这是我参与11月更文挑战的第20天,活动详情查看:2021最后一次更文挑战
长尾分布各位肯定并不陌生,指的是少数几个类别却有大量样本,而大部分类别都只有少量样本的情况,如下图所示

通常我们讨论长尾分布或者是文本分类的时候只考虑单标签,即一个样本只对应一个标签,但实际上多标签在实际应用中也非常常见,例如个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食,一般情况下,一个人的爱好有这其中的一个或多个,这就是典型的多标签分类任务
EMNLP2021上有一篇名为Balancing Methods for Multi-label Text Classification with Long-Tailed Class Distribution的论文详细探讨了各种平衡损失函数对于多标签分类问题的效果,从最初的BCE Loss到Focal Loss等,感觉这篇文章更像是平衡损失函数的综述。源码在Roche/BalancedLossNLP
Loss Functions
在NLP领域,二值化交叉熵损失(Binary Cross Entropy Loss)常被用来处理多标签文本分类问题,给定一个含有
N个样本的训练集
(x1,y1),...,(xN,yN),其中
yk=[y1k,...,yCk]∈{0,1}C,
C是类别数量,假设模型对于某个样本的输出为
zk=[z1k,...,zCk]∈R,则BCE损失的定义如下:
LBCE={−log(pik)−log(1−pik)if yik=1otherwise
其中,
pik=σ(zik),对于多标签分类问题来说我们需要将模型的输出值压缩到[0,1]之间,所以需要用到sigmoid函数
原本单标签问题,真实值
yk相当于一个onehot向量,而对于多标签来说,真实值
yk相当于一个onehot向量中多了一些1,例如[0,1,0,1],表示该样本同时是第1类和第3类
这种朴素的BCE非常容易收到标签不平衡的影响,因为头部样本比较多,可能所有头部样本的损失总和为100,尾部所有样本的损失加起来都不超过10。下面,我们介绍三种替代方法解决多标签文本分类中长尾数据的类别不均衡问题。这些平衡方法主要思想是重新加权BCE,使罕见的样本-标签对得到合理的"关注"
Focal Loss (FL)
通过在BCE上乘一个可调整的聚焦参数
γ≥0,Focal Loss将更高的损失权重放在"难分类"的样本上,这些样本对其真实值的预测概率很低。对于多标签分类任务,Focal Loss定义如下:
LFL={−(1−pik)γlog(pik)−(pik)γlog(1−pik)if yik=1otherwise
实际上论文关于Focal Loss的介绍只有这么多,如果想了解Focal Loss更详细的参数介绍,可以看我的这篇文章Focal Loss详解
Class-balanced focal loss (CB)
通过估计有效样本数,CB Loss进一步重新加权Focal Loss以捕捉数据的边际递减效应,减少了头部样本的冗余信息。对于多标签任务,我们首先计算出每种类别的频率
ni,那么对于每个类别来说,都有其平衡项
rCB
rCB=1−βni1−β
其中,
β∈[0,1)控制着有效样本数量的增长速度,损失函数变为
LCB={−rCB(1−pik)γlog(pik)−rCB(pik)γlog(1−pik)if yik=1otherwise
Distribution-balanced loss (DB)
通过整合再平衡权重以及头部样本容忍正则化(negative tolerant regularization, NTR),Distribution-balanced Loss首先减少了标签共现的冗余信息(这在多标签分类的情况下是很关键的),然后对"容易分类的"样本(头部样本)分配较低的权重
首先,为了重新平衡权重,在单标签的情况下,一个样本可以通过采样概率
PiC=C1ni1来加权,但是在多标签的情况下,如果采用同样的策略,一个具有多标签的样本会被过度采样,概率是
PI=c1∑yik=1ni1。因此,我们需要结合两者重新平衡权重
rDB=PiC/PI
我们可以将上述权重变得更光滑一些(有界)
r^DB=α+σ(β×(rDB−μ))
此时,
r^DB的值域为
[α,α+1]。rebalanced-FL (R-FL) 损失函数为
LR-FL={−r^DB(1−pik)log(pik)−r^DB(pik)log(1−pik)if yik=1otherwise
然后,NTR对同一标签头部和尾部样本进行不同的处理,引入一个比例因子
λ和一个内在的特定类别偏差
vi以降低尾部类别的阈值,避免过度抑制
LNTR-FL={−(1−qik)log(qik)−λ1(qik)log(1−qik)if yik=1otherwise
对于尾部样本来说,
qik=σ(zik−vi);对于头部样本来说,
qik=σ(λ(zik−vi))。
vi可以在训练开始时最小化损失函数来估计,其比例系数为
κ,类别先验信息
pi=ni/N,则
b^i=−log(pi1−1), vi=−κ×b^i
最终,通过整合再平衡权重以及NTR,Distribution-balanced Loss为
LDB={−r^DB(1−qik)log(qik)−r^DBλ1(qik)log(1−qik)if yik=1otherwise
Result
作者实验的两个数据集如下
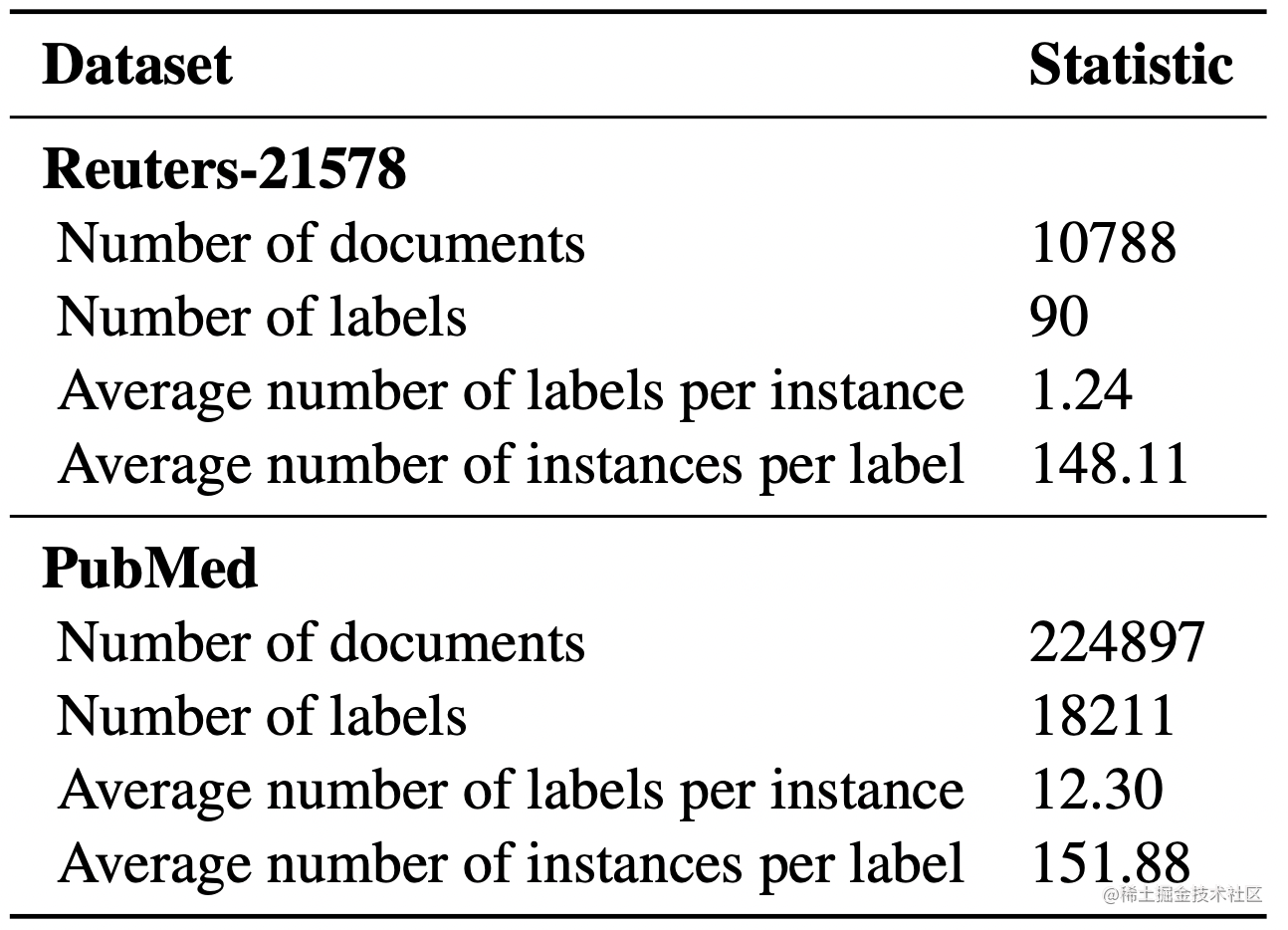
使用的模型为SVM,对比不同损失函数的效果

个人总结
这篇论文,创新了但又没创新,所有的损失函数都是别人提出来的,自己的工作只是在多标签数据集上跑了一遍做了个对比。最后,纯爱战士表示很淦