首先为什么要把二叉树线索化呢,首先的首先我们来理解下遍历二叉树的本质意义:遍历二叉树是以一定的规则把二叉树中的结点排列成一个线性序列,这实质上是对一个非线性的结构进行线性化的操作使每个结点在这个线性序列上都有一个前驱和后继(首尾只有后继或前驱)
比如某二叉树结点的中序序列abcde,c的前驱和后继分别是b,d.
但是,每个结点只能找到它的左右孩子信息,而不是前驱后继的信息。那再加两个指针不就好了,但这样就降低结构的存储密度了
我们的叶子结点的指针域是空着的,而且,有n个结点的二叉链表必定存在n+1个空链域,证明如下:
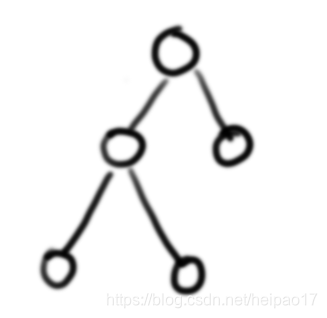
放个图好想象一点
设有n个结点,那么一定有2n个指针域,每个分支占去一个指针域(就是上图的每条线都会占去一个指针域),而每个结点除了头结点都会有一个分支进入结点(每个⚪的头顶处了头结点都有一条线)所以n个结点就有n-1个分支,即n个头结点就占去了n-1个指针域,而n个结点一共有2n个指针域,2n-(n-1)即剩下的空指针域,要就是n+1;
但人家指针还是叫lchild和rchild,所以,得加两个标志,Ltag,Rtag(线索标志)
规则如下:
Ltag=0时,lchild指示左孩子,Ltag=1时lchild指示结点的前驱
Rtag=0时,Rtag指示右孩子,Rtag=1时Rchild指示结点的后继
上代码
先写下二叉树的线索存储结构
typedef struct bithrnode
{
int data;
struct bithrnode *lchild,*rchild;//左右孩子指针
int Ltag,Rtag; //左右标志
}bithrnode,*bithrtree;
中序线索化代码
bithrtree pre;
pre->rchild=NULL; //pre表示刚访问完的结点,初始化时将其右孩子置为空,便于在树的最左点开始建线索
void inthreading(bithrtree p)
{
if(p)
{
inthreading(p->lchild);
if(!p->lchild) //p的左孩子为空
{
p->Ltag=1;
p->lchild=pre;
}
else p->Ltag=0;
if(!pre->rchild)
{
pre->Rtag=1;
pre->rchild=p;
}
else pre->Rtag=0;
pre=p;
inthreading(p->rchild);
}
}
因为现在只知道p和pre,所以用p来串前驱,用pre来串后继
有线索标志就为一,没线索标志就为0;