0.Briefly Speaking
本文于2014年发布于MICRO(2014 47th Annual IEEE/ACM Inernational Symposium on Microarchitecture)上,本文的工作是在前作DianNao的基础上进一步对加速器访存进行优化得到的。主要思路就是:尽管CNNs和DNNs的访存需求很大,但是没有超出多结点系统片上存储的能力之和,所以如果可以将神经网络计算所需的所有数据分布式地存放在多个计算结点组成的系统上(本地),这样就可以实现真正的高内部带宽和低外部通信,从而进一步大大优化了访存行为(甚至无需访存)
1.INTRODUCTION
首先文章中指出了在机器学习领域和系统结构领域的几点趋势:
- 机器学习应用已经取代科学计算成为推动高性能计算的主要力量
- 从硬件的角度来看,有向异构计算演化的趋势,且架构特制化(architecture specialization)被认为是实现高性能低功耗的必由之路
- 从机器学习的视角来看,逐渐增大的神经网络是一个重要的趋势,这使得访存成为性能瓶颈
随后对本文提出的新型互联架构做了一点简单的铺垫:
- 本文提出的架构是一种多芯片结构(Multiple chips),每个芯片不仅包含特制的计算逻辑,还包含足量的RAM使得多个芯片上的RAM容量之和足以承载整个神经网络参数而无需片下存储
- 通过将多个芯片使用专用网络互联,就可以以当下CPU和GPU面积和功耗的极小一部分的成本来高效实现当下最大的深度神经网络
- 通过增加每个芯片(结点)上的RAM容量,或者增加结点数量就可以适配更大规模的神经网络
2.STATE-OF-THE ART MACHINE LEARNING TECHNIQUES
首先,这部分对当下比较热门的CNNs和DNNs的结构做了简单的回顾和介绍,首先是主要的运算层次:
卷积层:抽取输入数据中的特征元素
以公式形式描述卷积层的运算如下:
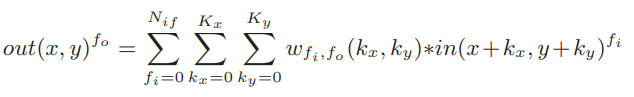
池化层:使输入数据降维,粗粒度特征显现
以公式形式描述的池化层运算如下:
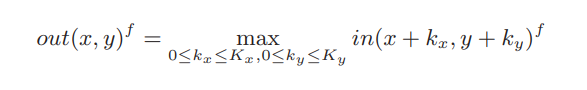
LRN(局部响应归一化)层:类似于生物神经元中的侧支性抑制
以公式形式描述的LRN层运算如下:
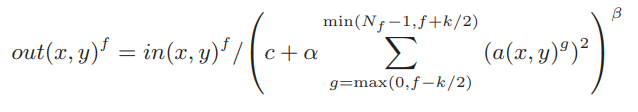
分类器层:将抽取出来的特征与相关类别对应起来
以公式形式描述的分类器层运算如下:
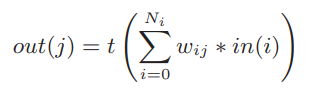
最后给出一个神经网络工作原理图,上面是直观理解,下面是具体动作,很好的一个解释图:
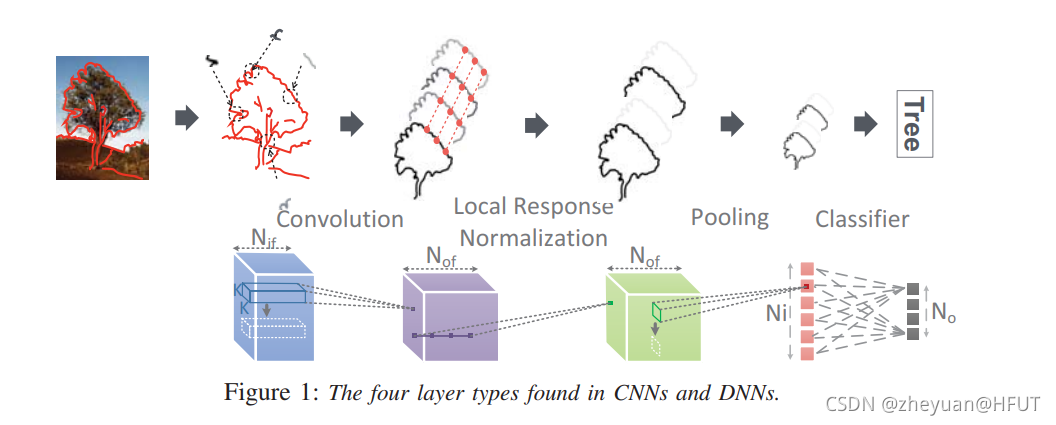
随后,这部分对用于测试基准的神经网络规格作了说明,在此不再赘述。最后对推理和训练存在的矛盾做出了澄清:对于很多工业级应用而言,线下训练就是足够的,也就是在线下训练完成,在使用时只执行推理任务,很多加速器的设计也只注重于推理部分,但是本次工作提出的架构却可以同时支持训练和推理。
3.THE GPU OPTION
这部分对使用GPU作为硬件载体的选项进行了分析。
GPU仍是当下业界实现CNNs和DNNs最受推崇的方式,相对于一般的SIMD核心而言它有着可观的能效比。但是它有三个主要的弊端:
- 因为要保证高速和通用性,所以硬件运算器的数量很多,GPU的开销(设计面积)很高。
- 性能对于实时应用而言还是不够快
- 能耗开销太高
4.THE ACCELERATOR OPTION
这部分对使用硬件加速器作为载体的选项进行了分析,分析对象是上一代加速器DianNao。
- 首先加速器DianNao使用0.53%的设计面积达到了GPU 47.91%的性能,所以这再一次证明了定制化架构的潜能巨大
- 另外,限制加速器DianNao性能进一步提升的原因还是在于访存:在CNNs和DNNs中,对于含有私有卷积核的卷积层和全连接层而言,访存开销很大,对访存带宽提出了很高的要求
5. A MACHINE-LEARNING SUPERCOMPUTER
这部分就是本文的核心部分,即一个面向机器学习的超级计算机。
5.1 Overview
首先,这部分以一个概述开头,简要叙述了解决问题的基本思路和加速器架构的简要描述。要解决的问题,如前所述,就是含有私有卷积核的卷积层和全连接层访存压力太大的问题,本文为了解决这些问题提出了以下几点设计原则作为纲领:
- 将突触(权重)存放在将要使用它们的神经元附近,从而减少了数据移动所带来的能耗和时间开销。芯片架构是完全分布式的,所以没有主存储器(计算所需的全部数据全部分布式地存储在各个芯片结点上)
- 提出了一种非对称的架构,每个结点的设计依赖于存储部件而非运算部件
- 只传输神经元数据,而保证突触数据固定不动,这是因为相比于大规模的突触数据,神经元数据的规模要小得多
- 通过将本地的存储切分为多块来实现内部的高带宽通信
加速器的架构,简单而言就是一组结点,一个结点(node)对应于一个芯片(chip),它们之间使用一组简单的二维网络来连接(之后的分析中看到,简单的互联网络也会带来一些通信开销,而这可以是下一步进行优化的方向),每一个结点含有一个大容量的存储器和神经元计算模块,神经元计算模块是前一项工作DianNao中NFU的升级版。
5.2 Node
既然加速器整体是由一组结点通过互联网络构成的,那么单个结点的结构剖析是绕不开的。
首先,结点的设计要遵循突触靠近神经元的准则,这是对Overview部分设计纲领1的体现,这样将存放突触数据的大容量存储器放置在神经元附近起到了两个目的:
- 首先,因为架构同时支持推理和训练,所以相对于移动大规模的突触数据,移动相对少量的神经元数据更加经济。
- 其次,使突触存储器靠近运算部件也可以提供低延迟、低功耗和高内部带宽
接下来思考的问题就是使用什么样的存储器来存储突触数据,这里经过了一系列的说明(优缺点对比),最终选定的的是eDRAM来代替SRAM。为了弥补eDRAM固有的缺点而每个时钟周期都供给足量的数据给NFU来计算,这里将eDRAM一分为四个bank,数据交叠置放于其中。但实际布局之后发现这造成了严重的布线拥塞(wire congestion),如下图:
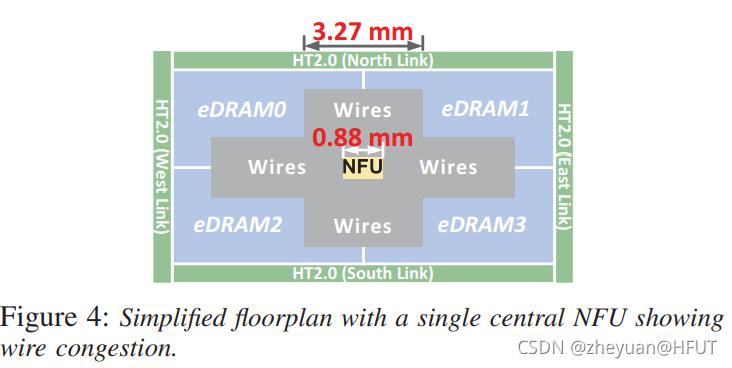
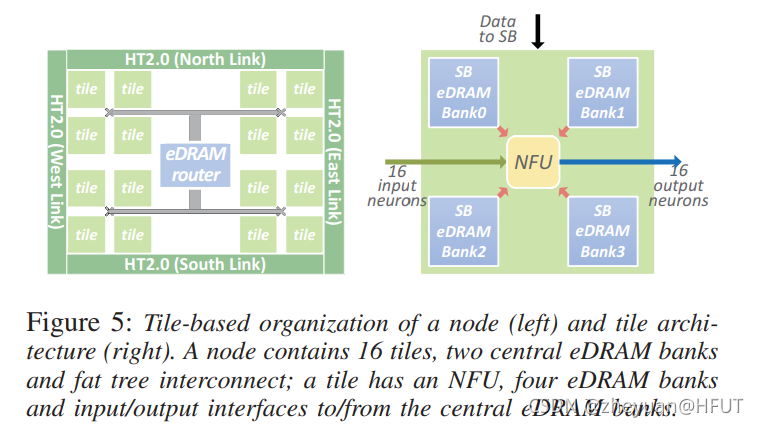
为了解决布线拥塞的问题,本文最终选择了分块式设计(tile-based),输出神经元分布到不同的块中,每个分块上的NFU只需要处理小规模的数据即可,这样大大减少了NFU的尺寸,布局之后发现这有效缓解了之前的布线拥塞问题。一个芯片(结点)上包含16个分块(tile),所有的分块使用fat tree(胖树拓扑)来互联,输入神经元通过fat tree广播到各个分块,输出神经元则被收集回去。芯片中间有两个中央eDRAM,一个用来存储输出神经元,另一个则是用来存储输入神经元,每一个分块上还有局部eDRAM,用来临时存储计算中产生的中间结果,等待计算完成之后再通过fat tree送回中央eDRAM。布局示意如下所示:
随后本部分介绍了结点的可配置性(configurability),本次工作设计的加速器可以同时支持推理任务和训练任务,加速器的分块和NFU的流水线可以被配置为适应不同层次和运行模式。值得注意的是,推理时采用16位定点数即可保证较高的精度,而这会使得训练时无法收敛,经过一系列尝试与权衡,本文最后选取了32位定点数进行训练。为了在硬件上兼顾训练和推理,加速器中的运算器支持运算器聚合,这意味着多个短字长的运算器(16-bit)可以聚合成数量较少的长字运算器(32-bit),分块可以被配置来适应不同运行模式和层次下的数据移动,示意图如下:

5.3 Interconnect
随后文章对架构中的互联做了简单的叙述,因为只移动神经元而突触数据固定,所以架构中没有使用定制化的高速互联IP,而是采用了商用的HyperTransfer(HT) IP核。各个结点之间采用了简单的二维网状互联网络(这可能会带来高额的通信开销,也是未来工作的一个优化方向)。在芯片中央含有一个虫洞路由器,并简单提及了它的规格。
5.4 Overall Characteristics
将上述描述的结点(含有16个分块)布局之后,得到的整体特征汇总如下:

每个结点含有16个分块,每个分块含有4个局部eDRAM,每个eDRAM有1024个4096位的行,中央eDRAM为4MB,所以一个结点上的存储器总量为36MB。布局之后的NFU工作在0.98GHz的时钟频率。
5.5 Programming, Code Generator and Multi-Node Mapping
最后,作为对结点部分介绍的收尾,文中介绍了如何对处理器编程和架构的多结点映射策略。需要说明的是,此架构本身对编程的要求不高(system ASIC),编程是为了初始化配置,随后将数据填入即可连续不断的运算。值得注意的是多结点映射策略,在每一层的运算结束时,每个结点的运算结果存放在中央eDRAM中,所有结点的输出之和构成了下一层神经网络的输入。这些数据首先通过fat tree向片内各个分块进行广播,再通过二维互联网络向其他结点进行传送。考虑到通信问题,有以下三种讨论:
| 层次 | 分析 |
|---|---|
| 卷积层和池化层 | 绝大部分都是结点内部通信,只有在边界时会有结点间通信 |
| LRN层 | 只有结点内部通信,因为计算所需的神经元都在同一片内 |
| 分类器层 | 需要大量的结点间通信,这里采用了计算-前推策略来处理这种情况,不涉及全局同步问题,只有本地决策 |
多结点映射下的示意图如下:

6. METHODOLOGY
这部分简单对实验方法进行了简介,包括实验平台和测试基准。
7. EXPERIMENTAL RESULT
这部分展示了实验的结果,布局结果展示芯片中绝大部分设计开销都集中在存储上,而只有很小一部分花费在计算逻辑和寄存器上,而使用Synopsys PrimePower分析的芯片功耗峰值约为15.97W,为当前最先进GPU功耗的5%-10%。

性能上显示芯片相对于测试基准GPU均有较大程度的性能提升,且结点数量越多加速器效果越明显,这是因为芯片中含有大量的运算部件,且高内部带宽保证了运算数据连续不断的输入。但同时实验中注意到,不同神经网络层次的可扩展性(scalability)差距比较大,运算不密集且结点间通信过多的结点扩展性最差(分类器层),这可以通过实现更加高效的互联网络来缓解。训练时性能提升更小一些,这是因为运算器聚合导致的运算器数量的减少使得加速器性能下降。
能耗方面发现随着结点数量的提升,能耗优化反而下降,这还是因为通信成本的上升导致的。
总之,这部分对实验结果和其产生的原因进行了分析。
8.RELATED WORKS
这部分对相关工作(机器学习、定制化加速器、可定制化架构)进行了进展上的简单介绍,从略。