基于XDMA 的PCIE读写DDR
概述:
想实现基于FPGA的PCIe通信,查阅互联网各种转载…基本都是对PCIe的描述,所以想写一下基于XDMA的PCIe通信的实现(PCIe结构仅做简单的描述(笔记),了解详细结构移至互联网)。
实现功能:PC通过PCIE读写DDR,同时用户通过逻辑代码可以读取被写入DDR内的数据(我是通过VIO实现DDR任意地址,任意数据大小的读取。)。
实践实践!!!
说明:
参考文档:
PCI Express Base Specification Revision 3.0
PCI Express Base Specification Revision 5.0
pg195-pcie-dma
PCI Express体系结构导读
源码下载:基于XDMA 的PCIE读写DDR Vivado工程
环境:Vivado2019.2。
参考博客:基于Xilinx XDMA 的PCIE通信
先看一下这篇博客干了什么
PC通过PCIE写入DDR4KByte个数据。
FPGA端通过VIO实现从DDR任意地址,任意地址大小数据的读取。
1.PCIe简介
PCI-Express(peripheral component interconnect express)是一种高速串行计算机扩展总线标准。PCIE属于高速串行点对点双通道高带宽传输,所连接的设备分配独享通道带宽,不共享总线带宽。PCIE设备通过称为互连或链路的逻辑连接进行通信。链路是两个PCI Express端口之间的点对点通信通道,允许它们发送和接收普通PCI请求和中断。PCIE使用共享并行总线架构,其中PCI主机和所有设备共享一组通用的地址,数据和控制线。

结构由互连一组组件的点对点链路组成,结构拓扑示例如上图所示。上图显示了称为层次结构的单个结构实例,由一个根联合体(RC)、多个端点(I/O设备)、一个交换机和一个PCI Express to PCI/PCI-X桥组成,所有这些都通过PCI Express链接互连。
1.1 PCIe和PCI之间的区别
| PCI | PCIe | |
|---|---|---|
| 速度上 | PCI的工作频率分为33MHz和66MHz,最大吞吐率 266MB/s | PCIe 1.0 x1 的吞吐率达到了250MB/s |
| 传输方式上 | PCI 是并行数据传输,一次传输4字节/8字节,半双工 | PCIe是串行数据传输,全双工 |
| 硬件上 | 传输PCI信号的是普通电平传输 | PCIe信号的是差分电平 |
| 链路上 | PCI是总线的连接方式 | PCIe是点对点的连接方式 |
1.2 PCIe速度以及不同Gen的编码方式
一代更比一代快。
| X1 | X2 | X4 | X8 | X16 | |
|---|---|---|---|---|---|
| PCIe 1.0 | 250MB/s | 500MB/s | 1GB/s | 2GB/s | 4GB/s |
| PCIe 2.0 | 500MB/s | 1GB/s | 2GB/s | 4GB/s | 8GB/s |
| PCIe 3.0 | 1 GB/s | 2 GB/s | 4GB/s | 8GB/s | 16GB/s |
PCIe编码:
PCIe 1.0和2.0采用了8b/10b编码方式,PCIe 3.0和4.0采用128b/130b编码。
| PCIEe版本 | 编码 | 时钟 | 带宽(X1) | 每时钟数据(bit) | 说明 |
|---|---|---|---|---|---|
| PCIe 1.0 | 8b/10b | 2.5GHz | 250MB/s | 1 | 2500/10=25MB/s |
| PCIe 2.0 | 8b/10b | 5GHz | 500MB/s | 1 | 5000/10=500MB/s |
| PCIe 3.0 | 128b/130b | 8GHz | 1GB/s | 1 | ( 8000/130 ) x ( 128/8 ) MB/s= 984 MB/s |
| PCIe 4.0 | 128b/130b | 16GHz | 2GB/s | 1 | ( 16000/130 ) x ( 128/8 ) MB/s= 1969MB/s |
1.3 PCIe端口描述-金手指
金手指分为Side B和Side A(详细引脚对应下面端口描述),方向如下所示:
Side B

Side A

PCIe端口:

1.4 PCIe传输模型
PCIe总线接口,采用分层实现的,事务层(Transaction Layer),数据链路层(Data Link Layer)和物理层(Physical Layer)。

事务层的主要职责是创建(发送)或者解析(接收)TLP (Transaction Layer packet),流量控制,QoS,事务排序等。
数据链路层的主要职责是创建(发送)或者解析(接收)DLLP(Data Link Layer packet),Ack/Nak协议(链路层检错和纠错),流控,电源管理等。
物理层的主要职责是处理所有的Packet数据物理传输,发送端数据分发到各个Lane传输(stripe),接收端把各个Lane上的数据汇总起来(De-stripe),每个Lane上加扰(Scramble,目的是让0和1分布均匀,去除信道的电磁干扰EMI)去扰(De-scramble),以及8/10或者128/130编码解码,等等。
PCIe传输的数据从上到下,都是以packet的形式传输的,每个packet都是有其固定的格式的。传输模型如下所示(数据经过每一层的数据格式):
TX端(生成数据包过程):

RX端(解包过程):

整体传输过程简易描述如下:

数据包传输详细流程如下:

在PCIe数据传输的过程中数据都是以Packet的形式传输,就如以下的传输中,每个Endpoint都需要实现这三层,每个Switch的每个Port也是需要实现这三层。

1.5 Posted TLP和Non-Posted TLP
假设某个设备要对另一个设备进行读取数据的操作,首先这个设备需要向另一个设备发送一个Request,然后另一个设备通过Completion Packet返回数据或者错误信息。在PCIe Spec中,规定了四种类型的请求(Request):
Memory、IO、Configuration和Messages。其中,前三种都是从PCI/PCI-X总线中继承过来的,第四种Messages是PCIe新增加的类型。
| Request Type | Non-Posted or Posted |
|---|---|
| Memory Read | Non-Posted |
| Memory Write | Posted |
| Memory Read Lock | Non-Posted |
| IO Read | Non-Posted |
| IO Write | Non-Posted |
| Configuration Read (Type 0 and Type 1) | Non-Posted |
| Configuration Write (Type 0 and Type 1) | Non-Posted |
| Message | Posted |
Posted TLP:Requester的请求并不需要Completer通过发送包含Completion的包进行应答,当然也就不需要进行等待了。
Non-Posted TLP:Requester发送了一个包含Request的包之后,必须要得到一个包含Completion的包的应答,这次传输才算结束,否则会进行等待。
很显然,Posted类型的操作对总线的利用率(效率)要远高于Non-Posted型。
PCIe的TLP包共有一下几种类型:

Non-Posted TLP传输示例:
如下图Endpoint向System Memory发送读请求(Read request)。Endpoint的读请求通过了两个Switch,然后到达其目标Root节点。Root对读请求的包进行解码后,并识别出操作地址,然后锁存数据,并将数据发送至Endpoint,即包含数据的Completion包,ClpD。

Posted TLP传输示例:
PCIe中的Memory写操作都是Posted的,因此Requester并不需要来自Completer的Completion。因此没有返回Completion,所以当发生错误时,Requester也不会知道。但是,此时Completer会将错误记录到日志(Log),然后向Root发送包含错误信息的Message。

1.6 配置和地址空间
Base Address Register:基址地址寄存器,PCIE设备是有自己独立的一套内部空间,不仅仅是配置空间,包括每个设备提供哪些I/O地址,memory地址,而BAR就是用来表征这些地址空间的。

对于Switch(Type1)有2个不同的地址空间。对于Endpoint(Type0)来说,最多可以拥有6个不同的地址空间。但是实际应用中基本上不会用到6个,通常1~3个BAR比较常见。如果某个设备的BAR没有被全部使用,则对应的BAR应被硬件全被设置为0,并且告知软件这些BAR是不可以操作的。对于被使用的BAR来说,其部分低比特位是不可以被软件操作的,只有其高比特位才可以被软件操作。而这些不可操作的低比特决定了当前BAR支持的操作类型和可申请的地址空间的大小。一旦BAR的值确定了(Have been programmed),其指定范围内的当前设备中的内部寄存器(或内部存储空间)就可以被访问了。当该设备确认某一个请求(Request)中的地址在自己的BAR的范围内,便会接受这请求。
2.基于XDMA的PCIe读写DDR
2.1设计描述
首先PC安装Xilinx提供的XDMA驱动,通过CMD命令行进行DDR的读写操作,以及寄存器的读写,同时用户通过逻辑代码可以读取写入DDR的数据(时间有限,用户通过逻辑往DDR写再传输到PC还没写,后期需要再写吧,其实和PC到DDR再通过逻辑读出DDR数据原理一样的)。
设计展示:
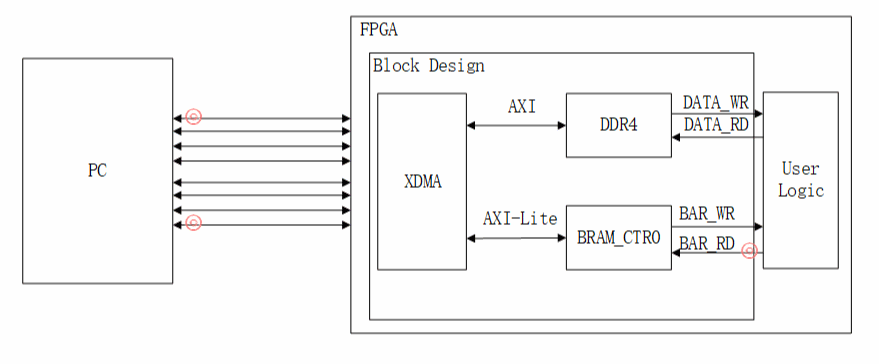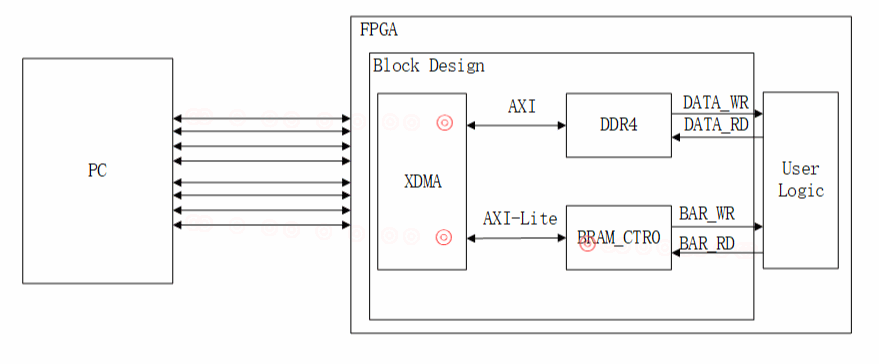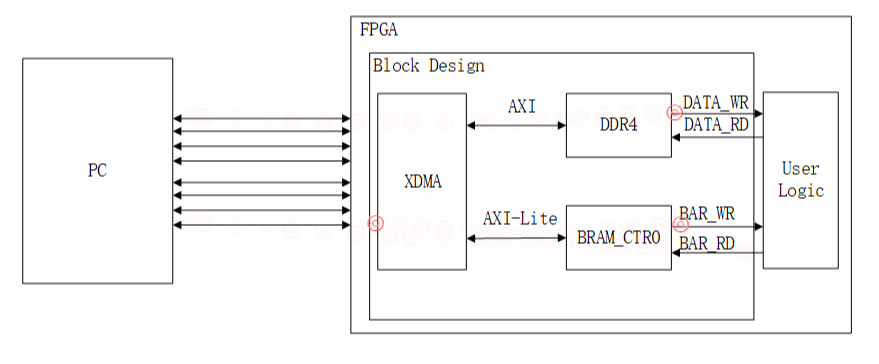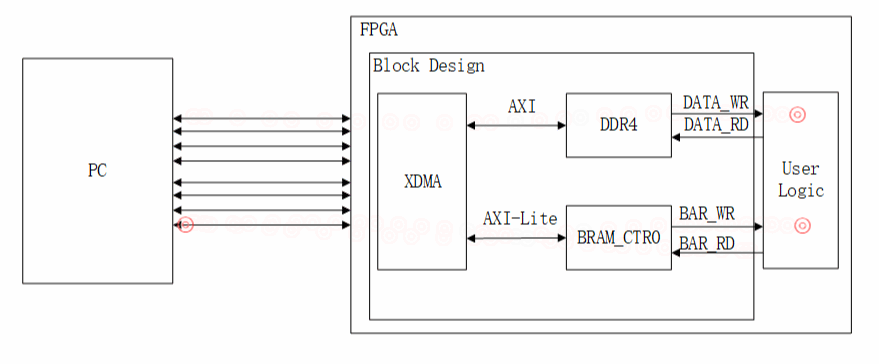
AXI4:用来数据传输。
AXI4-Lite:用来实现PCIe BAR地址到AXI-Lite寄存器地址的映射。
功能描述: (先通过功能了解设计,最后有功能展示)
读写DDR:
1、PC通过CMD执行以下命令,将 pc2fpga_file.bin 文件下的4096Byte写入FPGA:
xdma_rw.exe h2c_0 write 0x0000000 -b -f pc2fpga_file.bin -l 4096
2、PC通过CMD执行以下命令,从FPGA读取4096Byte写入到PC的 fpga2pc_file.bin 文件里:
xdma_rw.exe c2h_0 read 0x0000000 -b -f fpga2pc_file.bin -l 4096
3、通过逻辑代码实现PC写入DDR数据的读取
PC → DDR → FPGA
我是通过VIO实现DDR任意地址,任意数据大小的读取。
通过BAR访问寄存器:
1、PC通过CMD执行以下命令,通过PCIe BAR空间将4Byte数据映射到AXI_Lite寄存器:
xdma_rw.exe control write 0x08 -l 4 0xaa 0xbb 0xcc 0xdd
2、PC通过CMD执行以下命令,PCIe BAR空间访问AXI_Lite寄存器读取1Byte的数据:
xdma_rw.exe user read 0x08 -l 1
2.2 XDMA概述
XIlinx提供DMASubsystem for PCIExpressIP是一个高性能,可配置的适用于PCIe2.0、PCIe3.0的SG模式的DMA,提供用户可选择的AXI4接口或者AXI-Stream接口。XDMA是SGDMA,并非Block DMA,SG模式下,主机会把要传输的数据组成链表的形式,然后将链表首地址通过BAR传送给XDMA,XDMA会根据链表结构首地址依次完成链表所指定的传输任务。
该设计主要利用AXI4接口进行数据传输,AXI4-Lite接口进行BAR地空间的访问,通过BAR访问(读/写寄存器)。

AXI4:用来数据传输。
AXI4-Lite-Master:主机可以使用该接口向用户逻辑产生32位读和写请求(读写用户逻辑寄存器),用来实现PCIe BAR地址到AXI-Lite寄存器地址的映射。
AXI4-Lite-Slave:用户逻辑只是在该接口上控制对DMA控制器内部寄存器的32位读取或写入,不能通过此接口访问PCIE集成模块寄存器。该接口不向主机生成请求(不会映射到BAR)。
2.3 Block Design 设计
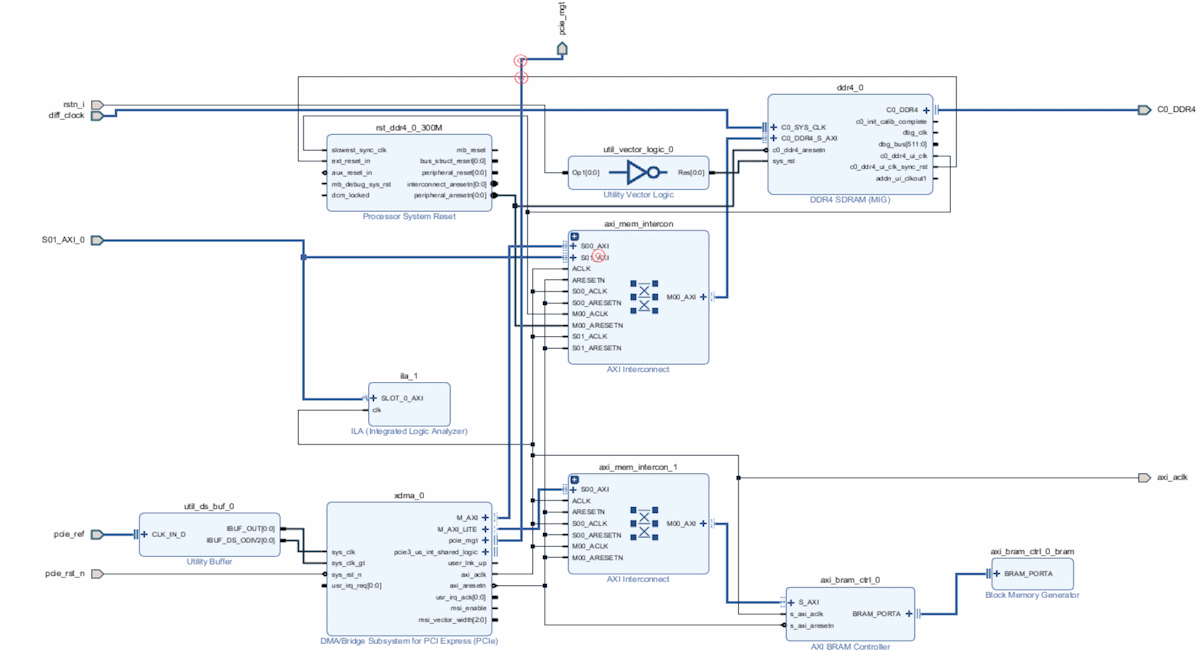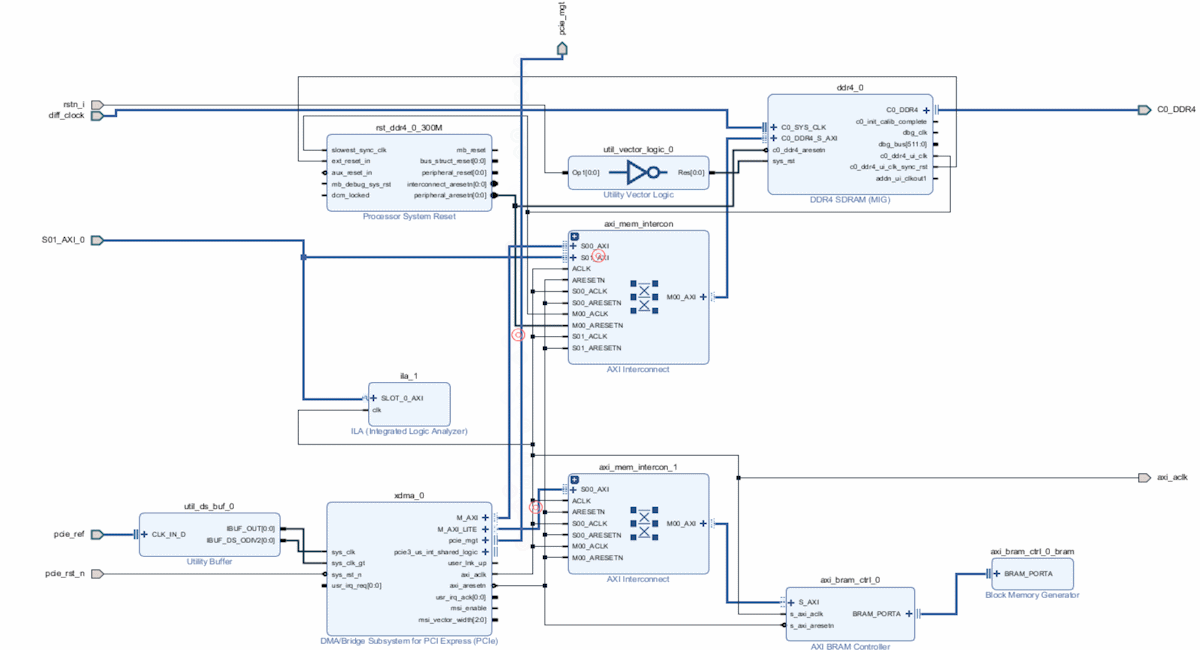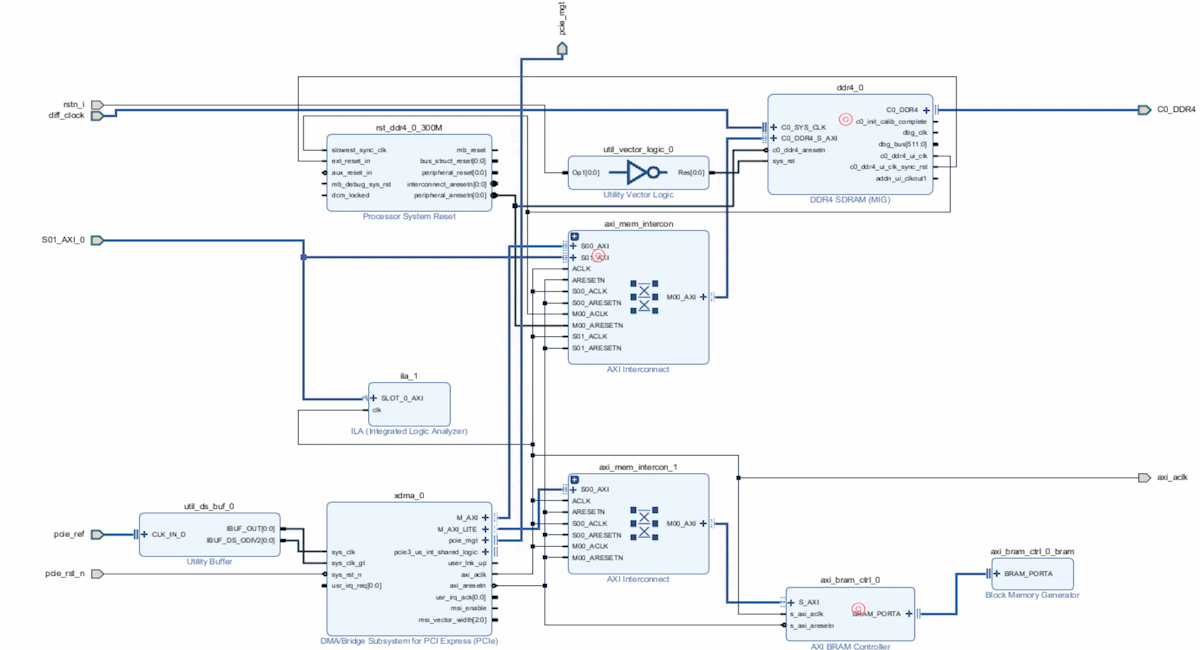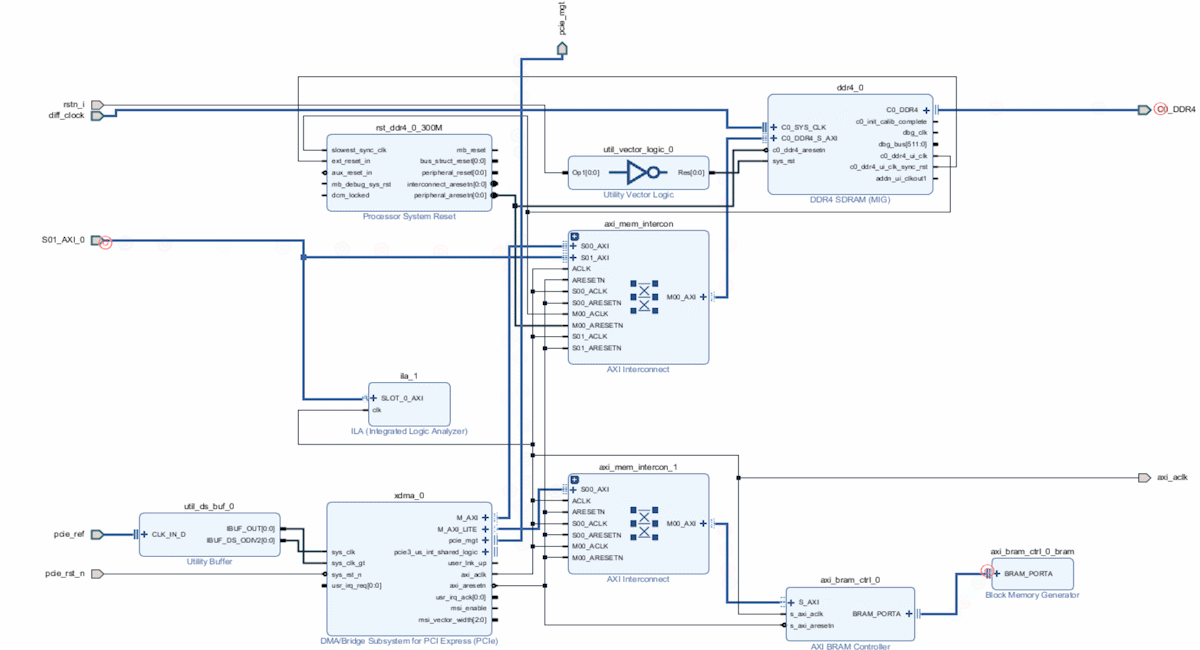
先来一个设计全貌:

下面说一下几个重要的配置:
XDMA IP设置:(根据自己的板子设置)
Lane Width:X8。
Max Link Speed:选择8.0GT/s 即PCIE3.0。
Reference Clock :100MHZ,参考时钟 100M。
DMA Interface Option:接口选择 AXI4 接口。
AXI Data Width:256bit,即 AXI4 数据总线宽度为256bit。
AXI Clock :250M,即AXI4 接口时钟为 250MHZ。
(8×8=64G,250M×256=64G,自己意会✌)

PCIe ID配置

PCIE BAR 配置
首先使能 PCIE to AXI Lite Master Interface ,这样可以在主机一侧通过PCIE 来访问用户逻辑侧寄存器或者其他 AXI4-Lite 总线设备映射空间选择 1M,当然用户也可以根据实际需要来自定义大小。
PCIE to AXI Translation:通常情况下,主机侧PCIE BAR 地址与用户逻辑侧地址是不一样的, 这个设置就是进行BAR 地址到AXI 地址的转换,比如主机一侧 BAR 地址为0,IP 里面转换设置为 0x80000000, 则主机访问 BAR 地址 0 转换到AXI LIte 总线地址就是0x80000000。

PCIE 中断设置
User Interrupts:用户中断,XDMA 提供16 条中断线给用户逻辑,这里面可以配置使用几条中断线。
Legacy Interrupt:XDMA 支持 Legacy 中断
选择 MSI 中断

配置DMA 相关内容
Number of DMA Read Channel(H2C)和Number of DMA Write Channel(C2H)通道数,对于PCIE3.0 来说最大 只能选择 4,也就是 XDMA 可以提供最多两个独立的写通道和两个独立的读通道,独立的通道对于实际应用中 有很大的作用,在带宽允许的前提前,一个PCIE 可以实现多种不同的传输功能,并且互不影响。
Number of Request IDs for Read (Write)channel :这个是每个通道设置允许最大的 outstanding 数量。

添加DDR连接至M_AXI接口,添加一个Bram连接至M_AXI_LITE口,添加S01_AXI_0(双击AXI Interconntct,增加Slave接口并外引用于用户逻辑代码访问)。
BD全貌:
接口描述:
M_AXI:通过AXI Interconntct互联模块连接DDR4。
M_AXI_LITE:通过AXI Interconntct互联模块连接BRAM。
S01_AXI_0:引出接口,用于用户逻辑访问AXI Interconntct进行DDR的读写。
pcie_ref:pcie参考时钟。
pcie_rst_:pcie复位信号。
axi_clk:axi时钟,引出为了BRAM的读写操作。
pcie_mgt:PCIe接口。
注意事项:
①axi_clk端口可能右键点击无法外引,可以新建一个output端口,再和axi_clk端口相连接即可。
②S01_AXI_0双击设置属性(不设置可能导致时钟不匹配):因为现在我只想去读DDR的数据,所以READ ONLY,这样例化就会少一些接口,避免不必要的错误,根据功能自己设置。

Block Design生成以下的RTL端口(用户新建TOP对其调用即可PC控制DDR读写、以及用户通过逻辑访问DDR):
//DDR
input diff_clock_clk_n;
input diff_clock_clk_p;
input rstn_i;
output C0_DDR4_act_n;
output [16:0]C0_DDR4_adr;
output [1:0]C0_DDR4_ba;
output [0:0]C0_DDR4_bg;
output [0:0]C0_DDR4_ck_c;
output [0:0]C0_DDR4_ck_t;
output [0:0]C0_DDR4_cke;
output [0:0]C0_DDR4_cs_n;
inout [7:0]C0_DDR4_dm_n;
inout [63:0]C0_DDR4_dq;
inout [7:0]C0_DDR4_dqs_c;
inout [7:0]C0_DDR4_dqs_t;
output [0:0]C0_DDR4_odt;
output C0_DDR4_reset_n;
//AXI
input [63:0]S01_AXI_0_araddr;//AXI读地址通道
input [1:0]S01_AXI_0_arburst;
input [3:0]S01_AXI_0_arcache;
input [0:0]S01_AXI_0_arid;
input [7:0]S01_AXI_0_arlen;
input [0:0]S01_AXI_0_arlock;
input [2:0]S01_AXI_0_arprot;
input [3:0]S01_AXI_0_arqos;
output S01_AXI_0_arready;
input [3:0]S01_AXI_0_arregion;
input [2:0]S01_AXI_0_arsize;
input S01_AXI_0_arvalid;
output S01_AXI_0_awready; //
output [1:0]S01_AXI_0_bresp; //响应
output S01_AXI_0_bvalid;
output [255:0]S01_AXI_0_rdata; //AXI写地址通道
output [0:0]S01_AXI_0_rid;
output S01_AXI_0_rlast;
input S01_AXI_0_rready;
output [1:0]S01_AXI_0_rresp;
output S01_AXI_0_rvalid;
output S01_AXI_0_wready; //
output axi_aclk; //AXI时钟
//PCIE
input [7:0]pcie_mgt_rxn;
input [7:0]pcie_mgt_rxp;
output [7:0]pcie_mgt_txn;
output [7:0]pcie_mgt_txp;
input [0:0]pcie_ref_clk_n;
input [0:0]pcie_ref_clk_p;
input pcie_rst_n;
我们通过编写AXI_Master代码,可以访问AXI Interconntct,间接的读取到DDR的数据。
2.4 AXI_Master代码
AXI_Master代码:
微信:Crazzy_M
顶层设计:

引入VIO便于DDR任意地址和数据大小的读写
vio_0 vio (
.clk(axi_aclk), // input wire clk
.probe_out0(readrst_n), // output wire [0 : 0] probe_out0
.probe_out1(user_raddr), // output wire [31 : 0] probe_out1
.probe_out2(user_rsize), // output wire [31 : 0] probe_out2
.probe_out3(user_rexe) // output wire [0 : 0] probe_out3
);
user_raddr:通过VIO写入要读取DDR数据的地址。
user_rsize:通过VIO写入要读取DDR数据的大小(单位为Byte)。
user_rexe:点击一次,执行一次读操作。
效果如下所示:
无时序违例:

3. AXI接口描述
Block Design引出S01_AXI_0以便用户访问DDR中的数据,那么我们就得要熟悉AXI协议是工作的。
3.1 AXI读写架构
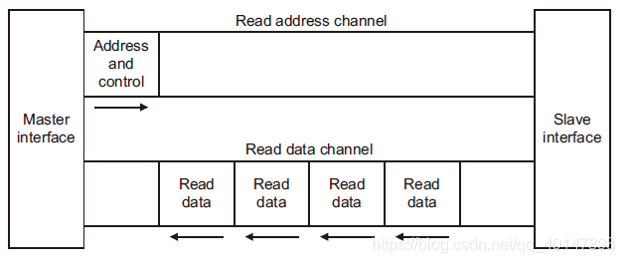
读地址通道:
每个读事务都有自己的地址通道。适当的地址通道携带通信所需的所有地址和控制信息。AXI协议支持以下机制:
可变的突发长度,每个突发长度从1-16个数据。
(连续传输的周期数就是突发长度。)
突发传送的大小为8-1024bit
…
读取数据通道:
读取数据通道可同时传输读取数据和来自设备从设备到主设备的响应信息。
数据总线,可以是8、16、32、64、128、256、512或1024bit。
一个指示读取事务完成状态的读取响应
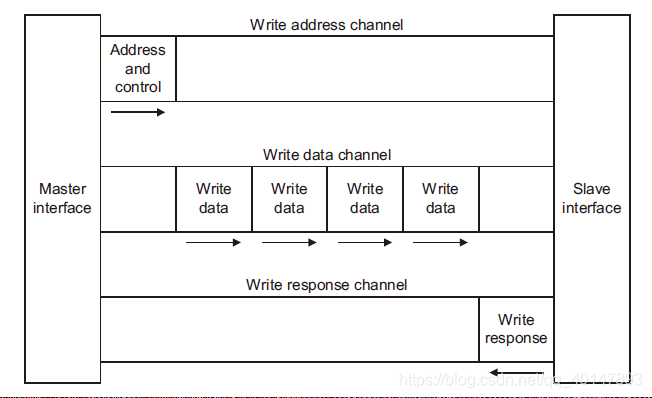
写地址通道:
每个写事务都有自己的地址通道。适当的地址通道携带通信所需的所有地址和控制信息。AXI协议支持以下机制:
可变的突发长度,每个突发长度从1-16个数据。
(连续传输的周期数就是突发长度。)
突发传送的大小为8-1024bit
…
写数据通道:
将写数据从主机传送到从机
数据总线,可以是8、16、32、64、128、256、512或1024bit。
每八个数据位的一个字节通道选通脉冲,指示数据总线的哪个字节有效。
写响应通道:
写通道响应为从设备提供了一种响应事务的方法。所有写事务使用完成信令。
完成信号对于每个脉冲串仅发生一次,而不是针对其中的每个单独的数据传输发生一次突变。
3.2 AXI信号描述
| AXI主机读地址通道 | I/O | 初始值 | 说明 |
|---|---|---|---|
| m_axi_araddr(C_M_AXI_ADDR_WIDTH-1: 0) | O | 0 | AXI主突发读地址通道地址总线。请求的读取事务的起始地址。 |
| m_axi_arburst(1:0) | O | 0 | AXI主突发读地址通道突发类型。指示突发类型。00b =固定-不支持。01b = INCR -递增地址。10b = WRAP -不支持。11b =保留。 |
| m_axi_arcache(3:0) | O | 0011b | AXI主突发读地址通道缓存。这始终由0011b的恒定输出驱动 |
| m_axi_arlen(7:0) | O | 0 | AXI主机突发读取地址通道突发长度。此限定符指定请求的AXI读取事务长度 |
| m_axi_arprot(2:0) | O | 0 | AXI主机突发读地址通道保护。这始终由000b的恒定输出驱动。 |
| m_axi_arready | I | 0 | AXI主机突发读取地址通道读取地址就绪。指示目标已准备好接受读取地址。1 =目标读取接受地址。0 =目标未准备好接受地址。 |
| m_axi_arsize(2:0) | O | 0 | AXI主突发读取地址通道突发大小。指示每个突发数据节拍的数据事务宽度。000b =不支持。001b =不支持。010b = 4字节(32位宽突发)。011b = 8字节(64位宽突发)。100b = 16字节(128位宽突发)。101b =(256位宽突发)。。110b =不支持。111b =不支持。 |
| m_axi_arvalid | O | 0 | AXI主机突发读地址通道读地址有效。指示m_axi_araddr是否有效。1 =读取地址有效。0 =读取地址无效。 |
| AX4主机写地址通道 | I/O | 初始值 | 说明 |
|---|---|---|---|
| m_axi_awaddr(C_M_AXI_ADDR_WIDTH-1: 0) | O | 0 | AXI主突发写地址通道地址总线。请求的写事务的起始地址。 |
| m_axi_awburst(1:0) | O | 0 | AXI主突发写地址通道突发类型。指示突发类型。 00b =固定-不支持。01b = INCR -递增地址。 10b = WRAP -不支持。11b =保留。 |
| m_axi_awcache(3:0) | O | 0011 | AXI主机突发写地址通道缓存。这始终由0011b的恒定输出驱动。 |
| m_axi_awlen(7:0) | O | 0 | AXI主机突发写地址通道突发长度。该限定符指定请求的AXI写事务长度 |
| m_axi_awprot(2:0) | O | 000b | AXI主机突发写地址通道保护。这始终由000b的恒定输出驱动。 |
| m_axi_awready | I | AXI主机突发写地址通道写地址就绪。指示目标已准备好接受写地址。 1 =目标准备接受地址。0 =目标未准备好接受地址。 | |
| m_axi_awsize(2:0) | O | 0 | AXI主突发写地址通道突发大小。指示每个突发数据节拍的数据事务宽度。 000b =不支持。001b =不支持。 010b = 4字节(32位宽突发)。011b = 8字节(64位宽突发)。100b = 16字节(128位宽突发)。101b =不支持。 110b =不支持。111b =不支持。 |
| m_axi_awvalid | O | 0 | AXI主机突发写地址通道写地址有效。指示m_axi_awaddr是否有效。1 =写地址有效。0 =写地址无效。 |
| AX4主机写响应通道 | I/O | 初始值 | 说明 |
|---|---|---|---|
| m_axi_bready | O | 0 | AXI主机突发写入响应通道就绪。指示源已准备好接收响应。 1:准备接收响应 0:未准备就绪接收响应 |
| m_axi_bresp(1:0) | I | AXI主机突发写入响应通道响应。指示写事务的结果。 00b =正常-正常访问已成功。01b = exoky-不支持。 10b = SLVERR -从属事务返回错误。 11b = DECERR -解码错误,事务目标未映射地址。 | |
| m_axi_bvalid | I | AXI主机突发写入响应通道响应有效。指示响应m_axi_bresp有效。 1 =响应有效。0 =响应无效。 |
| AX4主机读取数据通道 | I/O | 初始值 | 说明 |
|---|---|---|---|
| m_axi_rdata(C_M_AXI_DATA_WIDTH-1: 0) | I | AXI主突发读取数据通道读取数据。请求的读取事务的读取数据总线。 | |
| m_axi_rlast | I | AXI主机突发读取数据通道最后。指示突发事务的最后一个数据节拍。 0 =不是最后一个数据节拍。 1 = 数据最后一个节拍 | |
| m_axi_rready | O | 0 | AXI主突发读取数据通道就绪。表示读通道已准备好接受读数据。1 =准备好了。0 =未准备好。 |
| m_axi_rresp(1:0) | I | AXI主机突发读取数据通道响应。指示读取事务的结果。 00b =正常-正常访问已成功。01b = exoky-不支持。 10b = SLVERR -从属事务返回错误。 11b = DECERR -解码错误,事务目标未映射地址。 | |
| m_axi_rvalid | I | AXI主突发读取数据通道数据有效。指示m_axi_rdata有效。 1 =有效读取数据。0 =无效的读取数据。 |
| AX4主机写数据通道 | I/O | 初始值 | 说明 |
|---|---|---|---|
| m_axi_wdata(C_M_AXI_DATA_WIDTH-1: 0) | O | 0 | AXI主突发写数据通道写数据总线。 |
| m_axi_wlast | O | 0 | AXI主机突发写入数据通道最后。指示突发事务的最后一个数据节拍。 1:最后一个数据节拍 0:不是最后一个数据节拍 |
| m_axi_wready | I | AXI主机突发写入数据通道就绪。指示SG写数据通道目标从机已准备好接受写数据。 1 =目标从机准备就绪。 0 =目标从机未准备好。 | |
| m_axi_wstrb(C_M_AXI_DATA_WIDTH/8 - 1: 0) | O | 0 | AXI主突发写数据通道写选通总线。 |
| m_axi_wvalid | O | 0 | AXI主机突发写入数据通道数据有效。指示写数据通道在总线上有有效的数据节拍。 1 =有效写入数据。 0 =无效写入数据。 |
3.3 AXI握手过程
所有五个通道都使用相同的VLAID/READY握手机制来传输和控制信息。这种双向流量控制机制使主机和从机都可以控制数据和信息的移动速率。主机,指示何时有数据或控制信息。从机,产生READY信号,以指示它接收数据或控制信息。传输仅当VALID和READY信号均为高时。
通道握手信号之间的依赖:
为避免出现死锁情况,您必须观察到两者之间存在的依赖关系。
握手信号。
在任何传输中:
●一个AXI组件的VALID信号不得取决于READY信号。
●READY信号可以等待VALID信号的断言。
读取握手依赖关系:
| 读取握手信号 | 发起者 | 说明 |
|---|---|---|
| ARVALID | 主 | 读地址有效。1:读取地址有效、0:读地址无效 |
| RVALID | 从 | 读数据有效。1:读取数据可用、0:读取数据不可用 |
| ARREADY | 从 | 读取地址准备就绪。1:从机地址准备就绪、0:从机地址未准备就绪。 |
| RREADY | 主 | 读取数据就绪。1:主机准备就绪、0:主机为准备就绪。 |
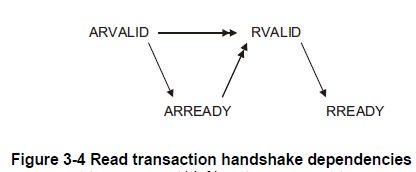
从机可以在声明ARREADY之前等待ARVALID声明
从设备必须等待ARVALID和ARREADY都被声明后才能开始
通过声明RVALID返回读取的数据。
写入握手依赖关系:
| 写入握手信号 | 发起者 | 说明 |
|---|---|---|
| AWVALID | 主 | 写地址有效。表示有效的写地址和控制信息。1:地址可用、0:地址不可用 |
| AWREADY | 从 | 接收地址准备。表明从机已经准备好接收地址信息。1:从机准备就绪、0:从机未准备就绪 |
| WVALID | 主 | 写有效。表明写数据有效。1:写数据可用、0:写数据不可用。 |
| WREADY | 从 | 接收数据准备。1:从机准备就绪、0:从机为准备就绪、 |
| BVALID | 从 | 写入响应有效。1:写响应可用、0:写响应不可用。 |
| BREADY | 主 | 接收响应准备就绪。1:主机准备接收就绪、0:主机未准备接收就绪 |
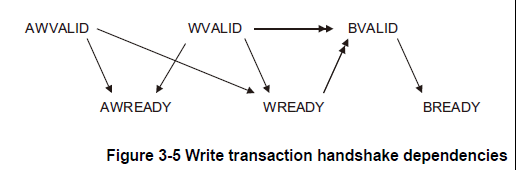
主机不得在等待从机断言AWREADY或WREADY之前断言AWVALID或WVALID
从机可以在声明AWREADY之前等待AWVALID或WVALID或两者
从机可以在声明WREADY之前等待AWVALID或WVALID或两者
从机必须在声明前等待WVALID和WREADY在BVALID断言之前声明。
握手方式:
VALID在READY之前:
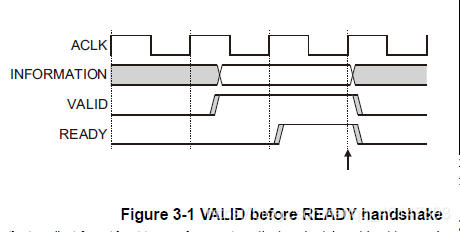
主机放置数据或控制信号,并将VALID信号驱动为高电平。
来自主机的数据或控制信息保持稳定,直到目标驱动READY信号为高电平,表示它接受数据或控制信息,箭头显示何时开始传输。
在声明VALID之前,不允许等待READY声明。一旦VALID被
断言它必须保持断言直到握手发生。
READY在VALID之前:
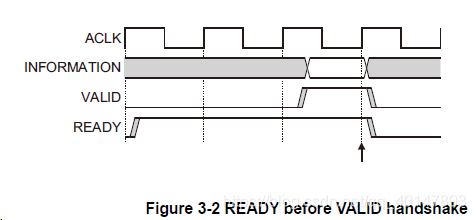
目标驱动器在数据或控制信息被写入之前就驱动READY为高,这表明从机可以在一个接收器中接受数据或控制信息生效后立即循环。允许在声明相应的READY之前等待VALID声明。 如果声明了READY ,则允许在声明VALID之前取消声明READY 。
VALID和READY同时:
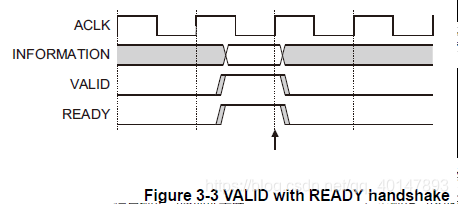
主机和从机恰好在同一周期内指示他们可以传输数据或控制信息。
4. PCIe DMA传输流程以及AXI_Lite寄存器描述
如果选择了AXI内存映射接口,
C2H传输的源地址为AXI地址,目的地址为PCIe地址。
H2C传输的源地址是PCIe,目的地址是AXI地址。
H2C和C2H转移的初始设置:

汉化一下:

以下图中:绿色是应用程序;橙色是驱动;蓝色是硬件。
H2C DMA传输流程:
汉化一下:

在H2C的过程中(PC执行写命令时)通过ila在AXI_Lite口捕捉该过程:



C2H DMA传输流程:

汉化一下:

在C2H的过程中(PC执行读命令时)通过ila在AXI_Lite口捕捉该过程:



上面的寄存器是什么呢?这就涉及到了AXI_Lite口寄存器。
AXI_Lite口寄存器描述:
PCIE到DMA空间的事务被路由到内部配置寄存器总线上。该总线支持32位地址空间和32位读写请求。PCIe寄存器的DMA子系统可以从主机或者AXI Slave接口访问,这些寄存器用于对直接存储器存取进行编程和检查状态。
PCIe到DMA的地址格式:

地址字段描述:

字段 [15:12]:
DMA的目标子模块
4’h0:

4’h1:

4’h2:

4’h3:

4’h4:

4’h5:

4’h6:

4’h8:

字段 [7:0]:
目标内要访问的寄存器的字节地址。位[1:0]必须为0。如下图bit0、bit1均为0。

如上图
AXI_LITE_AWADDR[31:0] = 0x0000_2014
AXI_LITE_WDATA[31:0] = 0x0000_0002
说明:

AXI_LITE_AWADDR :
bit1:bit0 均为0。
bit7:bit0:访问的寄存器的字节地址:0x14。
bit15:bit12:02h,DMA的目标子模块为IRQ Block。
bit31:bit16:Reserved。
上面H2C、C2H流程里面的寄存器应该明白是怎么回事了吧。
具体参考 文档pg195。
5. 功能展示
PC通过PCIe传输数据和配置寄存器后,用户通过逻辑读取DDR的数据:
5.1 DDR数据读写
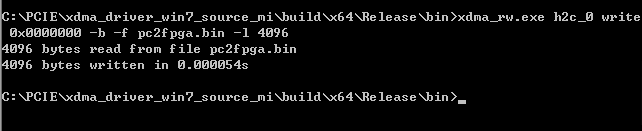
1、PC通过CMD执行以下命令,将 pc2fpga.bin 文件下的4096Byte写入DDR起始地址为0x00000000:
xdma_rw.exe h2c_0 write 0x0000000 -b -f pc2fpga.bin -l 4096
pc2fpga.bin文件内容如下所示:

PC通过CMD执行以下命令(TX):

验证数据是否写入DDR,我们通过逻辑代码进行DDR数据的读取:
从地址0000_0000h读取大小为4096Byte的数据。

观察源文件其实就是斜坡数据。

观察第一个256bit数据为:

最后一个256bit数据为:

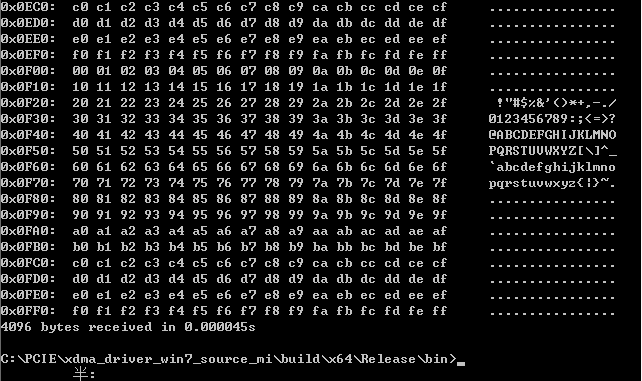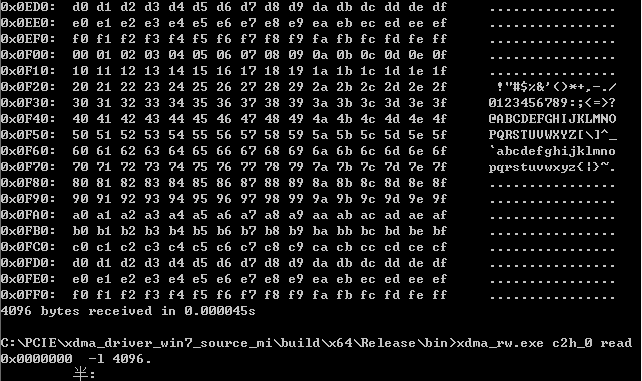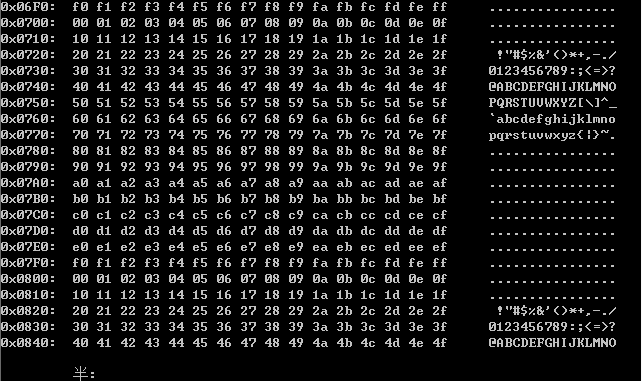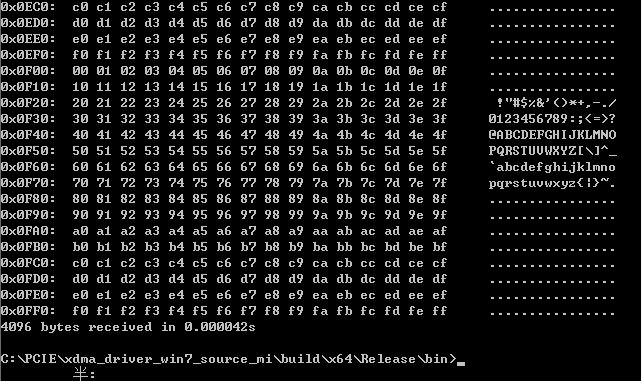
在PC CMD端输入以下指令也读取DDR数据,与用户读取的数据进行对比,无误。
xdma_rw.exe c2h_0 read 0x0000000 -l 4096
CMD读取的数据:

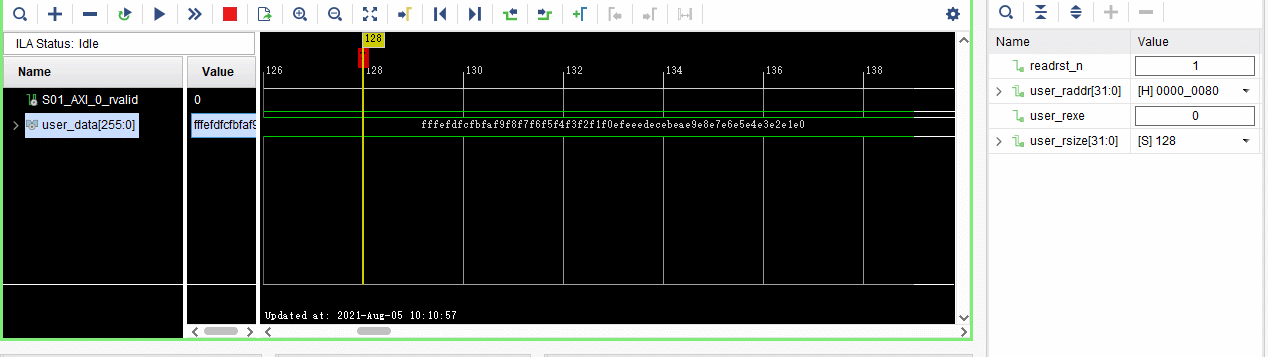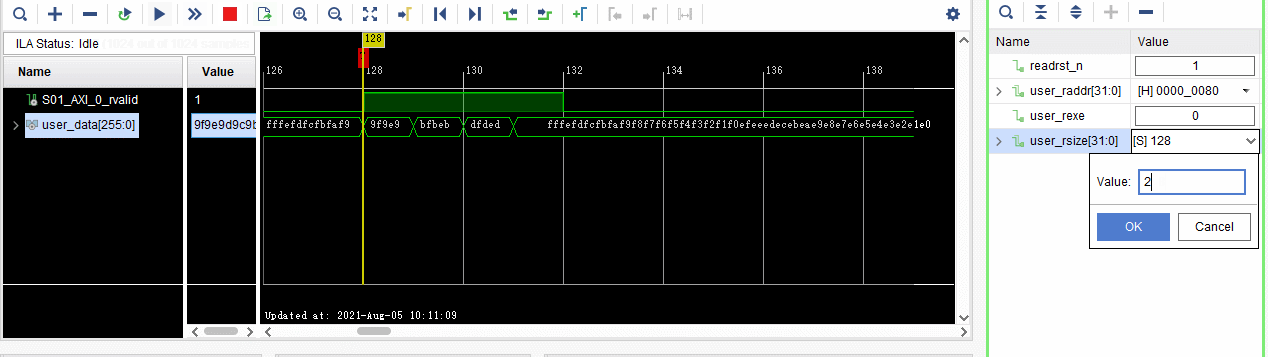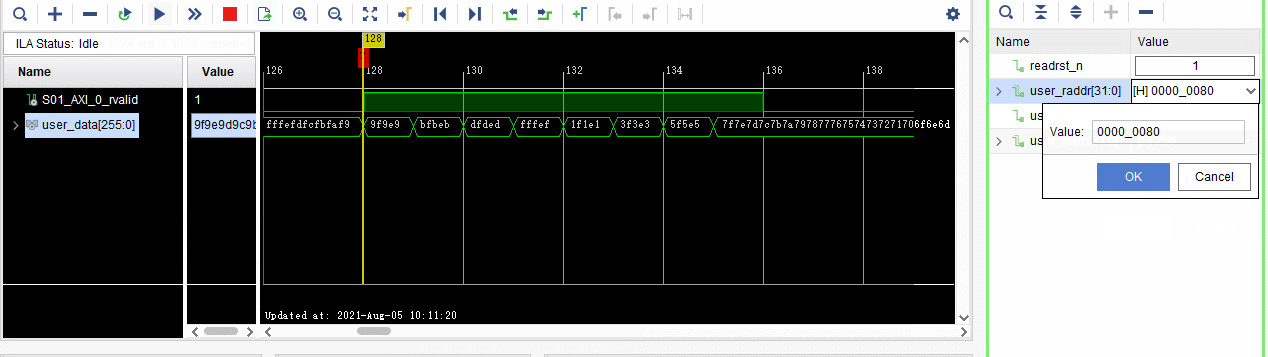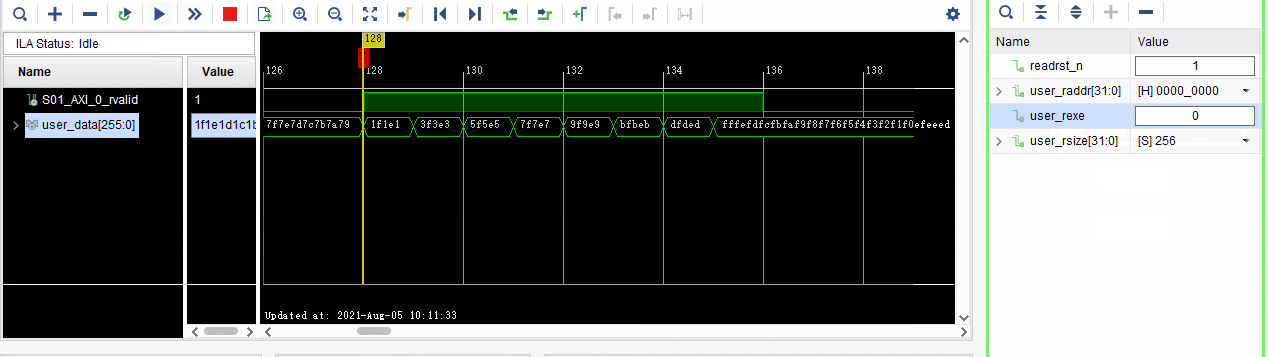
2、通过VIO输入地址和数据大小,进行相应的DDR数据读取。
从地址0000_0080读取64Byte的数据,即512bit数据。

。
对比PC端读取DDR0000_0080读取64Byte的数据,一样的✌

3、FPGA端通过VIO实现从DDR任意地址,任意地址大小数据的读取。
user_raddr:通过VIO写入要读取DDR数据的地址。
user_rsize:通过VIO写入要读取DDR数据的大小(单位为Byte)。
user_rexe:点击一次,执行一次读操作。
5.2 BAR空间的访问
1、PC通过CMD执行以下命令,通过PCIe BAR空间将4Byte数据映射到AXI_Lite寄存器:
xdma_rw.exe control write 0x08 -l 32 0x00 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 0x09 0x0a 0x0b 0x0c 0x0d 0x0e 0x0f 0x10 0x11 0x12 0x13 0x14 0x15 0x16 0x17 0x18 0x19 0x1a 0x1b 0x1c 0x1d 0x1e 0x1f
PC端 cmd输入(TX):

FPGA接收的数据(RX):

2、PC通过CMD执行以下命令,PCIe BAR空间访问AXI_Lite寄存器读取4Byte的数据:
xdma_rw.exe user read 0x08 -l 4
PC端 cmd输入(RX):

观察接收到FPGA返回的数据为0x08080808.
观察FPGA正在上传的数据(TX):

无误。
★★★如有错误,欢迎指导!!!