1、说说HashMap的结构
在JDK7时,采用数组+链表结构

在JDK8时,采用数组+链表+红黑树的结构,在一定条件下,链表会转化为红黑树。
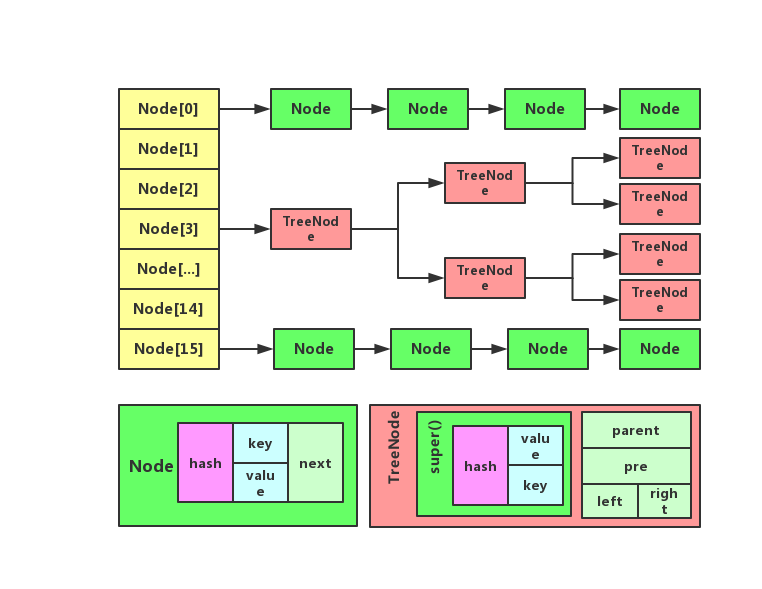
以上图来源于:https://blog.csdn.net/goosson/article/details/81029729
2、数组和链表的用处是什么
数组用来随机查找,能够根据hash值快速定位到Node的位置。
链表是用来解决hash冲突的,多个元素定位到同一个Node时,用链表将它们顺序串起来。
3、为什么要转红黑树
单链表的查询时间复杂度为O(n),因此当链表元素越来越多时,查询效率底下,因此在链表长度达到一个某一个值的情况下,链表会转化为红黑树,查询复杂度为O(logn)。
但是当链表元素少的时候,维护树的代价必然高于链表,因此不能一开始就直接使用红黑树。
4、什么条件下,链表会转化为红黑树,红黑树又会退化成链表
在某条链表的长度达到8时,先添加第9个元素,然后判断数组长度是否达到64。如果达到64,则进行链表转红黑树的操作。否则,仅仅只做扩容。(数组较小时,hash碰撞会比较频繁,导致链表长度过长。此时就应该先进行扩容,而不是立马树化。优先扩容可以避免一些不必要的树化)
当树中的元素经过一些删除操作变成6后,将会导致树退化成链表。中间有个过渡值7,可以防止频繁的树化与退化。
5、计算key的hash方法是怎么样的
hash方法的源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}首先需要理解>>>的含义,即无符号右移,高位补0。例如:
0111 1110 0000 1111 1011 0001 0101 1010
右移16位得到
0000 0000 0000 0000 0111 1110 0000 1111为什么要使用这个运算呢,直接返回key的哈希值不好吗?
一般来说,任意一个对象的哈希值比较大,随便实例化一个对象,得到它的hash值

转换成2进制后,得到
0011 1001 1010 0000 0101 0100 1010 0101而HashMap的长度一般就在[1,2^16]左右,取length=16为例,那么直接使用key的哈希值&(length-1)后,得到
0011 1001 1010 0000 0101 0100 1010 0101
&
0000 0000 0000 0000 0000 0000 0000 1111
---------------------------------------
0000 0000 0000 0000 0000 0000 0000 0101可见,运算后的结果对哈希值的高位无效,即如果两个不同对象的哈希值仅仅在高位上不一样的话,依然会存在哈希冲突的情况。因此,我们现在打算让运算后的结果对哈希值的高位以及低位都有效。
而对哈希值再次运算后,即使用key.hashCode()^ (h >>> 16)运算后,将哈希值的低16位异或了高16位,让高位与低位都影响到了对之后位置的选择上。
那为什么使用^异或呢,使用|以及&不好吗?
^能保证两个数都能影响到最终的结果,而|中只要一个为1,不管对方是多少,结果都为1,&也是同样的道理,有0则0。
区别两个细微对象的不同,就要深挖其细微之处。因此要在最大程度上避免哈希冲突,就越要使用到所有已知的特征,不能认为细微就没用。
6、为什么数组长度总是2的次幂
主要有两点原因:
提升计算效率,更快算出元素的位置
对于机器而言,位运算永远比取余运算快得多,在length为2的整数次方的情况下,hash(key)%length能被替换成高效的hash(key)&(length-1),两者的结果是相等的。
减少哈希碰撞,使得元素分布均匀
如果数组长度是2的整数次方时,也就是一个偶数,length-1就是一个奇数,奇数的二进制最后一位是1,因此不管hash(key)是多少,hash(key)&(length-1)的二进制最后一位可能是0,也可能是1,取决于hash(key)。即如果hash(key)是奇数的话,则映射到数组上第奇数个位置上。
如果length是一个奇数的话,length-1就是一个偶数,偶数的二进制最后一位是0,则不管hash(key)是奇数还是偶数,该元素都会被映射到数组上第偶数个位置上,奇数位置上没有任何元素!
因此,数组长度是一个2的整数次方时,哈希碰撞的概率起码能下降一半,而且所有元素也能均匀地分布在数组上。
具体原因可以移步到我的另外一篇文章为什么长度总是2的整数次方
7、在什么条件下进行扩容
首先,默认负载因子为0.75,默认容量为16,因此阈值=负载因子*容量=12
在JDK8中,插入第11个元素时,没达到阈值,不进行扩容。
插入第12个元素时,也不触发扩容。
插入第13个元素时,插入成功后,再进行扩容,扩容为原来的2倍长度。(尾插法)
而在JDK7中,准备插入第13个元素前,先进行扩容,再进行插入。(头插法)
8、扩容后元素的迁移机制
JDK7中,扩容后,需要重新计算所有元素的hash值,当然也有可能不计算。因为链表元素在迁移过程中,采用头插法,因此迁移完成后,新旧链表会出现倒置现象。
JDK8中,扩容后,不需要重新计算hash值,得益于hash寻址算法的优化。迁移过程中,采用尾插法,新旧链表不会倒置。
举个例子:首先JDK8中的寻址算法为:

其中hash是key.hashCode()高16位与低16位异或的结果,n为数组长度,即使用(n-1)与hash进行按位与得到元素的位置。
扩容前:n=16

则key1与key2由于hash冲突,会形成一个链表。
扩容后:n=32

数组长度变为原来的2倍,在计算上的表现,就是多出来一个高位参与按位与。
key1位置不变,而key2的hash值倒数第五位是1,因此按位与计算下来得到10101,而10101=10000+0101=原数组长度+原位置。
所以,不需要进行rehash。扩容后,只要判断hash值多出来的1bit是0还是1,0的话,则索引不变。1的话,新索引=原数组长度+旧索引。
看得出来,利用数组长度是2次方以及寻址算法的特点,扩容后不需要重新计算(n-1)&hash,而且让之前冲突的元素,由高位的不同重新散列到了其他位置上。
9、put过程是怎么样的
顺着源码走总是枯燥的,使用一张直观易懂的图来讲解put过程再合适不过
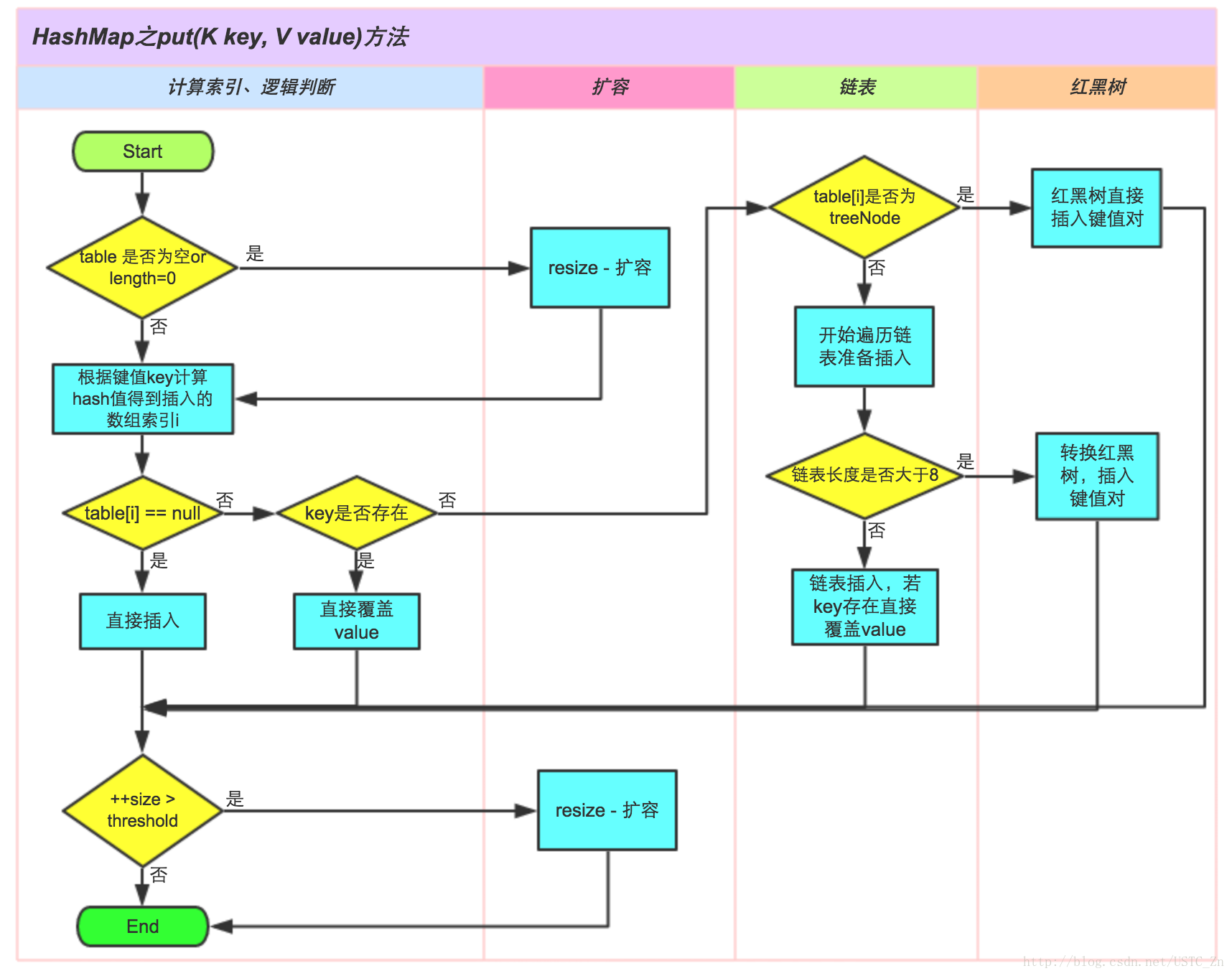
(图片来源于美团技术团队CSDN博客)
后续继续更新
(1)为什么JDK7采用头插法,而JDK8改成了尾插法
(2)谈谈对红黑树的认识
(3)线程安全的HashMap实现
(4)HashMap在JDK7与JDK8中的区别(至少4点)
......