基本思路
使用selenium模块来进行谷歌驱动,爬取相关的数据,然后将数据进行处理,利用正则分离数据,然后就是把每个功能包装成一个函数,利用得到的数据,实现存入数据库,以及存入csv等相关功能,还有一个就是数据可视化,先后荣立使用的是matplotlib和Pyecharts两个库,相对于matplotlib而言,Pyecharts做出的数据可视化更加的真实,可以动态交互的展现图表,然后对于语音处理方面,主要分为两个方面,一方面是录音转文字,录音的话,使用的是PyAudio库进行录音,存为wav格式的文件,这里使用的是借用科大讯飞API进行语音转文字,然后进行语音播报,使用的是Pyttsx3进行语音播报,然后可以进行死板式聊天,能力有限,并不能搭建出一套完整的人机对话项目。
关于数据的爬取
基础知识
爬取是用的谷歌驱动后来又换成了谷歌驱动,爬取前需要安装谷歌驱动(下载地址),然后才可以导入,然后就是爬取对应代码里面的spider_jinan()函数和spider_shandong()函数分别爬取
爬取的过程分析
用驱动打开浏览器,打开网页,通过xpath找到想要的数据,然后将数据保存为txt文件,最后关闭浏览器
数据可视化
使用matplotlib和pyecharts两个画图
数据的保存
存入数据库,存入csv
声音处理
录音及其转文字
使用的是PyAudio库,进行录音,设置的讲话时间为4秒,然后把数据保存下来,存成wav文件,然后使用wave库进行读取wav文件,设置声道数为1,采样宽度为2字节,采样率设为16000,最后将读入的文件传输给speech2text(speech, TOKEN, int(1536))函数,speech是数据,TOKEN是借助的API,int(1536)表示的是普通话,补充一下,也可以说英语,传入1737就是英语,传入1637就是粤语,传入1837就是四川话,可以传入多种数据,这里的语音识别,借助的是科大讯飞转的文字,使用科大讯飞前要进行数据的注册,注册之后会生成相应的数据,base_url,APIKey,SecretKey,这三个数据要保证传入正确才能正确的将语音转化成文字
关于语音播报
使用的是pyttsx3库,这个播报库使用起来非常的方便,首先用pyttsx3.init()函数进行初始化,然后就是用say()函数写出要说的内容,最后就是使用runAndWait函数进行播报,一共分为这三个步骤
代码
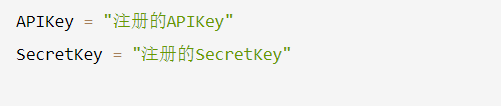
首先要去讯飞平台注册账号,然后就会获得APIKey和SecretKey,才能进行语音转文字
需填入方可使用
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author:杜小皮
# datetime:2021/6/23 10:41
# software: PyCharm
import wave
import requests
import time
import base64
from pyaudio import PyAudio, paInt16
import os
from time import sleep
import pyttsx3
from selenium import webdriver
import pandas as pd
import re
from PIL import Image
from wordcloud import WordCloud
from imageio import imread
import collections
import matplotlib.pyplot as plt
import pyecharts
from sqlalchemy import create_engine
# from pyecharts import Pie
def spider_jinan(): # 爬取所有数据
js = "var q=document.documentElement.scrollTop=100000"
driver = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
url = 'https://www.tianqi.com/jinan/' # 打开网页
driver.get(url)
content = driver.page_source
cl = driver.find_elements_by_xpath("/html/body/div[5]/div/div[2]/div[1]/span[2]/a[2]/h3") # 查看未来30天
cl[0].click() # 此处是根据老师讲的京东代码而写
list = driver.find_elements_by_xpath("/html/body/div[6]/div[2]/ul[1]") # 匹配所有数据
result = list[0].text.split("\n")
driver.close()
return result
def spider_res_jinan(result): # 数据的分离
weather = []
temp = []
data = []
month = []
day = []
a = 1
for i in result:
a += 1
# print(i)
# print(a)
b = (a % 4)
if (b == 0):
# print(i)
weather.append(i)
# 利用正则表达式找出温度,日期,天气
for i in result:
# print(i)
lista = re.findall("\d{2}-\d{2}", i)
# print(data)
# print(tem)
tem = re.findall("\d{2}~\d{2}℃", i)
# print(tem)
if tem == []:
del tem
else:
for iii in tem:
temp.append(iii)
if lista == []:
del lista
else:
# print(data)
for ii in lista:
# print(ii)
data.append(ii)
for i in data:
month.append(i.split("-")[0])
day.append(i.split("-")[1])
return weather, temp, data, month, day
def mean_temp_jinan(temp): # 求出未来30天的平均温度
temp_mean = []
for i in temp:
t = 0
# print(i)
z = re.findall("\d{2}", i)
for ii in z:
# print(ii)
ii = int(ii)
t += ii
temp_mean.append(t / 2)
return temp_mean
def image_jinan(weather): # 画出词云
res = pd.Series()
res["weather"] = pd.Series(weather)
qq = pd.DataFrame({
"天气": res["weather"]})
qq.to_csv("E:\\tianqi.txt", index=False)
stop = pd.read_csv('E:\\tianqi.txt', encoding='utf-8', engine='python', sep='limh')
back_pic = imread("E:\\code\\spider\\week8\\word_cloud\\helle.jpg") # aixin.jpg # 设置背景图片
wc = WordCloud(font_path='C:\\Windows\\Fonts\\simkai.TTF', # 设置字体 使用的 windows 自带的字体
background_color="white", # ="white", #背景颜色
max_words=2000, # 词云显示的最大数
mask=back_pic, # 设置背景图片
max_font_size=200, # =200, #字体最大值
random_state=42,
collocations=True, )
tupian = Image.open("E:\\helle.jpg") # 打开图片路径,形成轮廓
# 绘图
plt.figure(figsize=(16, 8))
plt.imshow(tupian)
plt.axis('off')
def temp_to_csv(weather, temp, data): # 将数据转存为csv
results = pd.DataFrame()
res = pd.Series()
res["weather"] = pd.Series(weather)
res["temp"] = pd.Series(temp)
res["data"] = pd.Series(data)
results.insert(0, '天气', res["weather"])
results.insert(0, '温度', res["temp"])
results.insert(0, '日期', res["data"])
# print(results)
results.to_csv("E:\\weather.csv", index=False)
def plt_mean_temp_jinan(data, mean__temp): # 画平均温度折线图
plt.xlabel("天气")
plt.ylabel("平均温度")
plt.title("温度变化")
plt.plot(data, mean__temp)
plt.grid(True)
plt.show()
def plt_fer_weather(weather):
tianqi = []
pinlv = []
word_counts = collections.Counter(weather) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词
# print(word_counts_top10) # 输出检查
sun = 0
cloud = 0
lit_rain = 0
mit_rain = 0
sail = 0
shadom = 0
z_rain = 0
th_rain = 0
xiaoyu = 0
for i in word_counts_top10:
print(i[0])
if i[0] == '多云':
sun += 1
elif i[0] == '阴转雨':
cloud += 1
elif i[0] == '多云转晴':
lit_rain += 1
elif i[0] == '小雨到大雨':
mit_rain += 1
elif i[0] == '中雨到大雨':
shadom += 1
elif i[0] == '多云转雨':
z_rain += 1
elif i[0] == '小雨到中雨':
th_rain += 1
elif i[0] == '小雨转多云':
sail += 1
elif i[0] == '小雨转阴':
xiaoyu += 1
# print(i[0])
tianqi = ["小雨转阴", '小雨到大雨', '多云转晴', '小雨转多云', '多云', '小雨到中雨', '阴转雨', '中雨到大雨', '多云转雨']
pie = pyecharts.Pie("山东天气比例", '2020-7-11')
pie.add('天气类型', tianqi, [xiaoyu, mit_rain, lit_rain, sail, sun, th_rain, cloud, shadom, z_rain], is_label_show=True)
pie = pyecharts.Pie("全国天气类型比例", '2018-4-16')
pie.render('C:\\Users\\dupeibo\\Desktop\\未来30天天气概况.html')
def spider_shandong():
city = []
temp = []
weather = []
js = "var q=document.documentElement.scrollTop=100000"
driver = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
url = 'https://www.tianqi.com/province/shandong/' # 打开网页
driver.get(url)
content = driver.page_source
list = driver.find_elements_by_xpath("/html/body/div[7]/div[1]/div[5]/ul") # 山东数据
result = list[0].text.split("\n")
driver.close()
return result
def shandong_data(result): # 爬取山东数据并分离
city = []
temp = []
weather = []
max_temp = []
min_temp = []
a = 2
for i in result: # 求出每个城市的天气
a += 1
# print(i)
# print(a)
b = (a % 4)
if (b == 0):
# print(i)
weather.append(i)
a = 3
for i in result: # 求出山东的城市
a += 1
# print(i)
# print(a)
b = (a % 4)
if (b == 0):
# print(i)
city.append(i)
for i in result: # 求出每个城市的温度
tem = re.findall('\d{2} ~ \d{2}℃', i)
# print(tem)
if tem == []:
del tem
else:
for iii in tem:
temp.append(iii)
for i in temp: # 求出温度的最大值和最小值
t = 0
# print(i)
z = re.findall("\d{2}", i)
# print(z[0])
min_temp.append(z[0])
max_temp.append(z[1])
return city, temp, weather, max_temp, min_temp
def shandong_Parallel(city, max_temp, min_temp):
parallel = pyecharts.Parallel("高低温度的平行坐标系图", "2021-7-13", width=1200,
height=600)
parallel.config(city)
parallel.add("高低温", [max_temp, min_temp], is_random=True)
parallel.render('C:\\Users\\dupeibo\\Desktop\\山东温度分析.html')
def jinan_to_sql(weather, temp, data):
# result = spider_jinan()
# weather, temp, data = spider_res_jinan(result)
results = pd.DataFrame()
res = pd.Series()
res["weather"] = pd.Series(weather)
res["temp"] = pd.Series(temp)
res["data"] = pd.Series(data)
results.insert(0, '天气', res["weather"])
results.insert(0, '温度', res["temp"])
results.insert(0, '日期', res["data"])
# print(results)
conn = create_engine('mysql+pymysql://root:dpb238031@localhost:3306/weather?charset=utf8')
sql = 'select * from runoob_tbl'
rub = pd.read_sql(sql, conn)
results.to_sql(name='jinan_weather', con=conn, if_exists='append', index=True)
def shandong_to_sql(city, weather, min_temp, max_temp):
# result = spider_shandong()
# city, temp, weather, max_temp, min_temp = shandong_data(result)
results = pd.DataFrame()
res = pd.Series()
res["city"] = pd.Series(city)
res["weather"] = pd.Series(weather)
res["max_temp"] = pd.Series(max_temp)
res["min_temp"] = pd.Series(min_temp)
results.insert(0, '城市', res["city"])
results.insert(0, '天气', res["weather"])
results.insert(0, '最低温', res["min_temp"])
results.insert(0, '最高温', res["max_temp"])
conn = create_engine('mysql+pymysql://root:dpb238031@localhost:3306/weather?charset=utf8')
# sql = 'select * from runoob_tbl'
# rub = pd.read_sql(sql, conn)
results.to_sql(name='shandong_weather', con=conn, if_exists='append', index=False)
def audio(exam, weather, temp, month, day):
# put = input("请输入要查看的信息,例如:今天,明天,后天")
if exam == "今天":
pt = pyttsx3.init()
pt.say("今天是:" + month[0] + "月" + day[1] + "日\n\n" + "今天的天气是\n" + weather[0] + "\n\n今天的气温是" + temp[0])
pt.runAndWait()
# print("天气:" + weather[0] + " ,温度为:" + temp[0] + " ,日期:" + data[0])
elif exam == "明天":
pt = pyttsx3.init()
pt.say("明天是:" + month[1] + "月" + day[1] + "日\n\n" + "明天的天气是\n" + weather[1] + "\n\n明天的气温是" + temp[1])
pt.runAndWait()
elif exam == "后天":
pt = pyttsx3.init()
pt.say("后天是:" + month[2] + "月" + day[1] + "日\n\n" + "后天的天气是\n" + weather[2] + "\n\n后天的气温是" + temp[2])
pt.runAndWait()
elif exam == "大后天":
pt = pyttsx3.init()
pt.say("大后天是:" + month[3] + "月" + day[1] + "日\n\n" + "大后天的天气是\n" + weather[3] + "\n\n大后天的气温是" + temp[3])
pt.runAndWait()
framerate = 16000 # 采样率
num_samples = 2000 # 采样点
channels = 1 # 声道
sampwidth = 2 # 采样宽度2bytes
FILEPATH = 'speech.wav'
base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
APIKey = "注册的APIKey"
SecretKey = "注册的SecretKey"
HOST = base_url % (APIKey, SecretKey)
def getToken(host):
res = requests.post(host)
return res.json()['access_token']
def save_wave_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels) #声道数
wf.setsampwidth(sampwidth) #采样宽度2bytes
wf.setframerate(framerate) # 采样率
wf.writeframes(b''.join(data))
wf.close()
def my_record(): #录音函数
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels,
rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = []
# count = 0
t = time.time()
print('请讲话...')
while time.time() < t + 4: # 秒
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('录音结束.')
save_wave_file(FILEPATH, my_buf)
stream.close()
def get_audio(file):
with open(file, 'rb') as f:
data = f.read()
return data
def speech2text(speech_data, token, dev_pid=1537):
FORMAT = 'wav'
RATE = '16000'
CHANNEL = 1
CUID = '24422381'
SPEECH = base64.b64encode(speech_data).decode('utf-8')
data = {
'format': FORMAT,
'rate': RATE,
'channel': CHANNEL,
'cuid': CUID,
'len': len(speech_data),
'speech': SPEECH,
'token': token,
'dev_pid': dev_pid
}
url = 'https://vop.baidu.com/server_api'
headers = {
'Content-Type': 'application/json'}
# r=requests.post(url,data=json.dumps(data),headers=headers)
print('正在识别...')
r = requests.post(url, json=data, headers=headers)
Result = r.json()
if 'result' in Result:
return Result['result'][0]
else:
return Result
if __name__ == '__main__':
flag = '重新开始'
while flag.lower() == '重新开始':
print("您是要查看'济南天气'还是'山东所有城市的天气'?")
pt = pyttsx3.init()
pt.say("您是要查看济南天气还是山东所有城市的天气?")
pt.runAndWait()
sleep(2)
# print('请输入数字选择语言:')
# devpid = input('1536:普通话(简单英文),1537:普通话(有标点),1737:英语,1637:粤语,1837:四川话\n')
my_record()
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
result = speech2text(speech, TOKEN, int(1536))
sleep(2)
print("识别结果:" + result)
print("开始收集数据....")
sleep(2)
# abc = "返回上一级"
if result == "济南天气":
# while abc == "返回上一级":
result = spider_jinan()
weather, temp, data, month, day = spider_res_jinan(result)
mean__temp = mean_temp_jinan(temp)
print("目前有的功能\n\n查看最近天气\n查看未来30天的温度\n画出天气词云\n平均温度折线图\n保存数据\n查看未来天气类型\n将数据存入数据库\n\n请选择你要使用的功能")
# print("查看最近天气\n查看未来30天的温度\n画出天气词云\n画平均温度折线图\n保存数据\n画出柱状图")
pt = pyttsx3.init()
pt.say("\n\n\n\n\n\n\n目前有的功能\n\n查看最近天气\n查看未来30天的温度\n画出天气词云\n平均温度折线图\n保存数据\n查看未来天气类型\n将数据存入数据库\n\n请选择你要使用的功能")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
func = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + func)
sleep(2)
# func = input()
if func == "查看最近天气":
# exam = input("请输入要查看的信息,例如:今天,明天,后天,大后天")
print("请输入要查看的信息,例如:今天,明天,后天,大后天")
pt = pyttsx3.init()
pt.say("请输入要查看的信息,例如:今天,明天,后天,大后天")
pt.runAndWait()
my_record()
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
apple = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + apple)
audio(apple, weather, temp, month, day)
pt1 = pyttsx3.init()
print("重新开始还是退出?")
pt1.say("是否重新开始还是退出?")
pt1.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "查看未来三十天的温度":
mean__temp = mean_temp_jinan(temp)
plt_mean_temp_jinan(data, mean__temp)
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("是否重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "画出天气词云":
image_jinan(weather)
# os.system("E:\\code\\spider\\week8\\word_cloud\\bodies.png")
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("是否重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "平均温度折线图":
plt_mean_temp_jinan(data, mean__temp)
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "保存数据":
temp_to_csv(weather, temp, data)
# print("csv文件保存成功")
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "查看未来天气类型":
plt_fer_weather(weather)
os.system('C:\\Users\\dupeibo\\Desktop\\未来30天天气概况.html')
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif func == "将数据存入数据库":
jinan_to_sql(weather, temp, data)
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("数据库保存成功\n\n重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
# print("数据库保存成功")
elif result == "山东所有城市的天气":
result = spider_shandong()
city, temp, weather, max_temp, min_temp = shandong_data(result)
pt = pyttsx3.init()
sleep(3)
print("目前有的功能\n\n\n查看各城市天气状况\n将数据存入数据库")
pt.say("目前有的功能\n\n\n查看各城市天气状况\n将数据存入数据库")
pt.runAndWait()
my_record()
sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
fun2 = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + fun2)
if fun2 == "查看各城市天气状况":
# shandong_Parallel(city, max_temp, min_temp)
os.system("C:\\Users\\dupeibo\\Desktop\\山东温度分析.html")
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)
elif fun2 == "将数据存入数据库":
shandong_to_sql(city, weather, min_temp, max_temp)
pt = pyttsx3.init()
print("重新开始还是退出?")
pt.say("重新开始还是退出?")
pt.runAndWait()
my_record()
# sleep(2)
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
flag = speech2text(speech, TOKEN, int(1536))
print("识别结果:" + flag)