文章目录
一、准备工作
1、正常流程
参考教程链接:Tesseract OCR V5.0安装教程(Windows)
流程概览:
- 下载tesseract程序
- 设置环境变量
- 检查是否安装成功
- 使用拓展语言包-中文
- 查看支持语言是否ok
2、持续报错及解决
jupyter持续路径报错
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH
用教程里的代测试了一些自己是否有安装成功,但jupyter一直报错。
反复订正自己的安装流程,确定没有一点点问题,但偏偏就给我整这么一出。
思来想去,可能是jupyter和原生python不一样(之前也遇到过同样的问题)。
于是在原生python中试了一下。
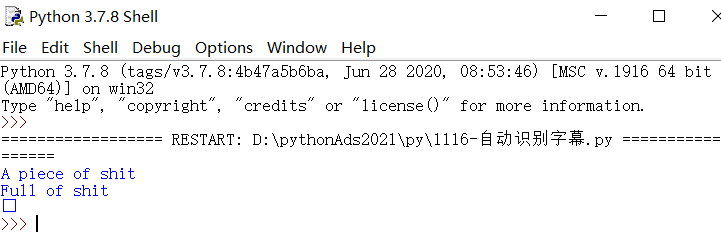

成了!!
解决jupyter环境变量问题
找到了问题所在,但解决仍然艰巨。
千辛万苦找到了这个教程:Jupyter notebok 环境配置,与kernel切换(切换虚拟环境)
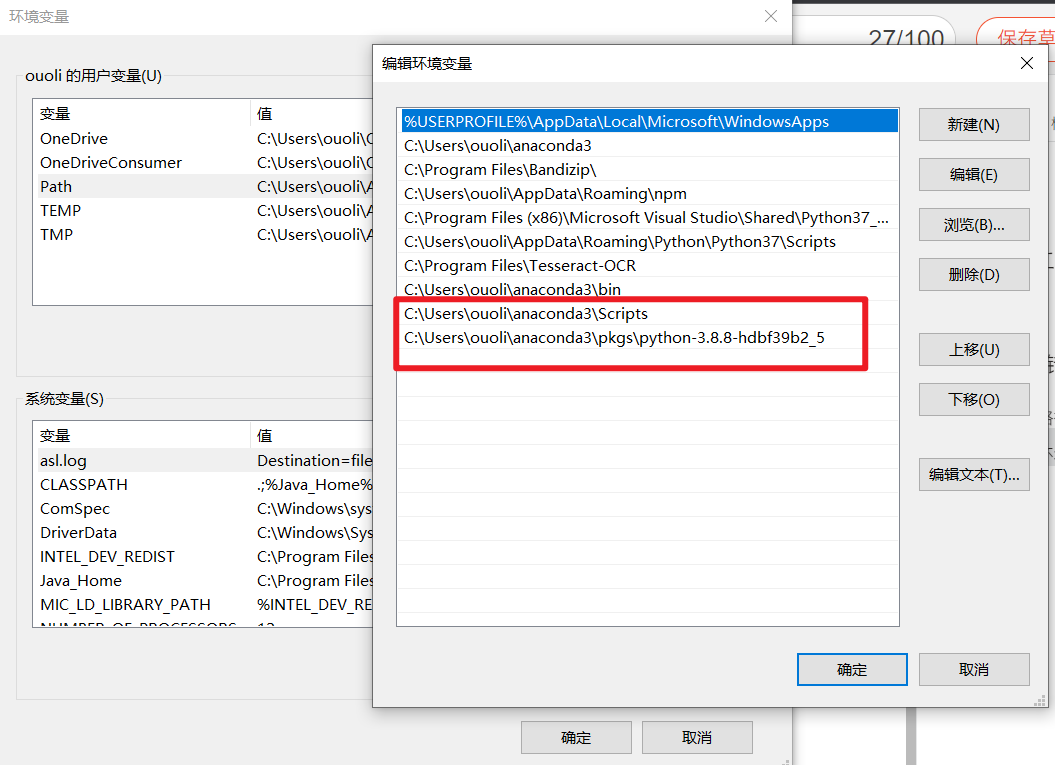
新建了这两个环境变量。
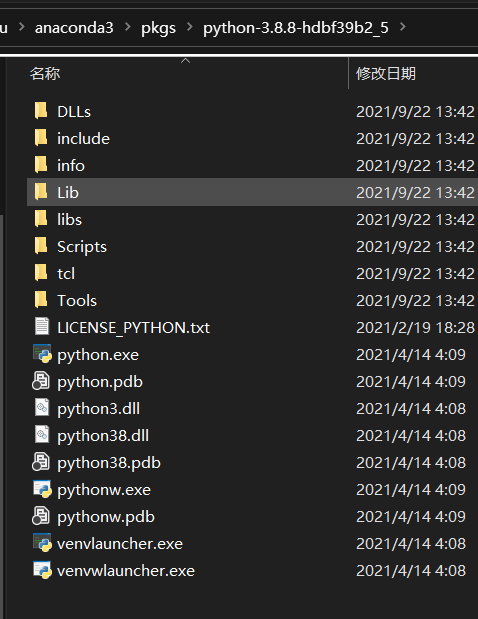
如何找到特定的路径
C:\Users\ouoli\anaconda3\pkgs\python-3.8.8-hdbf39b2_5
对于这个奇怪的路径,大家自己不要直接复制。
在搜索框里搜索jupyter,连续两次使用**【打开文件所在位置】**
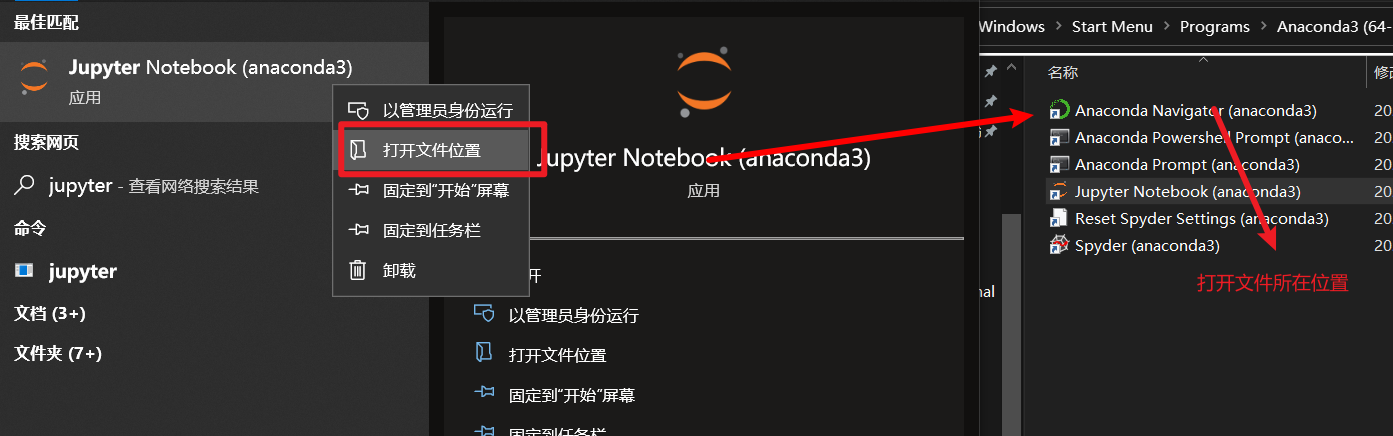
于是顺藤摸瓜一路找到文件夹。
二、正式开始
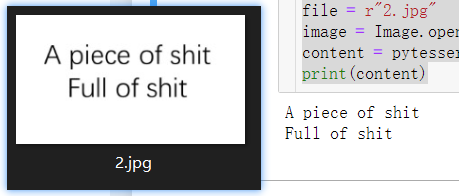
1、最基本的识别-从读图开始
基本思路
- 引入库 PIL,pytesseract
- 读取图片,Image.open(file)
- 内容分析pytesseract.image_to_string(image,lang=’ ')
- 打印
源代码如下
from PIL import Image
import pytesseract
file = r"D:\pythonAds2021\text_rec\2.jpg"
image = Image.open(file)
content = pytesseract.image_to_string(image, lang='eng')
print(content)
2、提取字幕
import pytesseract
import cv2
import numpy as np
from scipy import stats
import os
import matplotlib.pyplot as plt
os.chdir('D:\pythonAds2021')
读取视频的各个帧,将有字幕的图片片段提取出来,并以灰度图显示。
if __name__ == '__main__':
path = "a.mp4"
print(path)
cap = cv2.VideoCapture(path)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(frame_count)
i=0
while i<frame_count:
cap.set(cv2.CAP_PROP_POS_FRAMES, i)
_, frame = cap.read(i)
if i==48:
cv2.imwrite('20210701.jpg',frame)
shape = frame.shape
#调整字幕显示的区间
img=frame[550:600, 0:1070]
plt.imshow(img)
plt.axis("off")
plt.show()
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图
#cv2.imshow("Frame-2:Gray", img) #显示灰度图
_, img= cv2.threshold(img, 220, 255, cv2.THRESH_BINARY) # 图像,阈值,映射的最大值,使用什么算法一般为cv2.thresh_binary
#cv2.imshow("Frame-3:Binary", img) #显示灰度图
用Tesseract-OCR对截取出的字幕图片进行分析,按每秒24帧计算,间隔2.5秒截取一次,提取字幕。
#tessdata_dir_config = '--tessdata-dir "D:\\Tesseract-OCR\\tessdata" --psm 7 -c preserve_interword_spaces=1'
#设置中文字体
word = pytesseract.image_to_string(img,
lang='chi_sim',
config=' --psm 7 -c preserve_interword_spaces=1')
#config=tessdata_dir_config)
print(word)
#设置间隔时间
i=i+24*2.5
if cv2.waitKey(10) & 0xff == ord("q"):
break
cap.release()
cv2.destroyAllWindows()