笔记之用,原文链接:https://www.ioiogoo.cn/2018/03/15/,感谢原博分享
RNN生成模型的采样策略
RNN卷积神经网络可以用来做生成模型,目前已经有很多很成熟的应用,比如几个词生成一首古诗、一幅图片自动生成音乐等等。但是之前一直困扰我的一个问题是,在CNN中,将一个已经训练好的模型来预测一幅图片(假设是个分类问题),那么只要给定一张图片,它的分类肯定不会变化。而RNN在每次给定了输入后,怎么生成了不一样的输出结果呢?
在网上查了一些资料发现RNN在生成结果的时候会做一个sampling的过程,而网上很少有中文资料讲RNN是如何做sample的,在看过一些代码和一些文章后,写下这篇文章希望能对sample有个直观的了解。
Greedy Search
这是最简单的方式,直接采用softmax后的最大概率所对应的结果。
这样处理之后,在给定一个输入后,输出结果也就固定了,对于生成模型中,显然不具备结果多样性的特点。
Beam Search
上面的策略是只输出概率最高的一个结果,那现在策略改了,我取输出概率最高的前N个结果,然后随机选择一个作为最终结果,那是不是结果就有了多样性呢?
但是这种策略也有局限性,那就是在取出的前N个结果中,每个结果出现在最终结果的概率其实是一样的,这样子就丢失了一定得准确性。
Random Sampling
随机采样策略是目前比较流行的做法。基于输出结果的概率分布来随机采样,这样既保证了输出结果的多样性,也保留了输出结果的准确度。
举个例子解释下随机采样相对于前两种策略的优点。
假如给定的输入生成的输出结果是[0.8, 0.15, 0.05],那么在理想的情况下,我运行100次,采用Random Sampling生成的结果有80次取第一位代表的结果,15次取第二位,5次取第三位。如果采用Beam Search结果中有有50次取第一位,50次取第二位。如果采用Greedy Search,那么100次都只取第一位。
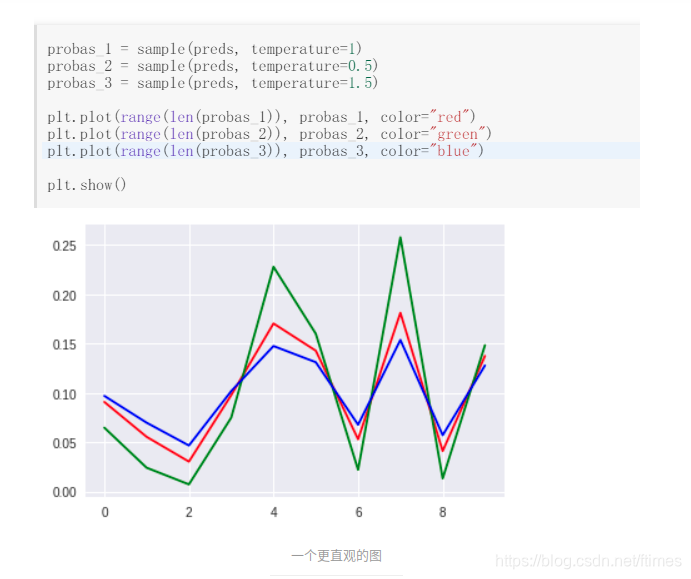
Random Sampling还有一个问题是问题的多样性有时候希望能有所控制,比如上面的例子,我如果倾向于生成更准确的结果,但是仍然要保留多样性,目标就是增加让概率值高的变得更高,概率值低的变得更低。具体的操作是使用temperature来控制。
def sample(preds, temperature=1.0):
'''
当temperature=1.0时,模型输出正常
当temperature=0.5时,模型输出比较保守
当temperature=1.5时,模型输出比较open
'''
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
return preds
将[0.8, 0.15, 0.05]分别进行temprature为0.5和1.5时,输出的值为
[0.96240602 0.03383459 0.0037594 ]
[0.67336313 0.22058883 0.10604805]
比较直观地可以看到结果,当概率分布比较均匀时,随机采样的结果也会比较分散,反之比较集中。