这里首先附上一张脑图:

一、List集合:
Vector:
Java中比较老的集合。底层是数组结构。
优点:线程同步、安全
缺点:效率低
通过源码我们可以查看到,vector集合底层大多数方法都是有synchronized关键字修饰的,所以效率比较低。见下图:
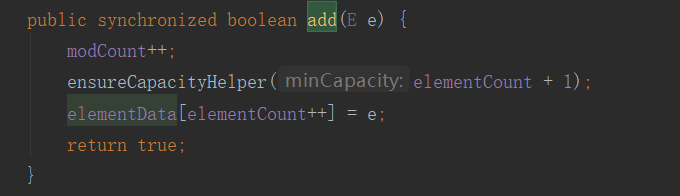
ArrayList:
底层:数组结构
优点:查询数据快
缺点:相对于链表结构增删慢
原因:
- 数组的索引处存放的就是数组的值,所以查询快。
- 数组每次删除数据都需要将原数组重新拷贝一份到新数组。然后垃圾回收机制会回收掉原数组。这样比较浪费时间,所以增删慢。
LinkedList:
底层:双链表
优点:数据增删快
缺点:查询慢
原因:
- 双链表结构中的每个元素,除了头部和尾部元素,中间元素都存储这上一个元素和下一个元素的信息。删除时只需要修改上一个元素和下一个元素的地址信息即可。所以删除快。
- 链表结构查询元素时都必须从头到尾依次查找,所以链表结构查询慢。
二、Set集合:
HashSet:
底层:基于HashMap实现的,可以说是HashMap的缩减。HashMap的value是一个没有实际意义的静态对象。见下图:

特点:无序、可以去重
LinkedHashSet:
底层:继承了HashSet,在构造方法中实现了LinkedHashMap,所以说是LinkedHashMap的缩减。见下图:

特点:有序、去重
TreeSet:
底层:在TreeMap的基础上进行封装的,在构造方法中实现了TreeMap。见下图:
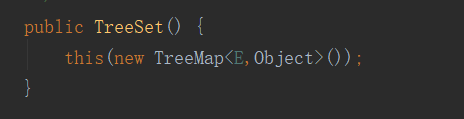
特点:
- 无序。集合元素顺序不是元素插入顺序。
- 排序。自然排序:根据key进行排序。定制排序:实现comparator
三、Map集合:
HashMap:
底层:数组+链表+红黑树
底层结构介绍:
- 存入值时,通过key拿到hashcode的值,通过hashcode计算hash值,然后hash(key)%len得到数组中的位置
- 如果该位置已经有值,再假设是一个链表,此时就会从头到尾查询链表,使用equals方法比较key值,如果相同,则会替换掉原来key值的value。如果整个链表没有相同的,则会加在链表尾部。
- 当链表长度超过8时,就会自动转成红黑树。
- 数组的长度默认是16,每次扩容都是2的幂。之所以选择16,是为了服务于从key映射到index(数组索引)的算法。
HashTable:
底层:数组+链表
HashTable和HashMap的区别:
- 两者最大区别是线程安全。HashTable是线程安全的,HashMap线程不安全。
- HashTable的键和值都不能为null,HashMap的键和值都可以为null。
- HashTable的默认初始容量11,HashMap默认初始容量16。二者扩容因子都是0.75。
- 二者计算Hash值的方法不同。Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸
LinkedHashMap:
底层:数组+链表+红黑树,在这个基础上加入了双链表。
总结:LinkedHashMap继承HashMap方法,重写了Entry方法,新增了上下节点的指针,就形成了双向链表。还有一个head的成员变量 ,是这个双向链表的头结点。见下图:

TreeMap:
底层:红黑树
底层原理:TreeMap底层定制了一个比较器。
自然排序:如果构造方法中没有定制排序,会根据key进行自然排序
定制排序:创建TreeMap对象时传入了一个Comparator对象,该对象负责
对TreeMap中所有的key进行排序。

