简介
本文主要讲解DataX的全量和增量同步实现方式,有具体代码可参考。增量同步时,将日志按天写入日志文件中
增量同步和全量同步是数据库同步的两种方式。
全量同步是一次性同步全部数据,增量同步则只同步两个数据库不同的部分。
多表同步大家肯定都会想用最省事的方法,比如就建立一个公共的Json模板,将读库(reader)和写库(writer)的连接地址、端口、账号、密码、表名都动态传入,然后字段用*号代替。那博主就告诉你,后续出错和维护的坑你得走一遍了,并不是说不行,具体还是看业务场景来。
避免大家踩坑,这里的多表同步会采用脚本进行动态参数传入,建议每个表对应一个Json文件,每个字段都单独写,并且字段用`符号包起来(如果某个字段是MySQL关键字会报错),不要嫌麻烦,不然后面出问题了问题更大,你还得重来一遍,如果涉及几十上百张表,你会懂那个痛苦的,频繁的Ctrl+C和Ctrl+V让你怀疑人生,不多说了,都是泪 。

话不多说,直接开撸
一、全量同步
1.示例Shell脚本文件:allSyncTask.sh
#!/bin/bash
. /etc/profile
# 读库的IP
r_ip="127.0.0.1"
# 读库的端口
r_port="3306"
# 读库的数据库名称
r_dbname="datax"
# 读库的账号
r_username="root"
# 读库的密码
r_password="123456"
# 写库的IP
w_ip="127.0.0.1"
# 写库的端口
w_port="3306"
# 写库的数据库名称
w_dbname="datax2"
# 写库的账号
w_username="root"
# 写库的密码
w_password="123456"
# DataX全量同步(多个文件直接写多个执行命令)
python /opt/datax/bin/datax.py /opt/datax/job/table1.json -p "-Dr_ip=$r_ip -Dr_port=$r_port -Dr_dbname=$r_dbname -Dr_username=$r_username -Dr_password=$r_password -Dw_ip=$w_ip -Dw_port=$w_port -Dw_dbname=$w_dbname -Dw_username=$w_username -Dw_password=$w_password"
python /opt/datax/bin/datax.py /opt/datax/job/table2.json -p "-Dr_ip=$r_ip -Dr_port=$r_port -Dr_dbname=$r_dbname -Dr_username=$r_username -Dr_password=$r_password -Dw_ip=$w_ip -Dw_port=$w_port -Dw_dbname=$w_dbname -Dw_username=$w_username -Dw_password=$w_password"
2.示例Json文件(这里随便写一个,大家当做模板参考就行):table1.json
因为是多表同步,会执行多个文件,我这里的
channel参数设置为10。
{
"job": {
"setting": {
"speed": {
"channel": 10
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"`id`",
"`name`"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://${r_ip}:${r_port}/${r_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull"],
"table": ["tabel1"]
}
],
"username": "${r_username}",
"password": "${r_password}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "update",
"column": [
"`id`",
"`name`"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://${w_ip}:${w_port}/${w_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull",
"table": ["tabel1"]
}
],
"username": "${w_username}",
"password": "${w_password}"
}
}
}
]
}
}
3.运行脚本即可
运行脚本之前先将放入的脚本进行授权,否则不能执行,对文件进行最高级别授权命令:
chmod 777 allSyncTask.sh
将allSyncTask.sh放入指定文件夹,运行命令:
./allSyncTask.sh
至此全量同步完成
二、定时增量同步
相比全量同步,增量同步增加了用某个字段来判断改条数据是否被更新,具体体现在 Shell 脚本和 Json 文件中,下面会提到。
1.准备工作:
给需要同步的表增加用于增量同步判断的字段,可用ID也可以用时间,个人建议用时间,更方便。
给读库的table1表加上实时更新的时间记录字段(可根据需要是否给写库也加上,我这里是加上的/font>):
alter table table1 add column `curr_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间(DataX数据采集使用)';
具体可参考我的其他博客的第二点:MySQL | 设置时间字段为自动更新(CURRENT_TIMESTAMP).
2.示例Shell脚本文件(相比于全量同步,这里使用了当前时间做条件传入):incrSyncTask.sh
#!/bin/bash
. /etc/profile
# 当前时间(用于增量同步判断条件)
curr_time=$(date +%Y-%m-%d)
# 读库的IP
r_ip="127.0.0.1"
# 读库的端口
r_port="3306"
# 读库的数据库名称
r_dbname="datax"
# 读库的账号
r_username="root"
# 读库的密码
r_password="123456"
# 写库的IP
w_ip="127.0.0.1"
# 写库的端口
w_port="3306"
# 写库的数据库名称
w_dbname="datax2"
# 写库的账号
w_username="root"
# 写库的密码
w_password="123456"
# DataX全量同步(多个文件直接写多个执行命令)
python /opt/datax/bin/datax.py /opt/datax/job/incr_table1.json -p "-Dcurr_time=$curr_time -Dr_ip=$r_ip -Dr_port=$r_port -Dr_dbname=$r_dbname -Dr_username=$r_username -Dr_password=$r_password -Dw_ip=$w_ip -Dw_port=$w_port -Dw_dbname=$w_dbname -Dw_username=$w_username -Dw_password=$w_password"
python /opt/datax/bin/datax.py /opt/datax/job/incr_table2.json -p "-Dcurr_time=$curr_time -Dr_ip=$r_ip -Dr_port=$r_port -Dr_dbname=$r_dbname -Dr_username=$r_username -Dr_password=$r_password -Dw_ip=$w_ip -Dw_port=$w_port -Dw_dbname=$w_dbname -Dw_username=$w_username -Dw_password=$w_password"
至于为什么加. /etc/profile,参考此文章的第二点:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
3.示例Json文件(相比于全量同步,这里使用了在读库(reader)加了一个where条件,条件就是传入的当前日期):incr_table1.json
{
"job": {
"setting": {
"speed": {
"channel": 10
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"`id`",
"`name`",
"`curr_time`"
],
"where": "curr_time between DATE_SUB('${curr_time} 05:00:00', INTERVAL 1 DAY) and '${curr_time} 04:59:59'",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://${r_ip}:${r_port}/${r_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull"],
"table": ["tabel1"]
}
],
"username": "${r_username}",
"password": "${r_password}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "update",
"column": [
"`id`",
"`name`",
"`curr_time`"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://${w_ip}:${w_port}/${w_dbname}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull",
"table": ["tabel1"]
}
],
"username": "${w_username}",
"password": "${w_password}"
}
}
}
]
}
}
简单说一下上面的增量逻辑:在 Shell 脚本中传入当前日期给where条件时间,我会让定时器在凌晨五点执行,所以查询的是昨天凌晨5点到今天04:59:59有修改的数据,查询条件就是第1点说到的实时修改时间
4.添加定时器,这里使用的是crontab
运行脚本之前先将放入的脚本进行授权,否则不能执行,对文件进行最高级别授权命令:
chmod 777 incrSyncTask.sh
4.1.编辑定时任务crontab,使用以下命令进入crontab任务文件:
crontab -e
4.2.进行vi编辑即可,添加crontab定时任务(每天凌晨5点执行,跟cron表达式类似):
0 5 * * * /opt/datax/bin/incrSyncTask.sh >/dev/null 2>&1
建议加上>/dev/null 2>&1,因为crontab会把日志都发给mail,这里是直接丢弃一样
,也可以指定输出到某个文件中,参考如下命令,每天执行后生成日志文件:
0 5 * * * /opt/datax/bin/incrSyncTask.sh > /opt/datax/log/incrSyncTask_$(date +\%Y\%m\%d).log 2>&1
这里需要用斜杠"\"对百分号进行转义
4.3.查看crontab日志:
tail -f /var/log/cron
或
tail -f /var/spool/mail/root
如果找不到/var/spool/mail/root文件,参考:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
定时任务跑了之后,会将日志文件输出到上面的位置,根据登录宿主机的用户不同,文件名不同。这里的发送到邮箱有些坑,日志量过大问题、找不到邮箱问题,参考:DataX踩坑2 | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
三、注意点
1.关于脚本运行后连接数据库报连接失败,重新连接等错误(\r换行符的问题)
其实脚本中的所有数据库参数都是正确的,但就是报错,可以看日志,发现每个参数后面都携带了\r换行符
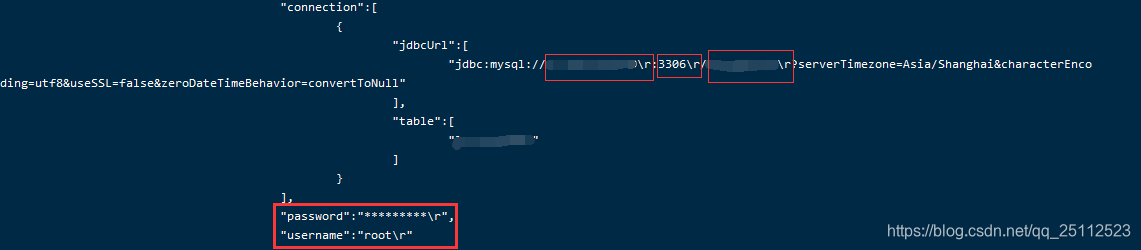
解决方法:Shell 脚本参数传递时有 \r 换行符问题.
2.批量执行多文件命令报错
建议将speed中的channel参数设置大一点,如10。
由于DataX读取数据和写入数据需要占用服务器性能,所以需要考虑服务器性能,channel的值并不是越大越好。
具体可参考结尾的性能优化文章。
3.执行命令报:FileNotFoundException
本来想将全量同步 Json 文件和增量同步 Json 文件放入不同的文件夹A和B,便于区分,直接放在 DataX 安装路径的 job 目录中,结果执行命令时找不到 job 目录下的A、B文件夹中的Json文件
4.定时任务crontab不执行 或 报错:/bin/sh: java: command not found
参考文章:DataX踩坑2: | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
相关文章
- Shell 脚本参数传递时有 \r 换行符问题.
- DataX | 在Liunx上安装和使用.
- DataX踩坑1 | 连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port.
- DataX踩坑2 | 定时任务crontab不执行或报错:/bin/sh: java: command not found.
参考博客
- Shell脚本-date用法:https://blog.csdn.net/shandianling/article/details/7640933/.
- Shell脚本-echo颜色输出:https://www.cnblogs.com/williamjie/p/9198836.html.
- crontab 详细用法 定时任务:https://www.cnblogs.com/aminxu/p/5993769.html.
- 如何查看crontab日志:https://www.cnblogs.com/doseoer/p/5663187.html.
- DataX性能优化1:https://xiaozhuanlan.com/topic/7860594132.
- DataX性能优化2:https://www.cnblogs.com/hit-zb/p/10940849.html.