01【TcaplusDB知识库】什么是TcaplusDB数据库?
TcaplusDB与MongoDB术语对比
| SQL术语/概念 | MongoDB术语/概念 | TcaplusDB术语/概念 | 解释/说明 |
|---|---|---|---|
| database | database | cluster | 数据库 |
| table | collection | tablegroup/table | 数据库表/集合 |
| row | document | record | 数据记录行/文档 |
| column | field | field | 数据字段/域 |
| index | index | index | 索引 |
| primary key | primary key | primary key | “主键,MongoDB自动将_id字段设置为主键” |
表
TcaplusDB表由主键字段和非主键字段两部分组成,主键字段最多可以指定8个,普通字段(非普通字段)最多可以指定256个。
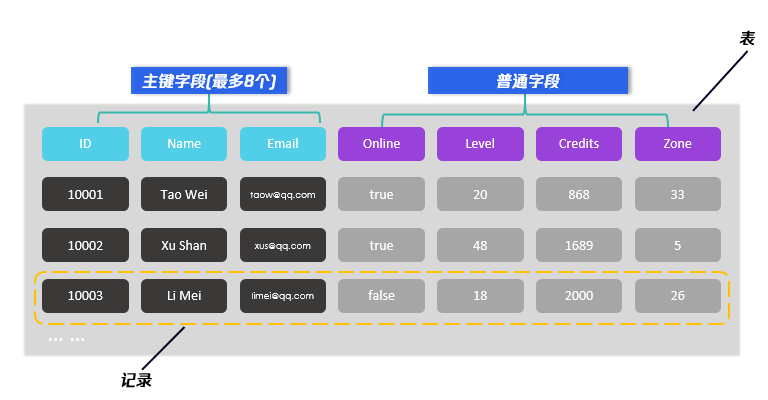
按照表定义可分为Protobuf表和TDR表,按照表结构可以分为Generic表和List表。
分表因子
Tcaplus的表定义要求设置一个分表因子(splittablekey)属性,分表因子必须是主键字段(primarykey)的子集。本质上,splittablekey所包含的字段将参与hash计算,然后根据hash值决定该记录被存储至集群中的哪个节点。因此,一个表的多个记录,它们splittablekey字段的值应该是多样化的,这样数据分布才比较均衡。举例来说,假设一个表的primarykey是"uid,role_id,zone_id",其中uid和role_id的值足够多样,而zone_id只有几个、最多几百个不同的值,那么使用zone_id作为splittablekey将会有很大的风险,若某个特定zone_id对应的记录特别多,会导致Tcaplus特定的存储节点严重过载,甚至数据量超过机器存储容量而无法提供服务。假设一个表的分表因子是性别,这会导致数据最多分布到2个存储节点, 那么业务的分布式能力就会被限制到最多2个存储节点的性能上。
分表因子决定了数据的物理分布(系统根据该字段做hash分散到不同节点),建议取离散度高的字段,利于负载均衡。不指定时默认取primarykey的所有字段。
记录
TcaplusDB记录由一行字符串组成每个字段的数字都支持嵌套类型,嵌套最多32层。单个记录大小最高10MB,可以将常用的对象文件序列化成二进制文件存储。

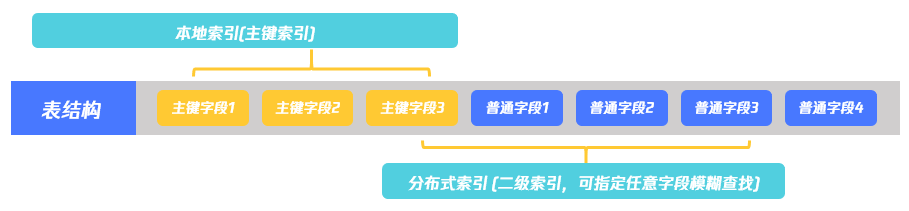
索引
TcaplusDB支持两种形式的索引:本地索引和全局索引。
- 本地索引:基于TcaplusDB主键字段建立的索引,在建表时随表一起建立。
- 全局索引:基于TcaplusDB表一级字段(包括主键字段和非主键字段)建立的索引。
通过本地索引和全局索引,用户可方便利用索引进行数据查询。优势:
- 基于本地索引查询,可以满足用户通过部分主键字段进行索引查询
- 基于全局索引,可以满足用户通过任意一级字段进行多种形式查询,如范围、模糊、聚合、分页等。
本地索引
基于TcaplusDB主键字段建立的索引,在建表时随表一起建立。
创建
本地索引是在建立表的时候,在表定义中申明的,比如proto或者xml文件中。并且一旦表创建后,就不能再增加、修改和删除本地索引了,删除表的时候,本地索引会一并删除。
查询
本地索引只支持等值查询,也就说,使用本地索引查询时,需要将本地索引中定义的字段全部都给值,比如定义了本地索引,包含字段为key1, key2,那么使用该索引进行查询时,就必须把key1和key2的值给出来才可以,并且是key1=XXX and key2=XXX的方式进行查询;
在tcaplus中,对应的是GetByPartKey请求,只有该请求是利用本地索引进行查询的;
由于本地索引查询时,可能会返回非常多的数据,此时,tcaplus会进行分包返回的,如果业务侧收包速度低于tcaplus返回响应包的速度,那么就可能导致tcaplus出现因为网络缓存区满而丢包的情况,一般建议是使用本地索引查询时,利用limit和offset的方式来分多次请求数据,特别是当数据量很大时。
特点
- 本地索引是实时索引,当插入或者删除数据时,会同时更新索引数据;
- 本地索引的字段必须包含在主键字段中,并且字段中还必须包含分表因子,因此,查询时最终只会落到一个数据分片上进行查询;
- 本地索引只支持等值查询;
- 一个表可以建立多个本地索引,查询时必须包含某一个本地索引的全部字段;
- 目前只有generic表支持本地索引;
约束
- 本地索引一旦创建,无法在使用期间修改、删除、新增,随表删除而删除。
- 本地索引只支持精确匹配,即在用本地索引字段作为查询条件时,只能精确匹配到具体值,不支持模糊、范围匹配。
- 本地索引必须包含分片因子。
- 本地索引中的字段都必须属于主键字段。
- 对其它非主键字段建立本地索引也是不允许的。
注意事项
假设本地索引包含的字段为key1, key2,如果出现key1=XXX and key2=XXX的记录数非常多时,当进行这个条件的本地索引查询时,就很容易出现性能问题,需要尽量避免,当然,目前tcaplus是没有限制记录数个数的。
全局索引
全局索引是基于TcaplusDB表一级字段(包括主键字段和非主键字段)建立的索引,顾名思义,就是tcaplus与索引系统之间是相互独立的,通过异步同步的方式,将tcaplus中的数据同步到索引系统,因此,全局索引是一个准实时索引系统,即进行索引查询时,tcaplus表中新更新的数据无法实时查询出来,正常情况下,新更新的数据到能够通过索引查询出来的时延为秒级,大部分情况是1秒之内;
全局索引目前只支持对generic表建立索引,并且只支持表的一级字段(包括key字段和value字段)建立索引;并且也只支持简单类型建立索引,支持的类型包括:int8, uint8, int16, uint16, int32, uint32, int64, uint64, float, double, string(字符串); 对于pb表的bool和enum类型也支持,当pb表字段定义为string类型,如果该字段存储的是二进制,那么查询结果可能会不符合预期;对于uint64类型,如果值大于int64的最大值,查询结果将不符合预期,因此,如果该字段值会超过int64的最大值,建议不要为该字段建立索引;
tcaplus支持动态创建和修改索引,业务可以随时增加或删除或者修改全局索引,修改全局索引时,比如增加了一个索引字段,不会影响业务对修改前的全局索引查询;
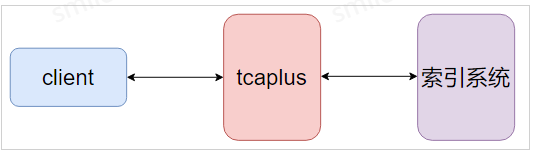
tcaplus与全局索引之间的架构如下图所示:
创建
创建或者修改全局索引,需要在页面上进行申请,进入oms页面,点击 “业务管理” ---- > “表管理” ---- > 选择要创建全局索引的表,拉到最右侧,如下图:
点击 “索引”,进入到索引配置页面,在该页面勾上要建立索引的字段,然后点击“确认创建索引”按钮,这样就生成了创建全局索引的申请单,dba审核之后,会生成一个创建全局索引的事务,当事务执行成功后,该索引就可以被访问了。
数据同步
数据同步,是指tcaplus数据同步到索引系统,两者之间的数据是最终一致的,数据同步架构如下图所示:

查询
tcaplus提供sql查询语句进行索引查询,其中,sql查询条件中的字段必须是建立了全局索引的字段,另外,如果是聚合查询,那么聚合查询的字段也必须是建立了全局索引的字段;
一个索引查询请求,当前限制最多返回3000条记录;
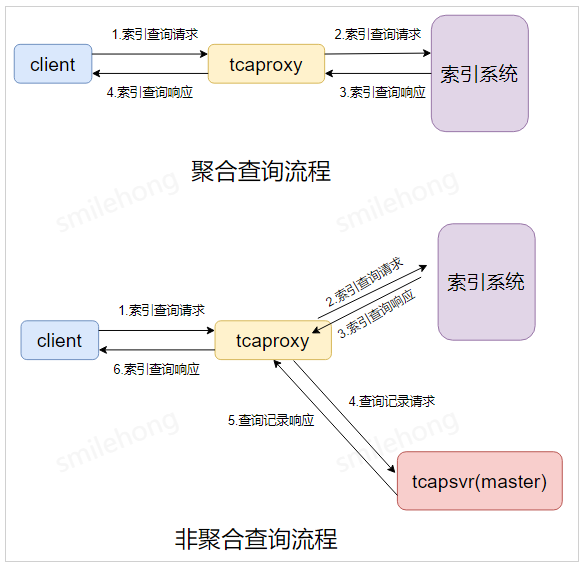
索引使用方式
- tcaplus_client客户端工具
tcaplus_client工具支持全局索引查询,查询命令直接使用sql查询语句进行查询即可,使用help select 命令可以获取相关查询命令。注意tcaplusdb_client使用版本,目前最新的支持3.46.0。
- C++ SDK
C++ SDK 已集成相关全局索引API,在示例代码中也有相关实现,具体请参考:
C++ TDR SDK 全局二索引示例路径
TcaplusServiceApiXXX/release/x86_64/examples/tcaplus/C++_tdr1.0_syncmode_generic_simpletable/SingleOperation/globle_index_query
C++ PB SDK全局索引示例路径
TcaplusPbApiXXX/release/x86_64/examples/tcaplus/C++_pb2_coroutine_simpletable/SingleOperation/global_index_query
支持的sql语句
- 条件查询
支持 =, >, >=, <, <=, !=, between, in, not in, like, not like, and, or , 比如:
select * from table where a > 100 and b < 1000;
select * from table where a between 1 and 100 and b < 1000;
select * from table where str like "test";
select * from table where a > 100 or b < 1000;
注意:between查询时,between a and b,对应的查询范围为[a, b],比如 between 1 and 100, 是会包含1和100这两个值的,即查询范围为[1,100]
注意:like查询是支持模糊匹配,其中"%"通配符,匹配0个或者多个字符; “_”通配符,匹配1个字符;
- 分页查询
支持limit offset分页查询,比如:
select * from table whre a > 100 limit 100 offset 0;
注意:当前limit必须与offset搭配使用,即不支持limit 1 或者 limit 0,1这种;
- 聚合查询
当前支持的聚合查询包括:sum, count, max, min, avg,比如:
select sum(a), count(*), max(a), min(a), avg(a) from table where a > 1000;
注意:聚合查询不支持limit offset,即limit offset 不生效;
注意:目前只有count支持distinct,即 select count(distinct(a)) from table where a > 1000; 其他情况均不支持distinct
- 部分字段查询
支持查询部分字段的值,比如:
select a, b from table where a > 1000;
对于pb表,还支持查询嵌套字段的值,类似:
select field1.field2.field3, a, b from table where a > 1000;
不支持的sql查询语句
- 不支持聚合查询与非聚合查询混用
select *, a, b from table where a > 1000;
select sum(a), a, b from table where a > 1000;
select count(*), * from table where a > 1000;
- 不支持order by查询
select * from table where a > 1000 order by a;
- 不支持group by查询
select * from table where a > 1000 group by a;
- 不支持having查询
select sum(a) from table where a > 1000 group by a having sum(a) > 10000;
- 不支持多表联合查询
select * from table1 where table1.a > 1000 and table1.a = table2.b;
- 不支持嵌套select查询
select * from table where a > 1000 and b in (select b from table where b < 5000);
- 不支持别名
select sum(a) as sum_a from table where a > 1000;
- 不支持的其他查询
- 不支持join查询;
- 不支持union查询;
- 不支持类似 select a+b from table where a > 1000 的查询;
- 不支持类似 select * from table where a+b > 1000 的查询;
- 不支持类似 select * from table where a >= b 的查询;
- 不支持其他未提到的查询。

TcaplusDB是腾讯出品的分布式NoSQL数据库,存储和调度的代码完全自研。具备缓存+落地融合架构、PB级存储、毫秒级时延、无损水平扩展和复杂数据结构等特性。同时具备丰富的生态、便捷的迁移、极低的运维成本和五个九高可用等特点。客户覆盖游戏、互联网、政务、金融、制造和物联网等领域。