
(相关资料均来自网络资源,相关书籍和论文,如有错误请批评指正)
上一篇我们介绍了互联网的发展历史,以及 Web2.0 面临的困境,本节我将着手介绍什么是 Web3.0,以及 Web3.0 面临的困境。
缘起语义网
事实上 Web3.0 的概念在 1998 年就被万维网的发明者 Tim Berners-Lee 提出过,不过一开始被称作语义网(并不是 Semantic Web),在他所描述的 Web3.0 中,其定义为更加智能的互联网,即人们希望通过人工智能来使得我们上网更加智能。事实上,就目前来看,我们的上网确实比以前更加智能了,比如精准的大数据画像,比如,你在 B 站看了一个类型的视频,那么当你再次刷新的时候,铺天盖地的都是相关的视频。再比如,你在 B 站搜索某个商品的视频,那很可能 B 站的广告,京东的广告,淘宝的广告就会在几秒钟之后推送相关的产品,等等如此。
而从一些更细的技术上来说,HTML5 新增的语义化标签也是属于 Tim Berners-Lee 的 Web3.0 的改进范畴。通过编程的语义标签,搜索引擎可以准确获取一个网页的核心信息,甚至包括移动端和 IoT 设备的信息。
Tim Berners-Lee 所愿景的 Web3.0 是一个人们能够访问任何网络资源(包括物联网生态下的硬件资源)的网络生态系统。然而这些基于人工智能和大数据算法的改进,并没有真正解决 Web2.0 时期的许多问题。所以在区块链迸发之前的时代,仅仅是基于人工智能和大数据等新一代信息技术的互联网并不能算得上 Web3.0.
区块链下的 Web3.0
在棱镜门事件之后,以太坊的联合创始人,也是现在 Polkadot 的创始人 Gavin 博士意识到,如今的互联网依旧存在很多的问题,于是 Gavin 提出了自己关于 Web3.0 的概念。
他描述了一个新一代更好的互联网:一个支付和资金为数字原生的互联网、一个”去中心化“应用程序与中心化应用程序竞争的互联网、一个用户能对自己的身份和数据有更多控制权的互联网。Gavin 特别指出了,我们不是试图取代现有的网络,而是在改变基础框架的同时保留我们喜欢的东西。
三个趋势
那么区块链下的 Web3.0 究竟与 Web2.0 有什么划时代的改进呢?
首先,货币将成为互联网的原生功能。我们现在的支付手段和方式,比如,支付宝,微信支付,paypal 等,都是互联网发展到了一定阶段,将支付这种方式从物理世界移植到了网络世界,当前支付手段本身仅仅是对互联网的扩展。而在未来,支付将成为互联网协议本身的一部分,比如,你可以随意的为你喜欢的 UP 投币(真实的货币),而不是 B 站根据 UP 情况,按时发放激励金。
其次,也是最重要的,那就是一些无需中心化的应用或者组织架构将变成去中心化的形式。很多人一直疑惑,明明中心化的系统运行的很好,为什么要选择去中心化呢?事实上,要维持一个中心化的系统,代价是非常高昂的,尤其是在一些本无需中心化的领域,通常需要花费大量的人力,物力去维持中心化系统。比如,很多互联网巨头每年花费巨额资金维护它们的服务器,但是反观比特币网络系统,仅仅依靠一个志愿者组织,就稳定运行了 12 年之久,且尚未出现任何大的问题。
最后,最引人注目的一点是用户将拥有更多的控制权。现在的网络世界,一方面,确实用户的信息被互联网巨头滥用(即使有法律,但实际上这仍是一个灰色地带),另一方面,各大公司确实通过这些数据提供了用户一些便利。而 Web3.0 旨在让用户拥有对自己数字隐私的更大控制权。
其实这个问题的两个重点在于,一,互联网公司不应该使用用户的任何隐私数据;二,互联网公司不应该无偿使用用户数据。
就第一点来说,比如一些交通类的互联网公司,一定程度上,它搜集我们的行程记录,这是无可厚非的,有了海量的用户的行程数据,可以通过算法为我们设计出更加合理的出行规划。但是对于一些应用来说,比如,它是一个记账的软件,但是却在安装 APP 的时候需要我提供我的通讯录,这无疑是一种对用户信息的长臂索取。甚至有些 APP 如果你不提供给它一些于 APP 无关的用户信息,它就不让你使用(虽然近些年国家法律在这方面正在完善,但实际上依旧有很多问题存在)。对于第二点来说,互联网公司将免费使用用户信息当做天经地义的事情,实际上这些巨头公司应该为用户隐私付费,或者说,在 Web3.0 时代,用户可以选择出售自己的一些低级别的隐私给互联网企业,以换取补偿。
语义网和区块链下的 Web3.0 的比较
| 语义网下的 Web3.0 | 区块链下的 Web3.0 |
|---|---|
| 无处不在:所有的设备都将连入网络中 | 统一身份认证系统:解决重复注册账号 |
| 人工智能:更加智能的网络 | 数据确权与授权:解决服务商滥用用户隐私数据 |
| 3D 图形:更好的视觉效果 | 隐私保护与抗审查:网络公司不能无偿使用用户数据盈利 |
| 无处不在:所有的设备都将连入网络中 | 去中心化运行:网络服务延续问题 |
Web3.0 的分层结构
这个结构是基于 Gavin 提出来的,但它并不一定是最终的结果,一切关于 Web3.0 都还在探索阶段。
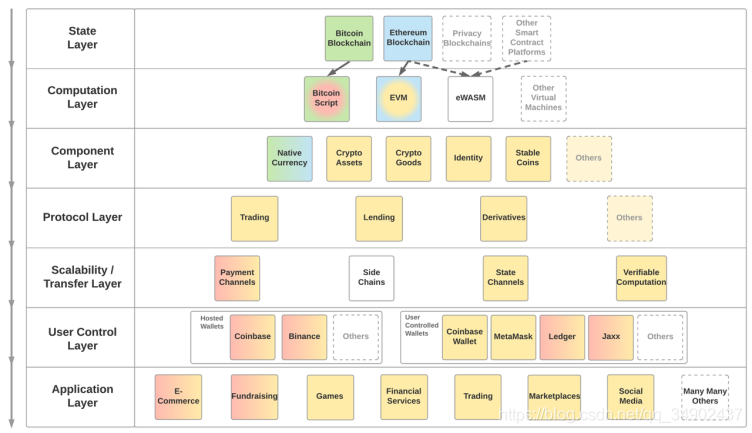
- 状态层几乎都是由相关的区块链基础设施独占提供的
- 计算层是人们向状态层下达指令的媒介。例如,比特币脚本的局限性就很高,基本上只能执行交易指令。而以太坊虚拟机(EVM)是图灵完备的,因此支持 EVM 的状态层可以执行任意复杂的计算
- 组件是搭建在计算层之上的,会重复使用标准化的智能合约模版。包括了,原生货币,密码学资产,数字商品,身份,稳定币
- 你在状态层上创建了组件之后,总归要让这些组件发挥作用。它们的生命周期需要依靠某些常见的基本函数来维持,因此这些函数正在实现标准化。目前各种各样的协议采用智能合约的形式
- 区块链在可扩展性上广受诟病。比特币区块链每秒交易量是 7 笔,以太坊区块链的每秒交易量是 15 笔。虽然区块链是否应该做出一些妥协,将每秒交易量增加至上千笔的问题引起了诸多争议,但是一个不争的事实是,通过不同的分层实现状态转移(也称为 Layer 2 扩展方案)需要状态层支持强健的拓扑结构
- 一直到用户控制层为止,普通的用户几乎不可能用到上述几层的功能,除非他/她直接通过命令行接口与计算层互动。用户控制层的主要功能是管理用户的私钥,以及在状态层上签署交易。状态层上的交易会改变用户的账户状态,因此在用户与 Web 3.0 应用的交互过程中处于核心地位
- 与传统网络非常相似的是,Web 3.0 上的大部分活动都将通过搭建在上述分层的第三方应用实现
Web3.0 的困境
虽然 Web3.0 是对互联网未来的无限遐想,但是 Web3.0 并不是一帆风顺,甚至即使是在开始阶段就困难重重。
- 对于企业来说,去中心化无疑是动了它们的奶酪,去中心化旨在打破互联网巨头的垄断地位,这些企业是否真的愿意进行改变,虽然我们看到很多巨头在这一块进行布局,但是毋庸置疑的是,它们的布局不太可能是为了一个平等的网络生态,而是为了下一次的垄断。
- 去中心化应用目前面临“不可能三角问题”,在用户体验,使用性能上还不能和成熟的中心化应用媲美,包括一些使用方式和观念都是对已经习惯于中心化网络世界的用户的挑战。
- 如何管理去中心化系统,虽然去中心化旨在将各个用户的权重降低,但是是否随着时间的推移,用户权重又会逐渐分化。比如,观察近几年矿场的变化,从人人都可以挖矿的时代,转而明显就出现了矿场集中化的情况,甚至不使用专门的矿机,普通用户根本无法通过挖矿获利。
- 用户是否真的关心隐私问题。虽然网络上经常报道用户对隐私的关注,但是实际上大众对隐私被贩卖的容忍度还是很高的。
- 基于区块链的 Web3.0 项目目前很多都是投机,传销项目,尤其是现在的币圈,鱼龙混杂,乌烟瘴气,人们对投机远比区块链技术更感兴趣。
- 最后就是去中心化的盈利问题,去中心化的开发者的盈利方式也许较之前会有一些变化。
结语
总之,Web3.0 前途未卜,也绝非一朝一夕,它可能需要十几年,二十几年才能看到结果。而所面临的困境已经不仅仅是技术上的问题,还包括社会学,经济学,心理学,金融,商业,国家政策等等领域的问题,所以说 Web3.0 相比于人工智能和大数据来说,它是一项有机会重塑人类生产关系的巨大机会。同时 Web3.0 的概念和含义不是一成不变,也应该随着其本身的发展,而重新被定义和修改,对于 Gavin 所定义的 Web3.0 我一直保持一种谨慎的态度。
最终,我希望 Web3.0 能够从互联网的角度,从虚拟世界的角度带给人类文明一个发展的方向和希望,我们二十年后见。