1.Dropout原理
1.概述
作用:防止过拟合
方法:训练时,随机停止某些神经元的参数训练
2. Dropout工作流程及使用
2.1 Dropout具体工作流程
假设我们要训练这样一个神经网络,如图2所示。

上图表示标准的神经网络。
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)

(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
Dropout在神经网络中的使用
Dropout的具体工作流程上面已经详细的介绍过了,但是具体怎么让某些神经元以一定的概率停止工作(就是被删除掉)?代码层面如何实现呢?
下面,我们具体讲解一下Dropout代码层面的一些公式推导及代码实现思路。
(1)在训练模型阶段
无可避免的,在训练网络的每个单元都要添加一道概率流程。

图4:标准网络和带有Dropout网络的比较
对应的公式变化如下:
. 没有Dropout的网络计算公式:
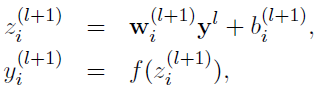
. 采用Dropout的网络计算公式:
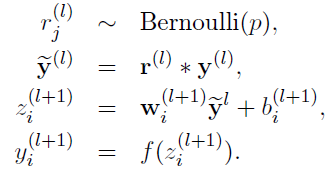
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、…、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
在测试模型阶段
预测模型的时候,每一个神经单元的权重参数要乘以概率p。
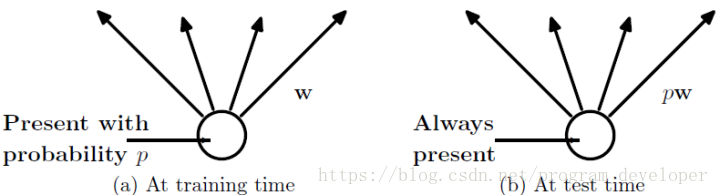
图5:预测模型时Dropout的操作
测试阶段Dropout公式:
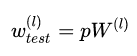
3.通过代码理解
# coding:utf-8
import numpy as np
# dropout函数的实现,函数中,x是本层网络的激活值。Level就是dropout就是每个神经元要被丢弃的概率。
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必须在0~1之间
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
# 硬币 正面的概率为p,n表示每个神经元试验的次数
# 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
print(dropout(x,0.4))
import torch
import torch.nn as nn
import torch.nn.functional as F
class LinearFC(nn.Module):
def __init__(self):
super(LinearFC, self).__init__()
self.fc = nn.Linear(3, 2)
def forward(self, input):
out = self.fc(input)
out = F.dropout(out, p=0.5, training=self.training)
return out
Net = LinearFC()
x = torch.randint(10, (2, 3)).float() # 随机生成不大于10的整数,转为float, 因为nn.linear需要float类型数据
Net.train()
output = Net(x)
print(output)
# train the Net
- 第一步
Net = LinearFC(),生成 W W W和 b b b:
W=tensor([[-0.5347, 0.3559, 0.0637],
[-0.5676, -0.0257, 0.1802]], requires_grad=True)
b=tensor([0.4141, 0.4688], requires_grad=True)
- 第二步
x = torch.randint(10, (2, 3)).float(),随机生成不大于10的整数,转为float, 因为nn.linear需要float类型数据
x=tensor([[3., 2., 0.],
[2., 6., 8.]])
- 第三步
output = Net(x)out = self.fc(input)进入forward, o u t = x × W T + b out = x \times W^T + b out=x×WT+b,代码实现:torch.mm(x, Net.fc.weight.t()) + Net.fc.bias
tensor([[-0.4783, -1.2855],
[ 1.9898, 0.6210]], grad_fn=<AddBackward0>)
- 第四步,dropout,公式 o u t = o u t / ( 1 − 0.5 ) 在 以 0.5 概 率 置 为 0 out = out/(1-0.5)在以0.5概率置为0 out=out/(1−0.5)在以0.5概率置为0
(torch.mm(x, Net.fc.weight.t()) + Net.fc.bias)/(1-0.5)=
tensor([[-0.9565, -2.5710],
[ 3.9796, 1.2420]], grad_fn=<DivBackward0>)
out=
tensor([[-0.0000, -0.0000],
[0.0000, 1.2420]], grad_fn=<MulBackward0>)
可以看到经过dropout之后,数据变为:tensor([[-0.0000, -0.0000], [0.0000, 1.2420]], grad_fn=<MulBackward0>)
转载:https://blog.csdn.net/powu0193/article/details/99573632