文章目录
1 Elasticsearch
1.1 Elasticsearch简介
应用开发中一个比较常见的功能是搜索,传统应用的解决方案:数据库的模糊查询。模糊查询存在的问题:
- 海量数据下效率低下
- 功能不够丰富:不够智能、不能高亮
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。能够在海量的结构化和非结构化的数据中进行快速搜索,帮助我们完成诸如 订单搜索、商品推荐、日志分析、性能监控 等功能。
和Elasticsearch类似的产品还有Apache组织开源的Solr ,Solr和Elasticsearch都是基于Lucene这个Java类库二次开发而成的框架。Solr在功能性、传统搜索应用方面的表现更好,Elasticsearch则在新兴的实时搜索表现更佳。Solr的发展一直都比较平稳,近些年来呈现渐渐的下降趋势,而Elasticsearch则呈现明显上升的趋势。
Elasticsearch的特点:
- Elasticsearch是基于Lucene(Java全文检索工具)的开发的搜索引擎
- Elasticsearch支持分布式,多用户访问,可以轻松的扩展到上百台服务器
- Elasticsearch是近实时的不是实时的搜索引擎,简单说插入一条新数据后并不能保证立刻搜索到,但保证在1s内一定可以搜索到
- Elasticsearch通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
- Elasticsearch使用JSON格式存储数据
1.2 Elasticsearch的安装
克隆一个安装好jdk环境的linux系统
- 修改配置文件limits.conf
vi /etc/security/limits.conf
在最后一行添加下面内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096 - 修改sysctl.conf
vi /etc/sysctl.conf
最后一行添加
vm.max_map_count=262144
运行该命令让sysctl生效
sysctl -p - 把es安装包上传到opt文件夹里面进行解压,tar -zxvf elasticsearch-6.4.1.tar.gz
- 修改es的配置文件允许远程访问
[root@localhost config]# vi elasticsearch.yml
将55行
#network.host: 192.168.0.1
改为:
network.host: 0.0.0.0
注意去除前面的# - 尝试启动es:
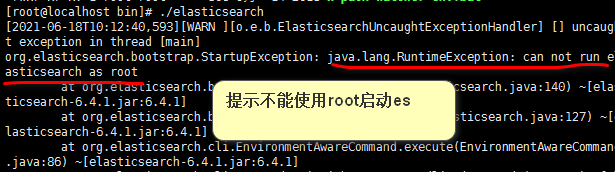
- es不能使用root用户启动。我们需要添加其他用户。
- 添加es用户,修改es文件夹的所属用户为es,elasticsearch不能使用root用户启动


所以我们需要通过linux的权限命令对文件夹进行修改所属用户。
7 使用es用户登录到linux里面,启动es

2 Elasticsearch起步
2.1 REST 回顾
REST(Resource Representational State Transfer)资源在网络传输中以某种表现形式进行状态转移。
REST风格的URI:
- 面向资源
- 通过HTTP的请求方式对资源进行操作
HTTP请求方式:
- GET 对资源的查询
- POST 对资源的新增(或者更新)
- PUT 对资源的更新(或者新增)
- DELETE 对资源的删除
2.2 RESTful API操作Elasticsearch
Elasticsearch数据相关的概念:
- 文档:json格式的数据,类似关系型数据库的一行数据。每个文档都会有唯一的id,可以由es生成,也可以由程序员指定
- 字段:每一个文档中的数据字段就相当于关系型数据库中一行的列
- 类型:Elasticsearch中保存数据的容器,类似于MySQL中的表
- 索引:保存有类型,类似于mysql的数据库。

为方便大家前期对Elasticsearch的数据有一个大体的认识,可以类比关系型数据库的一些概念,但注意2者之间有本质差别不可等价齐观。
2.3 创建和删除索引
创建索引和类型:
PUT /索引名
{
"mappings":{
"类型名":{
"properties":{
"字段名":{
"type":"字段类型"
},
"字段名":{
"type":"字段类型"
}
}
}
}
}
文档中字段的类型:
字符串:keyword,text
数值类型:long,integer,short,byte,double,float
布尔:boolean
日期:date
二进制:binary
案例:
PUT http://192.168.132.109:9200/dang
{
"mappings":{
"book":{
"properties":{
"name":{
"type":"text
},
"price":{
"type":"double"
}
}
}
}
}
查看索引:
查看索引:
#查看索引
GET /索引名/_mappings
示例:
GET http://192.168.146.40:9200/dang/_mappings
结果:
{
"dang": {
"mappings": {
"book": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "double"
}
}
}
}
}
}
删除索引:
#删除索引
DELETE /索引名
示例:
DELETE http://192.168.132.108:9200/dang
#删除所有索引
DELETE http://192.168.132.108:9200/*
结果:
{
"acknowledged": true
}
2.4 操作文档
-
添加文档
操作:
示例:
POST http://192.168.232.109:9200/dangdang/news/2{ "title":"新闻标题2", "content":"新闻内容2" } 其中id也可以不添加,系统会自动给我们创建一个id值结果:
#由es分配id
{
“_index”: “dangdang”,
“_type”: “news”,
“_id”: “z1sqAXgBNdZS7uufAQRX”,
“_version”: 1,
“result”: “created”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 0,
“_primary_term”: 1
}#指定文档的id { "_index": "dangdang", "_type": "news", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 } -
查询文档
操作:
#查看文档(数据):
GET /索引/类型/id值示例: GET http://192.168.232.109:9200/dangdang/news/_search 查看全部 GET http://192.168.232.109:9200/dangdang/news/1 查看id为1的数据结果:
#查询全部
{
“took”: 5,
“timed_out”: false,
“_shards”: {
“total”: 5,
“successful”: 5,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: 2,
“max_score”: 1.0,
“hits”: [
{
“_index”: “dangdang”,
“_type”: “news”,
“_id”: “z1sqAXgBNdZS7uufAQRX”,
“_score”: 1.0,
“_source”: {
“title”: “新闻标题3”,
“content”: “新闻内容3”
}
},
{
“_index”: “dangdang”,
“_type”: “news”,
“_id”: “2”,
“_score”: 1.0,
“_source”: {
“title”: “222”,
“content”: “2222”
}
}
]
}
}#根据 id 查询 { "_index": "dangdang", "_type": "news", "_id": "2", "_version": 2, "found": true, "_source": { "title": "222", "content": "2222" } } -
删除文档
操作:
#删除文档(数据):
DELETE /索引/类型/id示例: DELETE http://192.168.232.109:9200/dangdang/news/1结果:
{
“_index”: “dangdang”,
“_type”: “news”,
“_id”: “_doc”,
“_version”: 2,
“result”: “deleted”,//删除成功
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 2,
“_primary_term”: 1
} -
更新文档
操作:
#更新文档
POST /索引/类型/id
{
“title”:“222”,
“content”:“2222”
}示例: POST http://192.168.232.109:9200/dangdang/news/2 { "title":"222", "content":"2222" }
2.5 Elasticsearch的其他命令
查看es里面现存的所有索引
GET http://192.168.232.109:9200/_cat/indices?v
结果:
health status index uuid pri rep docs.count docs.deleted store.size
yellow open dangdang siHMxmNyTqyzm8pyhVghVg 5 1 2 0 7.8kb
索引、类型、映射这些组成可以由ES通过文档反推,也可以主动创建。在我们不创建索引和类型的情况下也可以直接插入文档数据。
在没有es1和book的情况下我们可以插入一个文档。
POST http://192.168.232.109:9200/es1/book/1
{
"name":"aa",
"price":200
}
3 批量操作
3.1 批量写 _bulk
Bulk API支持在一次请求中,可以对任意的索引执行多种不同的写操作。
语法:
PUT /_bulk
{操作类型以及操作的索引 类型 文档id信息}
{操作用到的数据}
{操作类型以及操作的索引 类型 文档id信息}
{操作用到的数据}
...
操作类型: index和create都是创建,区别是如果相同id的文档存在,index会覆盖,create会报错
update:更新
delete:删除
示例
PUT http://192.168.146.40:9200/_bulk
{"index":{"_index":"dangdang","_type":"book","_id":"1"}}
{"bookName":"红楼梦","author":"曹雪芹","price":19800.0}
{"update":{"_index":"dangdang","_type":"book","_id":"1"}}
{"doc":{"price":"1980.0"}}
{"create":{"_index":"dangdang","_type":"book","_id":"2"}}
{"bookName":"水浒传","author":"施耐庵"}
{"delete":{"_index":"dangdang","_type":"book","_id":"3"}}
//注意最后必须添加一个空行
注意:
- json数据不能主动换行,必须写成一行
- 多个json间必须要换行
- 在文件中json串最后一行下方必须再有一个空行
扩展:
如果在URI路径上指定了索引和类型,那么操作时json串中的条件可以省略对应的值,上面的操作也可以写成如下所示:
PUT http://192.168.146.40:9200/dangdang/book/_bulk
{"index":{"_id":"1"}}
{"bookName":"红楼梦","author":"曹雪芹","price":19800.0}
{"index":{"_id":"1"}}
{"doc":{"price":"1980.0"}}
{"create":{"_id":"2"}}
{"bookName":"水浒传","author":"施耐庵"}
{"delete":{"_id":"3"}}
操作中单条操作的失败,不会影响其它操作。返回结果中包含了每一条操作的结果。
3.2 批量读取_mget
可以一次性的查询多个数据,减少网络连接产生的开销,提高性能。
#批量获取
GET /_mget
{
"docs":[
{索引 类型 等信息},
...
]
}
示例:
GET http://192.168.146.40:9200/_mget
{
"docs":[
{"_index":"dangdang",
"_type":"book",
"_id":1
},
{
"_index":"dangdang",
"_type":"book",
"_id":2
}
]
}
如果在URI路径上指定了索引和类型,那么操作时json串中的条件可以省略对应的值,上面的操作也可以写成如下所示:
GET http://192.168.146.40:9200/dangdang/book/_mget
{
"docs":[
{"_id":1},
{"_id":2}
]
}
4 Elasticsearch高级检索DSL检索
准备测试数据:
#删除索引
DELETE /ems
#添加索引并设置类型
PUT /ems
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy/MM/dd HH:mm:ss|| yyyy/MM/dd ||epoch_millis"
},
"content":{
"type":"text"
},
"address":{
"type":"keyword"
}
}
}
}
}
PUT /ems/emp/_bulk
{"index":{}}
{"name":"小黑","age":23,"bir":"2012-12-12","content":"为开发团队选择一款优秀的MVC框架是件难难事,在众多可行的方案中决择需要很高的经验和水平","address":"北京"}
{"index":{}}
{"name":"王小黑","age":24,"bir":"2012-12-12","content":"Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在心容器之上,核心容器定义了创建、配置和管理 bean 的方式。为了测试添加一个内容北京","address":"上海"}
{"index":{}}
{"name":"张小五","age":8,"bir":"2012-12-12","content":"SpringCloud作为Java语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。SpringCloud的组件非常多,涉及微服务的方方面面,并在开源社区Spring 和Netflix、Pivotal 两大公司的推动下越来越完善","address":"无锡"}
{"index":{}}
{"name":"win7","age":9,"bir":"2012-12-12","content":"Spring的目标是致力于全方位的简化Java开发。 这势必引出更多的解释,Spring是如何简化Java开发的?","address":"南京"}
{"index":{}}
{"name":"梅超风","age":43,"bir":"2012-12-12","content":"Redis一个开源的使 用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API","address":"杭州"}
{"index":{}}
{"name":"张无忌","age":59,"bir":"2012-12-12","content":"ElasticSearch是一个 基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","address":"北京"}
4.1 快速入门
#简单示例:查询所有并排序
GET /ems/emp/_search
{
"query":{"match_all":{}},
"sort":[
{"age":{"order": "desc"}}
]
}
JSON请求体中的属性有不同的作用,这些属性都是Elasticsearch中定义好的。
4.2 语法
GET /索引/类型/_search
{
"query":{},//设定查询规则
"from":number,//搜索展示数据的起始下标
"size":number,//搜索出的数据的条数
"sort":[],//设定排序规则
"_source":[],//设定返回的字段
"highlight":{}//高亮显示
}
4.3 from和size (分页查询)
form和size等同于MySQL中limit后的2个数值,借助这2个属性可以完成分页。
GET /ems/emp/_search
{
"query":{"match_all":{}},
"from":3,
"size":3,
"sort":[
{"age":{"order": "desc"}}
]
}
4.4 sort(排序)
sort属性值是一个数组,表示可以设定多个字段的排序
{
"sort":[
{"字段1":{"order":"asc|desc"}},
{"字段2":{"order":"asc|desc"}}
]
}
上述语法也可以简化如下:
{
"sort":[
{"字段1":"asc|desc"},
{"字段2":"asc|desc“}
]
}
示例:
GET /ems/emp/_search
{
"query":{"match_all":{}},
"sort":[
{"address":{"order":"desc"}},
{"age":{"order": "asc"}}
]
}
GET /ems/emp/_search
{
"query":{"match_all":{}},
"sort":[
{"address":"desc"},
{"age":"asc"}
]
}
4.5 _source(查询指定字段)
_source是一个数组,指定要显示的字段。
{
”_source":["字段名1","字段名2",...]
}
示例
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"_source":["name","age"]
}
4.6 query(查询规则)
query用于设置查询规则,Elasticsearch中有多种查询规则
{
"query":{
"match_all":{},//匹配所有
"match":{},//分词查询
"term":{},//关键字查询
"range":{},//范围查询
"prefix":{},//前缀查询
"wildcard":{},//通配符查询
"ids":{},//多id查询
"fuzzy":{},//模糊查询
"bool":{},//bool查询
"multi_match":{}//多字段查询
}
}
我们选几种常见的进行讲解
1 match(分词查询)
match 匹配查询,会对条件分词后查询
GET /ems/emp/_search
{
"query":{
"match":{
"content": "Redis Java"
}
}
}
2 term (关键字查询)
term 关键字: 用来使用关键词查询,不会对条件分词
GET /ems/emp/_search
{
"query":{
"term":{
"content": {
"value": "spring" //注意必须小写,会查询出有大写Spring的,如果查大写,查不出数据。
}
}
}
}
3 range(范围查询)
range 关键字: 用来指定查询指定范围内的文档
#范围查询
GET /ems/emp/_search
{
"query":{
"range":{
"age": {
"gte": 40,//greater than equals
"lt":80 //less than
}
}
}
}
4 ids(多id查询)
#多id查询
GET /ems/emp/_search
{
"query":{
"ids":{
"values":["zQEs8XIBA5ZUCKIvGWVY",
"zgEs8XIBA5ZUCKIvGWVY"]
}
}
}
5 bool(布尔查询)
#bool查询:bool查询用于合并多个查询条件
bool查询中有must、should、must_not3个关键字
must:相当于java中的&&,所有条件必须同时满足
should:相当于java中||,任一条件满足即可
must_not:相当于java中的!,取反操作
GET /ems/emp/_search
{
"query":{
"prefix":{
"address":{
"value":"北"
}
}
}
}
GET /ems/emp/_search
{
"query":{
"range":{
"age":{
"gte":40
}
}
}
}
must示例:
GET /ems/emp/_search
{
"query":{
"bool":{
"must":[
{
"prefix":{
"address":{
"value":"北"
}
}
},
{
"range":{
"age":{
"gte":40
}
}
}
]
}
}
}
should示例:
GET /ems/emp/_search
{
"query":{
"bool":{
"should":[
{
"prefix":{
"address":{
"value":"北"
}
}
},
{
"range":{
"age":{
"gte":40
}
}
}
]
}
}
}
must_not示例
GET /ems/emp/_search
{
"query":{
"bool":{
"must_not":[
{
"prefix":{
"address":{
"value":"北"
}
}
},
{
"range":{
"age":{
"gte":40
}
}
}
]
}
}
}
6 multi_match(多字段分词查询)
muli_match用于在多个字段中分词查询
#多字段查询
GET /ems/emp/_search
{
"query":{
"multi_match": {
"query": "张黑java",
"fields": ["name","content"]
}
}
}
7 highlight(高亮查询)
hightlight用于在查询关键字上添加样式,以达到高亮显示的效果。
GET /ems/emp/_search
{
"query":{
"multi_match":{
"query":"张黑java",
"fields": ["name","content"]
}
},
"highlight":{
"fields": {
"content":{},
"name":{}
},
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"]
}
}
5 IK分词器
hightlight用于在查询关键字上添加样式,以达到高亮显示的效果。
GET /ems/emp/_search
{
"query":{
"multi_match":{
"query":"张黑java",
"fields": ["name","content"]
}
},
"highlight":{
"fields": {
"content":{},
"name":{}
},
"pre_tags": ["<span style='color:red'>"],
"post_tags": ["</span>"]
}
}
2 IK分词器
索引库的工作机制

1 IK分词器介绍
Elasticsearch中采用标准分词器进行分词,这种方式并不适用于中文;要想在中文系统中使用es达到搜索效果,就需要添加中文分词器。
IK分词器:IK Analyzer是一个基于java的由google提供的中文分词工具包。 IK Analyzer 3.0特性 采用了特有的“正向迭代最细粒度切分算法“,具有50万字/秒的高速处理能力。 支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
2 IK分词器的安装
- 上传压缩包到/opt
- 解压缩文件到 elasticsearch/plugins
#使用yum安装unzip工具
[root@localhost opt]# yum install -y unzip
#解压缩分词器到 es/plugins/analysis-ik子文件夹下
[root@localhost opt]# unzip elasticsearch-analysis-ik-6.4.1.zip -d elasticsearch-6.4.1/plugins/analysis-ik - 重启es
[root@localhost bin]# ps -ef | grep elasticsearch
[root@localhost bin]# kill -9 进程id
IK分词器规则:
IK分词器提供了两种分词规则:ik_max_word和ik_smart。
-
ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合 -
ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”GET /_analyze
{
“analyzer”:“ik_max_word”,
“text”:“土地老儿我的金箍棒在哪”
}GET /_analyze
{
“analyzer”:“ik_smart”,
“text”:“土地老儿我的金箍棒在哪”
}GET /_analyze
{
“analyzer”: “ik_max_word”,
“text”:“中华人民共和国国歌”
}
GET /_analyze
{
“analyzer”: “ik_smart”,
“text”:“中华人民共和国国歌”
}GET /_analyze
{
“analyzer”: “ik_max_word”,
“text”:“SpringCloud作为Java语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。SpringCloud的组件非常多,涉及微服务的方方面面,并在开源社区Spring 和Netflix、Pivotal 两大公司的推动下越来越完善”
}GET /ems/emp/_search
{
“query”:{
“match”:{
“content”:“开发”
}
},
“highlight”:{
“fields”: {
“*”:{}
},
“pre_tags”: [""],
“post_tags”: [""]
}
}
3 IK分词器的使用
#删除索引
DELETE /ems
#添加索引并设置类型
PUT /ems
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date"
},
"content":{
"type":"text",
"analyzer":"ik_max_word", //指定创建倒排索引时需要用的分词策略
"search_analyzer":"ik_max_word" //指定根据该字段查询时需要用的分词策略
},
"address":{
"type":"keyword"
}
}
}
}
}
PUT /ems/emp/_bulk
{"index":{"_id":"3"}}
{"name":"小黑","age":23,"bir":"2012-12-12","content":"为开发团队选择一款优秀的MVC框架是件难难事,在众多可行的方案中决择需要很高的经验和水平","address":"北京"}
{"index":{"_id":"1"}}
{"name":"王小黑","age":24,"bir":"2012-12-12","content":"Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在心容器之上,核心容器定义了创建、配置和管理 bean 的方式。为了测试添加一个内容北京","address":"上海"}
{"index":{"_id":"2"}}
{"name":"张小五","age":8,"bir":"2012-12-12","content":"SpringCloud作为Java语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。SpringCloud的组件非常多,涉及微服务的方方面面,并在开源社区Spring 和Netflix、Pivotal 两大公司的推动下越来越完善","address":"无锡"}
{"index":{"_id":"5"}}
{"name":"win7","age":9,"bir":"2012-12-12","content":"Spring的目标是致力于全方位的简化Java开发。 这势必引出更多的解释,Spring是如何简化Java开发的?","address":"南京"}
{"index":{"_id":"4"}}
{"name":"梅超风","age":43,"bir":"2012-12-12","content":"Redis一个开源的使 用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API","address":"杭州"}
{"index":{"_id":"6"}}
{"name":"张无忌","age":59,"bir":"2012-12-12","content":"ElasticSearch是一个 基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","address":"北京"}
4 配置扩展词
IK支持自定义扩展词典和停用词典
扩展词典就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典
停用词典就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典
-
编辑 analysis-ik/config/IKAnalyzer.cfg.xml
IK Analyzer 扩展配置
ext_dict.dic
ext_stopwords.dic
新建ext_dict.dic和ext_stopwords.dic vi ext_dict.dic 等特 vi ext_stopwords.dic 特点 -
重启 elasticsearch
注意:新增扩展词后只对新添加数据有效。
POST /ems/emp
{"name":"赵小六","age":8,"bir":"2020-02-12","content":"SpringCloud作为Java语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。SpringCloud的组件非常多,涉及微服务的方方面面,并在开源社区Spring 和Netflix、Pivotal 两大公司的推动下越来越完善","address":"无锡"}
GET /ems/emp/_search
{
"query":{
"term":{
"content":{
"value":"等特"
}
}
}
}
GET /ems/emp/_search
{
"query":{
"term":{
"content":{
"value":"特点"
}
}
}
}
6 java操作ES
1.引入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.4.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.4.1</version>
</dependency>
2.创建工具类
package com.baizhi.util;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import java.net.InetAddress;
public class ESUtils {
public static TransportClient getClient(){
try {
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.132.108"), 9300));
return transportClient;
}catch (Exception e){
e.printStackTrace();
}
return null;
}
}
3.增删改查操作
1. 添加
//准备连接
TransportClient client = ESUtils.getClient();
//准备数据
Map map=new HashMap();
map.put("name","11");
map.put("price",22);
//执行插入
IndexResponse indexResponse = client.prepareIndex("es1", "book", "10")
.setSource(map).get();
System.out.println(indexResponse);
client.close();
2. 删除
//准备连接
TransportClient client = ESUtils.getClient();
//执行删除
DeleteResponse deleteResponse = client.prepareDelete("es1", "book", "10").get();
System.out.println(deleteResponse);
client.close();
3. 修改
//准备连接
TransportClient client = ESUtils.getClient();
//准备数据
Map map=new HashMap();
map.put("name","33");
map.put("price",22);
//执行修改
UpdateResponse updateResponse = client.prepareUpdate("es1", "book", "10")
.setDoc(map).get();
System.out.println(updateResponse);
client.close();
4. 查询
//准备连接
TransportClient client = ESUtils.getClient();
//执行查询
SearchResponse searchResponse = client.prepareSearch("ems").setTypes("emp")
.setQuery(QueryBuilders.multiMatchQuery("张黑java", "name", "content"))
.setFrom(2).setSize(3)
.addSort("age", SortOrder.ASC)
.get();
System.out.println(searchResponse);
client.close();
5. 高亮查询
//准备连接
TransportClient client = ESUtils.getClient();
//执行查询
SearchResponse searchResponse = client.prepareSearch("ems").setTypes("emp")
.setQuery(QueryBuilders.multiMatchQuery("java", "name", "content"))
//设置高亮查询
.highlighter(new HighlightBuilder().field("content").preTags("<span style='color:red'>").postTags("</span>"))
.get();
System.out.println(searchResponse);
SearchHits hits = searchResponse.getHits();
System.out.println("查询出数据条数:"+hits.totalHits);
for (SearchHit hit:hits){
//获取原始数据
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
System.out.println(sourceAsMap);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//获取高亮显示结果
HighlightField content = highlightFields.get("content");
if(content!=null){
Text fragment = content.fragments()[0];
System.out.println(fragment);
}
}
client.close();
7 springboot操作es
1. 引入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
</dependency>
2. 配置TransportClient
@Bean
public TransportClient getClient(){
try {
TransportClient transportClient = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.232.109"), 9300));
return transportClient;
}catch (Exception e){
e.printStackTrace();
}
return null;
}
3. 测试类注入client对象。
在需要使用java操作es的地方注入该对象。
@Autowired
private TransportClient client;