说下 MySQL 的 redo log 和 binlog?
(1)MySQL 分两层:Server 层和引擎层。区别如下:
Server 层:主要做的是 MySQL 功能层面的事情。Server 层也有自己的日志,称为 binlog(归档日志)
引擎层:负责存储相关的具体事宜。redo log 是 InnoDB 引擎特有的日志。
(2)redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
(3)redo log 是循环写的,空间固定会用完;
(4)binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
二、说说建立索引的优势、负面影响和原则?
(1)建立索引的优势
检索速度:快速访问表中的特定的信息,提高检索速度。
唯一性:创建唯一性索引,保证数据库中每一行数据的唯一性
加速连接:加速表和表之间的连接。
减少分组和排序的时间:使用分组和排序进行数据检索是,可以显著减少查询中分组和排序的时间。
(2)索引的缺点:
耗时:创建索引和维护索引需要耗费时间、这个时间是随着数据量增加和叠加的。
占空间:索引需要占用物理存储空间。
维护速度:对表的增、删、改的时候索引需要动态的维护,这样就降低了数据的维护速度。
(3)建立索引有那些原则
1) 选择唯一性高的字段建立索引
2)选择使用频率高的字段建立索引
3)尽量使用组合索引
MySQL索引的分类?
1、唯一索引(主键索引也是唯一索引的一种)
2、普通索引
3、组合索引
4、全文索引
索引的建立原则和使用原则
1)where子句中的列或者连接在指定的列
2)唯一索引保证数据的唯一性
3)不要过度使用索引
4) 索引遵循最左原则
说下 MySQL 覆盖索引?
概念:查询的数据列包含在一个索引中,那么称这类索引为覆盖索引,在mysql中,可以通过explain命令输出的Extra列来判断是否使用了覆盖索引,若使用了额覆盖索引查询,则Extra列包含“Using index”的字串。
优点:
1) 提高查询效率,只需要查索引二不需要回表查询。
索引的各种匹配原则
1)等值匹配原则
2)最左侧列匹配
3)最左前缀匹配原则
4)范围查找规则
5)等值匹配+范围匹配原则
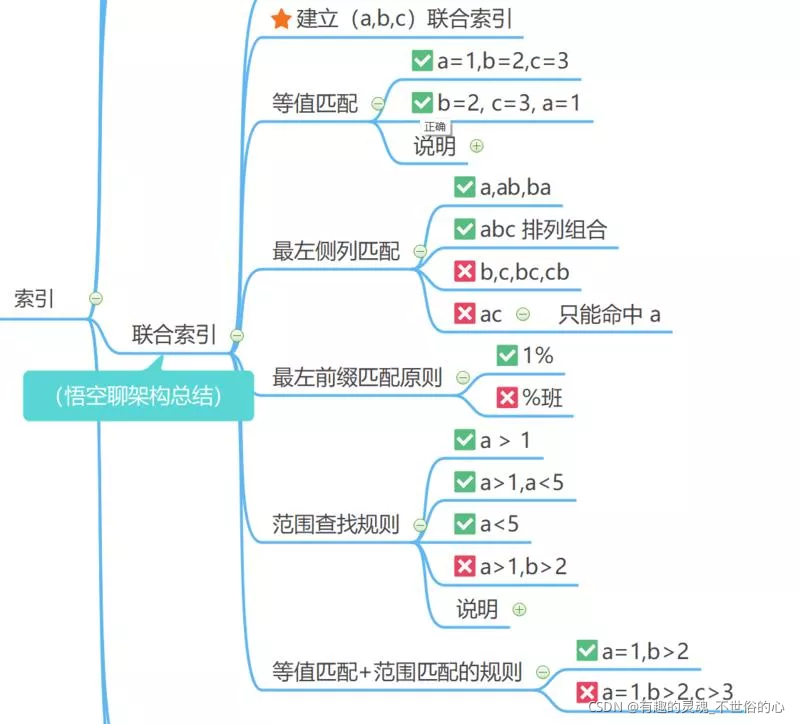
说下 MySQL 最左匹配原则知道吗?
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
比如有联合索引 [a、b、c],where 过滤条件中哪些排列组合可以用到索引?(比如这种:where a=xxx b=xxx and c=xxx)
以下排列组合都会走索引:a、ab、ac、ba、ca、abc、acb、bac、bca、cab、cba。必须有一个 a,排列组合中的顺序会被优化器优化,所以不用关心顺序。
以下排列组合不会走索引:b、c、bc、cb。因为没有 a。
关于范围查询:a=xxx and b<10 and b > 5 and c =xxx,c 字段用不到索引,因为 b 是一个范围查询,遇到范围查询就停止了。
最左匹配原则的原理:我们都知道索引的底层是一颗 B+ 树,那么联合索引当然还是一颗 B+ 树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的,如下图所示:
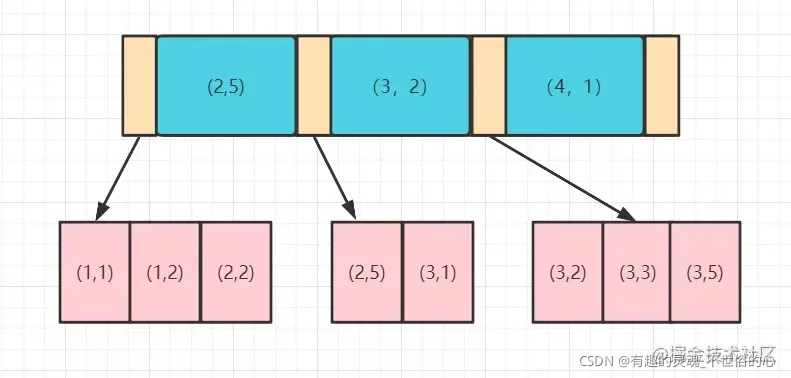
可以看到 a 的值是有顺序的,1,1,2,2,3,3,3,3。b 的值是没有顺序的1,2,2,5,1,2,3,5。
所以 b = 2 这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如 a=1 and b=2 a,b 字段都可以使用索引,因为在 a 值确定的情况下 b 是相对有序的,而 a>1 and b=2,a 字段可以匹配上索引,但 b 值不可以,因为a的值是一个范围,在这个范围中b是无序的。
说下执行计划?
在生产过程中,经常会遇到因为SQL语句导致的性能瓶颈问题,这时候就需要我们去优化SQL的执行效率;EXPLAIN语句的各个输出项指标可以帮助我们有针对性的提升查询语句的性能。
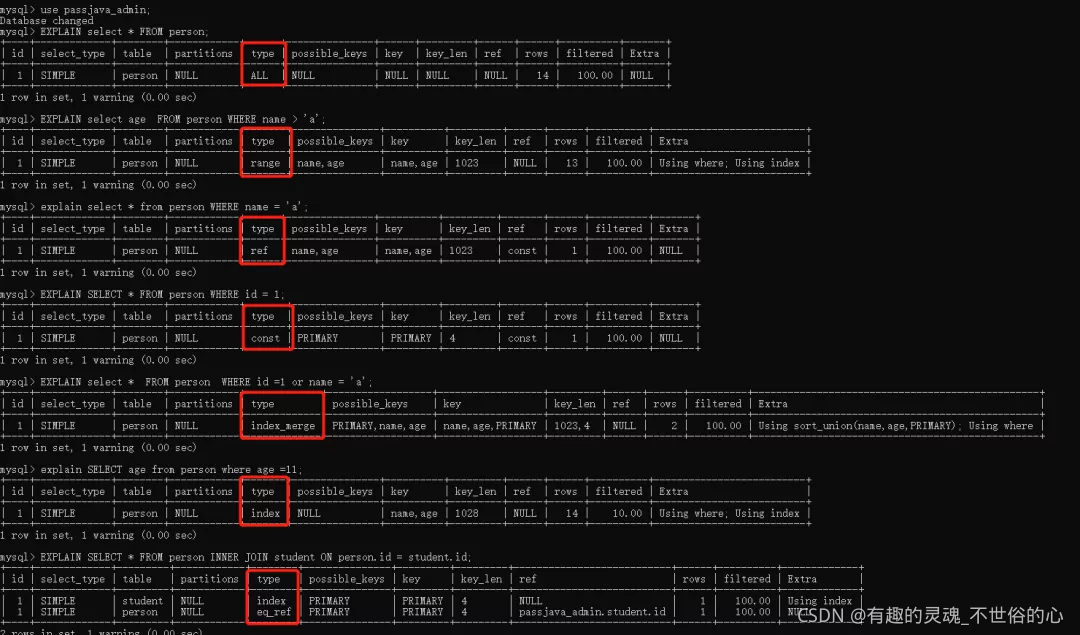
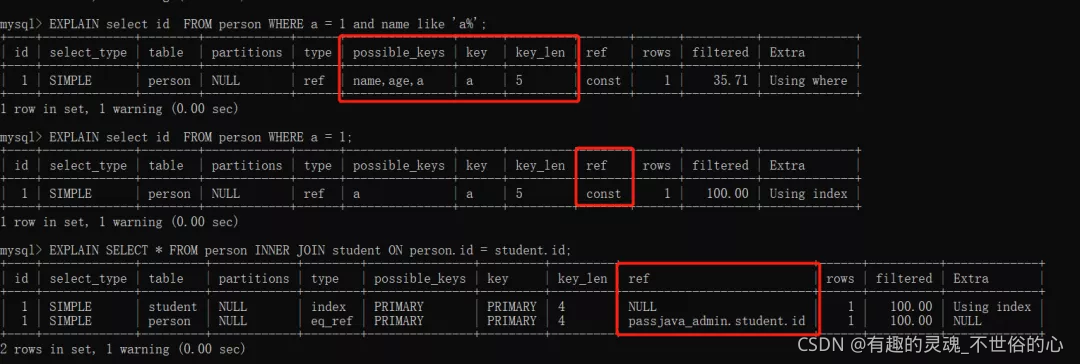
执行计划重要指标解释(id主键,name,age 联合索引, a 普通索引,b普通列):
type 字段 =>>
ALL - 最牛的优化结果这里就不展开介绍了
range - 索引范围查询;
ref - 二级索引等值查询;
const - 主键/唯一索引等值查询;
index_merge - 多个索引查询;
index - 覆盖索引且需要扫描全部的索引;
eq_ref - 被连接表主键/唯一引等值查询;
possible_keys 字段 =>> 可能用到的索引(备胎);
key 字段 =>> 实际用到的索引(转正);
key_len 字段 =>> 实际使用索引的最大长度
ref 字段 =>> 等值查询有一个常数/列值
const - 索引等值查询;
[DB].[table].[column] - 被调用表索引列等值查询;
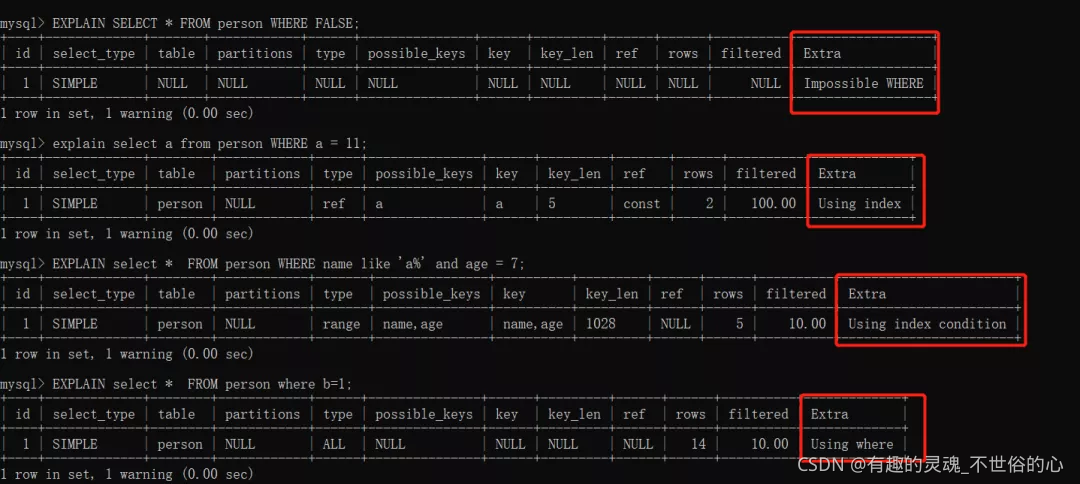
Extra字段 =>>
Impossible WHERE - where false;
Using index - 覆盖索引;
Using index condition - 索引下推;
Using where - 顺序扫描,where条件查询。
下面几张图说明了具体出现的场景:
说下主从复制原理?
1、master服务器将数据的改变记录到binlog中;
2、slave服务器会在一定时间间隔内对master 的binlog进行检查,如果发生改变,则开始一个I/OThread请求读取master中binlog;
3、同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒;
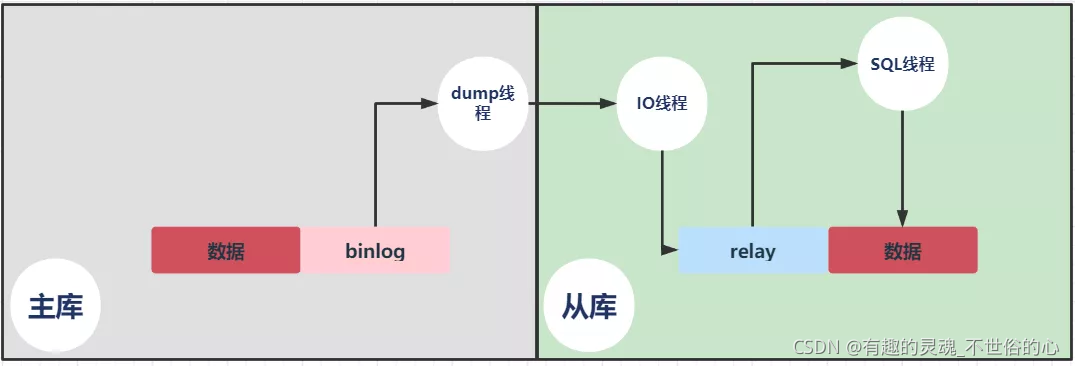
大白话解释:
从库会生成两个线程,一个I/O线程,一个SQL线程;
I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
主库会生成一个dump线程,用来给从库I/O线程传binlog;
SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
主从复制存在数据丢失问题的解决方案:在使用过程中需要开启半同步复制;
主从复制的使用场景主要有以下两种:HA、读写分离。
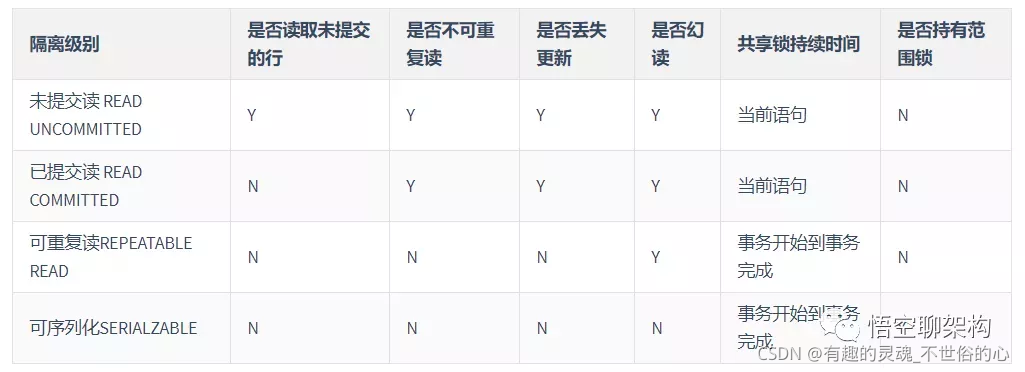
说下 SQL 标准的事务隔离级别?
读未提交(read uncommitted)是指,一个事务还没提交时,它做的变更就能被别的事务看到。
读提交(read committed)是指,一个事务提交之后,它做的变更才会被其他事务看到。
可重复读(repeatable read)是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
串行化(serializable ),顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
说说生成唯一 ID 的雪花算法是怎么样的?

1 bit:不用,统一为 0
41 bits:毫秒时间戳,可以表示 69 年的时间。
10 bits:5 bits 代表机房 id,5 个 bits 代表机器 id。最多代表 32 个机房,每个机房最多代表 32 台机器。
12 bits:同一毫秒内的 id,最多 4096 个不同 id,自增模式
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨(可以搜索 2017 年闰秒 7:59:60),会导致发号重复或者服务会处于不可用状态。