目录
②inner join、left join、right join的区别?

一,多表联查join
–1,准备表和数据
#多表联查:
#1.课程表
CREATE TABLE courses(
cno VARCHAR(5) NOT NULL,
cname VARCHAR(10) NOT NULL,
tno VARCHAR(3) NOT NULL,
PRIMARY KEY (cno) #单独设置主键
);
#2.得分表
CREATE TABLE scores(
sno VARCHAR(3) NOT NULL,
cno VARCHAR(5) NOT NULL,
degree NUMERIC(10,1) NOT NULL,
PRIMARY KEY (sno, cno) #联合主键,了解
);
#3.学生表
CREATE TABLE students(
sno VARCHAR(3) NOT NULL,
sname VARCHAR(4) NOT NULL,
ssex VARCHAR(2) NOT NULL,
sbirthday DATETIME,
class VARCHAR(5),
PRIMARY KEY (sno)#主键
);
#4.老师表
CREATE TABLE teachers(
tno VARCHAR(3) NOT NULL,
tname VARCHAR(4),
tsex VARCHAR(2),
tbirthday DATETIME,
prof VARCHAR(6),
depart VARCHAR(10),
PRIMARY KEY (tno)
);
#5.插入数据
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (108 ,'曾华' ,'男' ,'1977-09-01',95033);
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (105 ,'匡明' ,'男' ,'1975-10-02',95031);
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (107 ,'王丽' ,'女' ,'1976-01-23',95033);
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (101 ,'李军' ,'男' ,'1976-02-20',95033);
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (109 ,'王芳' ,'女' ,'1975-02-10',95031);
INSERT INTO STUDENTS (SNO,SNAME,SSEX,SBIRTHDAY,CLASS) VALUES (103 ,'陆君' ,'男' ,'1974-06-03',95031);
INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (804,'易天','男','1958-12-02','副教授','计算机系');
INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (856,'王旭','男','1969-03-12','讲师','电子工程系');
INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (825,'李萍','女','1972-05-05','助教','计算机系');
INSERT INTO TEACHERS(TNO,TNAME,TSEX,TBIRTHDAY,PROF,DEPART) VALUES (831,'陈冰','女','1977-08-14','助教','电子工程系');
INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('3-105' ,'计算机导论',825);
INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('3-245' ,'操作系统' ,804);
INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('6-166' ,'模拟电路' ,856);
INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('6-106' ,'概率论' ,831);
INSERT INTO COURSES(CNO,CNAME,TNO)VALUES ('9-888' ,'高等数学' ,831);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (103,'3-245',86);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (105,'3-245',75);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (109,'3-245',68);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (103,'3-105',92);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (105,'3-105',88);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (109,'3-105',76);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (101,'3-105',64);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (107,'3-105',91);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (108,'3-105',78);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (101,'6-166',85);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (107,'6-106',79);
INSERT INTO SCORES(SNO,CNO,DEGREE)VALUES (108,'6-166',81);
–2,方式1:笛卡尔积Cartesian product
#多表联查,三种方式:
#方式1:笛卡尔积,用逗号连接多张表
SELECT * FROM dept,emp #产生了大量的结果集
SELECT * FROM dept,emp #逗号隔开表
#描述两张表的关系 表名.字段名
WHERE dept.deptno = emp.deptno
#练习1:查询部门名称和员工表的所有数据
SELECT dept.dname,emp.* FROM dept,emp #逗号隔开表名
WHERE dept.deptno=emp.deptno #表关系
#练习2:查询部门的所有和员工的名字,只要部门名称叫accounting的
SELECT dept.*,emp.ename FROM dept,emp #逗号隔开表名
WHERE dept.deptno=emp.deptno #表关系
AND dept.dname='accounting' #业务条件
#练习3:查询所有部门和员工的数据,条件是部门编号>1的
SELECT * FROM dept,emp
WHERE dept.deptno=emp.deptno#表关系
AND emp.deptno>1 #业务条件
#练习4:查询易天老师能讲的课程名称
SELECT courses.cname FROM teachers,courses
WHERE courses.tno=teachers.tno #表关系
AND teachers.tname='易天' #业务条件
#练习5:查询计算机导论课程的总分
SELECT SUM(degree) FROM courses,scores
WHERE courses.cno=scores.cno #表关系
AND courses.cname='计算机导论' #业务条件
–3,方式2:连接查询 join
①三种连接 join
- 内连接 inner join
- 左(外)连接 left join
- 右(外)连接 right join
②inner join、left join、right join的区别?
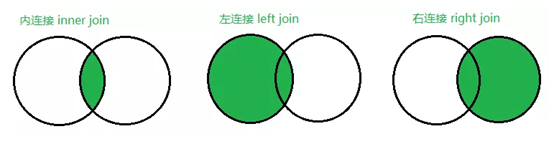
- INNER JOIN两边都对应有记录的才展示,其他去掉
- LEFT JOIN左边表中的数据都出现,右边没有数据以NULL填充
- RIGHT JOIN右边表中的数据都出现,左边没有数据以NULL填充
#方式2:连接查询,用join连接多张表
SELECT * FROM dept JOIN emp #用join连接多张表
SELECT * FROM dept JOIN emp
ON dept.deptno=emp.deptno #表关系
#练习1:查询部门名称和员工表的所有数据
SELECT dept.dname,emp.* FROM dept JOIN emp
ON dept.deptno=emp.deptno#表关系
#练习2:查询部门的所有和员工的名字,只要部门名称叫accounting的
SELECT dept.*,emp.ename FROM emp JOIN dept
ON dept.deptno=emp.deptno #表关系
WHERE dept.dname='accounting' #业务条件
#练习3:查询所有部门和员工的数据,条件是部门编号>1的
SELECT * FROM dept JOIN emp
ON dept.deptno=emp.deptno #表关系
WHERE emp.deptno>1 #业务条件
#练习4:查询易天老师能讲的课程名称
SELECT courses.cname FROM courses JOIN teachers
ON courses.tno=teachers.tno #表关系
WHERE teachers.tname='易天' #业务条件
#练习5:查询计算机导论课程的总分
SELECT SUM(scores.degree) FROM courses JOIN scores
ON courses.cno=scores.cno #表关系
WHERE courses.cname='计算机导论' #业务条件
#测试 三种连接的区别????
#有两种连接查询:内连接和外连接(左外连接,右外连接)
#inner join:取两张表的交集
#left join:左边表的所有和右边满足条件的
#right join:右边表的所有和左边满足条件的
#内连接:取交集,取左右表都满足条件的
SELECT * FROM dept INNER JOIN emp
ON dept.deptno=emp.deptno
#左连接:取左表的所有和右表满足条件的不满足的都是null
SELECT * FROM dept LEFT JOIN emp
ON dept.deptno=emp.deptno
#右连接:取右表的所有和左表满足条件的不满足的都是null
SELECT * FROM emp RIGHT JOIN dept
ON dept.deptno=emp.deptno
#连接查询的效率:小表驱动大表,
#把结构简单或者数据量少的表放在前面作为左表
#因为左表会查所有数据,右表只查满足了条件的那些数据
–4,方式3:子查询subquery
概念
子查询是指嵌入在其他select语句中的select语句,也叫嵌套查询。子查询执行效率低慎用。记录少时效率影响不大、图方便直接使用,记录多时最好使用其它方式替代。也叫嵌套查询,把上次的查询结果,当这次查询的条件来用
单行子查询 =
返回结果为一个
多行子查询 in
in子查询
#方式3:子查询:要分析第一次查啥,第二次查啥
#练习1:查询计算机导论课程的总分
#第一次查:根据cname查cno- 3-105
SELECT cno FROM courses WHERE cname='计算机导论'
#第二次查:根据cno查degree
SELECT SUM(degree) FROM scores WHERE cno='3-105'
#改成子查询:嵌套查询
SELECT SUM(degree) FROM scores WHERE cno=(
SELECT cno FROM courses WHERE cname='计算机导论'
)
#练习2:查询易天老师能讲的课程名称
#第一次查:根据tname查tno 804
SELECT tno FROM teachers WHERE tname='易天'
#第二次查:根据tno查cname
SELECT cname FROM courses WHERE tno=804
#改造 (子查询)
SELECT cname FROM courses WHERE tno=(
SELECT tno FROM teachers WHERE tname='易天'
)
#练习3:查询accounting部门的员工的名字
SELECT ename FROM emp WHERE deptno IN(
SELECT deptno FROM dept WHERE loc='二区'
)
#练习4:查询高于平均工资的员工信息
SELECT * FROM emp WHERE sal>(
SELECT AVG(sal) FROM emp #平均工资
)
–练习1:查询research部门的所有员工姓名和工资
#练习1:查询research部门的所有员工姓名和工资
#方式3:子查询
SELECT emp.ename,emp.sal FROM emp WHERE deptno=(
SELECT deptno FROM dept WHERE dname='research'
)
#方式1:笛卡尔积
SELECT emp.ename,emp.sal FROM emp,dept
WHERE emp.deptno=dept.deptno#表关系
AND dept.dname='research'#业务条件
#方式2:连接查询
SELECT emp.ename,emp.sal FROM dept INNER JOIN emp
ON emp.deptno=dept.deptno#表关系
WHERE dept.dname='research'#业务条件
–练习2:查询research部门的所有员工姓名和工资
#练习2:查询jack所在的部门信息
#方式3:子查询
SELECT * FROM dept WHERE deptno=(
SELECT deptno FROM emp WHERE ename='jack'
)
#方式1:笛卡尔积
SELECT dept.* FROM dept,emp
WHERE emp.deptno=dept.deptno#表关系
AND emp.ename='jack'#业务条件
#方式2:连接查询
SELECT dept.* FROM dept JOIN emp
ON emp.deptno=dept.deptno#表关系
WHERE emp.ename='jack'#业务条件
–练习3:查询总监的部门信息
#练习3:查询总监的部门信息
#方式1:笛卡尔积
SELECT dept.* FROM dept,emp
WHERE emp.deptno=dept.deptno#表关系
AND emp.job='总监'#业务条件
#方式2:连接查询
SELECT dept.* FROM dept JOIN emp
ON emp.deptno=dept.deptno#表关系
WHERE emp.job='总监'#业务条件
#方式3:子查询
SELECT dept.* FROM dept WHERE deptno=(
SELECT deptno FROM emp WHERE job='总监'
)
–练习4:查询李军的平均分
#练习4:查询李军的平均分
#方式3:子查询
SELECT AVG(degree) FROM scores WHERE sno=(
SELECT sno FROM students WHERE sname='李军'
)
#方式1:笛卡尔积
SELECT AVG(scores.degree) FROM students,scores
WHERE students.sno=scores.sno#表关系
AND students.sname='李军'#业务条件
#方式2:连接查询
SELECT AVG(scores.degree) FROM students JOIN scores
ON students.sno=scores.sno#表关系
WHERE students.sname='李军'#业务条件
–练习5:查询陈冰能讲的课程名
#练习5:查询陈冰能讲的课程名
#方式3:子查询
SELECT courses.cname FROM courses WHERE tno=(
SELECT tno FROM teachers WHERE tname='陈冰'
)
#方式1:笛卡尔积
SELECT courses.cname FROM teachers,courses
WHERE teachers.tno=courses.tno #表关系
AND teachers.tname='陈冰'#业务条件
#方式2:连接查询
SELECT courses.cname FROM teachers JOIN courses
ON teachers.tno=courses.tno #表关系
WHERE teachers.tname='陈冰'#业务条件
二,数据库的扩展
–1,索引
定义
索引是一种排好序的快速查找的数据结构,它帮助数据库高效的进行数据的检索。在数据之外,数据库系统还维护着满足特定查找算法的数据结构(额外的存储空间),这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高效的查找算法。这种数据结构就叫做索引。
一般来说索引本身也很大,不可能全部存储在内存中,因此往往以索引文件的形式存放在磁盘中。目前大多数索引都采用BTree树方式构建。
概述
好处是: 提高查询效率 坏处是: 本身是单独的空间来存储
分类:
1,单值索引:一个索引只包含一列
2,唯一索引:一个索引只包含一列,值不能重复
3,复合索引:一个索引包含多个列
单值索引
create index 索引名 on 表名(字段名)–一个索引只包含一个列
#5.创建 唯一索引:一个索引包含一列,值要唯一
CREATE UNIQUE INDEX locindex ON dept(loc)
#添加失败,因为loc的值有重复的
CREATE UNIQUE INDEX dnameindex ON dept(dname)
SHOW INDEX FROM dept#查看索引
#使用索引
EXPLAIN SELECT * FROM dept WHERE dname='research'
唯一索引
create unique index 索引名 on 表名(字段名)
一个索引只包含一个列,列的值不能重复
#5.创建 唯一索引:一个索引包含一列,值要唯一
CREATE UNIQUE INDEX locindex ON dept(loc)
#添加失败,因为loc的值有重复的
CREATE UNIQUE INDEX dnameindex ON dept(dname)
SHOW INDEX FROM dept#查看索引
#使用索引
EXPLAIN SELECT * FROM dept WHERE dname='research'
复合索引
create index 索引名 on 表名(字段名1,字段名2,字段名3…)
一个索引包含多个字段,用时要遵循最左原则,否则复合索引失效
失效的情况:按照 2 3 23 ,没有包含最左边的
#6.创建 复合索引:
CREATE INDEX fuheindex ON emp(ename,job,deptno)
SHOW INDEX FROM emp
#用时可能会让复合索引失效--必须遵循最左原则(必须包含着最左边的)
EXPLAIN SELECT * FROM emp WHERE ename='jack' #生效
EXPLAIN SELECT * FROM emp WHERE job='总监' #失效
EXPLAIN SELECT * FROM emp WHERE ename='jack' AND job='副总' #生效
EXPLAIN SELECT * FROM emp WHERE job='副总'AND ename='jack'#生效
删除索引
alter table 表名 drop index 索引名
show index from 表名
使用explain关键字检查,SQL中是否使用了索引(检查SQL的执行性能)
#7.删除索引
SHOW INDEX FROM emp
ALTER TABLE emp DROP INDEX jobindex
总结
优点:
索引是数据库优化
表的主键会默认自动创建索引
每个字段都可以被索引
大量降低数据库的IO磁盘读写成本,极大提高了检索速度
索引事先对数据进行了排序,大大提高了查询效率
缺点:
索引本身也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也要占用空间
索引表中的内容,在业务表中都有,数据是重复的,空间是“浪费的”
虽然索引大大提高了查询的速度,但对数据的增、删、改的操作需要更新索引表信息,如果数据量非常巨大,更新效率就很慢,因为更新表时,MySQL不仅要保存数据,也要保存一下索引文件
随着业务的不断变化,之前建立的索引可能不能满足查询需求,需要消耗我们的时间去更新索引
视图View
概念
可视化的表,视图当做是一个特殊的表,是指,把sql执行的结果,直接缓存到了视图中。
下次还要发起相同的sql,直接查视图。现在用的少,了解即可.
使用: 1,创建视图 2,使用视图
测试
#视图:创建视图+使用视图
#练习:查询名字里有a的员工信息
SELECT * FROM emp WHERE ename LIKE '%a%'
#1.创建视图:create view 视图名 as select语句
CREATE VIEW empview AS
SELECT * FROM emp WHERE ename LIKE '%a%'
#2.使用视图
SELECT * FROM empview
#好处:提高了SQL的复用性+屏蔽了业务表的复杂性+数据共享
#坏处:是一张单独的表存了业务表的数据造成了数据重复+无法优化
–3,SQL优化
1, 用字段名称代替*
2, where里: 尽量用and不用or , 尽量用=不用!= <> , 条件越精确越好 ,
3, 表设计:
表里的索引不要超过5个 , 给where后或者order by经常用的字段加索引 ,复合索引要遵循最左特性不然就失效了 , 索引表及时删掉多余的索引
用varchar代替char , 用数字代替字符串 , 用默认值代替null
4, 批量处理:
批量查,批量的删,最好使用分页
三范式
1 第一范式(1NF)
在任何一个关系数据库中,第一范式(1NF) [2] 是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。
简而言之,第一范式就是无重复的列。
2 第二范式(2NF)
第二范式(2NF) [2] 是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
简而言之,第二范式就是非主属性完全依赖于主关键字。
3 第三范式(3NF)
满足第三范式(3NF) [2] 必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在图3-2的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
简而言之,第三范式就是属性不依赖于其它非主属性。