初识JVM:
大纲:
n JVM的概念
n JVM发展历史
n JVM种类
n Java语言规范
n JVM规范
JVM的概念:
n JVM是Java Virtual Machine的简称。意为Java虚拟机
n 虚拟机
– 指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统
n 有哪些虚拟机
– VMWare
– Visual Box
– JVM
n VMWare或者Visual Box都是使用软件模拟物理CPU的指令集
n JVM使用软件模拟Java 字节码的指令集
Java和JVM的历史:
n 1996年 SUN JDK 1.0 Classic VM
– 纯解释运行,使用外挂进行JIT
n 1997年 JDK1.1 发布
– AWT、内部类、JDBC、RMI、反射
n 1998年 JDK1.2 Solaris Exact VM
– JIT 解释器混合
– Accurate Memory Management 精确内存管理,数据类型敏感
– 提升的GC性能
– JDK1.2开始 称为Java 2。J2SE, J2EE, J2ME 的出现加入Swing Collections
n 2000年 JDK 1.3 Hotspot 作为默认虚拟机发布,加入JavaSound
n 2002年 JDK 1.4 Classic VM退出历史舞台,Assert 正则表达式 NIO IPV6 日志API 加密类库
n 2004年发布 JDK1.5 即 JDK5 、J2SE 5 、Java 5
– 泛型
– 注解
– 装箱
– 枚举
– 可变长的参数
– Foreach循环
n JDK1.6 JDK6
– 脚本语言支持
– JDBC 4.0
– Java编译器 API
n 2011年 JDK7发布
– 延误项目推出到JDK8
– G1
– 动态语言增强
– 64位系统中的压缩指针
– NIO 2.0
n 2014年 JDK8发布
– Lambda表达式
– 语法增强 Java类型注解
n 2016年JDK9
– 模块化
JVM大事记
n 使用最为广泛的JVM为HotSpot
n HotSpot 为Longview Technologies开发 被SUN收购
n 2006年 Java开源 并建立OpenJDK
– HotSpot 成为Sun JDK和OpenJDK中所带的虚拟机
n 2008 年 Oracle收购BEA
– 得到JRockit VM
n 2010年Oracle 收购 Sun
– 得到Hotspot
n Oracle宣布在JDK8时整合JRockit和Hotspot,优势互补
– 在Hotspot基础上,移植JRockit优秀特性
各种JVM
n KVM
– SUN发布
– IOS Android前,广泛用于手机系统
n CDC/CLDC HotSpot
– 手机、电子书、PDA等设备上建立统一的Java编程接口
– J2ME的重要组成部分
n JRockit
– BEA
n IBM J9 VM
– IBM内部
n Apache Harmony
– 兼容于JDK 1.5和JDK 1.6的Java程序运行平台
– 与Oracle关系恶劣 退出JCP ,Java社区的分裂
– OpenJDK出现后,受到挑战 2011年 退役
– 没有大规模商用经历
– 对Android的发展有积极作用
规范
n Java语言规范
– 语法
– 变量
– 类型
– 文法
n JVM规范
– Class文件类型
– 运行时数据
– 帧栈
– 虚拟机的启动
– 虚拟机的指令集
Java语言规范
语法定义
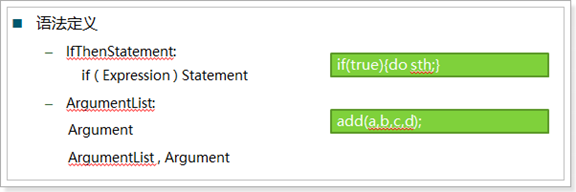
关于if语句块的定义,关于参数列表的定义等;
词法结构
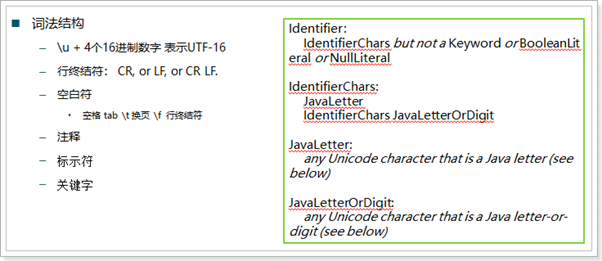
| Identifier: 标识符: |
Java之关于标识符 Java语言要求类名、方法名、变量名、常量名等都必须是合法的标识符。我们通常所说的标识符第一个字符必须是字母、下划线或者$,后面的字符可以是上面的字符或者是数字,当然前提是后面还有字符。通过查找资料才知道,原来这里的字母并不单纯指我们熟悉的26个大小写字母,而是指Unicode字符集。 于是标识符的定义又有了如下规则: 1,首字符所对应的代码点必须使得Character类的isJavaIdentifierStart方法返回值为true,如果有后续字符,那么后续字符所对应的代码点必须使得Character类的isJavaIdentifierPart方法返回值为true; 2,标识符不能和Java中的关键字和保留字相同; 3,标识符不能和Java中预定义的字面常量相同; 4,标识符长度必须在系统支持范围内。 另外需要注意的是: 1,Java将goto和const定义为保留字,基本没有语法应用,但是不能使用它们作为标识符; 2,系统定义的true,false,null并不是关键字,而是字面常量,仍然不允许作为标识符使用; 3,$可作为标识符使用,但是我们应该减少对他的使用。因为$通常在编译器生成的标识符名称中使用。假如一个类为A,在内部声明成员类B,编译后就会产生A.class和A$B.class,如果我先定义一个类为A$B,然后定义一个类为A,并在A内部声明成员类B,编译之后就会生成三个class文件:A$B.class,A.class,A$B.class,因为产生两个A$B.class,故会报编译错误; 4,在Java语言规范中,标识符的长度是任意的;Java虚拟机规范中,标识符是有长度限制的,最大长度为65535,但是这个最大长度仅限于除空字符null以外的字符; 5,标识符区分大小写。 |
| public static void 打印(){ System.out.println("中文方法哦"); } public static void main(String[] args) { 打印();//java内部采用了Unicode字符集,universal。 } 从例子中看到方法名称是汉字,那他可不可以呢?究其原因是什么呢,正如注释中解释的那样,Java内部采用的是Unicode(universal code)的字符集,Unicode是国际通用字符集。Unicode分为UTF-8和UTF-16实现..\字符编码笔记:ASCII,Unicode 和 UTF-8\字符编码笔记:ASCII,Unicode 和 UTF-8.docx。UTF-8是一种可变的字符编码方式,可以是1个、2个或3个字节,而UTF-16有2个子节组成。汉字是由两个字节表示的,用Unicode字符集能够表示汉字,所以Java的标识符可以表示为汉字。当然了,如果是在开发的过程中,应该是不会有人选择用汉字来给标识符命名的,这样做是要承担很大的风险的。 |
– Int
– 0 2 0372 0xDada_Cafe 1996 0x00_FF__00_FF
– Long
– 0l 0777L 0x100000000L 2_147_483_648L 0xC0B0L
– Float
– 1e1f 2.f .3f 0f 3.14f 6.022137e+23f
– Double
– 1e1 2. .3 0.0 3.14 1e-9d 1e137
– 操作
– += -= *= /= &= |= ^= %= <<= >>= >>>=
类型和变量
– 元类型
– byte short int long float char
– 变量初始值
– boolean false
– char \u0000
– 泛型
| class Value { int val; } class Test { public static void main(String[] args) { int i1 = 3; int i2 = i1; i2 = 4; System.out.print("i1==" + i1); System.out.println(" but i2==" + i2); Value v1 = new Value(); v1.val = 5; Value v2 = v1; v2.val = 6; System.out.print("v1.val==" + v1.val); System.out.println(" and v2.val==" + v2.val); } } 程序输出: i1==3 but i2==4 v1.val==6 and v2.val==6 原因: i1 i2为不同的变量 v1 v2为引用同一个实例 |
Java内存模型
类加载链接的过程
public static final abstract的定义
异常
数组的使用
…….
JVM规范
n Java语言规范定义了什么是Java语言
n Java语言和JVM相对独立
– Groovy
– Clojure
– Scala
n JVM主要定义二进制class文件和JVM指令集等
JVM规范包括:
n Class 文件格式
n 数字的内部表示和存储
– Byte -128 to 127 (-27 to 27 - 1)
n returnAddress 数据类型定义
– 指向操作码的指针。不对应Java数据类型,不能在运行时修改。Finally实现需要
n 定义PC
n 堆
n 栈
n 方法区
整数的表达,JVM使用的是补码
– 原码:第一位为符号位(0为正数,1为负数)
– 反码:符号位不动,原码取反
– 负数补码:符号位不动,反码加1
– 正数补码:和原码相同
| 5 原码:00000101 -6 原码: 10000110 反码: 11111001 补码: 11111010 -1 原码: 10000001 反码: 11111110 补码: 11111111 打印JVM种整数的二进制表示 int a=-6; for(int i=0;i<32;i++){ int t=(a & 0x80000000>>>i)>>>(31-i); System.out.print(t); } |
为什么要用补码?
| 计算0的表示: 0 正数:00000000 负数:10000000 0 正数:00000000 – 正数补码:和原码相同 0 负数:10000000 反码:11111111 补码:00000000 -6+5 11111010 + 00000101 = 11111111 -4+5 11111100 + 00000101 = 00000001 -3+5 11111101 + 00000101 = 00000010 |
0是一个非常特殊的数字,它既不属于整数,也不属于负数。所以0在二进制中很难表示。
例如:0
正数:00000000
负数:10000000
因为我们不知道0的表示方式,显然这种表示是会有问题的。
如果我们用补码来表示0会怎么样呢?
例如,如果把0当成是正数:
0
正数:00000000
正数的补码是源码本身。是全0.
例如,如果把0当成是负数:补码是反码加1,也是全0.
0
负数:10000000
反码:11111111
补码:00000000
使用补码的好处:
1, 使我们能够没有歧义的去表示0这个数字。不管你把0认为是正数也好,负数也好,它的补码都是全0.所以0在计算机中的表示就是全0.
2, 补码能够很好的参与计算机当中的二进制的运算,比如:
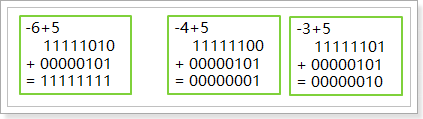
比如计算-6+5,如果是补码的话,计算机只需要简单的把这两个数字的补码相加就可以了,得到全1,全1就是-1的补码。计算结果正确。后面两个的计算同理。因此,我们可以看到,使用补码作运算的时候,它非常方便。加法是一个基本的运算,减法可以表示成加法,如果我们计算加法的时候,我们使用补码的话,我们只需要简单的计算两个补码的和就可以直接得到正确的结果,并且符号位是直接参与运算的。而如果使用源码来表示数字,那么计算得到的结果就不是我们想要的结果。
float的表示与定义
一些特殊的方法
<clinit>
<init>
init和clinit区别
① init和clinit方法执行时机不同
init是对象构造器方法,也就是说在程序执行 new 一个对象调用该对象类的 constructor 方法时才会执行init方法;
而clinit是类构造器方法,也就是在jvm进行类加载—–验证—-准备—-解析—–初始化,中的初始化阶段jvm会调用clinit方法。
② init和clinit方法执行目的不同
init is the (or one of the) constructor(s) for the instance, and non-static field initialization. 是实例的(或其中一个)构造函数,以及非静态字段初始化。
clinit are the static initialization blocks for the class, and static field initialization. 是类的静态初始化块,以及静态字段初始化。
上面这两句是Stack Overflow上的解析,很清楚init是instance实例构造器,对非静态变量解析初始化,而clinit是class类构造器对静态变量,静态代码块进行初始化。看看下面的这段程序就很清楚了。
class X {
static Log log = LogFactory.getLog(); // <clinit>
private int x = 1; // <init>
X(){
// <init>
}
static {
// <clinit>
}
}
clinit详解
在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则根据程序员通过程序制定的主观计划去初始化类变量和其他资源,或者可以从另外一个角度来表达:初始化阶段是执行类构造器<clinit>()方法的过程。
①<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问如下代码
public class Test{
static{
i=0;//给变量赋值可以正常编译通过
System.out.print(i);//这句编译器会提示"非法向前引用"
}
static int i=1;
}
②虚拟机会保证在子类的<clinit>()方法执行之前,父类的<clinit>()方法已经执行完毕。 因此在虚拟机中第一个被执行的<clinit>()方法的类肯定是java.lang.Object。由于父类的<clinit>()方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作,如下代码中,字段B的值将会是2而不是1。
static class Parent{
public static int A=1;
static{
A=2;}
static class Sub extends Parent{
public static int B=A;
}
public static void main(String[]args){
System.out.println(Sub.B);
}
}
③接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成<clinit>()方法。 但接口与类不同的是,执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法。 只有当父接口中定义的变量使用时,父接口才会初始化。 另外,接口的实现类在初始化时也一样不会执行接口的<clinit>()方法。
注意:接口中的属性都是static final类型的常量,因此在准备阶段就已经初始化话。
VM指令集
n 类型转化
– l2i
n 出栈入栈操作
– aload astore
– aload将一个局部变量加载到操作栈
– astore将一个数值从操作数栈存储到局部变量表
n 运算
– iadd isub
n 流程控制
– ifeq ifne
n 函数调用
– invokevirtual invokeinterface invokespecial invokestatic
– 方法调用相关的jvm子令集主要有一下5种:
–
– invokestatic ------------------------------->调用类方法(静态绑定,速度快)
–
– invokevirtual ------------------------------>调用实例方法(动态绑定)
–
– invokespecial ----------------------------->调用实例方法(静态绑定,速度快)
–
– invokeinterface --------------------------->调用引用类型为interface的实例方法(动态绑定)
–
– invokedynamic --------------------------->JDK 7引入的,主要是为了支持动态语言的方法调用。可参考
– New JDK 7 Feature: Support for Dynamically Typed Languages in the Java Virtual Machine
JVM需要对Java Library[z1] 提供以下支持:
n 反射 java.lang.reflect
n ClassLoader
n 初始化class和interface
n 安全相关 java.security
n 多线程
n 弱引用
Java中的弱引用
What——什么是弱引用?
Java中的弱引用具体指的是java.lang.ref.WeakReference<T>类,我们首先来看一下官方文档对它做的说明:
弱引用对象的存在不会阻止它所指向的对象被垃圾回收器回收。弱引用最常见的用途是实现规范映射(canonicalizing mappings,比如哈希表)。
假设垃圾收集器在某个时间点决定一个对象是弱可达的(weakly reachable)(也就是说当前指向它的全都是弱引用),这时垃圾收集器会清除所有指向该对象的弱引用,然后把这个弱可达对象标记为可终结(finalizable)的,这样它随后就会被回收。与此同时或稍后,垃圾收集器会把那些刚清除的弱引用放入创建弱引用对象时所指定的引用队列(Reference Queue)中。
实际上,Java中存在四种引用,它们由强到弱依次是:强引用、软引用、弱引用、虚引用。下面我们简单介绍下除弱引用外的其他三种引用:
· 强引用(Strong Reference):通常我们通过new来创建一个新对象时返回的引用就是一个强引用,若一个对象通过一系列强引用可到达,它就是强可达的(strongly reachable),那么它就不被回收
· 软引用(Soft Reference):软引用和弱引用的区别在于,若一个对象是弱引用可达,无论当前内存是否充足它都会被回收,而软引用可达的对象在内存不充足时才会被回收,因此软引用要比弱引用“强”一些
· 虚引用(Phantom Reference):虚引用是Java中最弱的引用,那么它弱到什么程度呢?它是如此脆弱以至于我们通过虚引用甚至无法获取到被引用的对象,虚引用存在的唯一作用就是当它指向的对象被回收后,虚引用本身会被加入到引用队列中,用作记录它指向的对象已被回收。
Why——为什么使用弱引用?
考虑下面的场景:现在有一个Product类代表一种产品,这个类被设计为不可扩展的,而此时我们想要为每个产品增加一个编号。一种解决方案是使用HashMap<Product, Integer>。于是问题来了,如果我们已经不再需要一个Product对象存在于内存中(比如已经卖出了这件产品),假设指向它的引用为productA,我们这时会给productA赋值为null,然而这时productA过去指向的Product对象并不会被回收,因为它显然还被HashMap引用着。所以这种情况下,我们想要真正的回收一个Product对象,仅仅把它的强引用赋值为null是不够的,还要把相应的条目从HashMap中移除。显然“从HashMap中移除不再需要的条目”这个工作我们不想自己完成,我们希望告诉垃圾收集器:在只有HashMap中的key在引用着Product对象的情况下,就可以回收相应Product对象了。显然,根据前面弱引用的定义,使用弱引用能帮助我们达成这个目的。我们只需要用一个指向Product对象的弱引用对象来作为HashMap中的key就可以了。
How——如何使用弱引用?
拿上面介绍的场景举例,我们使用一个指向Product对象的弱引用对象来作为HashMap的key,只需这样定义这个弱引用对象:
| 1 2 |
|
现在,弱引用对象weakProductA就指向了Product对象productA。那么我们怎么通过weakProductA获取它所指向的Product对象productA呢?很简单,只需要下面这句代码:
| 1 |
|
实际上,对于这种情况,Java类库为我们提供了WeakHashMap类,使用和这个类,它的键自然就是弱引用对象,无需我们再手动包装原始对象。这样一来,当productA变为null时(表明它所引用的Product已经无需存在于内存中),这时指向这个Product对象的就是由弱引用对象weakProductA了,那么显然这时候相应的Product对象时弱可达的,所以指向它的弱引用对象会被清除,这个Product对象随即会被回收,指向它的弱引用对象会进入引用队列中。
引用队列
下面我们来简单地介绍下引用队列的概念。实际上,WeakReference类有两个构造函数:
| 1 2 3 4 |
|
我们可以看到第二个构造方法中提供了一个ReferenceQueue类型的参数,通过提供这个参数,我们便把创建的弱引用对象注册到了一个引用队列上,这样当它被垃圾回收器清除时,就会把它送入这个引用队列中,我们便可以对这些被清除的弱引用对象进行统一管理。
JVM的编译
n 源码到JVM指令的对应格式
n Javap
javap是jdk自带的一个工具,可以对代码反编译,也可以查看java编译器生成的字节码。
n JVM反汇编的格式
– <index> <opcode> [ <operand1> [ <operand2>... ]] [<comment>]
– 反汇编(Disassembly):把目标代码转为汇编代码的过程,也可以说是把机器语言转换为汇编语言代码、低级转高级的意思
| 源码: void spin() { int i; for (i = 0; i < 100; i++) { ; // Loop body is empty } } |
JVM指令: 0 iconst_0 // Push int constant 0 1 istore_1 // Store into local variable 1 (i=0) 2 goto 8 // First time through don't increment 5 iinc 1 1 // Increment local variable 1 by 1 (i++) 8 iload_1 // Push local variable 1 (i) 9 bipush 100 // Push int constant 100 11 if_icmplt 5 // Compare and loop if less than (i < 100) 14 return // Return void when done |
[z1]Java类库: library 是一系列由开发者已写好的类的集合,它们只实现特定的功能点,通过 library 你可以调用其他开发者写好的类,所以可以说 library 是为了方便代码重用。library 里面的类都是用于处理特定的问题的。例如,一个用于处理数学运算的 library,它里面的类都是用于计算特定的数学问题,如计算定积分、解方程等等。还有图片处理的 library,用于对图片进行各种编辑操作等等。library 里的类的各种函数都实现好了处理各种特定问题的算法,开发者可以调用它们处理问题,也可以覆盖某些函数。