bound(Hash.begin(), Hash.end(), key) - Hash.begin();
}
int main()
{
int n, num = 0;
double x1, x2, y1, y2;
while (scanf("%d", &n), n) {
Hash.clear();
int k = 0;
for (int i = 0; i < n; i++) {
scanf("%lf%lf%lf%lf", &x1, &y1, &x2, &y2);
Hash.push_back(x1), Hash.push_back(x2);
s[k++] = seg(x1, x2, y1, 1); //入边
s[k++] = seg(x1, x2, y2, -1); //出边
}
sort(Hash.begin(), Hash.end());
sort(s, s + k);
//离散化
Hash.erase(unique(Hash.begin(), Hash.end()), Hash.end());
double ans = 0;
int len = Hash.size();
for (int i = 0; i < k; i++) {
int L = search(s[i].l);
int R = search(s[i].r) - 1;
//更新区间
update(L, R, 0, len - 2, 1, s[i].d);
ans += sum[1] * (s[i + 1].h - s[i].h);
}
printf("Test case #%d\nTotal explored area: %.2lf\n\n", ++num, ans);
}
return 0;
}
第二种划分方式
可以得知,线段树辅助扫描线,维护的是连续区间 ,那么在进行区间划分的时候,直接不将边界分开就好了,后面的两道题就采用这种方法
int mid = l + r >> 1;
(左区间函数) (l, mid);
(右区间函数) (mid, r);
题目2 窗内的星星
这个题主要是将点扩充成矩形后求最大面积交,利用线段树辅助扫描线维护每加入一条边后,最大的矩形面积交的值,加入一条入边就等于扫描线停下的位置进入了这个矩形覆盖的增益区域,加入一条入边就表示扫描线已经移出这个矩形的增益区域,如果当进入一个矩形的增益区域的同时,还没有出之前矩形的增益区域,那么这个区域的增益值就会叠加,只需要每一次加边的时候同时记录此时的最大值,在所有最大值中取最大就可以了,但是关于这个题的边界判断,我个人觉得这个题还是不太对劲
#include <iostream>
#include <algorithm>
#define lch rt << 1
#define rch rt << 1 | 1
using namespace std;
typedef long long ll;
const int maxn = 2e4 + 5;
struct seg
{
ll y1, y2, h, c;
seg(){}
seg(ll ys, ll yd, ll H, ll v) {
y1 = ys, y2 = yd, h = H, c = v;
}
bool operator < (const seg &a) const {
if (h == a.h) return c < a.c;
return h < a.h;
}
}line[maxn];
ll ms[maxn << 2], add[maxn << 2], Hash[maxn];
inline void pushup(int rt)
{
ms[rt] = max(ms[lch], ms[rch]);
}
inline void pushdown(int rt)
{
if (add[rt]) {
add[lch] += add[rt];
add[rch] += add[rt];
ms[lch] += add[rt];
ms[rch] += add[rt];
add[rt] = 0;
}
}
void update(int L, int R, int l, int r, int rt, ll val)
{
if (L <= l && r <= R) {
ms[rt] += val;
add[rt] += val;
return ;
}
pushdown(rt);
int mid = l + r >> 1;
if (L < mid) update(L, R, l, mid, lch, val);
if (R > mid) update(L, R, mid, r, rch, val);
pushup(rt);
}
int search(ll x, int n)
{
return lower_bound(Hash, Hash + n, x) - Hash;
}
int main()
{
int n, w, h, x, y, c;
while (cin >> n >> w >> h) {
int k = 0;
for (int i = 0; i < n; i++) {
cin >> x >> y >> c;
Hash[k] = y;
line[k++] = seg(y, 1LL * y + h - 1, x, c);//入边
Hash[k] = 1LL * y + h - 1;
// cout << "1: " << Hash[k] << endl;
line[k++] = seg(y, 1LL * y + h - 1, 1LL * x + w, -c);//出边
// cout << "2: " << line[k - 1].y1 << endl;
}
sort(Hash, Hash + k);
sort(line, line + k);
//离散化
int m = unique(Hash, Hash + k) - Hash;
ll ans = -0x7fffffff;
for (int i = 0; i < k; i++) {
int L = search(line[i].y1, m);
int R = search(line[i].y2, m);
//cout << "r: " << R << " l: " << L << endl;
update(L, R, 0, m - 1, 1, line[i].c);
// cout << "i: " << i << " " << ms[1] << endl;
ans = max(ans, ms[1]);
}
cout << ans << endl;
}
return 0;
}
求矩形并的周长
这个问题其实类似求矩形面积并,但是要稍微抽象一些,求这类问题有两种方法,但由于蒟蒻只会一种,所以就只介绍一种…
依旧是向求面积并时,标记入边和出边,遇到入边就给对应的范围 + 1,表示覆盖了一次,遇到出边就就给对应范围 -1 表示扫描线覆盖的这个区域覆盖次数 -1,在统计周长的时候,先按照横坐标进行一次扫描线,每一次统计加入该边后的覆盖长度与上一次覆盖长度差的绝对值,然后再按照纵坐标进行一次扫描线,即为答案,要注意,由于可能出现入边和出边重叠的情况,但是重叠的部分是不算周长的,这里对边进行排序的时候,遇到重叠情况,采取先加入边再加出边的策略。
- 演示 计算与轴平行的矩形并的长度
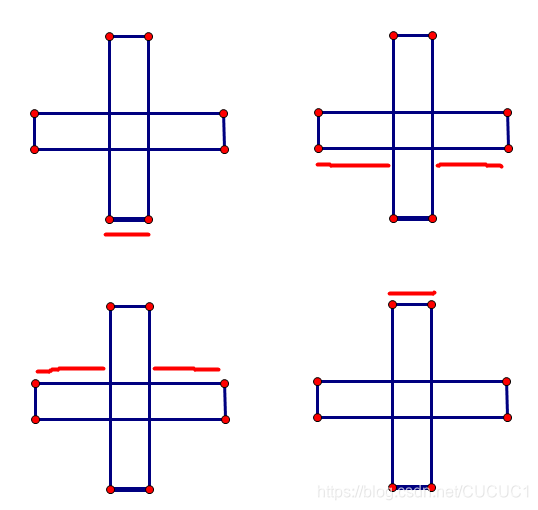
这个方法挺抽象的,我强行解释一下:
对于每一次加入入边,那么覆盖的长度一定 >= 上一次覆盖的长度,就说明变长的这一部分一定是之前未被覆盖的,也就是说其没有被前面的矩形并所完全包含进去
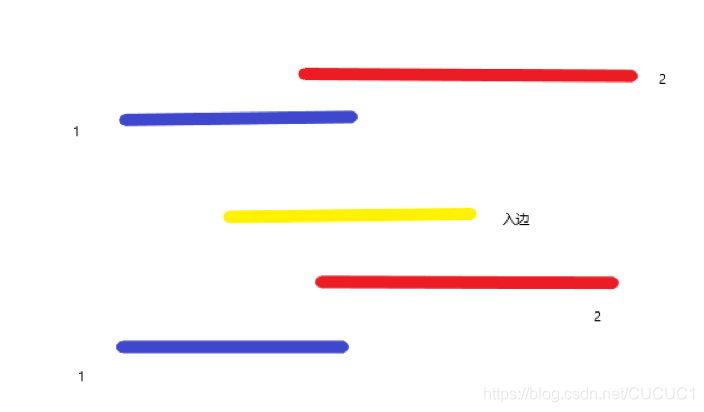
这里黄色表示新加入的入边,之前由于1,2号入边已经将新加入的入边覆盖过了,而且其对应的出边并没有在新加入的入边之前就被扫描到,所以事实上这条边是在这两个矩形并的内部,并不能对周长产生贡献,也可以换个说法,当加入一条入边时,覆盖的长度并没有变化,说明,这个入边的下面有至少一条入边将这个区域给覆盖了,而且上面至少也对应一条出边,等待着将这个区域取消覆盖状态,也就是说,新加入的入边至少处于一个矩形的内部,对周长是没有贡献的,出边也同理,每加入一条出边覆盖的长度 <= 上一次的长度,如果等于上一次长度,说明这条出边也是没有对周长产生贡献的
之前看到的一句话,总结的很好
因为每次添加了一条线段,如果没有没有使总区间覆盖长度发生变化,说明这条线段其实在多边形的内部,被覆盖掉了,不能计算,只要能引起总区间长度发生变化的,说明该线段不被覆盖不被包含
[USACO5.5]矩形周长Picture
#include <iostream>
#include <algorithm>
#include <vector>
#include <cstring>
#define lch rt << 1
#define rch rt << 1 | 1
using namespace std;
typedef pair <int, int> PII;
const int maxn = 10000 + 10;
struct seg
{
int x, y1, y2, d;
seg(){}
seg(int X, int Y1, int Y2, int flag) {
x = X, y1 = Y1, y2 = Y2, d = flag;
}
bool operator < (const seg &a) const {
if (x != a.x) return x < a.x;
return d > a.d;
}
}s[maxn];
int pos[maxn][4];
int mark[maxn << 2], sum[maxn << 2], n;
vector <int> Hash;
int search(int key)
{
return lower_bound(Hash.begin(), Hash.end(), key) - Hash.begin();
}
void pushup(int rt, int l, int r)
{
if (mark[rt]) sum[rt] = Hash[r] - Hash[l];
else if (l == r) sum[rt] = 0;
else sum[rt] = sum[lch] + sum[rch];
}
void update(int L, int R, int l, int r, int rt, int d)
{
if (L <= l && r <= R) {
mark[rt] += d;
pushup(rt, l, r);
return ;
}
int mid = l + r >> 1;
if (L < mid) update(L, R, l, mid, lch, d);
if (R > mid) update(L, R, mid, r, rch, d);
pushup(rt, l, r);
}
int get_ans(int k)
{
int res = 0, last = 0;
sort(s, s + k), sort(Hash.begin(), Hash.end());
Hash.erase(unique(Hash.begin(), Hash.end()), Hash.end());
int length = Hash.size();
for (int i = 0; i < k; i++) {
int L = search(s[i].y1);
int R = search(s[i].y2);
update(L, R, 0, length - 1, 1, s[i].d);
res += abs(last - sum[1]);
last = sum[1];
}
return res;
}
void init(int &k)
{
k = 0;
Hash.clear();
memset(s, 0, sizeof s);
}
int main()
{
cin >> n;
int k = 0;
int x1, y1, x2, y2;
for (int i = 0; i < n; i++) {
cin >> x1 >> y1 >> x2 >> y2;
pos[i][0] = x1, pos[i][1] = y1, pos[i][2] = x2, pos[i][3] = y2;
Hash.push_back(x1), Hash.push_back(x2);
s[k++] = seg(y1, x1, x2, 1);//入边
s[k++] = seg(y2, x1, x2, -1);//入边
}
int ans = get_ans(k);
init(k);
for (int i = 0; i < n; i ++) {
//cin >> x1 >> y1 >> x2 >> y2;
x1 = pos[i][0], y1 = pos[i][1], x2 = pos[i][2], y2 = pos[i][3];
Hash.push_back(y1), Hash.push_back(y2);
s[k++] = seg(x1, y1, y2, 1);//入边
s[k++] = seg(x2, y1, y2, -1);//入边
}
ans += get_ans(k);
cout << ans << endl;
return 0;
}
这里再补充一下求矩形面积交的做法,其实跟矩形面积并基本相似,只需要再维护一个每加入一条边后,当前所有重叠边的长度,并且同时维护每个区间覆盖的总长度,由于没有Pushdown函数,所以需要处理一下Pushup函数
void pushdown(int l,int r,int rt)
{
if(t[rt].cnt)
t[rt].len=X[r+1]-X[l];
else if(l==r)
t[rt].len=0;
else
t[rt].len=t[rt<<1].len+t[rt<<1|1].len;
if(t[rt].cnt>1)
t[rt].s=X[r+1]-X[l];
else if(l==r)
t[rt].s=0;
else if(t[rt].cnt==1)
t[rt].s=t[rt<<1].len+t[rt<<1|1].len;
else
t[rt].s=t[rt<<1].s+t[rt<<1|1].s;
}
解释一下
- 1 对于覆盖次数 >= 2的区间,区间长度直接为当前区间长度
- 2 对于覆盖次数 == 1的区间,由于这个区间的标记只是说明当前区间被覆盖,对于它的子区间我们并不能清楚的知道,若是它下面的小区间也被覆盖过至少一次,那么此时就等于覆盖了这个小区间两次以上,那么当前的区间覆盖次数 >= 2的长度就是子区间的长度和 (这里为什么选择子区间覆盖的长度,因为对于一个区间,其多次覆盖的长度一定不长于子区间覆盖的全部长度)
- 3 对于没有被覆盖(或者说这个区间没有完全被用作矩形边长的一部分),就分别统计子区间的全部覆盖长度和覆盖两次及以上的长度即可
#include <cstdio>
#include <cstring>
#include <cctype>
#include <string>
#include <set>
#include <iostream>
#include <stack>
#include <cmath>
#include <queue>
#include <vector>
#include <algorithm>
#define mem(a,b) memset(a,b,sizeof(a))
#define inf 0x3f3f3f3f
#define N 2200
#define ll long long
using namespace std;
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
struct Seg
{
double l,r,h;
int f;
Seg() {}
Seg(double a,double b,double c,int d):l(a),r(b),h(c),f(d) {}
bool operator < (const Seg &cmp) const
{
return h<cmp.h;
}
} e[N];
struct node
{
int cnt;
double len,s;
} t[N<<2];
double X[N];
void pushdown(int l,int r,int rt)
{
if(t[rt].cnt)
t[rt].len=X[r+1]-X[l];
else if(l==r)
t[rt].len=0;
else
t[rt].len=t[rt<<1].len+t[rt<<1|1].len;
if(t[rt].cnt>1)
t[rt].s=X[r+1]-X[l];
else if(l==r)
t[rt].s=0;
else if(t[rt].cnt==1)
t[rt].s=t[rt<<1].len+t[rt<<1|1].len;
else
t[rt].s=t[rt<<1].s+t[rt<<1|1].s;
}
void update(int L,int R,int l,int r,int rt,int val)
{
if(L<=l&&r<=R)
{
t[rt].cnt+=val;
pushdown(l,r,rt);
return;
}
int m=(l+r)>>1;
if(L<=m) update(L,R,lson,val);
if(R>m) update(L,R,rson,val);
pushdown(l,r,rt);
}
int main()
{
int n,q;
double a,b,c,d;
scanf("%d",&q);
while(q--)
{
scanf("%d",&n);
mem(t,0);
int num=0;
for(int i=0; i<n; i++)
{
scanf("%lf%lf%lf%lf",&a,&b,&c,&d);
X[num]=a;
e[num++]=Seg(a,c,b,1);
X[num]=c;
e[num++]=Seg(a,c,d,-1);
}
sort(X,X+num);
sort(e,e+num);
int m=unique(X,X+num)-X;
double ans=0;
for(int i=0; i<num; i++)
{
int l=lower_bound(X,X+m,e[i].l)-X;
int r=lower_bound(X,X+m,e[i].r)-X-1;
update(l,r,0,m,1,e[i].f);
ans+=t[1].s*(e[i+1].h-e[i].h);
}
printf("%.2lf\n",ans);
}
return 0;
}