文章目录
Scala数据结构的特点
1. Scala的集合基本介绍
Scala 同时支持不可变集合和可变集合,不可变集合可以安全的并发访问。
俩个主要的包:
- scala.collection.immutable
- scala.collection.mutable
Scala 默认采用不可变集合,对于几乎所有的集合类,Scala都同时提供了可变(mutable)和不可变(immutable)的版本。
Scala 的集合有三大类:
- 序列 Seq(有序的, Linear Seq)
- 集 Set
- 映射 Map【key->value】
所有的集合都扩展自 Iterable 特质,在Scala中集合有可变(muatable)和不可变(immutable)俩种类型。
2. 可变集合和不可变集合举例
- 不可变集合:scala不可变集合,就是这个集合本身不能动态变化。(类似Java数组,是不可以动态增长的)
- 可变集合:可变集合,就是这个集合本身可以动态变化的。(比如:ArrayList,是可以动态增长的)
Java中的可变集和不可变集举例:
import java.util.ArrayList;
public class JavaCollection {
public static void main(String[] args) {
//不可变集合类似的Java数组
int[] nums = new int[3];
nums[2] = 11;
nums[2] = 22;
//可变集合举例
ArrayList<String> a1 = new ArrayList<String>();
a1.add("zs");
a1.add("zs2");
System.out.println(a1 + " 地址 " + a1.hashCode()); //内存地址
a1.add("zs3");
System.out.println(a1 + " 地址2 " + a1.hashCode()); //内存地址发生了变化
}
}
[zs, zs2] 地址 242625
[zs, zs2, zs3] 地址2 7642233
Process finished with exit code 0
不可变集合继承层次——览图

对比总结:
- 1.Set、Map是Java 中也有的集合。
- 2.Seq是Java没有的,Scala中的List归属到Seq了,因此Scala中的List和Java不是同一个概念了。
- 3.for循环中的 1 to 3 ,就是IndexedSeq 下的 Vector。
- 4.String也是属于 IndexedSeq。
- 5.经典的数据结构比如 Queue 和 Stack 被归属到 LinearSeq 中。
- 6.Scala中的Map体系有一个SortedMap,说明Scala的Map支持排序。
- 7.IndexedSeq 和 LinearSeq 的区别:IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位。LinearSeq是线性的,即有头尾的概念,这种数据结构一般是通过遍历来查找,它的价值在于应用到一些具体的应用场景(电商网站,大数据推荐系统:最近浏览的10个商品)
可变集合继承层次——览图

对比总结:
- 1.在可变集合中比不可变集合更加丰富。
- 2.在Seq集合中,增加了Buffer集合,常用的有ArrayBuffer和ListBuffer。
- 3.如果涉及到线程安全可以选择使用syn…开头的集合。
- 4.其余的和不可变集合基本相同。
数组-定长数组(声明泛型)
1. 第一种方式定义数组
说明:这里的数组等同于 Java 中的数组,中括号的类型就是数组的类型。
val arr1 = new Array[Int](10)
// 赋值,集合元素采用小括号访问
arr(1) = 7
代码展示:
object 第一种定义数组的方式 {
def main(args: Array[String]): Unit = {
/*
说明:
1. 创建了一个 Array 对象
2. [Int]表示泛型,即该数组中,只能存放Int
3. [Any]表示该数组可以存放任意类型
4. 在没有赋值的情况下,各个元素的值 0
5. arr01(3) = 10 表示修改第4个元素的值
*/
val arr01 = new Array[Int](4) //底层:int[] arr01 = new int[4]
println(arr01.length) //4
println("arr01(0)=" + arr01(0)) // 0
for (i <- arr01) println(i) //数据的遍历
println("----------------------")
arr01(3) = 10
for (i <- arr01) println(i)
}
}
4
arr01(0)=0
0
0
0
0
----------------------
0
0
0
10
Process finished with exit code 0
2. 第二种方式定义数组
说明:在定义数组时直接赋值
//使用 apply 方法创建数组对象
val arr1 = Array(1, 2)
代码演示:
object 第二种定义数组的方式 {
def main(args: Array[String]): Unit = {
/*
说明:
1. 使用的是 object Array 的 apply
2. 直接初始化数组,这是因为你给了 整数 和 "",这个数组的泛型就是 Any
3, 遍历方式一样
*/
var arr02 = Array(1, 3, "xx")
arr02(1) = "xx"
for (i <- arr02) println(i) //遍历
//可以使用传统的遍历方式,使用索引遍历
for (index <- 0 until arr02.length) {
printf("arr02[%d]=%s", index, arr02(index) + "\t")
}
}
}
1
xx
xx
arr02[0]=1 arr02[1]=xx arr02[2]=xx
Process finished with exit code 0
数组-变长数组(声明泛型)
1. 变长数组声明访问
说明:
//定义 声明
val arr2 = ArrayBuffer[Int]()
//追加值 元素
arr2.append(7)
//重新赋值
arr2(0) = 7
代码演示:
import scala.collection.mutable.ArrayBuffer
object 变长数组声明 {
def main(args: Array[String]): Unit = {
//创建 ArrayBuffer
val arr01 = ArrayBuffer[Any](3, 2, 5)
//访问,查询
println("arr01(1) = " + arr01(1))
// 遍历
for (i <- arr01) println(i)
println(arr01.length)
println("arr01.hash" + arr01.hashCode())
//修改【修改值、动态增加】
//使用 append 追加数据,append支持可变参数
//可以理解成java的数组的扩容
arr01.append(90.0, 13)
println("arr01.hash = " + arr01.hashCode())
println("---------------------------------------------")
arr01(1) = 89 //修改值
for (i <- arr01) println(i)
arr01.remove(0) //删除值
for (i <- arr01) println(i)
println("最新的长度:" + arr01.length)
}
}
arr01(1) = 2
3
2
5
3
arr01.hash110266112
arr01.hash = -70025354
---------------------------------------------
3
89
5
90.0
13
89
5
90.0
13
最新的长度:4
Process finished with exit code 0
总结:
- ArrayBuffer 是变长数组,类似 Java 的 ArrayList
- val arr2 = ArrayBuffer[Int]() 也是使用的 apply 方法构建对象
- def append(elems: A*) {appendAll(elems)} 接受的是可变参数
- 每 append 一次,arr底层会重新分配空间,进行扩容,arr2的内存地址会发生改变,成为新的 ArrayBuffer
2. 定长数组与变长数组的转换
说明:
arr1.toBuffer //定长-->变长
arr2.toArray //变长-->定长
注意事项:
- arr2.toArray 返回结果是一个定长数组,arr2本身没有变化
- arr1.toBuffer 返回结果是一个可变数组,arr1本身没有变化
代码演示:
import scala.collection.mutable.ArrayBuffer
object 定长数组与变长数组的转换 {
def main(args: Array[String]): Unit = {
val arr2 = ArrayBuffer[Int]()
arr2.append(1, 2, 3) //追加值
println(arr2)
/*
说明:
1. arr2.toArray 调用 arr2 的方法 toArray
2. 将 ArrayBuffer ---> Array
3. arr2 本身没有任何变化
*/
val newArr = arr2.toArray
println(newArr)
/*
说明:
1. newArr.toBuffer 是把 Array -> ArrayBuffer
2. 底层实现
override def toBuffer[A1 > : A]:mutable.Buffer[A1] = {
val result = new mutable.ArrayBuffer[A1](size)
copyToBuffer(result)
result
}
*/
//3. newArr 本身没有变化
val newArr2 = newArr.toBuffer
newArr2.append(123)
println(newArr2)
}
}
ArrayBuffer(1, 2, 3)
[I@7f63425a
ArrayBuffer(1, 2, 3, 123)
Process finished with exit code 0
3. 多维数组的定义和使用
说明:
//定义
val arr = Array.ofDim[Double](3,4)
//说明:二维数组种有三个一维数组,每个一维数组中有四个元素
//赋值
arr(1)(1) = 11.11
代码演示:
object 多维数组的定义使用 {
def main(args: Array[String]): Unit = {
//创建
val arr = Array.ofDim[Int](3,4)
//遍历
for (i <- arr) {
for (j <- i) print(j + "\t")
}
println()
println(arr(1)(1)) //指定取出
arr(1)(1) = 99 //修改值
for (i <- arr) {
for (j <- i) print(j + "\t")
}
println()
//按照索引进行遍历输出
for (i <- 0 to arr.length-1) {
for (j <- 0 to arr(i).length-1) {
printf("arr[%d][%d]=%d\t", i, j, arr(i)(j))
}
}
println()
}
}
0 0 0 0 0 0 0 0 0 0 0 0
0
0 0 0 0 0 99 0 0 0 0 0 0
arr[0][0]=0 arr[0][1]=0 arr[0][2]=0 arr[0][3]=0 arr[1][0]=0 arr[1][1]=99 arr[1][2]=0 arr[1][3]=0 arr[2][0]=0 arr[2][1]=0 arr[2][2]=0 arr[2][3]=0
Process finished with exit code 0
Scala数组与Java的List相转换
1. Scala数组 转 Java List
代码案例:
object Java的List转Scala数组 {
def main(args: Array[String]): Unit = {
//Scala集合与Java集合互相转换
val arr = ArrayBuffer("1", "2", "3")
import scala.collection.JavaConversions.bufferAsJavaList
//对象 ProcessBuilder,因为,这里使用到了上面的 bufferAsJavaList
val javaArr = new ProcessBuilder(arr) //传值的时候触发隐式转换
//这里的arrList就是Java中的List
val arrList = javaArr.command()
println(arrList) //输出 [1, 2, 3]
}
}
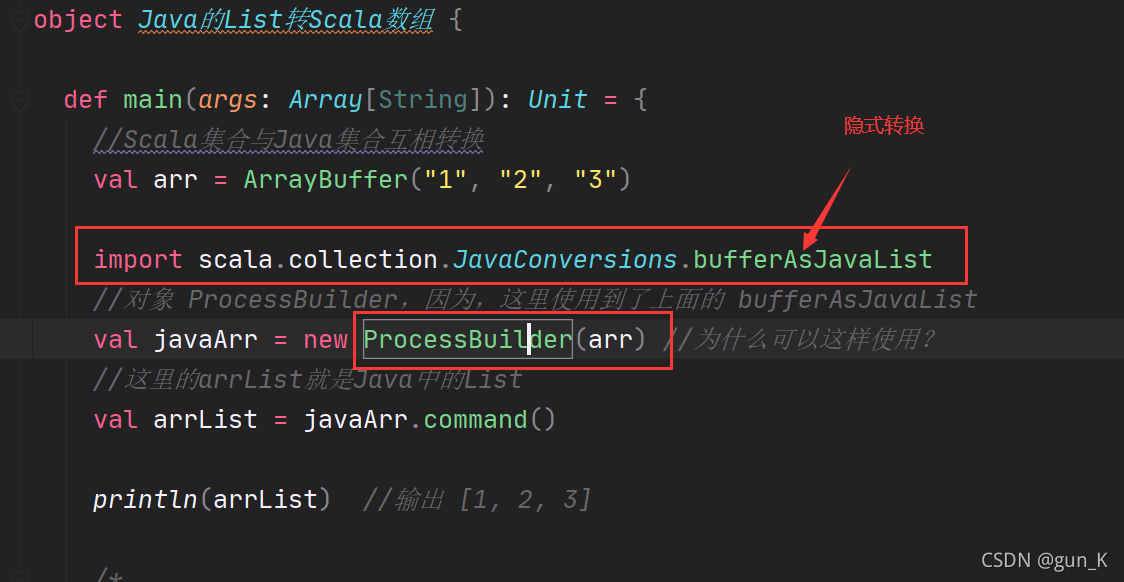


2. Java List 转 Scala 数组
/*
说明:
1. asScalaBuffer是一个隐式函数
2. 源码:
implicit def asScalaBuffer[A](l: ju.List[A]): mutable.Buffer[A] = l match {
case MutableBufferWrapper(wrapped) => wrapped
case _ =>new JListWrapper(l)
}
*/
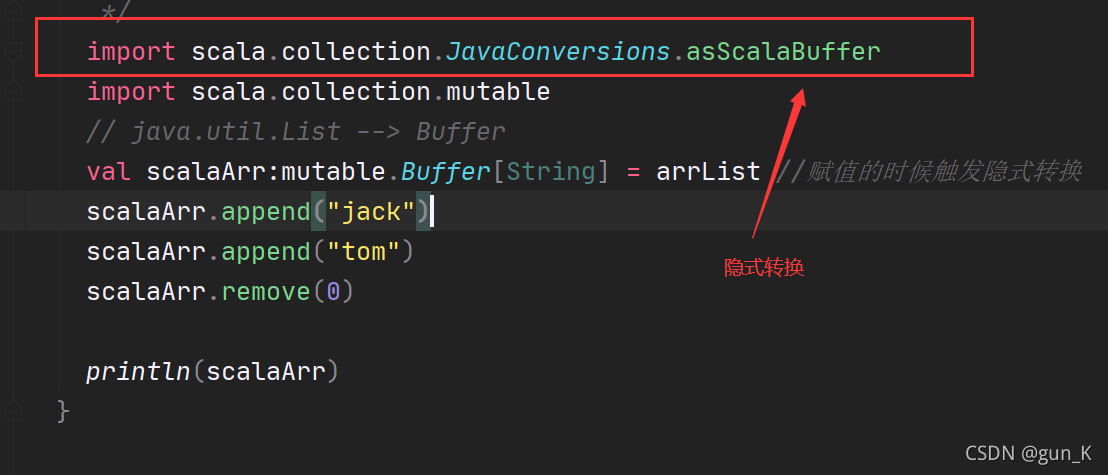
import scala.collection.JavaConversions.asScalaBuffer
import scala.collection.mutable
// java.util.List --> Buffer
val scalaArr:mutable.Buffer[String] = arrList //赋值的时候触发隐式转换
scalaArr.append("jack")
scalaArr.append("tom")
scalaArr.remove(0)
println(scalaArr)
元组 Tuple
元组也可是可以理解为一个容器,可以存放各种相同或者不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,成称为元组,灵活, 对数据没有过多的约束。
注意:元组中最大只能有22个元素
1. 元组的创建、访问、遍历
代码演示:
object 元组的创建使用 {
def main(args: Array[String]): Unit = {
/*
说明:1. touple是一个Touple,类型是Touple4
2. 为了高效的操作元组,编译器根据元素的个数不同,对应不同的元组类型。
分别是 Tuple1——Tiple22
*/
val tuple1 = (1 ,2 ,3, "hello",4)
println(tuple1)
/*访问元组:下面俩种方式底层实现一样
源码如下:
@throws(classOf[IndexOutOfBoundsException])
override def productElement(n: Int) = n match {
case 0 => _1
case 1 => _2
case 2 => _3
case 3 => _4
case 4 => _5
case _ => throw new IndexOutOfBoundsException(n.toString())
}
*/
println(tuple1._1) //下标从1开始
println(tuple1.productElement(1)) //下标从0开始
//元组的遍历需要使用到迭代器,
println("------------------------迭代器遍历元组--------------------------")
for (item <- tuple1.productIterator) {
println("item: " + item)
}
}
}
(1,2,3,hello,4)
1
2
------------------------迭代器遍历元组--------------------------
item: 1
item: 2
item: 3
item: hello
item: 4
Process finished with exit code 0
列表 List
介绍:
- Scala中的List和JavaList不一样,在Java中List是一个接口,真正存放数据的是ArrayList,而Scala的List可以直接存放数据,就是一个Object,默认情况下Scala的List是不可变的,List属于序列Seq。
- val List = scala.collection.immutable.List
- object List extends SeqFactory[List]
代码演示:
object 列表操作使用 {
/*
说明:
1. 在默认情况下,List 是 **scala.collection.immutable.List**,即不可变。
2. 在Scala中,**List就是不可变的**,如果需要使用可变的List,则使用 ListBuffer。
3. List在package object scala 做了 val List = scala.collection.immutable.List
4. val Nil = scala.collection.immutable.Nil //list()
*/
def main(args: Array[String]): Unit = {
val list01 = List(1, 2, 3) //创建时,直接分配元素
println(list01)
val list02 = Nil //空集合
println(list02)
}
}
List(1, 2, 3)
List()
Process finished with exit code 0
注意事项:
- List 默认为不可变集合。
- List 在 scala 包对象申明的,因此不需要引入其它包也可以使用。val List = scala.collection.immutable.List
- List中可以放任何数据类型,比如 arr1 的类型为 List[Any]
- 如果希望得到一个空列表,可以使用 Nil 对象,在 scala 包对象申明的,因此不需要引入其它包也可以使用。val Nil = scala.collection.immutable.Nil
1. 追加元素 :+ +:
代码演示:
//访问列表中的元素
val value = list01(1) //1是索引,表示取出第2个元素
println(value)
//列表追加元素:
//通过: :+ 和 +: 给list追加元素(本身集合没有变化)
var list1 = List(1, 2, 3, "dkl")
// :+ 运算符表示在列表的最后增加数据
val list2 = list1 :+ 4
println(list1)
println(list2)
val list3 = 10 +: list1
println(list3)
2. 追加元素 ::
代码演示:
/*
:: 运算符执行步骤:
1. List()
2. List(List(1, 2, 3, kaizi))
3. List(6, List(1, 2, 3, kaizi))
4. List(5, 6, List(1, 2, 3, kaizi))
5. List(4, 5, 6, List(1, 2, 3, kaizi))
*/
val list4 = List(1, 2, 3, "kaizi")
val list5 = 4 :: 5 :: 6 :: list4 :: Nil
println(list5)
3. 追加元素 :::
代码演示:
/*
::: 步骤:扁平化
1. List()
2. List(1, 2, 3, kaizi)
3. List(6, 1, 2, 3, kaizi)
4. List(5, 6, 1, 2, 3, kaizi)
5. List(4, 5, 6, 1, 2, 3, kaizi)
*/
val list6 = List(1, 2, 3, "kaizi")
val list7 = 4 :: 5 :: 6 :: list6 ::: Nil
println(list7)
ListBuffer
1. +=、append、++=、++、remove
代码演示:
import scala.collection.mutable.ListBuffer
object 可变列表ListBuffer {
def main(args: Array[String]): Unit = {
val list0 = ListBuffer[Int](1, 2, 3)
println(list0(2)) //按照索引访问元素
for (item <- list0) println(item) //遍历
//动态增加元素,list1就会变化,增加一个一个的元素
val list1 = new ListBuffer[Int] //空列表
list1 += 4
list1.append(5)
println(list1)
//将整个列表中的元素加到另一个列表中
list0 ++= list1
print(list0)
val list2 = list0 ++ list1
println(list2)
val list3 = list0 :+ 5 //list0不变,list3():ListBuffer(1, 2, 3, 4, 5, 5)
println(list3)
println("-----------------------------删除-------------------------------")
list1.remove(1) //按索引删除元素
for (i <- list1) println(i) //4
}
}
3
1
2
3
ListBuffer(4, 5)
ListBuffer(1, 2, 3, 4, 5)ListBuffer(1, 2, 3, 4, 5, 4, 5)
ListBuffer(1, 2, 3, 4, 5, 5)
-----------------------------删除-------------------------------
4
Process finished with exit code 0=
队列 Queue
- 1.队列是一个有序列表,在底层可以用数组或者链表来实现。
- 2.其输入和输出要遵循先入先出的原则。即:先存入队列的数据,要先取出。后存入的要后取出。
- 3.在Scala中,由设计者直接给我们提供队列类型 Queue 使用。
- 4.在Scala中,有 scala.collection.mutable.Queue 和 scala.collection.immutable.Queue,一般来说,我们在开发中通常使用可变集合中的队列。
1. 队列追加元素
代码演示:
//创建队列
val que1 = new mutable.Queue[Int]
println(que1) //Queue()
//给队列增加元素
que1 += 9
println(que1) //Queue(9)
que1 ++= List(4, 5, 7) //默认直接将List中的元素加在队列后面
println(que1) //Queue(9, 4, 5, 7)
2. 队列删除和加入队列元素
代码演示:
//在队列中,严格遵守,入队列的数据,放在队尾,出队是在队列头部取出数据
//dequeue从队列头部取出元素,que1本身会变
val queueElement = que1.dequeue()
println(que1)
//enqueue入队列,默认是从队列的尾部加入。Redis
que1.enqueue(100, 10, 99, 888)
println(que1) //Queue(4, 5, 7, 100, 10, 99, 888)
3. 返回队列里的元素
代码演示:
println("--------------------------返回队列的元素-----------------------------")
//1. 获取队列的第一个元素,队列本身不受影响
println(que1.head) //4
//2. 获取队列的最后一个元素,队列本身不受影响
println(que1.last) //888
//3.取出队尾的数据,即:返回除了第一个元素之外的元素,可以级联使用
println(que1.tail) //Queue(5, 7, 100, 10, 99, 888)
println(que1.tail.tail.tail.tail) //Queue(10, 99, 888)
Map 映射
1. Java中的Map
代码演示:
import java.util.HashMap;
public class Java中的Map映射 {
public static void main(String[] args) {
HashMap<String, Integer> hm = new HashMap<>();
hm.put("no1", 100);
hm.put("no2", 200);
hm.put("no3", 300);
hm.put("no4", 400);
hm.put("no5", 500);
System.out.println(hm); //无序的
System.out.println(hm.get("no2"));
}
}
{
no2=200, no1=100, no4=400, no3=300, no5=500}
200
Process finished with exit code 0
2. Scala中的Map
- Scala 中的 Map 和 Java类似,也是一个散列表,它存储的内容也是键值对(key—value)映射,Scala中不可变的 Map 是有序的,可变的 Map 也是无序的。
- Scala 中,有可变的 Map(scala.collection.mutable.Map)和不可变 Map(scala.collection.immutable.Map)
3. 构建 Map 映射
(1)构造不可变映射
Scala中的不可变 Map 是有序的,构建 Map 中的元素底层是 Tuple2 类型。
/*
1. 默认 Map 是 immutable.Map //不可变
2. key-value 类型支持Any
3. 在Map的底层,每对key-value是Tuple2
*/
val map1 = Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> "北京")
println(map1) //从结果可以看出,不可变的Map输出顺序和申明顺序一致
Map(Alice -> 10, Bob -> 20, Kotlin -> 北京)
从结果可以看出,不可变的Map输出顺序和申明顺序一致。
(2)构造可变映射
val map2 = mutable.Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> "北京")
println(map2) //从结果可以看出,可变的Map输出顺序和申明顺序不一致
Map(Bob -> 20, Kotlin -> 北京, Alice -> 10)
从结果可以看出,可变的Map输出顺序和申明顺序不一致。
(3)创建空映射
val map3 = new mutable.HashMap[String, Int]
println(map3)
Map()
(4)创建对偶元组
说明:
创建对偶元组:包含俩个数据的元组,类型为 Tuple2
包含键值对的二元组,和第一种方式等价,只是形式不同
val map4 = mutable.Map(("Alice", 10), ("Bob", 20), ("Kotlin", "北京"))
println(map4)
4. Map 取值方式
(1)使用 map(key) 取值
说明:
- 如果key存在,则返回对应的值。
- 如果key不存在,则抛出异常 java.util.NoSuchElementException
- 在 Java 中,如果 key不存在则返回 null
代码演示:
val map = mutable.Map("kaizi" -> "dkl", "mc" -> "ah", "rap" -> "xin")
println(map("kaizi")) //dkl
(2)使用 contains 方发检查是否存在 key
说明:
- 如果 key 存在,则返回 true
- 如果 key 不存在,则返回 false
代码演示:
if (map.contains("kaizi")) {
println("key 存在,值是:" + map("kaizi"))
} else {
println("key 不存在")
}
(3)使用 map.get(key).get 取值
通过 map.get(key) ,这样调用返回一个 Option 对象,要么是 Some,要么是 None。
说明和小结:
- map.get 方发会将数据进行包装
- 如果 map.get(key).get 存在返回 some,如果key不存在,则返回None。
- 如果 map.get(key),get 存在,返回 key 对应的值,否则,抛出异常。java.util.NoSuchElementException:None.get
代码演示:
println(map.get("mc").get) //ah
//println(map.get("mcc").get) //抛出异常
(4)使用 map.getOrElse() 取值
getOrElse 方法:
def getOrElse[B1 >: B](key: A, default: => B1): B1 = get(key) match {
case Some(v) => v
case None => default
}
说明:
- 如果key存在,返回key对应的值。
- 如果key不存在,返回默认值。在 Java 中底层有很多类似的操作。
代码演示:
//方式4:使用 map.gerOrElse() 取值
println(map.getOrElse("dongkaizi", "默认值K"))
//不存在dongkaizi, 返回默认值K
(5)如何选择取值的方式:
- 1.如果我们确定map有这个key,则应当使用map(key),速度快。
- 2.如果我们不能确定map是否有key,而且有不同的业务逻辑,使用 map.contains() 先判断,再加入逻辑。
- 3.如果只是简单的希望得到一个值,使用 map.getOrElse(“ip”, “xxx.x.x.x”)
5. Map 增删改查
(1)更新Map元素
小结:
- map 是可变的,才能修改,否则会报错。
- 如果存在key,则修改对应的值,key不存在,等价于添加一个key-value。
代码演示:
//注意只有可变Map才能修改跟新里面的元素
val map1 = mutable.Map("铠" -> "die", "貂蝉" -> "dance", "八戒" -> "fat")
println(map1)
map1("貂蝉") = "dance in dark"
println(map1)
Map(八戒 -> fat, 貂蝉 -> dance, 铠 -> die)
Map(八戒 -> fat, 貂蝉 -> dance in dark, 铠 -> die)
(2)添加Map元素
注意:
当增加一个key-value,如果key已经存在就是更新替换,如果不存在就是添加
代码演示:
val map2 = mutable.Map(("A", 1), ("B", 2), ("C", 3))
map2 += ("D" -> 4) // 增加单个元素
println(map2)
map2 += ("E" -> 5, "F" -> 6) // 增加多个元素
println(map2)
Map(D -> 4, A -> 1, C -> 3, B -> 2)
Map(D -> 4, A -> 1, C -> 3, F -> 6, E -> 5, B -> 2)
(3)删除Map元素
说明:
- 1.删除多个,就直接多写key。
- 2.如果key存在,就删除,不存在,也不会报错。
代码演示:
map2 -= ("A", "B", "AAA")
println(map2)
Map(D -> 4, A -> 1, C -> 3, F -> 6, E -> 5, B -> 2)
Map(D -> 4, C -> 3, F -> 6, E -> 5)
(4)遍历 Map
说明:
- 1.每遍历一次,返回的元素是Tuple2。
- 2.取出的时候,可以按照元组的方式取出。
代码演示:
val map3 = mutable.Map(("A", 1), ("B", "Beijing"), ("C", 3))
for ((k, v) <- map3) println(k + "->" + v)
for (k <- map3.keys) println(k) //取出键
for (v <- map3.values) println(v) //取出值
for (t <- map3) println(t) //取出元组
Set 集
1. Java 中的 Set
Java中,HashSet 是实现 Set接口的一个实体类,数据是以哈希表的形式存放的,里面不可以包含重复数据。Set接口是一种不包含重复元素的 collection,HashSet 中的数据也是没有顺序的。
public class Java中的Set {
public static void main(String[] args) {
HashSet hashSet = new HashSet<String>();
hashSet.add("kaizi");
hashSet.add("MCahao");
hashSet.add("MCxuejie");
hashSet.add("rapxin");
System.out.println(hashSet);
}
}
[kaizi, MCxuejie, rapxin, MCahao]
Process finished with exit code 0
2. Scala 中的集 Set
(1)集合(可变/不可变)的创建
代码演示:
val set = Set(1, 2, 3) //不可变
println(set)
val set2 = mutable.Set(1, 2, "hello") //可变集
println(set2)
Set(1, 2, 3)
Set(1, 2, hello)
(2)可变集合的元素删除
val set3 = mutable.Set(1, 2, 3, 4, "abc")
println(set3)
set3 -= 2 //操作符形式
set3.remove("abc") //方法形式,scala的Set可以直接删除值
println(set3)
Set(1, 5, 2, hello, 6, 4)
Set(1, 2, abc, 3, 4)
注意:如果删除的对象不存在,则不生效,也不会报错。
(3)遍历集合
for (x <- set3) println(x)