Hive建表方式共有三种:
- 直接建表法
- 查询建表法
- like建表法
首先看官网介绍
’[]’ 表示可选,’|’ 表示二选一
1.直接建表法:
Hive将HDFS上的文件映射成表结构,通过分隔符来区分列(比如’,’ ‘;’ or ‘^’ 等),row format就是用于指定序列化和反序列化的规则。
比如对于以下记录:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
逗号用于分割列,即FIELDS TERMINATED BY char,分割为如下列 ID、name、hobby(该字段是数组形式,通过 ‘-’ 进行分割,即COLLECTION ITEMS TERMINATED BY ‘-’)、address(该字段是键值对形式map,通过 ‘:’ 分割键值,即 MAP KEYS TERMINATED BY ‘:’);
而FIELDS TERMINATED BY char用于区分不同条的数据,默认是换行符;
file format(HDFS文件存放的格式)
默认TEXTFILE,即文本格式,可以直接打开。
注:一般很少用insert (不是insert overwrite)语句,因为就算就算插入一条数据,也会调用MapReduce,这里我们选择Load Data的方式。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
说明:
1、 Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
2、 filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode:9000/user/hive/project/data1
3、 LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。
如果没有指定 LOCAL 关键字,则根据inpath中的uri查找文件
4、 OVERWRITE 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
具体实例
加载相对路径数据。
hive> load data local inpath 'sc.txt' overwrite into table sc;
加载绝对路径数据。
hive> load data local inpath '/home/hadoop/hivedata/students.txt' overwrite into table student;
加载包含模式数据。
hive> load data inpath 'hdfs://mini1:9000/hivedata/course.txt' overwrite into table course;
OVERWRITE关键字使用。
external
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
元数据就是表的属性数据,表的名字,列信息,分区等标的属性信息,它是存放在RMDBS传统数据库中的(如,mysql)。表数据就是表中成千上万条数据了。
hive的存储过程:启动hive时,会初始化hive,这时会在mysql中生成大约36张表(后续随着业务的复杂会增加),然后创建表,会在mysql中存放这个表的信息(不是以表的形式存在的,而是把表的属性以数据的形式放在mysql中,这样在hive中使用sql命令一样是能够查到这张表的)。然后把本地的文本文件使用hive命令格式化导入到表中,这样这些数据就存放到hdfs中,而不是在mysql或hive中。
查询建表法
通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据
一般用于中间表
like建表法
会创建结构完全相同的表,但是没有数据。
常用语中间表
表分区的增删修查
增加分区
这里我们创建一个分区外部表
create external table testljb(id int) partitioned by (age int);
添加分区
官网说明:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)实例说明
- 一次增加一个分区
alter table testljb add partition (age=2);- 一次增加多个分区
alter table testljb add partition(age=3) partition(age=4);- 注意:一定不能写成如下方式:
alter table testljb add partition(age=5,age=6);如果我们show partitions table_name 会发现仅仅添加了age=6的分区。
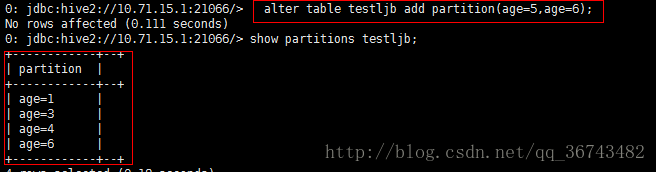
这里猜测原因:因为这种写法实际上:具有多个分区字段表的分区添加,而我们写两次同一个字段,而系统中并没有两个age分区字段,那么就会随机添加其中一个分区。
举个例子,有个表具有两个分区字段:age分区和sex分区。那么我们添加一个age分区为1,sex分区为male的数据,可以这样添加:
alter table testljb add partition(age=1,sex='male');删除分区
删除分区age=1
alter table testljb drop partition(age=1);注:加入表testljb有两个分区字段(上文已经提到多个分区先后顺序类似于windows的文件夹的树状结构),partitioned by(age int ,sex string),那么我们删除age分区(第一个分区)时,会把该分区及其下面包含的所有sex分区一起删掉。
修复分区
修复分区就是重新同步hdfs上的分区信息。
msck repair table table_name;查询分区
这个很简单
show partitions table_name;参考: https://blog.csdn.net/qq_36743482/article/details/78418343