
近年来,数据驱动的深度学习在很多领域取得了成功,而训练数据规模不断增大的同时,也发展出了许多大规模的预训练模型,其中GPT-3等模型甚至可以达到千亿级别的参数量。但由于训练大模型对硬件的要求门槛较高,以往都是在拥有超大显存的显卡如A100的平台上进行训练,普通用户常常因为硬件条件的限制望而却步。
目前,工业界通常采用分布式训练来进行大规模模型的训练,如将输入的数据切片喂给不同的卡提升训练任务吞吐量,或将模型切片部署到多卡上实现模型并行;除此之外,也有将数据的batch再切分成mini-batch从而实现流水并行等方法。但这些并行需求对深度学习框架也带来了严峻挑战,主流深度学习框架对数据并行支持得非常好,对模型并行、流水并行的支持还比较有限。
为了让更多用户体验使用各大框架训练大规模模型的不同,在2021 CCF大数据与计算智能大赛上,作为大赛合作方,OneFlow在先进系统赛道提交了“基于BERT的大模型容量挑战赛”赛题,本赛题旨在基于有限的显存资源将BERT模型的参数量尽可能提升,从而模拟实际的场景下普通用户进行诸如GPT-3这种大规模模型的训练过程。参赛者可选择任一深度学习框架参赛。
欢迎各位开发者朋友报名切磋技艺,除了5万元单赛题奖金,还有CCF综合奖金等你来瓜分,获奖者还将获得CCF颁发的证书。
1、单赛题奖

注:单赛题奖特指本赛题奖金。以上奖金为税前奖金。
2、CCF综合奖
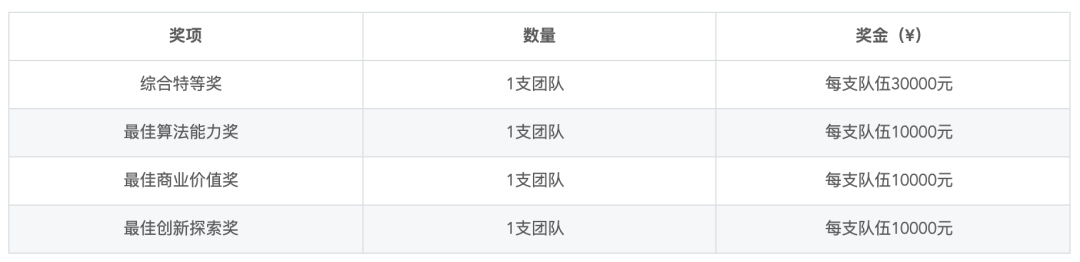
注:以上奖金为税前奖金。
3、权威证书
单赛题奖一二三等奖,及CCF特别奖获奖团队,都可以获得由中国计算机学会颁发的权威纸质证书。参赛者在初赛中成功提交作品,在初赛结束后均可获得电子证书。
CCF大数据与计算智能大赛(CCF Big Data & Computing Intelligence Contest,简称CCF BDCI)由中国计算机学会于2013年创办。大赛由国家自然科学基金委员会指导,是大数据与人工智能领域的算法、应用和系统大型挑战赛事。自2021年9月16日第九届CCF BDCI大赛首批赛题上线以来,选手报名十分踊跃,参赛竞逐也异常激烈。短短两周内,首批上线的13道赛题已吸引5017人报名、组建赛队4127支,聚合了来自全国各地、百余家企事业单位及科研院所的优秀人才。
1
赛题详情
1、赛题名称
基于BERT的大模型容量挑战赛
2、技术方向
智能算法、性能优化
3、赛题背景
本赛题旨在基于有限的显存资源将BERT模型的参数量尽可能提升,从而模拟实际的场景下普通用户进行诸如GPT-3这种大规模模型的训练过程。参赛者需要在系统层面上进行优化使得可以进行参数量尽可能多的大模型的训练。参赛者最终需要提交一个BERT的实现模型,通过提高隐含层参数量(hidden size)提升模型的参数量,并在基于保证参数量的基础上尽可能提升系统的吞吐率。
3、赛题任务
基于BERT的原始paper(https://arxiv.org/abs/1810.04805)使用TensorFlow、PyTorch和Oneflow三个主流深度学习框架之一进行 BERT Large 模型的实现,并通过修改隐含层参数量(hidden size)增加其参数量,用来模拟普通用户利用显卡训练诸如 GPT-3 这种大模型的场景。参赛者在固定 batch_size=2的输入参数以及 BERT Large 模型其它参数的前提下,通过调大 hidden_size 参数来增大模型的总参数对单机多卡的分布式训练调优,使得在相同的硬件资源限制下能够运行更大 hidden_size 参数模型的训练。
参赛者需要将实例化的模型置于 GPU 上,并基于 BERT 模型进行分布式训练方面的改进(常用的技术包括数据并行、模型并行、ZeRO 和流水并行等)。参赛者的模型禁止使用 fp16 混合精度训练以及模型集成,最多可以在 2 卡上对模型进行训练,每张卡显存占用不超过 12G。
各框架的 BERT 实现 baseline 链接如下:
Pytorch:
https://github.com/tea321000/hugging_face_competition
Oneflow:
https://github.com/Oneflow-Inc/models/tree/bert_competition_baseline_graph/bert-oneflow
参赛者也可以使用其它框架进行实现,但需要保证模型结构以及dataloader与已有的baseline进行对齐。
2
赛题赛程
大赛正式赛共计4个月,采用初赛、决赛、总决赛“三级赛制”,具体赛程安排如下:
2021/09/16-2021/11/22,大赛初赛(线上)
(1)2021/09/27,发布大赛赛题,开放正式赛报名
(2)2021/10/11-2021/11/22,初赛阶段,开放数据下载,可提交作品并参与测评
2021/11/23-2021/12/5 大赛决赛(线上)
(1)2021/11/23-2021/12/03,对作品代码、反作弊情况审核,复现成绩
(2)2021/12/04-2021/12/05,决赛答辩评审
2021/12中旬,大赛总决赛(线下)
(1)2021/12中旬,举办大赛总决赛评审、颁奖典礼等系列活动
3
提交要求
参赛者需基于给出的baseline或其它框架进行实现,通过增大hidden_size参数模拟实际场景下的大模型训练,通过分布式训练系统的优化使得同样的硬件资源下可以训练更大的模型。
参赛者在平时的开发调试过程中,可以使用脚本在本地进行参数量和吞吐量的离线评测,以对上传模型的指标有相应的预期。在本地的算法开发阶段完成后,需要提供模型的权重、源码和对应的实现文档,并以压缩包的形式一并上传。
注意:
(1)初赛期间,参赛团队每日最多在竞赛平台提交1次作品,各队作品由队长进行统一提交,上传文件大小需低于300MB,最终成绩以初赛阶段最高一次提交成绩为准;
(2)出题方将定期进行测评,具体阶段性排行榜分数请关注大赛官方平台。
4
评测标准
我们选取hidden size和吞吐率(throughput)作为我们的排名依据。对提交的结果首先综合评估其参数量的有效性,当hidden size为提交的结果中最大值时且提交结果有效时,设为当前榜单的最高位次;当hidden size与已有的有效结果相同时,则分别计算其吞吐率,吞吐率高者位次靠前。榜单会公布每个有效提交结果的hidden size和吞吐率。吞吐率的计算公式如下:
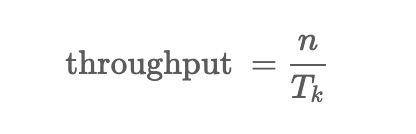
其中,n表示处理的样本数量,Tk表示处理个样本的时间。
总分数为:
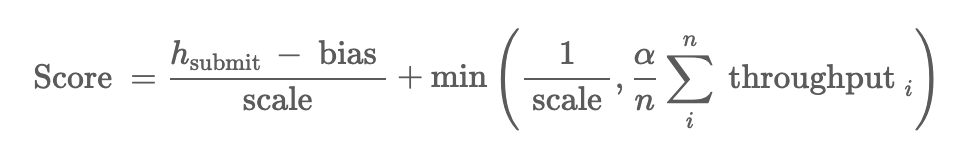
总分数由参 赛者提 交的 hidden_size hsubmit 归一化后的结果以及吞吐率throughput两个部分组成。
当 hidden_size 不相同时,提交的hidden_size越大分数越高;hidden_size 相同的情况下,则吞吐率越高分数越高。计算的实际吞吐率为按评测时间长度去掉启动时间后平均分成n段,程序在这n段时间计算的吞吐率取平均。
此外,评测平台的评测流程如下:
1、用户提交相应的压缩包到参赛平台上,上传成功后处于参赛平台的等待队列中;
2、评测方不定期从参赛平台的等待队列中拉取参赛者上传的压缩包到评测平台并进行评测,根据比赛的时间等因素在最长一周内完成评测并返回结果。
由于要保持评测平台硬件的统一以及评测的公平性,评测的机器数量并不是越多越好,因此会有一定的延迟,请参赛者耐心等待。
欢迎赛事交流微信群探讨:

看了赛题和相关信息,有没有想大显身手的冲动?欢迎开发者个人或组队报名参与,瓜分奖金。点击阅读原文报名参赛。
题图源自Pixabay, PagDev