分区(分区实战案例)、Combiner、Shuffer
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118990176(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 分区
在MapReduce中,通过我们指定分区,会将同一个分区的数据发送到同一个Reduce当中进行处理。例如:为了数据的统计,可以把一批类似的数据发送到同一个Reduce当中,在同一个Reduce当中统计相同类型的数据,就可以实现类似的数据分区和统计等。其实就是相同类型的数据,有共性的数据,送到一起去处理。
MapReduce默认是只有一个分区(一个分区就是对应一个输出文件),在之前写过的程序中p1.jar-p9.jar程序的运行,最后生成的文件文件都是part-r-00000的形式,也就是默认只有一个输出文件
接下来通过例子来理解分区
- 如果不进行索引或者分区,那么在orcle数据库中进行数据查询就需要进行全表扫描,采用索引或者分区可以提高查询的性能,不同点在于索引不会破坏原有的表,只是相当于创建了一个查询目录,而分区是会改变表(这里就先介绍分区,之后再介绍索引)
- 分区创建会有相对应的判断条件,满足筛选条件的查询只会扫描对应分区中的内容,比如要查询的2500-2800之间的信息,就只在分区2中进行扫描
- 导入、导出、备份数据时候可以针对分区来进行操作,而不需要针对一整张表,如果某个分区发生了损坏,我们可以只针对这一个分区进行恢复,其它的分区不受影响
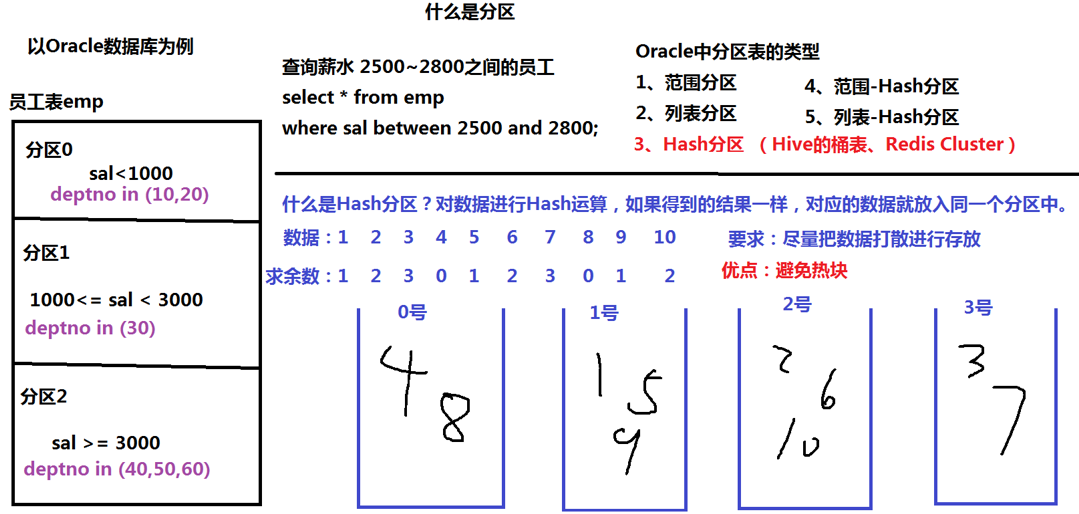
- 分区表的类型有五种(以orcle数据库为例):范围分区、列表分区、hash分区、范围-hash分区、列表-hash分区
- hash分区,就是对数据通过hash运算,如果得到的结果一致,就将对应的数据放置在同一个分区中,比如下面将数据分为四份,就可以除以4取余数(一种hash运算的方式,也可以选用其它的运算方法)
- 分区的要求是尽量把数据打散进行存放,避免形成热块。每一个分区可以视为一个Server,如果当前分区的数据量过大,那么服务器处理这部分数据就会占用很大一部分的时间,该服务区的压力就会非常大,性能就会受到影响
- 打散的效果是取决于采用的hash计算的方法
2 根据部门号建立分区
MapReduce是根据什么标准进行分区的?这个问题在敲代码之前应该先弄清楚。答案就是:根据Map的输出建立分区<k2,v2>
接下来的案例就是以员工的部门号建立分区,还是使用之前的员工表emp.csv文件中的数据,其中最后一个字段就是员工部门,共有三个分类,分别为10、20、30
首先创建一个名为part的package,然后把实现序列化的Employee.java文件复制粘贴在part下,接着建立一下分区的规则,新建一个Java Class文件命名为MyPartitor,还是不用自己写底层代码,直接继承Partitioner父类,然后重写里面的方法
package part;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
// k2 部门号 v2员工对象
public class MyPartitor extends Partitioner<IntWritable, Employee>{
@Override
public int getPartition(IntWritable k2, Employee v2, int numTsk) {
// 建立对应的分区
//numTsk 表示的就是分区的个数
//得到分区号
int deptno = v2.getDeptno();
if (deptno ==10) {
//放入到一号分区
return 1%numTsk;
}else if (deptno ==20) {
//放入到二号分区
return 2%numTsk;
}else {
//放入到三号分区
return 3%numTsk;
}
}
}
接着就要书写Map和Reduce来实现我们制定的分区的逻辑,先处理Map程序,在之前的序列化的Map程序的基础上进行(只需要修改的就是k2,代表着部门号)
package part;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// k1 v1 k2 部门号 v2 员工对象
public class EmployeeMapper extends Mapper<LongWritable, Text, IntWritable, Employee> {
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//数据:7369,SMITH,CLERK,7902,1980/12/17,800,0,20
String data = v1.toString();
//分词
String[] words = data.split(",");
//创建员工对象
Employee e = new Employee();
//设置员工号
e.setEmpno(Integer.parseInt(words[0]));
//设置员工姓名
e.setEname(words[1]);
//职位
e.setJob(words[2]);
//老板
e.setMgr(Integer.parseInt(words[3]));
//入职日期
e.setHiredate(words[4]);
//薪水
e.setSal(Integer.parseInt(words[5]));
//奖金
e.setComm(Integer.parseInt(words[6]));
//部门号
e.setDeptno(Integer.parseInt(words[7]));
//输出k2 部门号 v2 员工对象
context.write(new IntWritable(e.getDeptno()), e);
}
}
Map程序完成后,就是要进行Reduce程序设计,新建一个Java Class程序命名为EmployeeReducer,整个程序的代码如下
package part;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class EmployeeReducer extends Reducer<IntWritable, Employee, IntWritable, Employee>{
@Override
protected void reduce(IntWritable k3, Iterable<Employee> v3,Context context)
throws IOException, InterruptedException {
for (Employee e:v3) {
context.write(k3, e);
}
}
}
然后就是差一个执行的主程序,还是将原来的运行主程序复制过来,修改一下其中部分的参数(一共修改了三行代码,添加了setReducerClass,然后在k2,v2之后添加了分区规则并指定了分区的个数)
package part;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EmployeeMain {
public static void main(String[] args) throws Exception {
// (1)创建任务Job,并且制定任务的入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(EmployeeMain.class); //指定为当前程序
//(2)指定任务的Map,Map的输出类型
job.setMapperClass(EmployeeMapper.class);
job.setMapOutputKeyClass(IntWritable.class);//k2 员工号
job.setMapOutputValueClass(Employee.class);//v2 Employee对象
//指定分区规则
job.setPartitionerClass(MyPartitor.class);
//分区的个数
job.setNumReduceTasks(3);
//(3)指定任务的Reduce,Reduce的输出类型
job.setReducerClass(EmployeeReducer.class);
job.setOutputKeyClass(IntWritable.class);//k4
job.setOutputValueClass(Employee.class);//v4
//(4)指定任务的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//(5)执行任务
job.waitForCompletion(true); //表示执行的时候打印日志
}
}
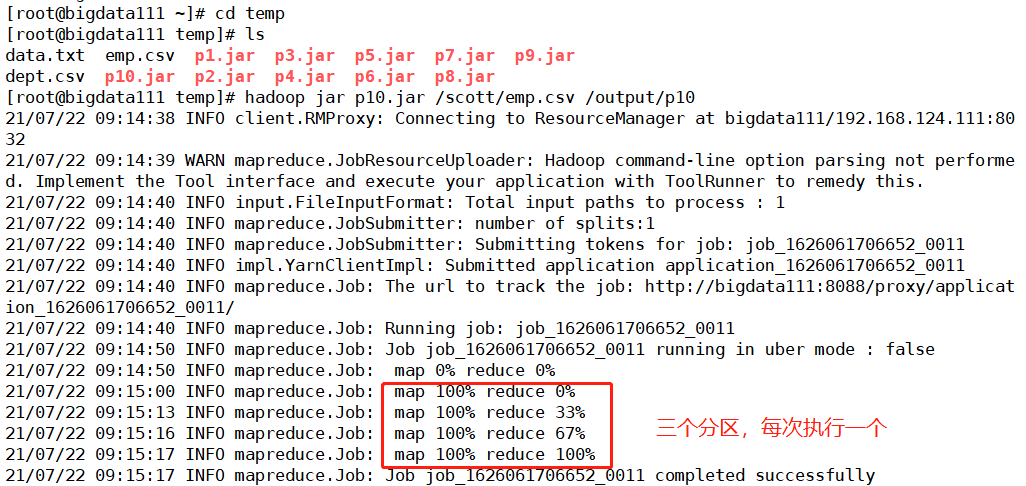
至此框架中的内容全部整理完毕,输出为p10.jar文件后上传到hadoop上运行(注意查看其中Reduce的操作,以前就是直接100%,这次变成了三步,而且是均分为三步)
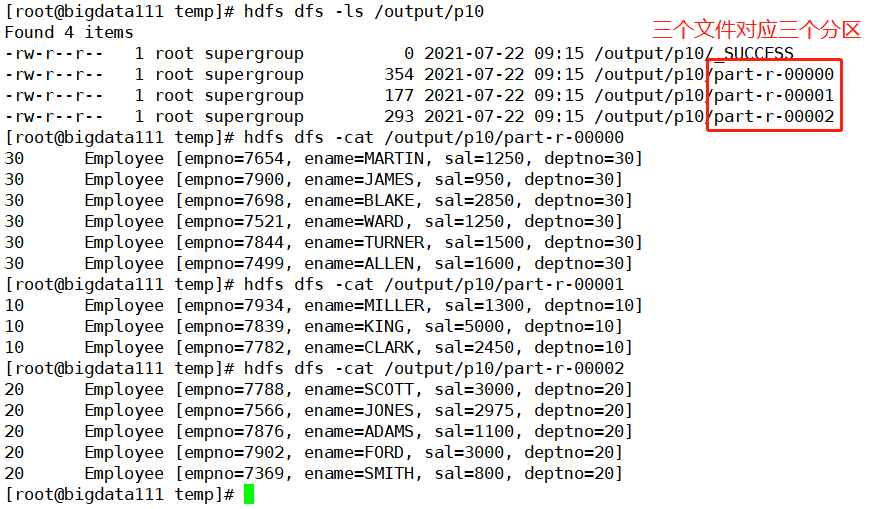
核实一下生成的文件信息内容,最终三个文件和最初设置的三个分区对应上了,查看每个文件中的信息也符合分区存放数据的要求,至此关于MapReduce的分区的知识点就梳理完毕了
3 Combiner
集群上的可用带宽限制了MapReduce作业的数量,因此尽量避免map和reduce任务之间的数据传输是有利的。Hadoop允许用户针对map任务的输出指定一个combiner (就像.mapper,reducer) 。 combiner函数的输出作为reduce函数的输入。由于combiner术语优化方案,所以Hadoop无法确定对map任务输出记录调用多少次combiner (如果需要) 。换言之,不管调用多次combiner, reducer的输出结果都是一样的。
可能上面说的有点抽象,下面根据图示进行理解
- Combiner是一种特殊的Reducer,需要继承Reducer的父类
- Combiner是运行在Map端。先对Map输出的结果,进行本地的合合
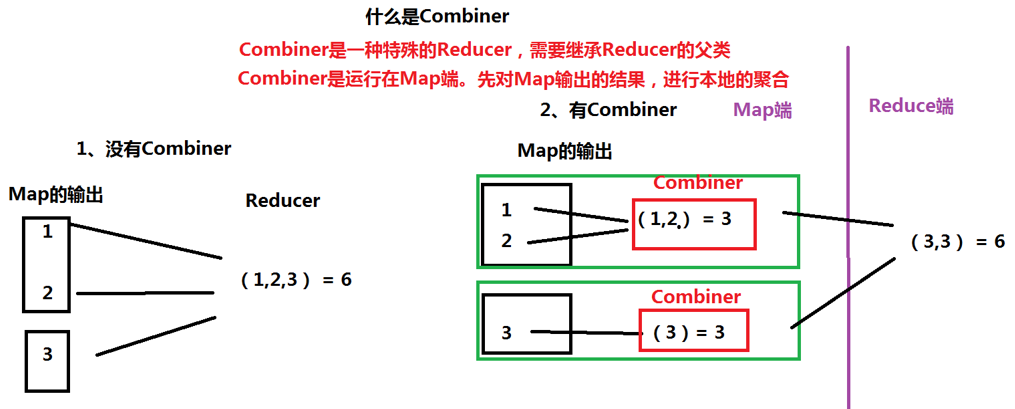
有Combiner和没有Combiner两种方式进行对比,可以发现没有Combiner情况下,Map的输出结果会直接通过网络传送给Reduce端,而有了Combiner后,显示在同服务器的本地上进行结果的初步合并,然后在把处理的结果送至Reduce端,这样减少了数据的传输,也就降低了功耗,提高了性能
之前的WordConut程序进行改造,注意Combiner的本质就是对于数据进行求和(就是在中间的部分添加一行代码,然后再打包为p11.jar)
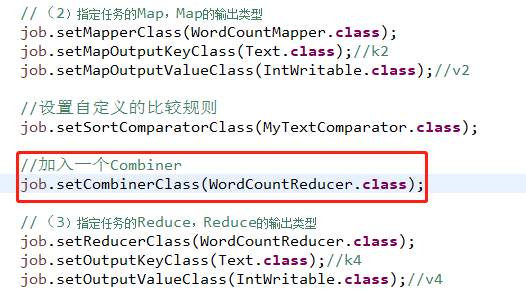
将打包的jar包上传至hadoop上运行
核实一下输出的结果,应该是和原来的结果保持一致
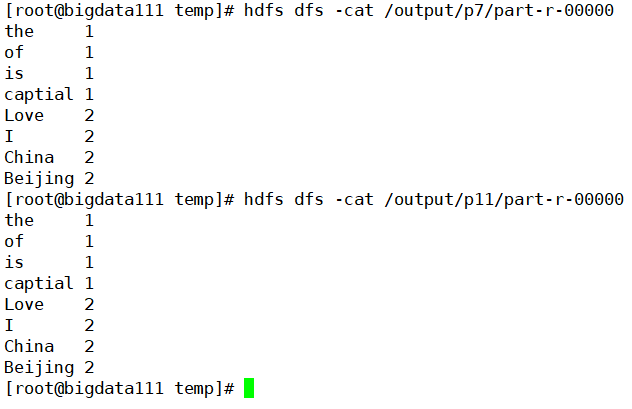
但是还有注意地方:
- (1)有些情况下Combiner是不可以使用的,前面提到的Combiner本质就是进行求和,比如在求平均值的情况下,这个功能就不能使用了
- (2)不管有没有Combiner不能改变最后运行结果
- (3)不管有没有Combiner,都不应该改变原有的处理逻辑(案例:倒排索引)
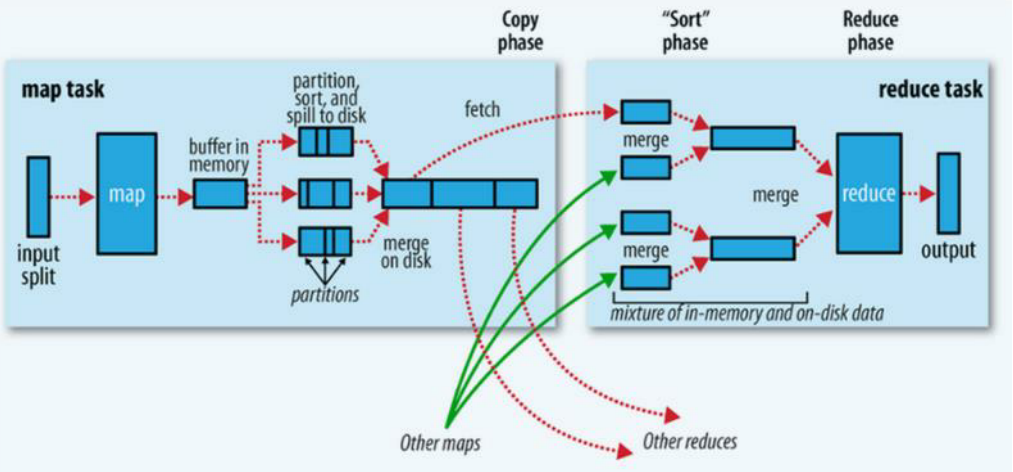
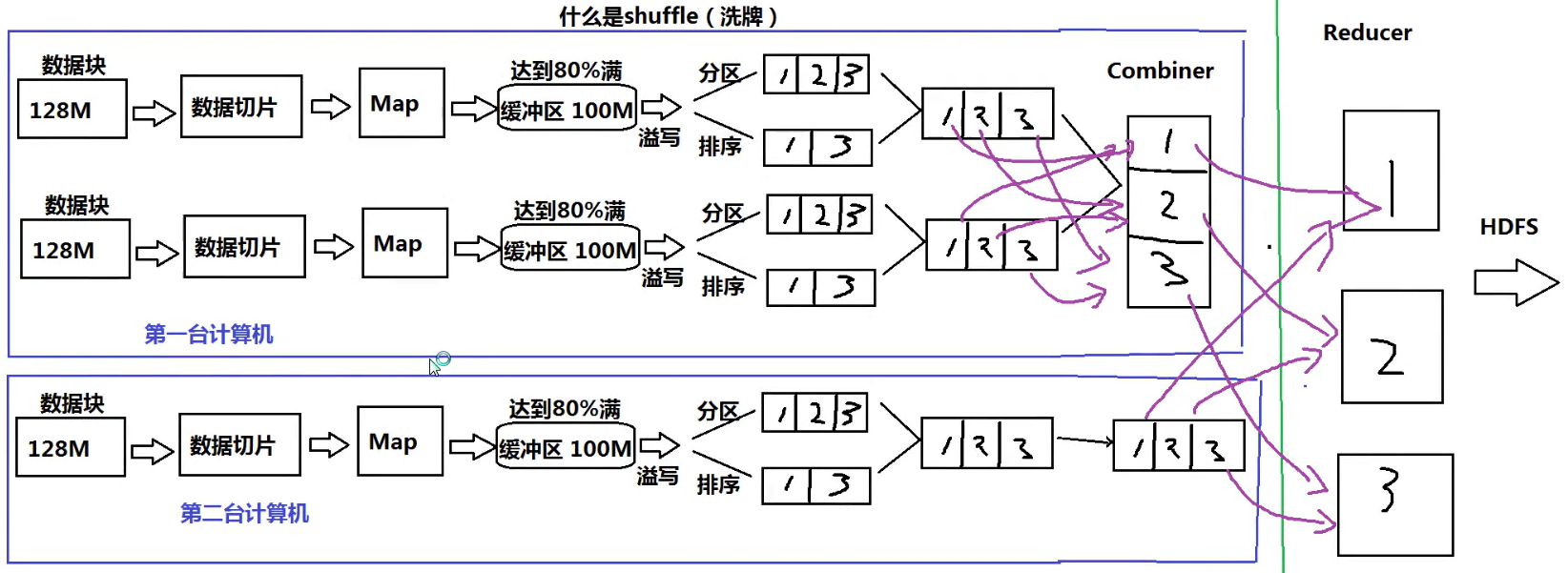
4 Shuffer
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce,Shuffle是必须要了解的。
什么是Shuffer:
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中, shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前后两个部分。在shuffle之前,也就是在map阶段, MapReduce会对要处理的数据进行分片(split)操作,为每一个分片分配一个MapTask任务。接下来map()函数会对每一个分片中的每一行数据进行处理得到键值对(key,value) ,其中key为偏移量, value为一行的内容。此时得到的键值对又叫做“中间结果” 。此后便进入shuffle阶段,由此可以看出shuffle阶段的作用是处理“中间结果”
整个运行过程按照图解进行分析如下:
- (1)数据导入会按照128M进行切片
- (2)进入Map阶段,Map的输出并不是直接送到Reduce中,而是先将结果送到本地的缓冲区(内存为100M),如果达到了80%,就进行溢写(将内存中的数据写成一个一个的文件)
- (3)然后再进行输出,就可以进行分区或者排序的操作
- (4)将80M的多个小文件进行合并(由于每次超过80M就进行溢写,所以会存在很多小文件)
- (5)Combiner对本地输出进行聚合
- (6)Map端至此才结束,进入到Reduce端,最后数据处理完毕后输出到HDFS中
以下是官方给的示例图