文章目录
BeautifulSoup find、findall()多级索引详解(附例题)
- BeautifulSoup库的安装:
命令行运行:
pip3 install beautifulsoup4
文章以以海南大学起点论坛为例
标准选择器
find_all()
find_all( name , attrs , recursive , text , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
常用参数:
- name:标签名,使用html标签名来索引
sb = soup.find_all('img')
- atters
可根据标签名、属性、内容查找文档。
使用双属性来查找元素:
content = html.find(attrs = {
'class':'p_opt','id':'card_1550_menu_content'})
注意find_all()方法返回的是一个列表!访问列表的内容需要使用下标:
content[n] #注意下标从0开始
而访问列表元素的下一级元素则使用:.contents[n]来访问(也是从0开始的)
content[n].contents[m] #注意下标从0开始
嵌套查询:
嵌套查询很常用:
扫描二维码关注公众号,回复:
13195276 查看本文章

例子:
ul = html.find_all('ul') #查找ul标签下的内容、嵌套选择
for li in ul:
print(li.find_all('li')) #打印多个ul中的每一个
find()
find(name, attrs, recursive, text, wargs)
find用法和findall一模一样,但是返回的是找到的第一个符合条件的内容输出。注意find()方法返回的不是列表,而是一个单个元素对象,想要访问该对象的子元素就直接使用.contents[n]即可,不需要再添加下表
上面的代码对应的冗余代码:
from bs4 import BeautifulSoup
import urllib
from urllib import request
url = 'http://www.ihain.cn/forum.php?mod=guide&view=newthread'
headers ={
}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'
req = request.Request(url,None,headers = headers)
response = request.urlopen(req)
# 获得response对象
html = BeautifulSoup(response,'html.parser')
多级索引:
这里我们以一个例子来讲解多级索引
查找目标:
列表中的“起点百事通文本”

对应的html:

我们通过索引来逐步得到我们想要的内容:
- 这里为什么要一步一步来呢? 因为很多网站的HTML的属性都是比较冗余的,无法一次精确就查找到元素,通过逐步索引我们可以缩小我们的抖索范围,达到精确索引的目的
先找到div,再找到第一个子元素ul:

div = html.find('div',id = 'nv')
找到ul标签,这里我直接用.contents[1]没有索引到,但是用[3]索引到了,可能原因是存在一些不可见元素,我们随机应变

print(div[0].contents[3],'\n') #ul
ul标签的子元素索引:

我们逐步寻找内容,找到我们想要的:
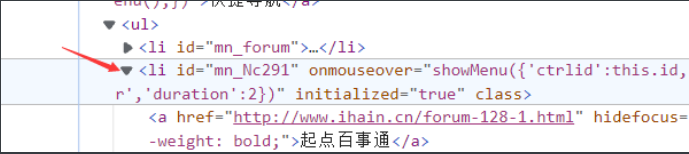
先找到ul下第二个子元素
print(div[0].contents[3].contents[1])#ul下的第二个li

再在ul下第二个子元素的第一个子元素确定a标签
print(div[0].contents[3].contents[1].contents[0])#ul下的第二个li下的第一个内容即<a>标签及其内容
找到文本:
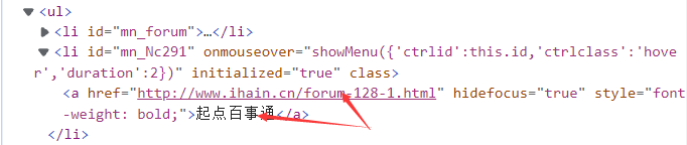
print(div[0].contents[3].contents[1].contents[0].text) #<a>的文本内容(起点百事通)
最终通过.get()方法获取标签中属性的链接
print(div[0].contents[3].contents[1].contents[0].get('href')) #对应的链接内容
上面代码对应的冗余代码:
from bs4 import BeautifulSoup
import urllib
from urllib import request
url = 'http://www.ihain.cn/forum.php?mod=guide&view=newthread'
headers ={
}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36 Edg/94.0.992.31'
req = request.Request(url,None,headers = headers)
response = request.urlopen(req)
# 获得response对象
html = BeautifulSoup(response,'html.parser')
至此 BeatifulSoup的find_all的查找基本上已经可以满足查找需求了 ,但是更方便查找的是Xpath等索引方式,这是另一种查找内容的方式,本篇不做介绍~