第三章:Pandas功能介绍及应用
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/119103730(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Csv和Excel文件读取与写入
1.1 Csv文件读取与写入
1.1.1 Csv数据读取
这里以一份股票数据为例,利用Pandas进行数据读取,操作输出如下,直接将文件所在路径复制到括号中,直接进行读取会发生报错
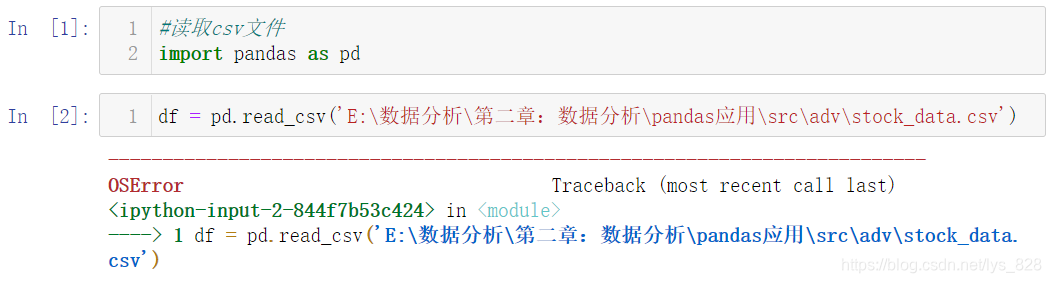
原因与解决问题的方法如下:
- 文件路径中不能只使用
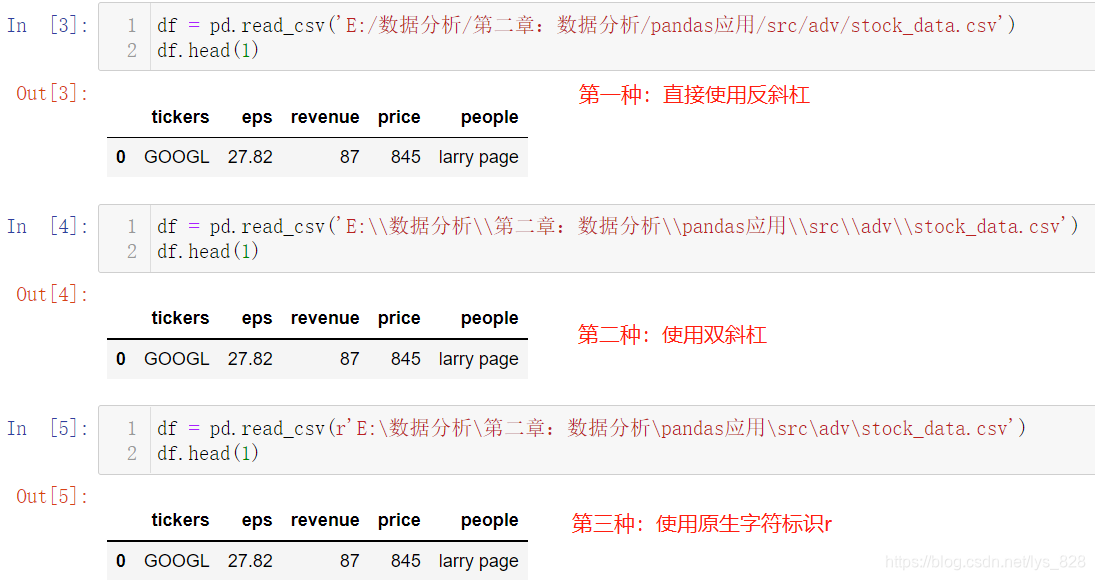
\,因为\在python字符串中表示转义字符(有时候不留意就会报错) - 解决方式有三种(绝对路径):
/、\\、r - 最简单粗暴的方式:相对路径
(1)使用绝对路径(把文件的全部路径信息输入完整)读取Csv文件如下
(2)使用相对路径读取Csv文件:最简单的操作就是把要读取的数据文件和python文件放在同一文件夹下,直接读取就不会报错
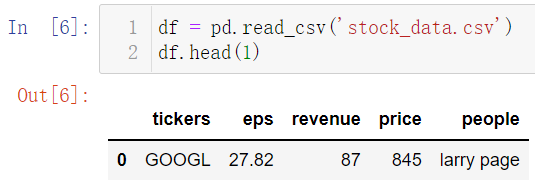
不过以上是在处理单个文件时候的操作,此外为了养成一个良好的习惯,之后如果遇到处理多份数据和分析过程有多个阶段时候,往往会把各个过程分析的python文件单独放在一个文件,数据再放在另一个单独的文件夹中,方便后续工作的管理(特别是在论文写完之后进行数据文件的校对,所有的数据都在一个文件夹中就方便查找),比如这里就是将所有的pyhton代码文件放在adv文件夹中,数据放在data文件夹中,这两个文件夹都是在src文件夹下
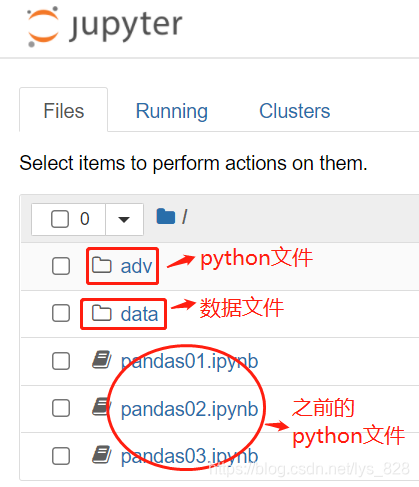
这时候读取数据的方式就是相对路径和绝对路径结合(前面的..代表着此文件所在的上一层文件夹)
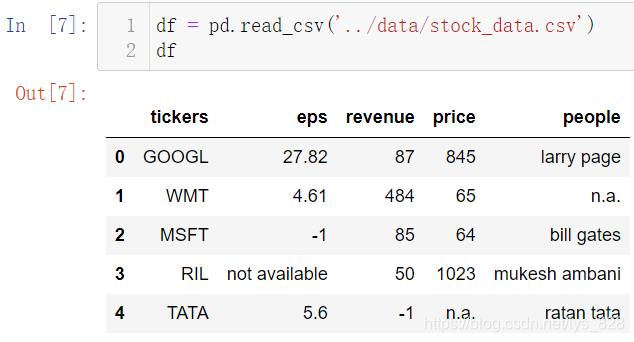
1.1.2 跳过指定行读取数据
前面在介绍Pandas基础的时候有介绍skiprows参数,这里补充讲一下,该参数的值可以直接是整型数据,也可以是列表数据
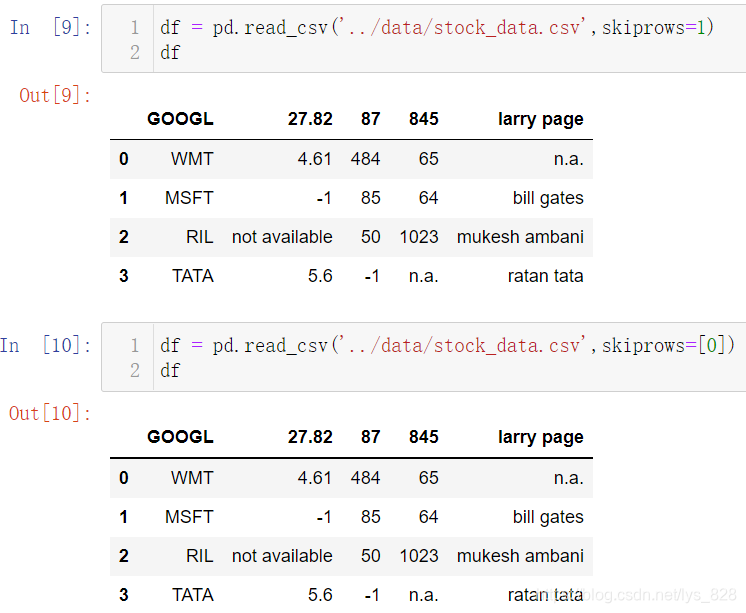
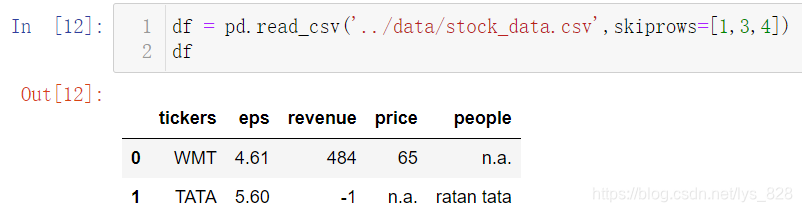
需要注意的就是如果是列表,切记取值是从0开始取的,如上所示skiprows=[0]等同于skiprows=1都表示跳过第一行再读取数据。直接赋值整型数据n,代表跳过前n行;如果赋值是列表,可以指定跳过一些中间不想要的数据,这样就能过滤掉一些不想要的行。比如下面指定的skiprows=[1,3,4],相当于跳过第2、4、5行数据再读取(注意:此处字段名所在的行为第1行)
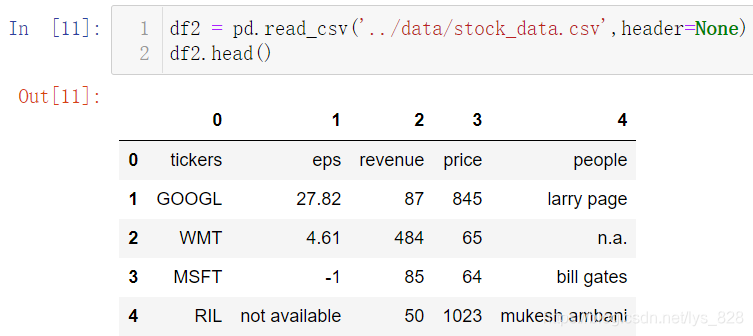
1.1.3 字段名称操作
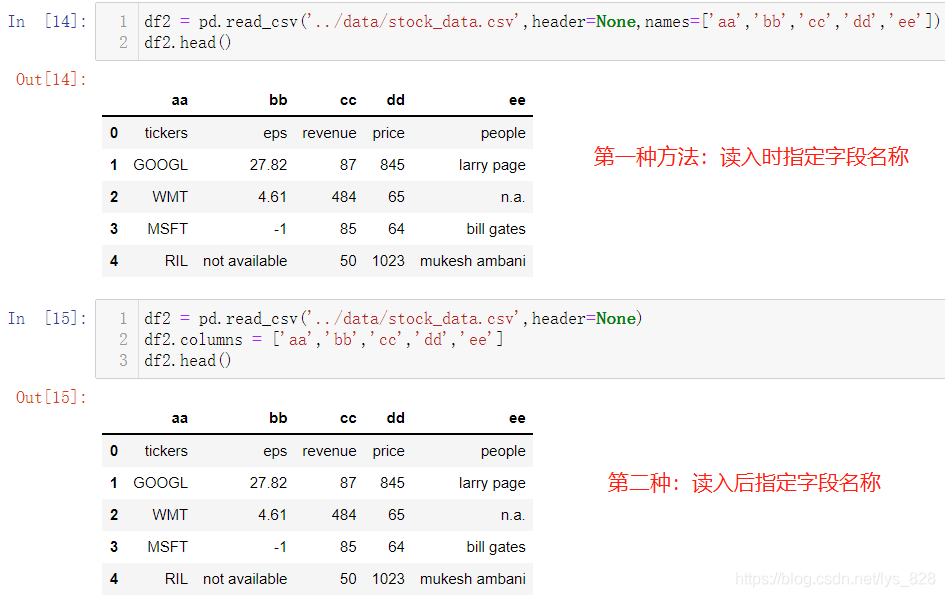
之前讲解过headers=None参数的设置,直接将字段名称忽略,自动分配从0开始表达列数量的数字,如下
除此之外,这个还可以配合着names参数搭配使用,再处理没有字段名称的数据时候,直接指定,再回顾一下之前的内容,两者就构成了字段名称处理的两种方式
1.1.4 读取指定数量的数据
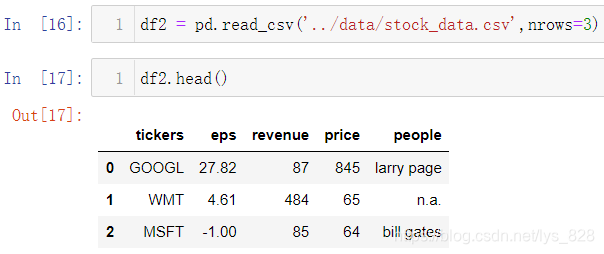
有时数据量太大,不需要提取全部的数据,只要进行里面的部分数据的提取就可以,那么就需要直接读取指定要求的行数,比如刚刚的数据由于只有5条,这里指定读取3条
同时也可以配合着之前介绍的skiprows参数使用,如下

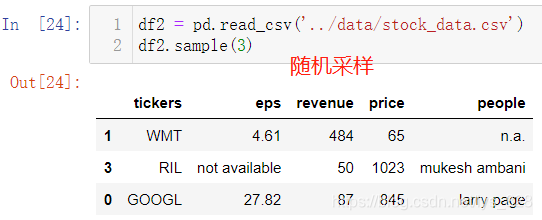
上面的方式只能获取固定规则下的数据,如果说是要随机采样,获取指定长度的数据,可以使用sample(n)方式,其中n就代表采样数量
1.1.5 数据存入Csv
数据处理完毕后,想要保存到本地,可以使用to_csv()的方法
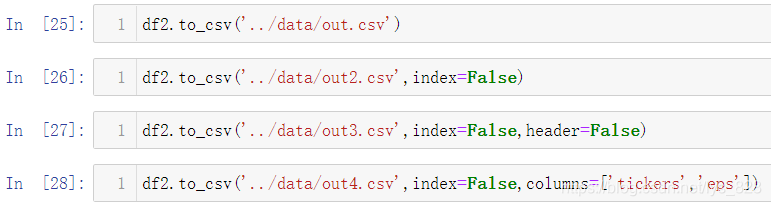
- (1)直接填写路径不加任何参数,会把整个DataFrame完整不动地保存在本地
- (2)
index=False参数,取消第一列的索引值,如果索引是01234…是默认数值,这个可以设置,如果是其他有含义的索引列,一般不会进行取消,这里要根据实际需求设置 - (3)
header=False参数,或许不想生成的数据里面有字段名称,就可以使用这个参数设定 - (4)
columns=['xxx']参数,代表只保存列表中含有的数据字段,相当于进行数据指定列保存
1.2 Excel数据读取与写入
1.2.1 Excel数据默认读取
还是使用刚刚的股票数据,文件是通过csv文件另存为Excel文件,括号中添加数据所在的地址,读取操作如下
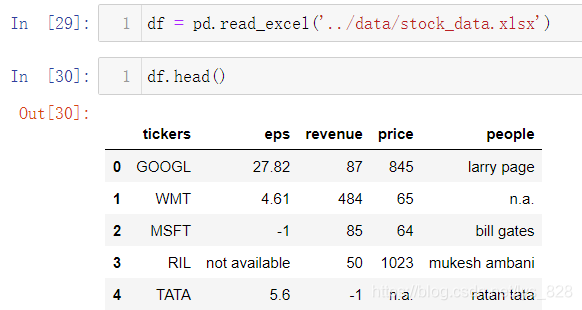
1.2.2 指定sheet进行读取
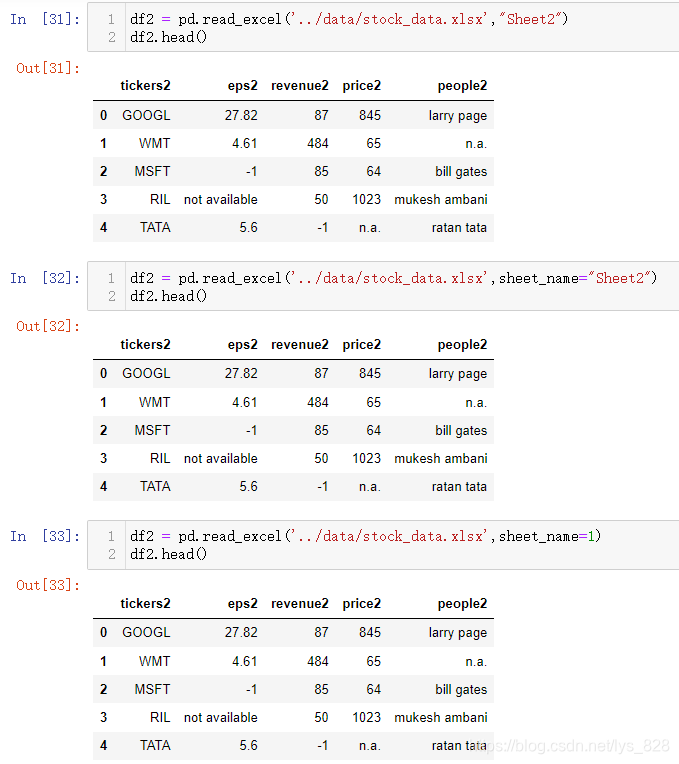
Excel中会存在多个表单(sheet),每个表单中都会有数据,有时数据并不是在默认的第一个表单中,因此就有需要根据不同的表单获取数据,比如将原表单的数据复制一份到第二份表单中,为了区别开来,将字段名称后都添加个2
关键参数为sheet_name,该参数为函数中第二个位置的参数且赋值可以为整数也可以为字符串,所以在文件路径后面直接输入对应的表名通过位置参数传递或者直接通过参数名称赋值传递表名都可以,如下(sheet_name默认值为0,即读取第一个sheet中的内容,第二个sheet表单就对应着sheet_name=1)
1.2.3 读入数据初步处理
有时候拿到的数据里面存在缺失值或者异常值,在读取数据过程就就可以直接进行处理,读入后就是清洗过的完整数据。需要使用到converters参数,赋值对应是一个字典,里面的键为字段名称,值就为处理该字段的方法/函数,比如price字段中存在着n.a.数据(缺失值),可以直接进行替换
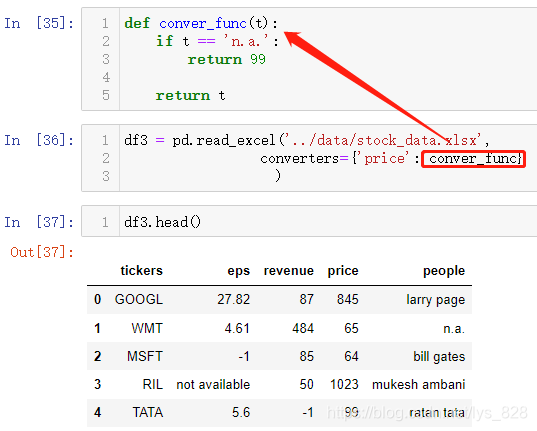
比如处理异常值,收入在一定的范围内是正常,超过就是300设定为高收入(这里不知道具体的单位,只做假设演示),然后负数自然是异常数据。通过converters参数就可以实现数据的初步清洗

1.2.4 数据保存为Excel文件
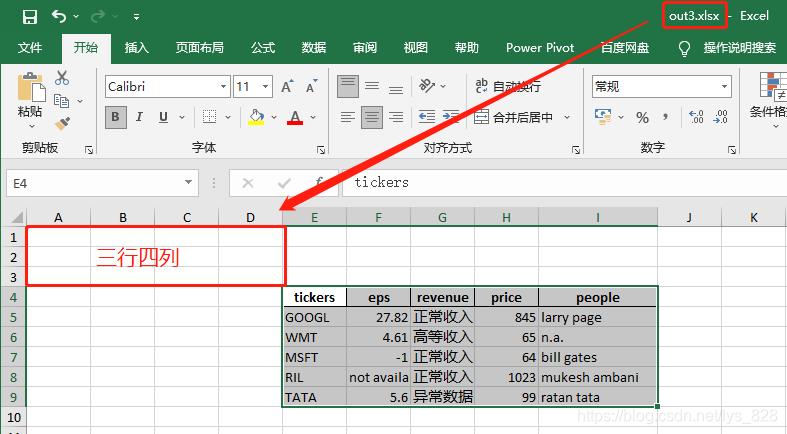
数据处理完毕后保存为原来的文件格式,这里的操作和之前保存Csv文件类似。由于Excel中是存在行和列,可以更加具体指定数据保存位置开始的范围,比如要保存从第3行和第四列开始
最后out3.xlsx文件的内容如下(startrow和startcol两个参数相当于指定数据存放在Excel中平移的位置)
1.2.5 保存数据到同一文件下的不同sheet中
前面介绍了读取不同sheet中的数据,自然有时也会有讲数据保存到不同sheet的需求,具体的模板代码如下
with pd.ExcelWriter('../data/combine.xlsx') as writer:
df3.to_excel(writer,sheet_name='df1')
df3.to_excel(writer,sheet_name='df2',startrow=3,startcol=4)
其中第一行中的文件路径就是要保存的文件名称,然后下面两个代码是指定sheet的名称,关于这部分还是挺实用,有兴趣可以参考一下博客中的另外两篇文章:筛选同一表格下的多个sheet里的内容并保存在对应的sheet中 和 【python办公自动化】将Word文本和Pdf表格数据提取并整合到同一个Exeel下的多sheet中
2 缺失数据处理
缺失值处理的三种方式:
- 直接删除:
dropna() - 拟合差值:
interpolate() - 填充:
fillna()
2.1 数据类型查看
在实战中介绍这三种方式知识以及如何使用,首先加载数据,这里使用创建的天气数据
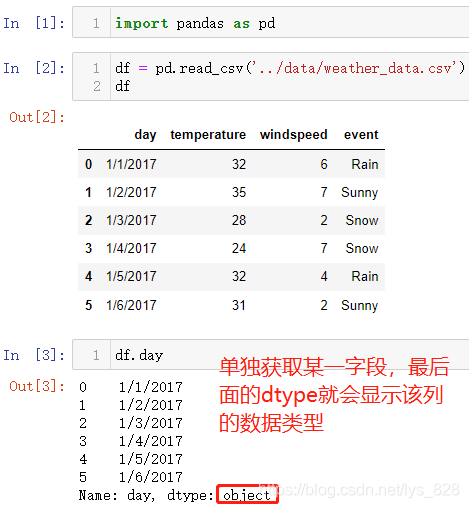
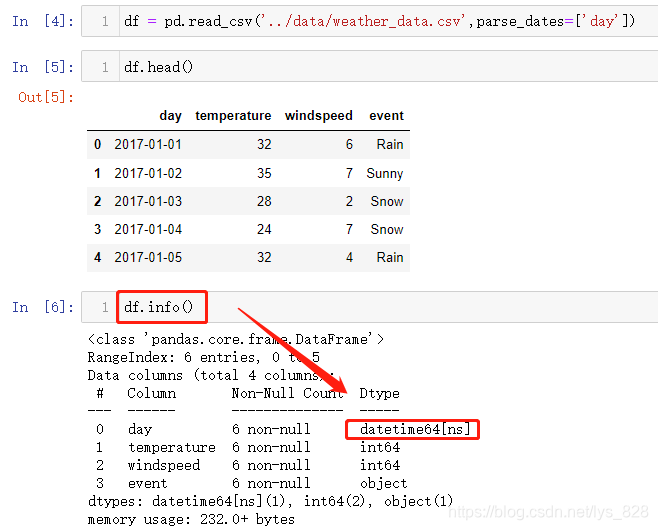
可以发现读取的数据中包含了时间,但是读入进来后Pandas默认将其当做了object数据(也就是字符串数据类型),因此可以在读入的时候使用parse_dates参数,指定要当做日期处理的字段名,数据读取完毕后,目标字段就会被自动解析为时间的数据类型
此外除了直接调用某一字段会显示出该字段的数据类型,使用df.info()方法就会把所有字段的数据类型都显示出来
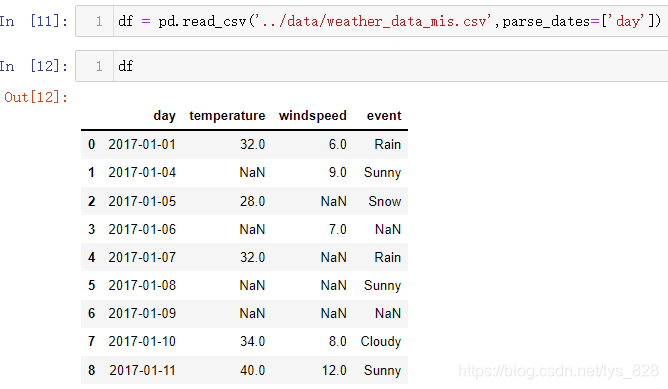
2.2 数据缺失值查看与汇总计数
为了获取缺失值,将刚刚的数据中添加一些数据,人为制造缺失值,再进行读取操作
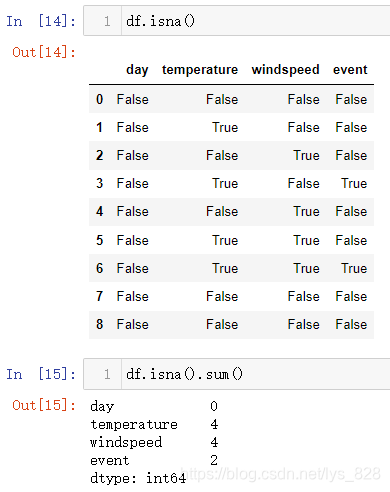
首先通过isna()方法可以用来查看每个字段中的数据是否为空值,最后使用sum()方法进行汇总
2.3 缺失数据填充
2.3.1 固定值填充
直接使用fillna()方法进行,这里和之前读取数据里面converters参数使用原理类似,都是中间给定一个字典,键为字段名称,值就为要填充的数据
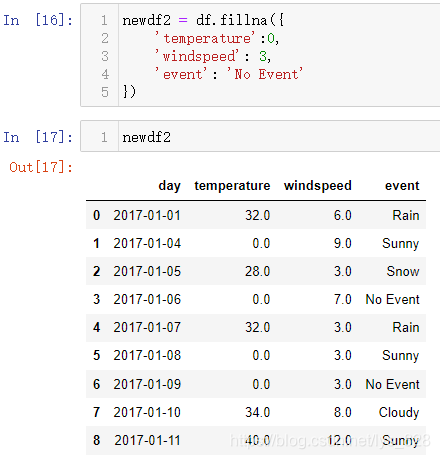
2.3.2 动态值填充
刚刚实现的是按照固定的数值进行缺失值填充,此类数据主要是一些统计结果类型数据,每份数据直接没有很强的关联性,如果手上的数据是一些趋势有规律的数据,比如股票,传感器等类型的数据,再以固定值填充就不靠谱了,因此就有了动态填充的需求
(1)向前填充:ffill
按照当前字段中前一个值,对该缺失值值进行填充
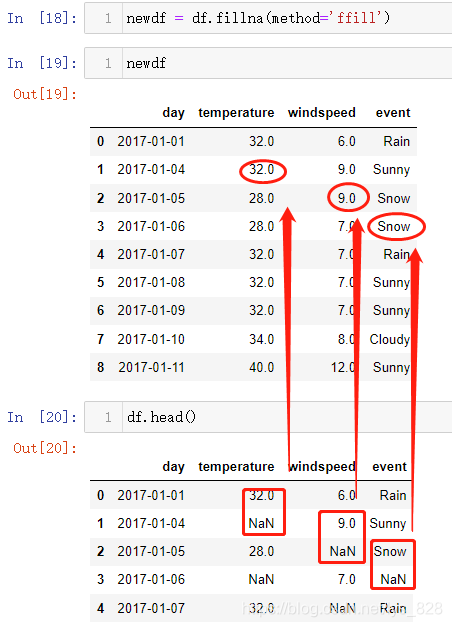
(2)向后填充:bfill
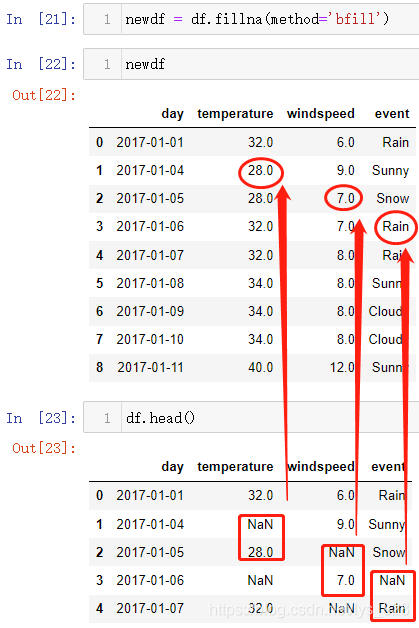
注意点:动态填充存在瑕疵,当数据的第一行或者第最后一行存在缺失值时(前面几行连续缺失或者最后几行连续缺失),动态填充是处理不了的,所以要结合之前的固定值填充的方法,把这个问题解决掉,两者配合着使用就能完成缺失值填充的操作
补充点: 如果想要以横向的数据为标准进行填充,有两种方式,第一种可以使用axis = 1 或者axis = ‘columns’参数;第二种方式就是将df进行转置new_df = df.T,这样之前的操作就都可以使用,最后填充完再转置回来就ok啦
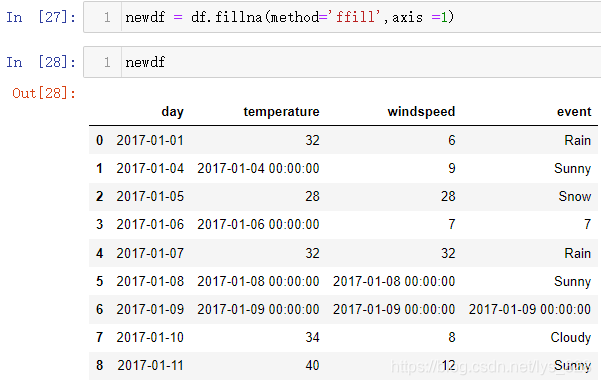
此外,还有一个limit参数,控制填充的个数,如下
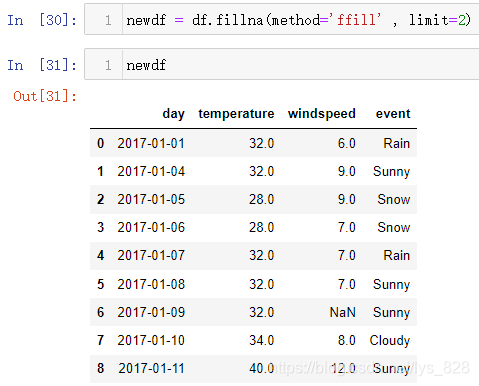
2.4 缺失数据拟合差值
2.4.1 直接数值类型数据拟合差值
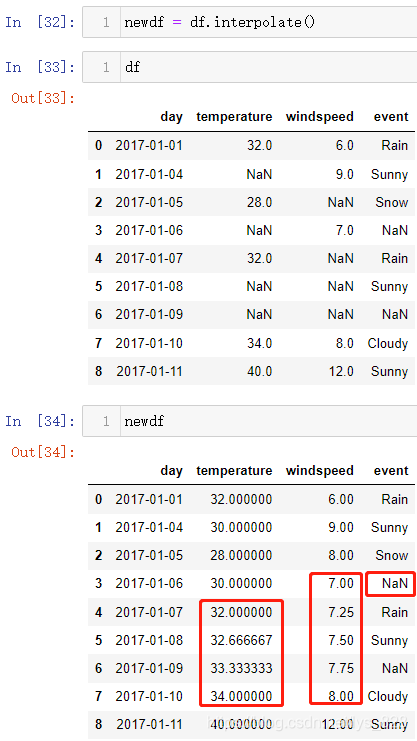
interpolate()方法默认就是根据数值计算来进行缺失值的处理,操作如下。输出结果汇总可以看出,既然是依靠数值计算,那么字符串数据类型的缺失值就没有办法处理,对于数值型数据,比如下面红框中的内容,就是根据缺失值前后的数据然后再计算中间缺数据的个数,最后进行等比处理
2.4.2 参照时间类型数据拟合差值
通过method='time'进行操作,注意索引需要是为时间数据类型,这也是前面要转化时间类型数据的原因,首先将索引设置为day,接着再进行拟合插值,操作结果如下:
- 如果直接指定
newdf = df.interpolate(method='time'),执行会报错,提醒这种方法要求索引为时间索引 - 第二部分红框的内容和之前的直接拟合差值没有任何区别,主要是因为这部分日期时间是连续的,没有出现隔天的现象
- 第三部分红框的内容就显示出来差别了,这里填充的29,之前填充的是30,就是因为第一种是直接以前后的数值为依据,而这里还参考了前面的时间索引

2.5 缺失数据删除
2.5.1 含缺失值就删除
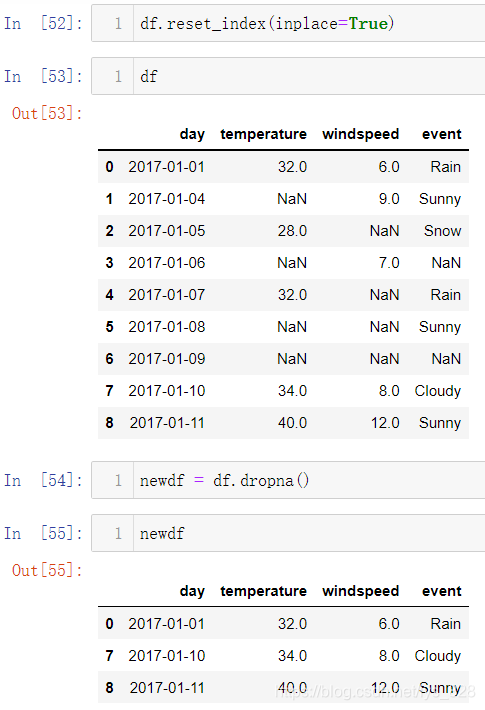
首先将数据再转化为原来的样子,重置一下索引,如果直接使用dropna()方法,会直接将只要含有空值的行全部删除,输出结果如下,最后就只剩下3条有效数据
2.5.2 一行数据全为空才删除
其实想删除的是全部数据都为空的行,并不是要求含有缺失值就删除,那么就可以使用how='all'这个参数,输出结果如下
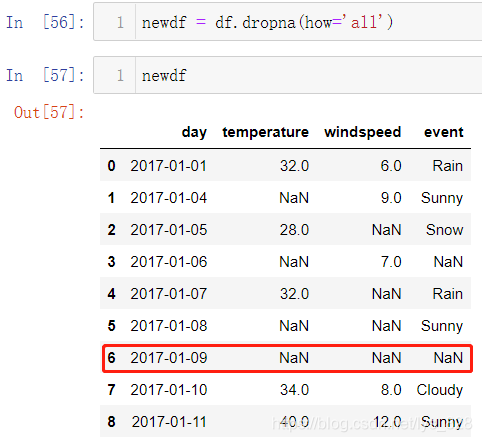
输出中发现有一条数据这里后面三个都是空值,前面有一个字段是时间字段部位空,说明这里的all要求的是所有字段,如果是这个时间放在索引上面,输出结果如下。结果发现2017-01-19号这条数据就被清除了,再次证明这里的all是针对所有的字段,也就是从第二列开始的所有数据(第一列为索引)
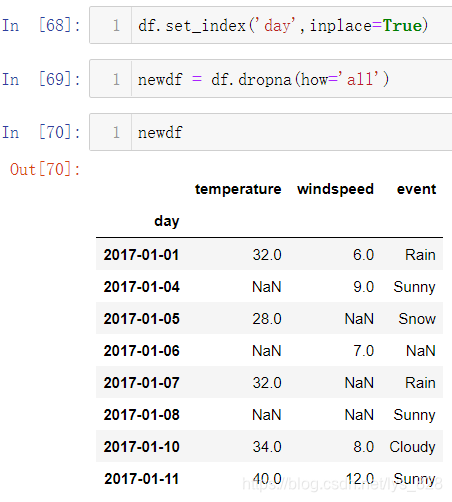
2.5.3 指定缺失值数量进行条件删除
前面的两种条件都太苛刻了,有时候希望可以控制一下缺失值,满足缺失值数量在某某水平,那么每行超过这个指定缺失值数量的行才被删除,此时thresh参数就可以发挥重要作用。我们可以自己指定该参数赋值的整数,满足这个条件的行数才会被删除,比如这里指定thresh=1,就是指所有字段中必须要有一个字段中有数据,容许每行存在的缺失值数量就为:字段数量 - thresh
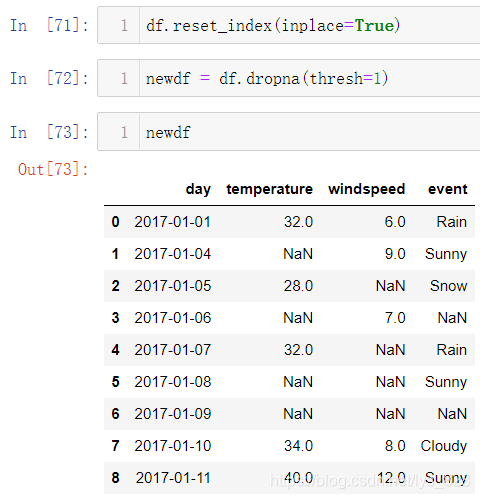
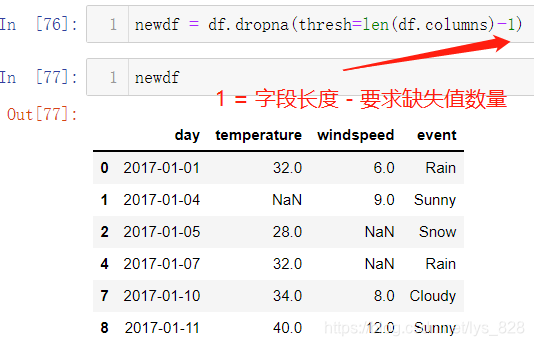
假如要求每行的缺失值数量不要超过n个,处理的代码为:newdf = df.dropna(thresh=len(df.columns)-n)
3 数据替换
核心方法replace()
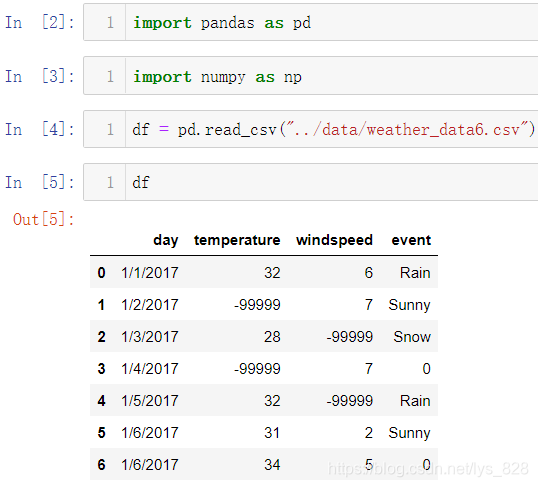
3.1 单值替换
顾名思义就是对具体的某一个值进行替换,使用的数据还是刚刚的数据,不过将上面的缺失值都进行修改,变成“异常值”了,读取数据如下
比如将df中数值为-99999替换成为指定的数据(括号中前面是待替换的数据,后面是替换后的数据)
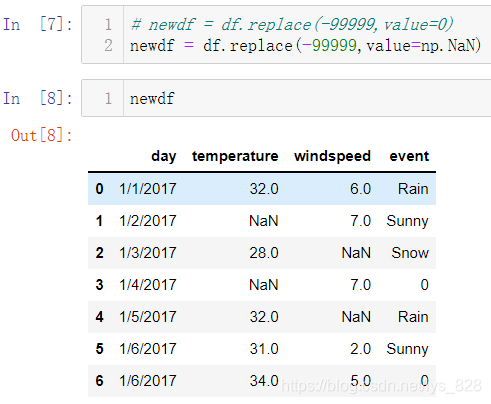
上面这种是针对具体某一个值的替换,那么更具体一点要求进行某一具体单元格数据的替换,比如将df中第5行第3列的-99999替换为-88888,具体实现方式就是之前学到的iloc坐标取值的方式
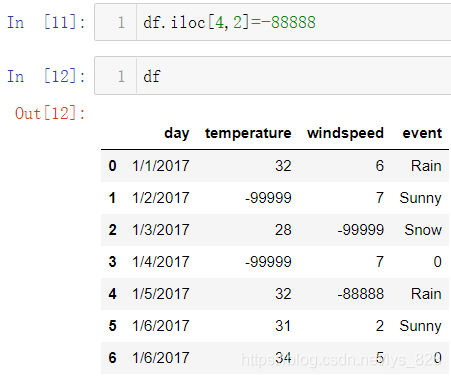
3.2 多值替换
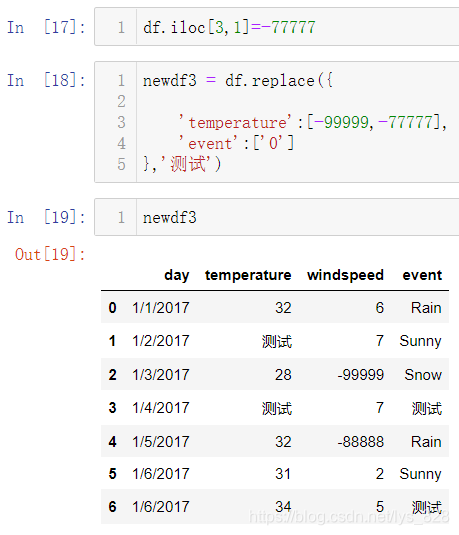
在单值替换的基础上更进一步,就是进行多值替换,也就是把多个数据同时转化为指定的数据,需要同时使用到to_replace参数和value参数。把所有要替换的数据都放在列表中然后复制给to_replace参数,注意这里event字段是字符串数据类型,里面的0自然也是字符串的形式(特别是数值替换时,要留心该字段的数据类型)
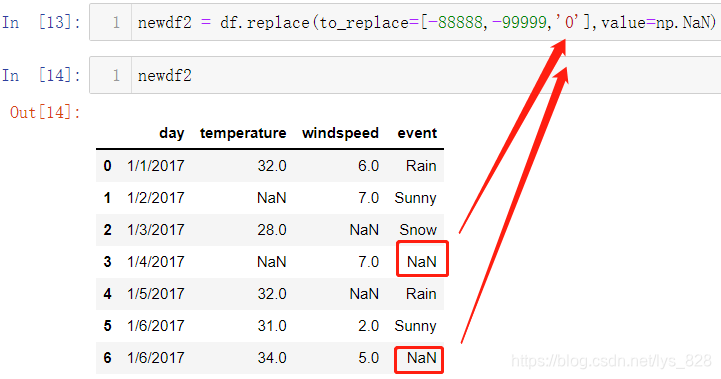
替换后的值除了是单一的数据外也可以是列表数据,需要和前面的列表数据量保持一致,这样就默认前后一一替换对应了
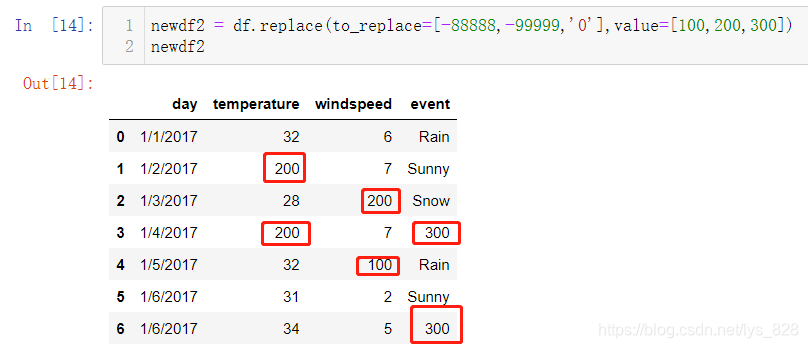
3.3 列数据替换
操作方式和之前缺失值多列处理以及数据读入预处理的原理基本类似,也是通过字典参数,键对应字段名称,值对应要替换的数据,最后面的一个参数为替换后的数据,输出结果如下,发现只有temperature字段的-99999数值被替换成了目标数据,windspeed字段没有发生变化,然后event字段再次说明了替换是需要注意数据类型
3.4 使用map方法进行替换
3.4.1 传递字典
第一种方式是使用字典的方式进行传递, 需要注意的是map方法使用针对的是具体的某字段数据的替换,且字典中的键应该包含该字段所有的唯一值,否则替换后就会变成空值,操作如下
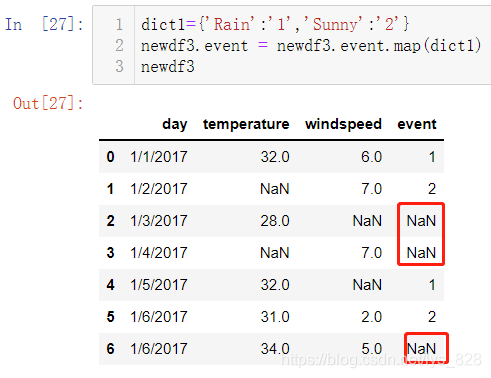
输出的结果并不是想要的,就是因为指向替换里面的Rain和Sunny,但是Snow和0没有指定,所以就用空值进行填充,使用map传递字典需要把所以的唯一值都传入
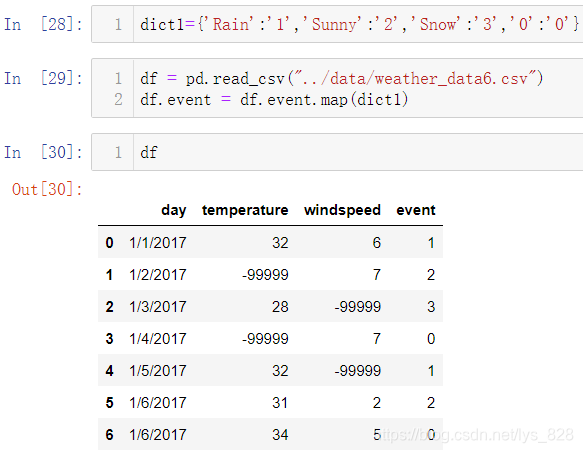
可能也发现了,使用这种方法只能用在字段中的唯一值较少的情况,如果该字段下面的分类数量过多,那么就要一个一个输入,这个也是此方法的弊端
3.4.2 传递函数
传递函数的方式相较于字典会有更多的用途,相当于使用一个函数来对字段中所有的数据进行处理,功能很强大,这里就是进行替换的具体应用,操作如下
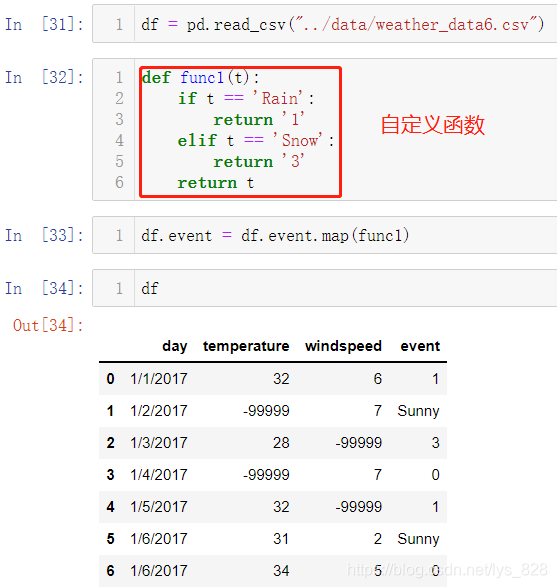
结果输出中也没有传递字典那样苛刻,没有指定替换的数据会以原本的样式进行呈现
3.5 使用正则表达式进行替换
当要修改的内容比较多,采用上面的方式就得一个一个进行输入了,为了能让那个问题简化,就可以使用正则表达式进行替换。比如将temperature字段中的空值使用字符进行替换(构造带有符号的数据),结果输出如下
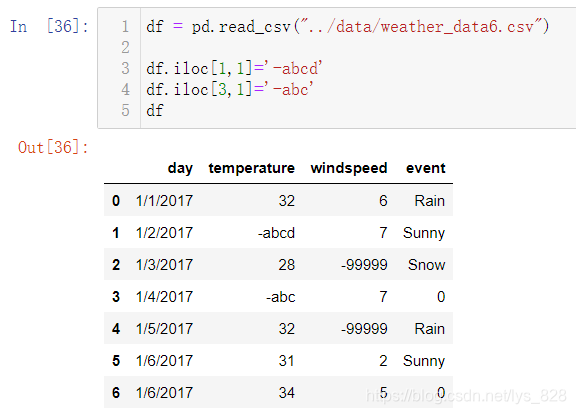
要想替换将带符号的内容统一进行替换为数值(比如这里只要带有负号的数据统一替换为100),此外还应该注意的是正则表达式匹配的前提是数据为字符串类型,否则不生效
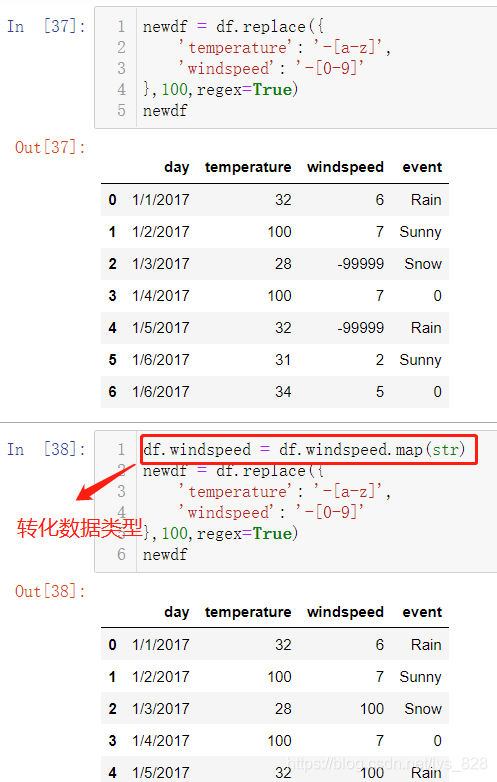
输出结果显示当字段数据类型为字符串时候正则替换的操作才显示出来,另外改变数据类型的时候就使用了刚刚介绍了字段的map()方法的使用(直接使用astype()也可以)。之前介绍的是map()中传递的自定义函数完成数据的替换,这里就是直接使用自带的函数完成字段数据类型的转化。map()方法灵活应用可以实现很多复杂操作,熟练的掌握map()方法在今后数据处理过程中会省很多步骤
4 时间索引操作
时间索引操作就是指对DataFrame数据中索引index一列是时间的数据进行操作,前面已经有过时间字段数据的转化和设置为索引的设置,接下来就是来看一下具体针对时间索引有哪一些操作
4.1 读取并转化为时间索引数据
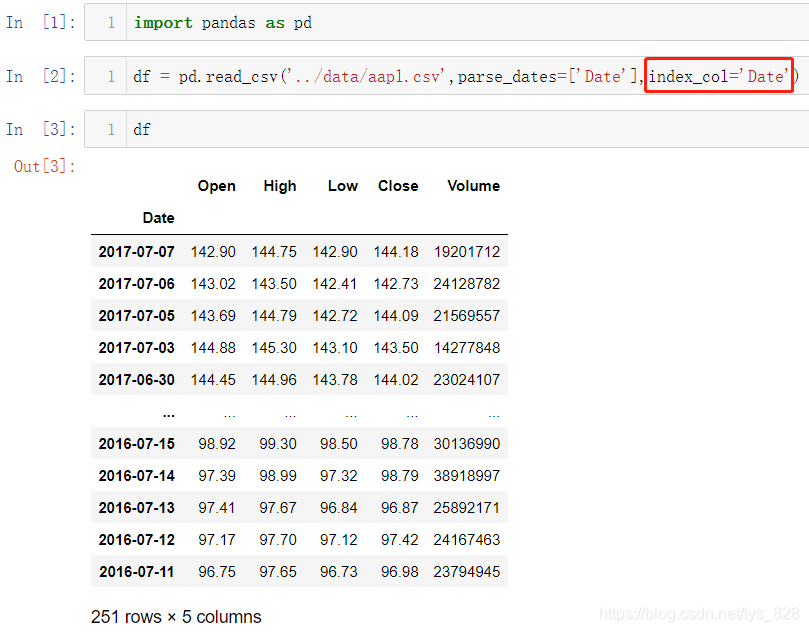
在读取数据过程中这里再介绍一个参数index_col,即指定作为索引的列(字段),配合着之前的parse_dates参数,就可以直接将数据中属于时间的字段直接转化为时间索引数据
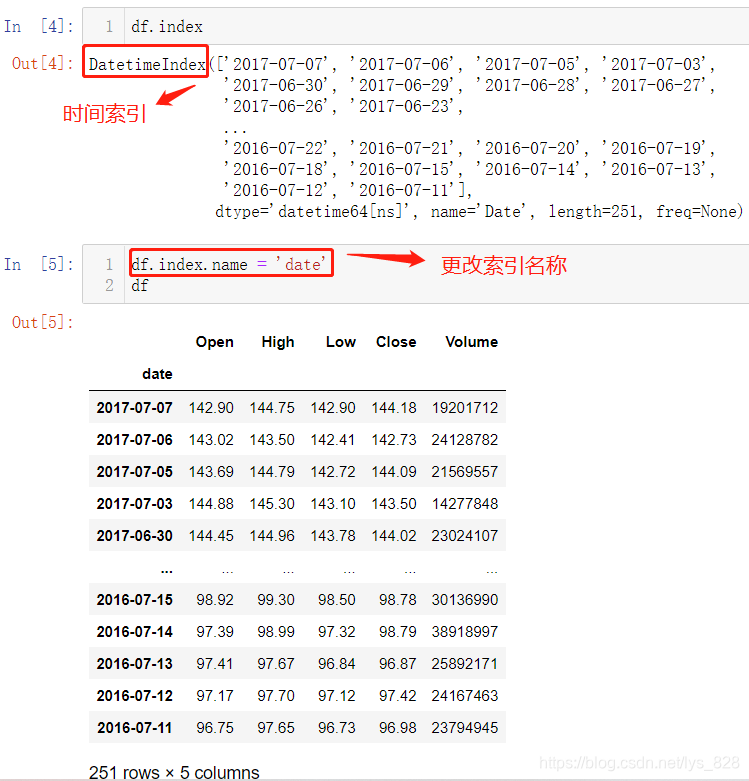
核实一下看看这个索引数据类型,时间索引英文名称为DatetimeIndex。顺带提一下,这种操作会把字段的名称默认给赋值给索引index,如果想要对索引的名称进行修改,使用的代码为df.index.name = 'xxx'
4.2 时间索引常用操作
4.2.1 直接索引取值
先回顾一下获取行或者列的操作,如下
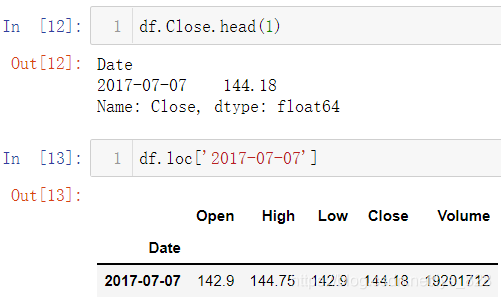
如果是时间序列,就会有很多好玩的操作,比如选取2017年的数据,直接通过df.loc['2017'].head()就可以查看2017年前5条的数据,甚至先前的版本不需要loc可以直接进行2017年数据的筛选
Pandas自0.25.x版本后就进入了1.x版本,这个也不算是时间太久远,相当于是一个版本的更迭,先前版本号可以下载0.25.3,如下可以看到卸载之前使用的Pandas版本为1.1.2。按照某指定版本模块代码的指令为:pip install xxx==版本号(注意直接在notebook中装完模块后,一般需要restart一下kernel,然后再执行所选代码,注意下面代码前的运行编号,restart后再运行是重新从1开始计数了)
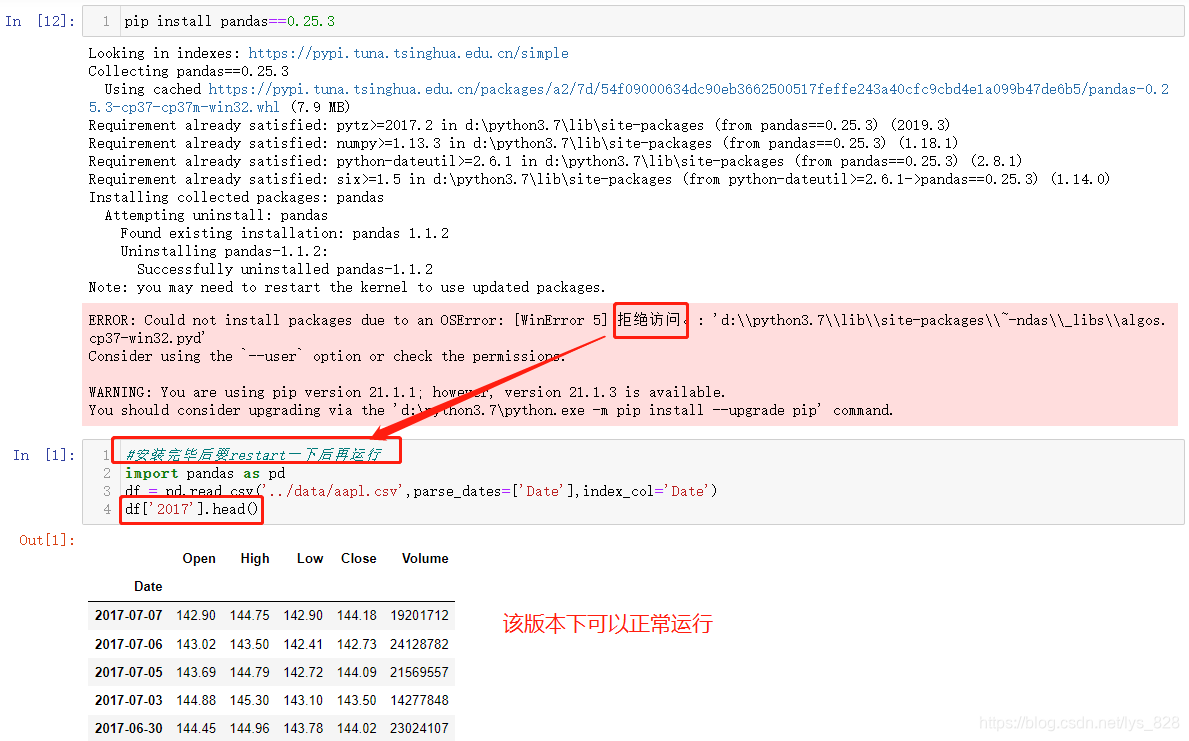
如果要查看2017年6月份的数据,直接通过df['2017-06']就可以获取(为了方便展示,选择输出前五条数据)
获取具体的某一天中的数据,比如2017年6月2号的行数据。然后基于获取的行数据,还可以进一步得到具体的某一字段的数据,相当于先确定行再确定列(字段),这样就把单元格的具体的位置确定下来了。
需要注意的是上述操作获取的只是一个Series数据,要获取单元格的数据,可以借助.values的操作(最后输出的数据类型为array数据,再次证明Pandas底层下面是numpy)
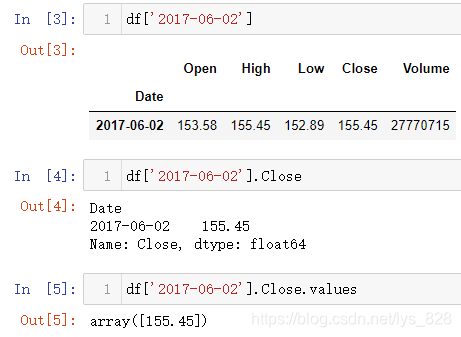
既然可以直接对月份进行汇总计算,就可以直接使用之前介绍的一些统计量不用再复杂的从时间中提取月份数据后再进行分组汇总了(以取最小值和均值为例,其它的统计量类似)
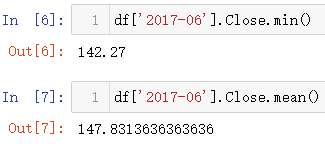
4.2.2 切片索引
之前也有介绍df[xxx:xxx]行数据获取,时间索引也可以使用这种方式,但是注意时间是有顺序,通过代码进行检验,如果指定的索引顺序与时间索引的方向不一致,获取的结果就为空
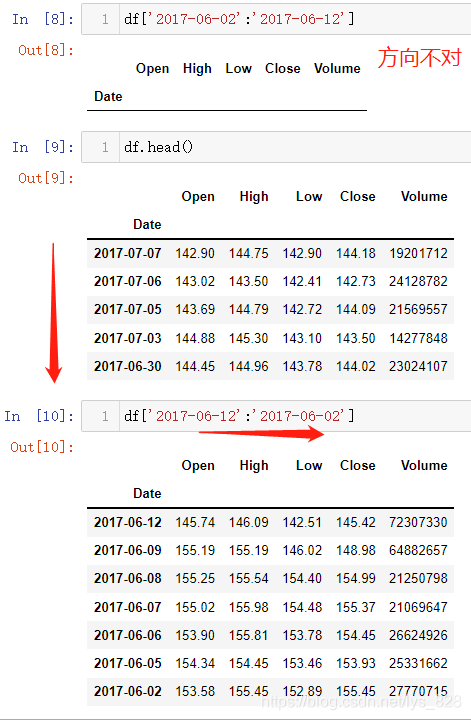
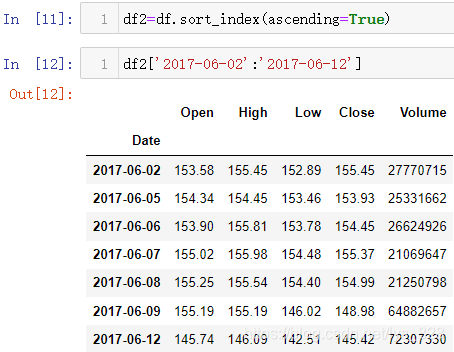
那么既然涉及到方向的问题,就需要知道时间序列如何排序,可以使用sort_index()的功能(如果是按照某字段排序就是sort_values('字段名')),需要注意的是,函数里面有个指定排序的方向的参数为ascending,默认值为False表示降序排列(从大到小),也可以根据需要指定为True,表示升序排列(从小到大)
4.2.3 时间重采样
时间重采样respame():将时间序列从一个频率转换为另一个频率的过程,且会有数据的结合的操作。比如在获得每天的销售信息时候,想要进行每个月甚至每年的销售汇总时候,就需要使用时间序列重采样。
需要注意:一般是要选取指定的字段后再进行resample(),否则就会以全部字段进行,由于中间会涉及到数据的运算,当数据量或者数据值越大时候就很消耗性能,影响程序的运行时间,比如最后一列的数值就很大,输出结果时候有明显感觉的延迟
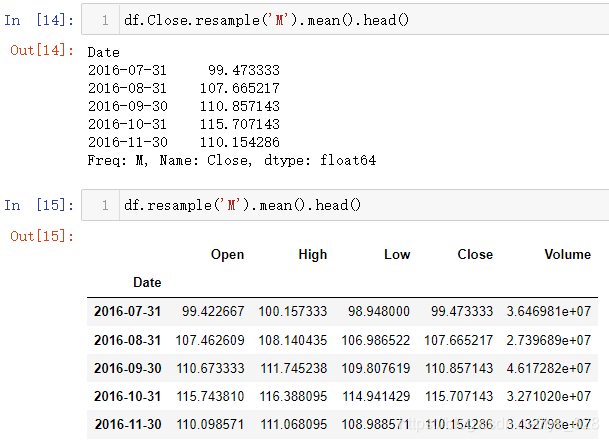
重采样的时间可以选取的有很多种,比如常见的年、季度、月、日、小时,还有一些工作日、周、每月的第一天/最后一天、每年的最后一个工作日/日历日等等
4.2.4 简单绘图
时间序列绘制图像非常简单好用,直接一行代码就搞定。代码指令就是在获取字段的基础上加上plot(),这样默认就会以时间索引为x轴,选取的字段为y轴进行图像绘制
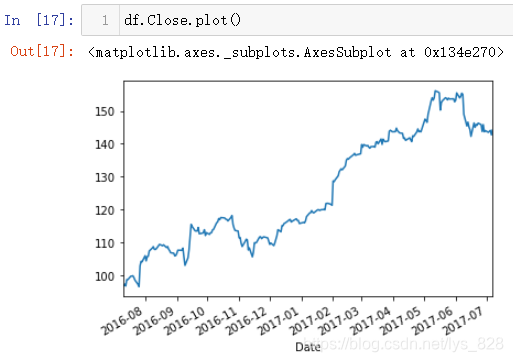
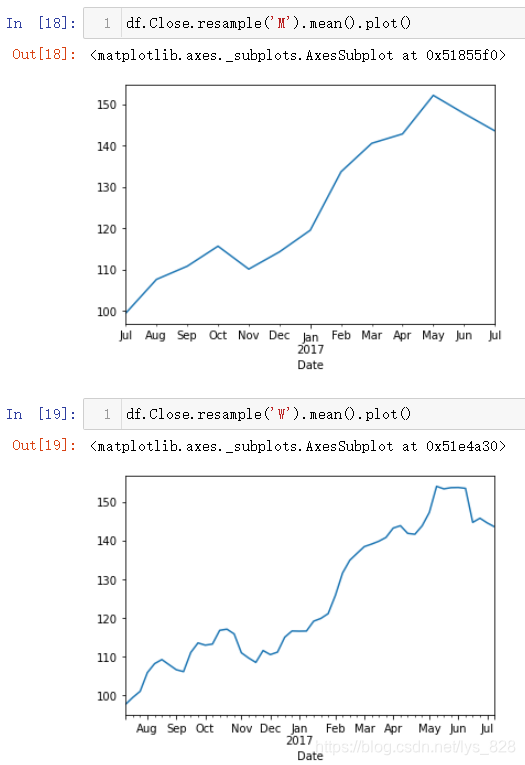
当采用时间重采样之后的数据进行绘图,就相当于对图像进行平滑处理,假如取每个星期和每个月的均值数据来绘制图形,输出结果如下(M是按照月份,W是按照星期,可以看到x轴标签此时自动转变为英文各月份单词的缩写)
5 时间数据构造和频率转换
5.1 时间数据构造
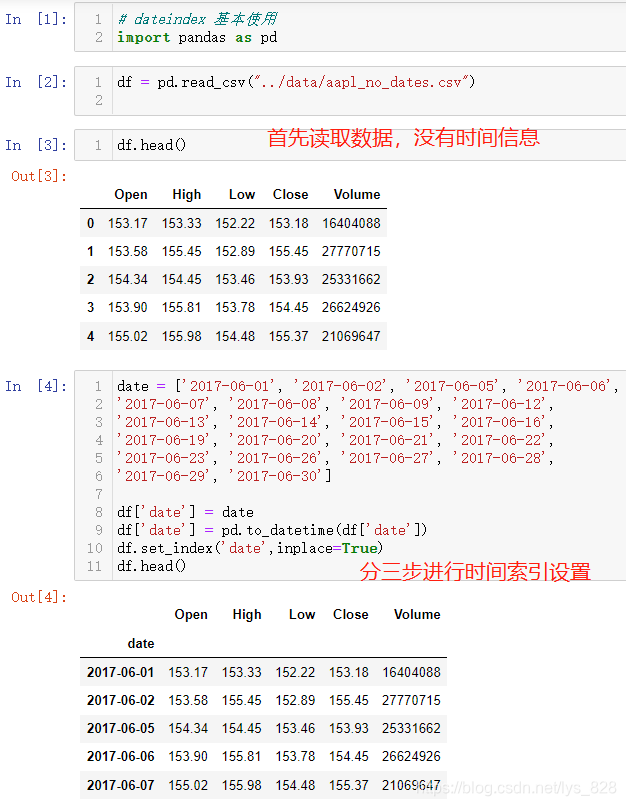
前面介绍过时间数据类型的转化和时间重采样,都是基于已有的数据基础上,那么有时候需要自己添加时间数据作为索引,时间数据如何构造的问题就逐渐浮出水面了。解决的方式就是采用pd.date_range()方法
首先看一下原来添加时间字段并设置为索引的方法,一共分为三步。第一步将时间字符串数据放置在列表中,然后赋值给df中的一个新字段;第二步就是将该字段的数据类型转化为时间数据类型;第三步指定该字段为索引。具体操作代码如下
5.1.1 第一种构造方式
如果采用pd.date_range()方法,直接省去了转化数据类型的操作,而且要添加数据量越多越能体现出此方法的优势,避免了大量手动输入,特别是这种股票数据,周末是没有数据,所以想使用循环一般也不太容易实现,但是pd.date_range()一行代码就搞定了数据的构造
基本的三个参数,start参数指定时间开始的数据,end参数表示时间结果的数据,freq表示时间构造的规则,这里的B代表着工作日
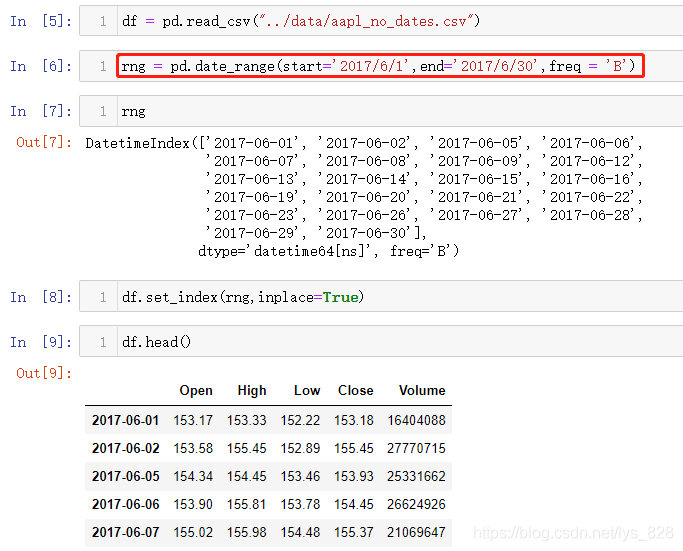
5.1.2 第二种构造方式
前面的三个参数相当于是指定了时间的跨度(有起始和终止时间)和生成时间的规则,自动生成的时间序列;有时候也有这样的需求:有起始时间和持续时间(没有终止时间)以及时间记录规则,最终构造时间索引数据,这时候就是end参数改成periods参数即可,比如从2020年1月1日开始,每小时记录一次,一共持续15个小时,生成数据如下
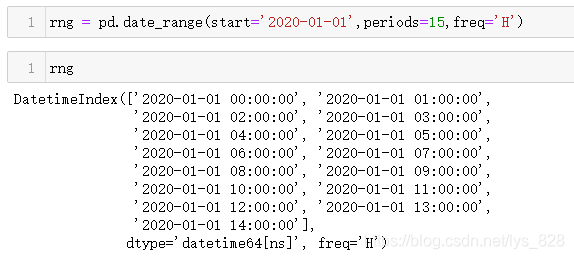
5.2 利用时间索引查找缺失值
就是按照两个DataFrame数据中的时间索引的数据进行求差集,然后求解出差异的数据,如果有需要可以进一步根据这些差异的索引获取数据(原理就是两个集合求差集),这种方式也可以拓展到不是时间序列的数据甚至是字段数据中

5.3 时间频率转换
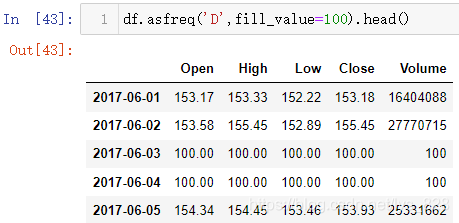
读取的是股票数据,属于工作日时段的数据,没有周末的信息,除了上面的差集求解外,还可以使用asfreq()方法,其中D为每一天,输出结果中就会显示出周末的时间索引,但是由于没有数据,默认显示空值
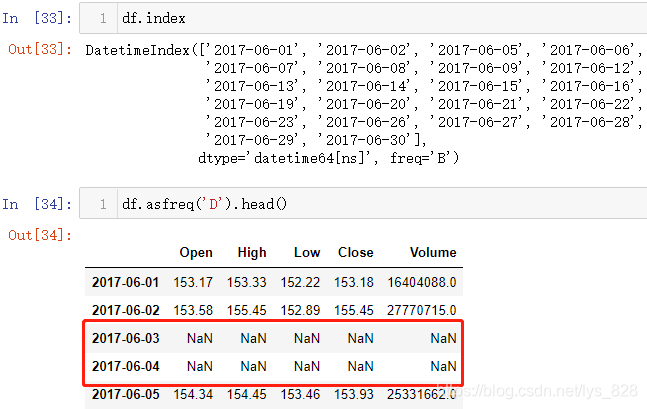
自然出现了缺失值,就有对应的处理方法,函数中的method参数就是用来解决这个问题,有两个可选的值,分别对应前面讲到的缺失值动态填充的方法,此外还有静态填充的参数fill_value,就是指定一个填充数据
动态填充
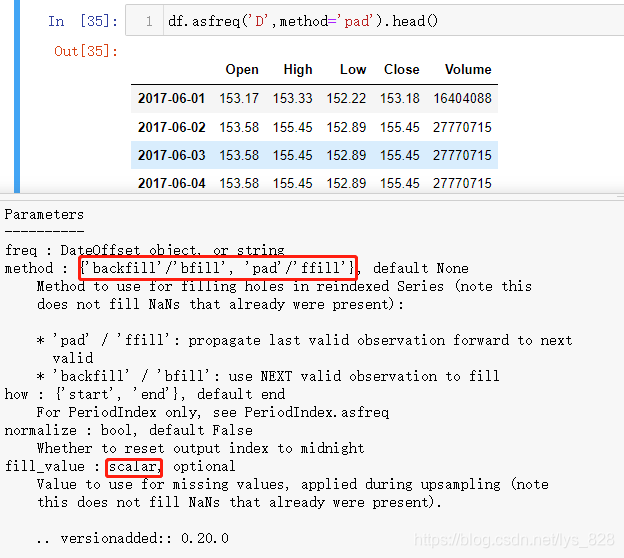
静态填充
5.4 基础应用
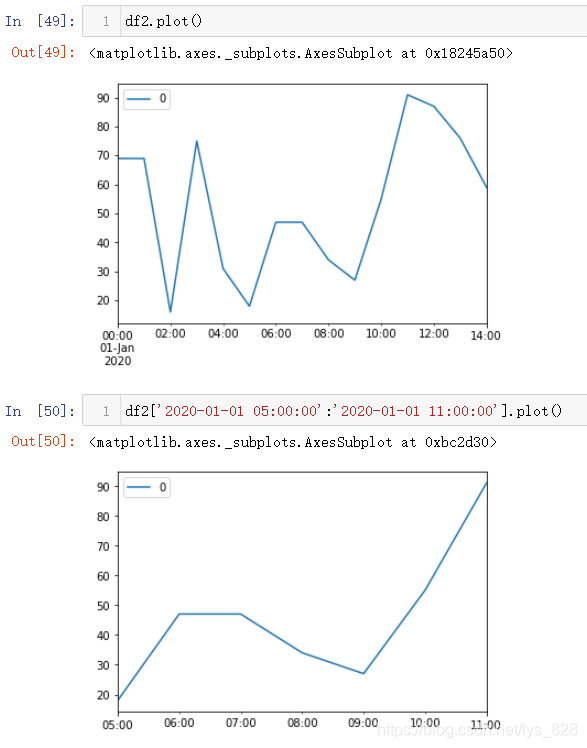
使用 pd.date_range() 生成时间索引,然后利用随机数绘制一个简单的图像

绘制图形时,可以选择默认全部数据进行绘制,也可以选取部分数据进行绘制图形
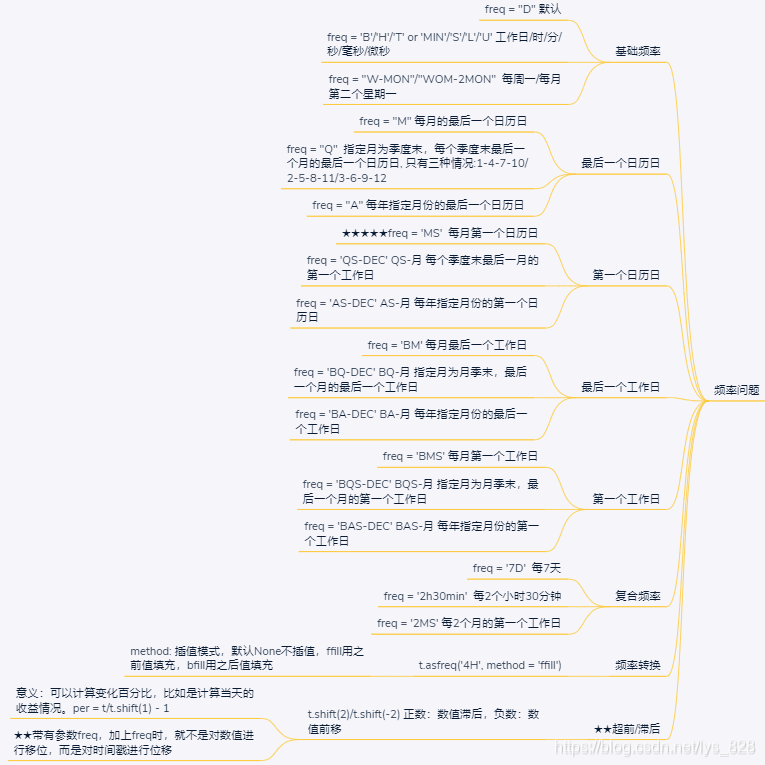
补充点:关于时间频率这里指定的规则很多,可以参考这篇文章:Pandas中时间序列处理(3)时间戳索引中date_range()方法及频率freq的变换,最后给出一个文章中总结出的脑图,有兴趣的可以自行阅读
6 节假日与工作日数据
通过上面的时序数据分析,发现有个时间比较显眼就是5月1号,这个在国外认为是正常的工作日,但是在中国就是法定的节假日,股票自然在节假日不开市,因此就有了解决国家之间认可的工作日和节假日的不同的需求
6.1 自定义节假日
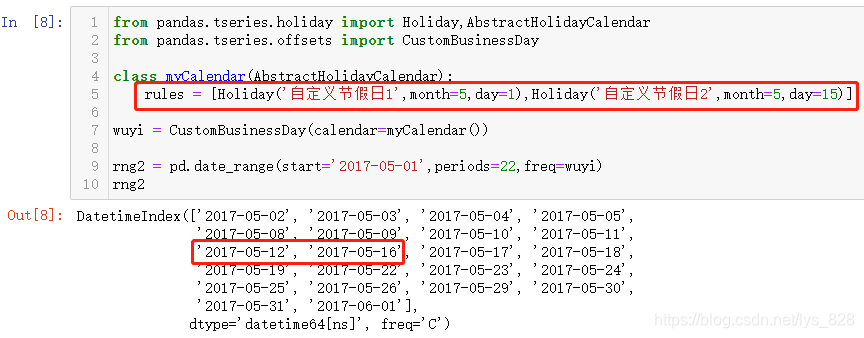
直接给出使用的模板代码,使用时在此基础上进行添加数据和稍作改动即可
from Pandas.tseries.holiday import Holiday,AbstractHolidayCalendar
from Pandas.tseries.offsets import CustomBusinessDay
#自定义节假日类,核心在于往rules列表里面加载自己想要添加的时间
class myCalendar(AbstractHolidayCalendar):
rules = [Holiday('自定义节假日1',month=5,day=1)]
#加载自己定义的这个类
wuyi = CustomBusinessDay(calendar=myCalendar())
#应用自己定义的这个类
rng2 = pd.date_range(start='2017-05-01',periods=22,freq=wuyi)
rng2
输出结果如下:(使用的步骤就是总结的三步,核心就是把自己想要添加的节假日信息放在rules列表中)

除了指定法定假日,还可以按照自己需要,随便指定一个日期,比如自己的生日都行,然后重新加载运行看一下,为了简单,直接假定生日为5月15(上面输出结果中存在的时间),输出结果如下
比如有些时候要研究事故,会分为工作日事故和非工作日事故,其中非工作日事故就进一步细分就有了节假日事故和正常的周末事故,刚好自定义节假日方式能够帮忙解决这个问题
6.2 自定义工作日
有些国家的工作日很特殊,但是为了业务需求,必须要处理这部分数据。比如埃及工作日,就是从星期天到星期四(甚至现在有的国家已经提倡工作四天,休息三天了),因此为了解决这个问题,就有了自定工作日的需求。代码模板如下
from Pandas.tseries.offsets import CustomBusinessDay
egypt_weekdays= "Sun Mon Tue Wed Thu"
b2 = CustomBusinessDay(weekmask=egypt_weekdays)
rng3 = pd.date_range(start='2017-05-01',periods=22,freq=b2)
rng3
输出结果为:(通过输出对比原来的结果,可以发现这里的输出确实按照了周日到周四时间进行输出)
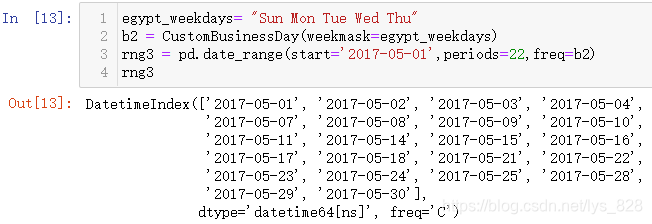
注意事项:核心就在于指定weekmask参数对应的字符串数据,该字符串第一个字符就是代表着一周工作开始的时间,最后一个就是结束时间,中间是以空格分隔,星期这里的简写没有点,对比官方给出的使用手册,默认是按照周一到周五作为工作日

6.3 综合自定义节假日和自定义工作日
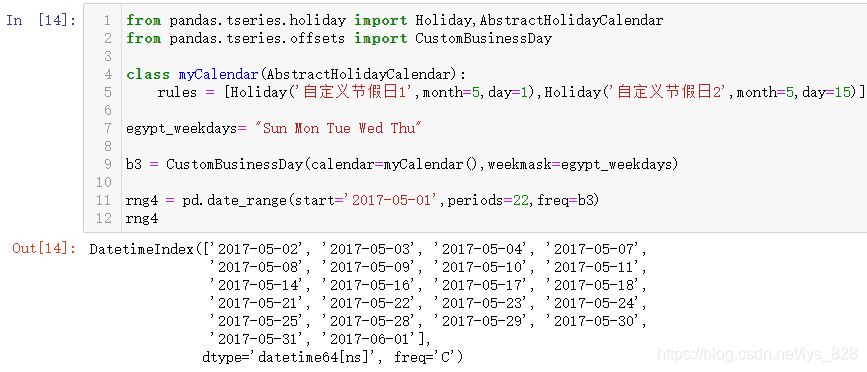
如果要把自定义节假日和自定义工作日结合,那就简单了,直接将两者合并就可以了,细心点的小伙伴可以发现这两个就是对应同一个函数/类的两个不同的参数,代码模板如下
from Pandas.tseries.holiday import Holiday,AbstractHolidayCalendar
from Pandas.tseries.offsets import CustomBusinessDay
#自定义想要的节假日
class myCalendar(AbstractHolidayCalendar):
rules = [Holiday('自定义节假日1',month=5,day=1),Holiday('自定义节假日2',month=5,day=15)]
#自定义工作日起止时间
egypt_weekdays= "Sun Mon Tue Wed Thu"
#加载自定义的工作日和节假日
b3 = CustomBusinessDay(calendar=myCalendar(),weekmask=egypt_weekdays)
#应用自定义的工作日和节假日
rng4 = pd.date_range(start='2017-05-01',periods=22,freq=b3)
rng4
输出结果如下:(需要留意的一点就是自定义节假日这里传入的是一个类对象,自定义工作日这里传入的是一个字符串对象)
6.4 核实自定义时间
上面自定义了工作日和节假日的时间规则b3,可以更进一步验证这个时间规则(或者更确切的说要使用这个规则进行时间运算之前进行核准),比如这里指定一个具体的时间为5月1号(这一天b3规则下是非工作日)
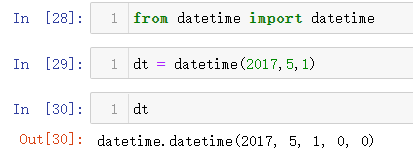
接下来就有一个难点就是如何确定这个日期对应周几?直接翻日历百度当然可以,有没有什么方法可以直接获取到,这里就能体现出时间数据类型的优势了,可以直接对这个变量采用dir()方法,看一下该类型数据中自带哪些已经封装好了方法/函数

发现里面有两个方法/函数和星期week有关,就可以直接测试一下,输出结果中一个显示1,一个显示为0

面对这种情况最简单粗暴的方式就是直接查看说明文档,开卷有益,多多看看说明文档有时候会恍然大悟,调出的文档如下(有没有发现惊喜就是这样意外,两者都是指向星期一Monday,而且两个函数的返回值描述信息都是一样)

所以可以确定2017年5月1号对应的星期一,那么再用测试过5个工作日对应的日期(输出的结果为5月8号,正好对应埃及的工作日时间规则,其中5号6号对应周末,2,3,4号对应本周的三个工作日,7,8号对应下周的两个工作日,故这样日期就对上了,核准无误)

7 时间类型数据处理
将字符串组成的列表数据转化为时间类型数据核心代码:pd.to_datetime()
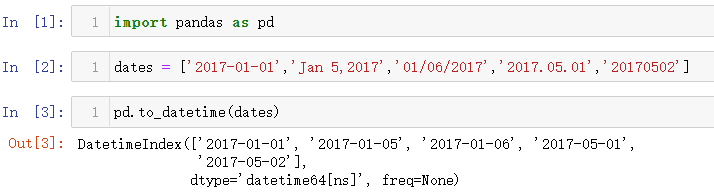
7.1 常见时间格式
7.1.1 时间格式转化
常见的年月日时间,操作如下(基本上就是这五种类型,三种年月日的表现形式,一种月份在前,一种日在前的表现形式)
如果再加上时分秒,看一下转化的结果(虽然后几个日期在输入时没有加时分秒,但是输出时为了保持格式一致都统一转化为相同的格式)

7.1.2 默认时间处理格式
上面测试的时间数据都很“正常”,没有产生歧义,有些时间数据可能就不是了,比如13-11-2017,11-13-2017这两个数据,到底是哪个正确,可以通过程序跑一下(本以为第二个时间格式是会报错,输出结果发现两种样式均可以)
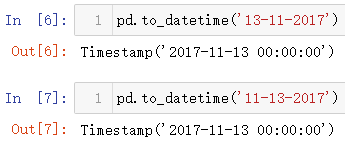
那么再看一下这两个时间格式,2017-11-13和2017-13-11哪一个日期会解析正确,还是和上面一样两个都是正确,输出结果显示第二种是不符合解析的格式要求,并提醒月份必须是在指定范围内
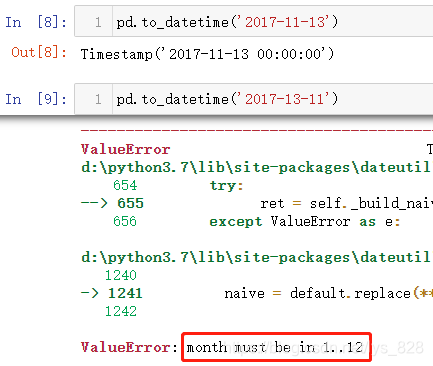
综上两个示例可以发现,如果把年放在最前面,那么Pandas解析时间的规则就必须是年月日的形式(这也符合正常人的认知),但是如果年放在后面的话,解析的时间规则发现月日年和日月年均可,这里就出现一个问题,上面的第一个示例中解析13这个值是超过12个月份的总数的,所以自动判定为日这没有问题,如果是02-04-2021和04-02-2021,系统会解析出来什么样的结果(又追加了三组时间格式转化的测试)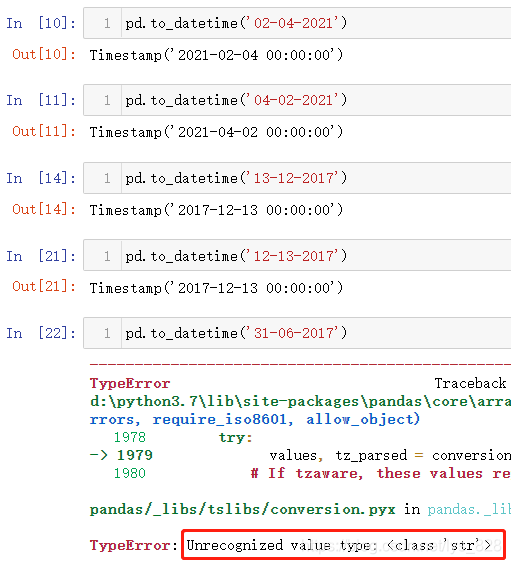
综合上面的全部的示例可以得出一下默认规则:
- (1)如果年份在前,时间格式只能为年月日形式
- (2)如果年份在后,需要判断月份和日相对于正常区间的取值的大小(月份1-12之间,日1-31之间)
- a)若月份和日均在正常取值范围内,用户输入的什么时间格式,程序就输出什么格式
- b)若月份超过正常取值范围内,日在正常取值范围内,这时候就会进行细分,如果日的取值如果在1-12之间,那么输出的结果就会发生日和月位置互换,如果日的取值大于12,那么程序直接报错
- c)若日超过正常取值范围内,不管月份取值多少,程序直接报错(对于那些特殊的月份日的取值不需要超过31,只需要超过该月最多的天数即可)
7.2 自定义时间格式(处理无效时间)
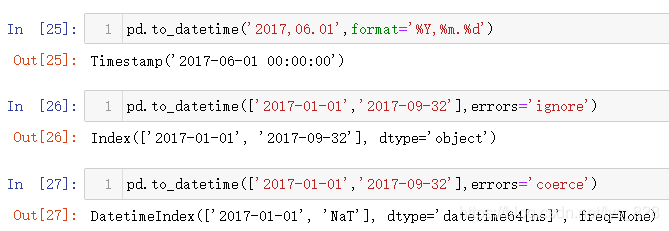
为了应对总结的(2)中 b)的问题,可以通过参数dayfirst来自定义时间的格式,从而避免这种自动位置转化的过程

除了这个参数外,还可以使用时间格式化方式,借助参数format,按照指定的时间格式进行转化(这种方式处理就很强,无论你输入的什么时间格式,只要有年月日的影子,不管中间有多么复杂的符号,都可以进行识别)。格式化中的字符d代表day(天),m代表month(月),Y代表Year(年),更多的时间字符的格式化符号可以参考:python中时间格式化符号

比如下面更多的无效时间数据处理,本质上有点类似正则匹配。如果出现的时间格式属于(2)中 c)的情况强行进行日期转换就会直接报错,可以借助errors参数进行防错处理,当errors = 'ignore',表示忽略错误的数据,如果errors = 'coerce',表示无效时间数据会被替换为空值(但是属于时间类数据的空值,NaT:Not a Time)
7.3 时刻与时间戳转换
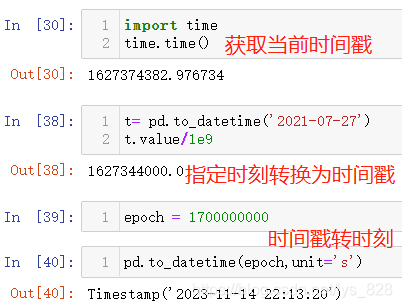
先明晰一个时间点:1970-01-01 00:00:00(计算机起始计数时间),时间戳就是该时间到今天这一刻的总秒数。
- 获取当前时间戳:
time.time() - 获取指定时间戳:
t.value - 时间戳转时刻:
pd.to_datetime()
8 Period时期操作
核心代码操作:pd.Period()
8.1 常见几类周期时间
前面介绍了时刻相关的时间处理方式,接下来看一下时期时间的操作与实战。分别按照年(Y)、月(M)、日(D)、小时(H)、季度(Q)、星期(W)进行梳理
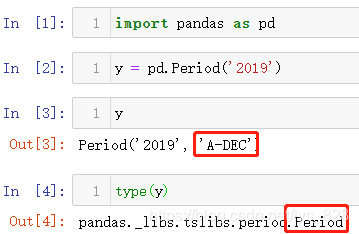
(1)年份
进行年份时期数据类型的构造,直接输出时期数据变量(比如这里的y,之后的m、d等变量)会告诉时期的时间还有对应输出的频率freq的规则,这里默认是A-DEC代表着每年最后一个月(即12月)的最后一个日历日(可以参考前面介绍freq时候的链接)
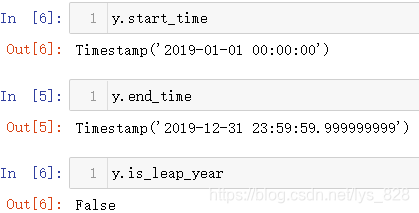
获取年份时期开始和结束的时间,以及是否为闰年的判断
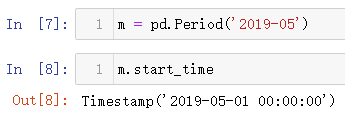
(2) 月周期
也是通过pd.Period()方法,然后传入的是年月,不是只传入月份数据
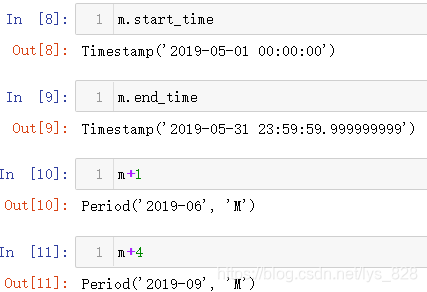
接着看一下时期的开始和结束时间,以及简单的时期运算
(2)日周期
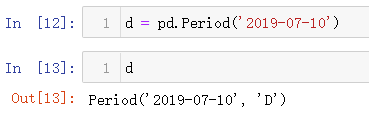
构造日周期数据
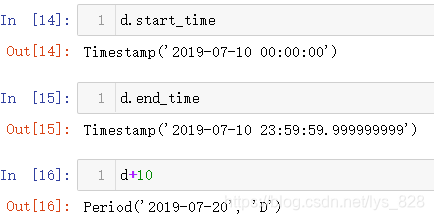
查看日周期的起始和结束时间,并进行简单的运算
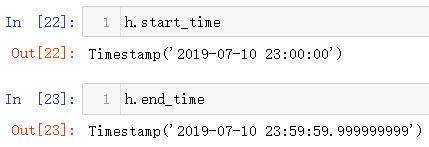
(4)小时周期
小时周期构造,注意此时默认的freq是S,也就是秒,如果进行运算最后的操作是在秒上面进行,要想以小时周期显示,应该指定freq='H',然后再进行运算,操作就在小时层面上运行
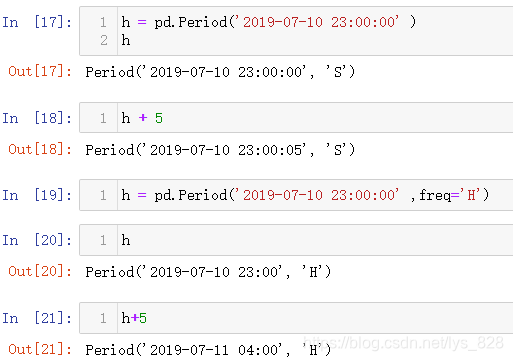
还是可以查看时期的开始时间和结束时间
(5)季度周期
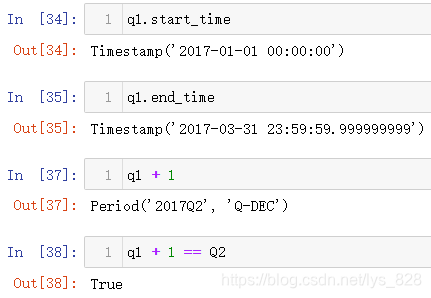
构造季度周期数据,特别注意Q-DEC的解释,代表着每年每季度的最后一个月的日历日,其中输入的q就代表季度,不区分大小写

继续进行时期的开始时间和结束时间的查看,此外简单的运算核实上面两变量的关系
(6)周时期
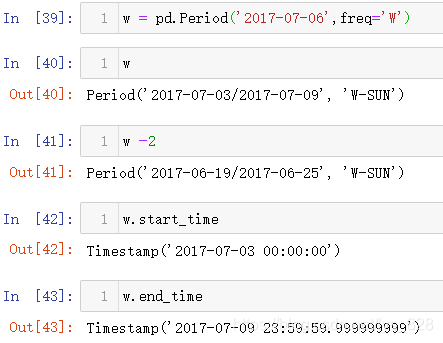
构造周时期数据如下,freq='W'代表着频率为周,具体的规则表现为:'W-SUN'按照每周的最后一天(默认也就是周日),同样也可以进行简单计算和开始与结束时间的查看
8.2 时期频率转化
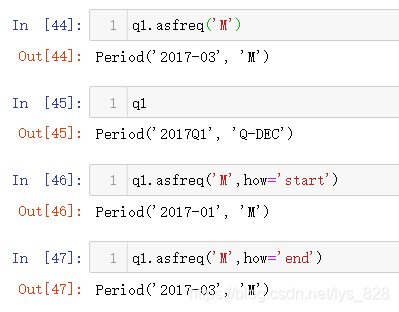
之前学到了asfreq()方法,在处理时期数据时候也可以派上用场,比如将刚刚的季度周期数据转化为月份周期数据。需要留心的是季度里面包含了3个月,将时期频率freq转化为月,这个默认变成1个月,默认取的频率freq就是每个季度的最后1个月,比如这里Q1表示第1季度,该季度的最后1月就是3月份,同时也可以通过how参数来控制取到的月份值
8.3 时期索引和时间索引区别
之前学过了时间索引DateTimeIndex,这里介绍时期索引PeriodIndex,注意输出结果中显示不同的数据类型
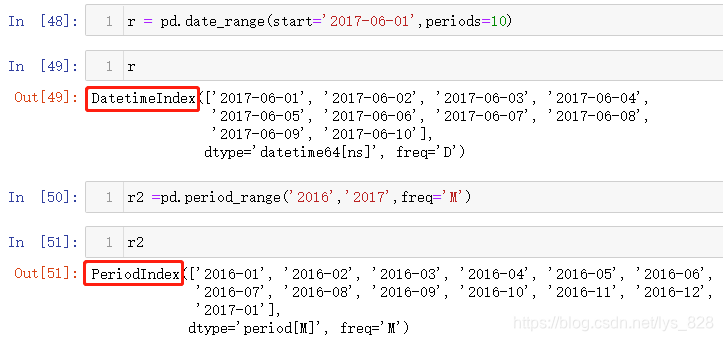
两者都可以生成一段时间序列,具体的区别通过代码运行结果来查看。如下都是生成2016至2017年的索引数据,除了整体数据类型不同外,具体到每一个元素的数据类型也不一样,一个是Period数据类型一个是datetime64[ns]数据类型,此外还有一个很大的差别,以月M作为频率freq的时期数据里面的数据最少是到月份,而后者是到具体的日,这也体现出时期本身的范围概念上的区别
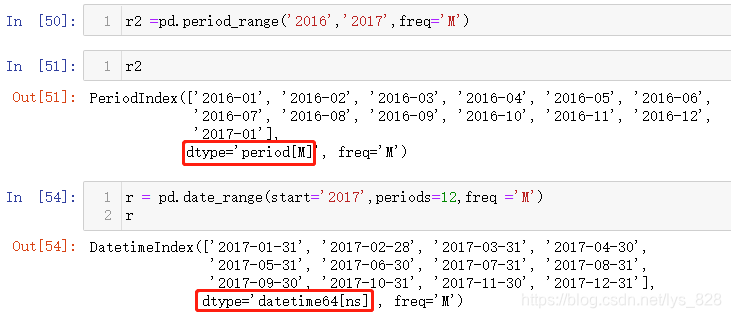
进一步可以采用频率freq为年Y,查看这个区别就会更明显
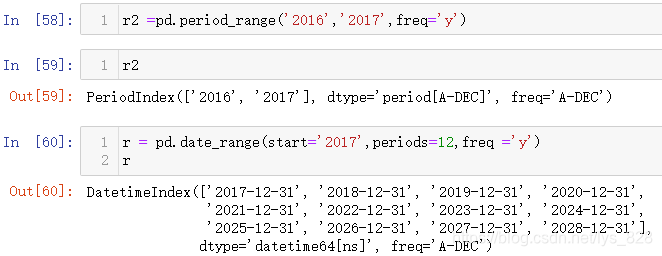
8.4 时期数据实战操作
8.4.1 生成简单的数据月报
利用numpy的随机数功能和现在学到的时期索引,时期频率freq按照月份取就可以了。核心就是在于数据的长度和时期索引的长度一致而且index设置为产生的时期索引
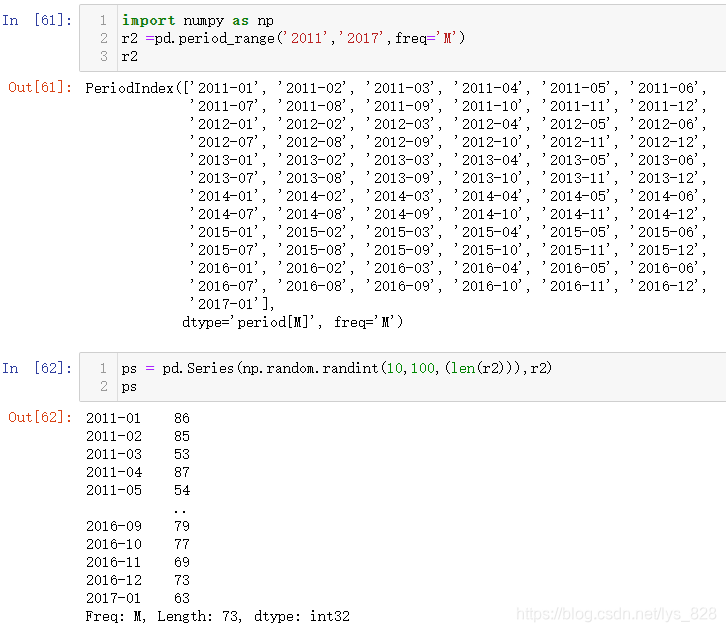
既然索引是时期,那么就可以使用之前的筛选数据的方式,比如筛选2015年1月到2017年1月的数据

8.4.2 营销数据实操
首先读取文件中的数据,观看一下读取内容中索引是简单的自然数,这里要将索引用时期数据来当,就需要把行数据转化为列数据,但是转化之前需要先处理一下Line Item字段的数据
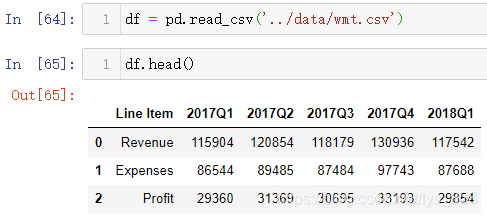
可以让Line Item字段的数据暂时作为索引,然后再转置一下,这样原来的行标题就变成索引了,也完美解决了索引中不全是时期数据的问题
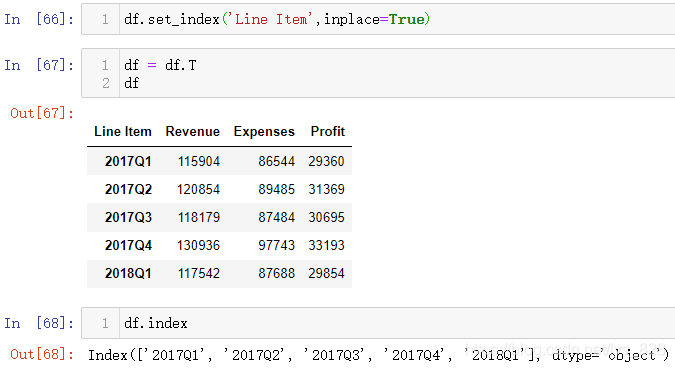
通过最后查看索引的情况,发现只是形式上符合前面介绍的时期数据的样式,但是本质上还是object字符串数据类型,因此需要进行数据类型转化。核心代码:pd.PeriodIndex()
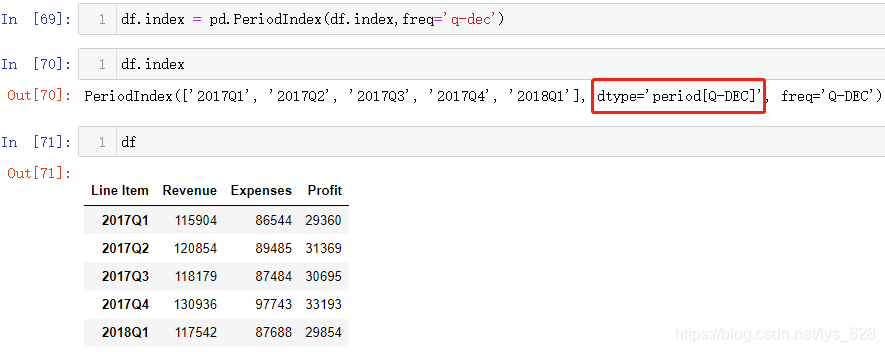
转化完毕后数据类型就是时期数据,然而这里Line Item名称却在时期数据这列上方,仿佛是时期索引的名称,实际上不是,因此强迫症表示有必要进行设置索引名称(注意上面输出索引这一列信息,没有name的属性,因此这个Line Item名称属于横向第一列的各字段名称,赋值完毕重新运行后就有了name属性),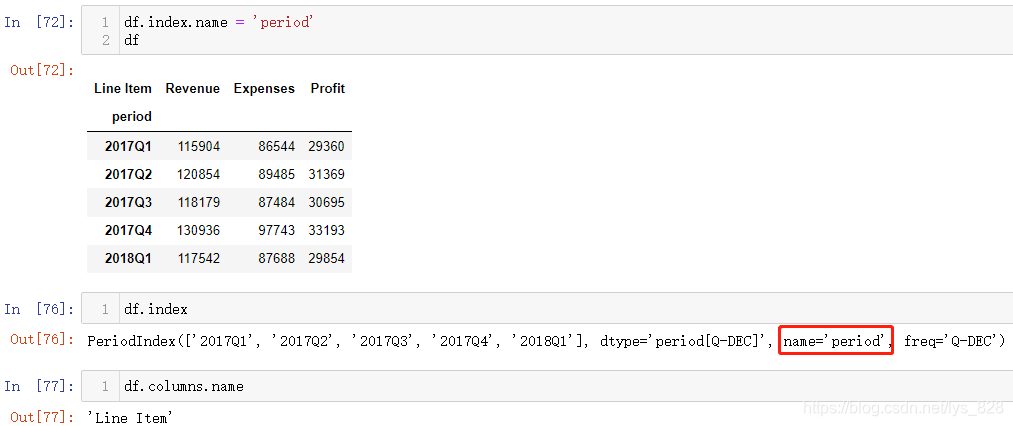
既然是时期索引,索引中每一个数据都是Period数据类型,就可以使用前面反复使用到的时期开始的时间和结束的时间,比如进行单个时期数据的起始和结束的时间查看
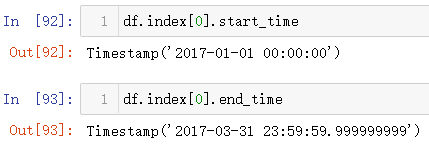
那么将单个数据扩展到整个时期索引数据中该怎么操作呢?还记得前面重点说明字段的map方法的使用,直接配合着lambda就会发生不可思议的效果(x就是代表着时期索引中的每一个时期数据)
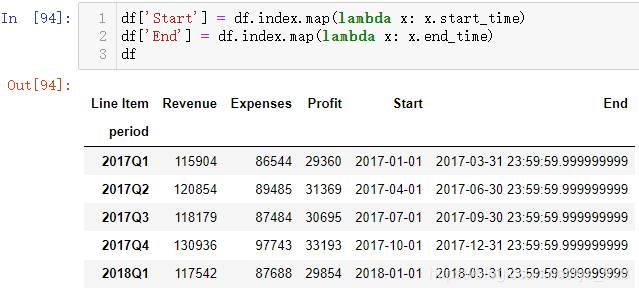
输出的结果中就增添了两个字段,其中End字段的时间格式并不符合我们的要求,借助前面介绍自定义时间格式的方式就可以把输出的样式修改过来,比如去掉最后面的一大堆9还有那个小数点,只保留精度到秒即可。
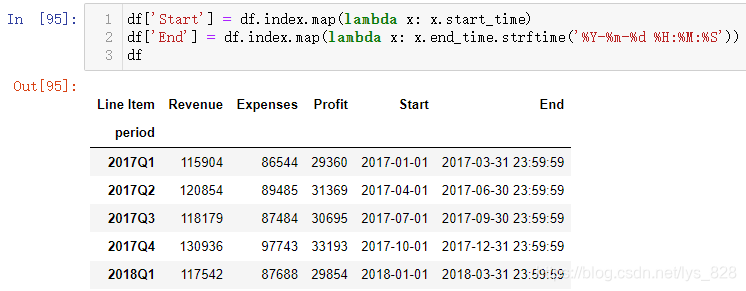
可能和前面的自定义时间格式操作稍有不一样,前面用的pd.to_datetime()方法中的format参数,这里使用的是datetime数据类型下自带的格式化时间的函数strftime(),其中的f就代表format的含义,最终时间格式化的字符格式都是一模一样,由此整个营销数据实操案例就讲解完毕
9 时区转化功能
两个核心的基础常识:
- (1)地球是圆的,国家处于不同的时区中,中国位于东8区
- (2)时间分为两种,一种是绝对时间(也就是本地时间),一种是相对时间(时区时间)
首先进行测试数据加载,由于第一行不是想要的数据,可以直接选择跳过,然后时间字段自动解析并作为索引(这里复习前面讲过的各种参数)
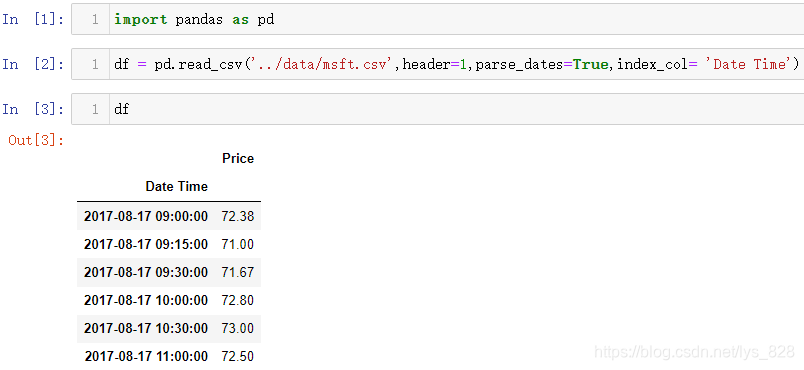
9.1 时区位置
核心代码:tz_localize()
比如柏林为东2区,上海为东8区,输出的结果就会在原有的时期数据基础上加上对应的时间东区为正,西区为负
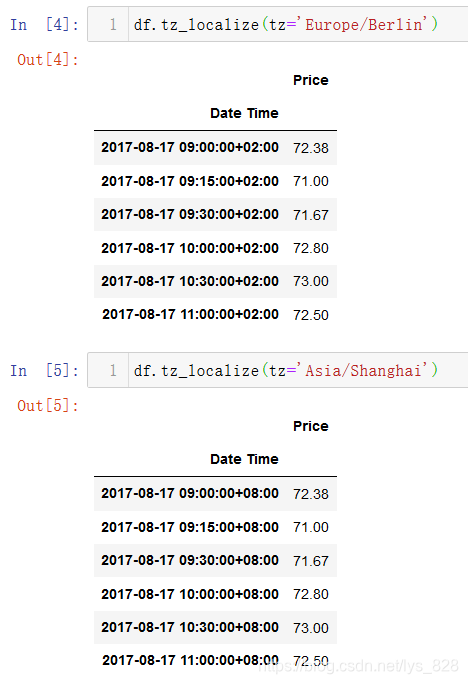
具体可以使用的各城市的时区信息能用以下代码查看
from pytz import all_timezones
print (all_timezones)
输出结果为:(结果太多了,因为世界上的国家都有200多个,再怎么划分数量也不会少,只截取部分数据)
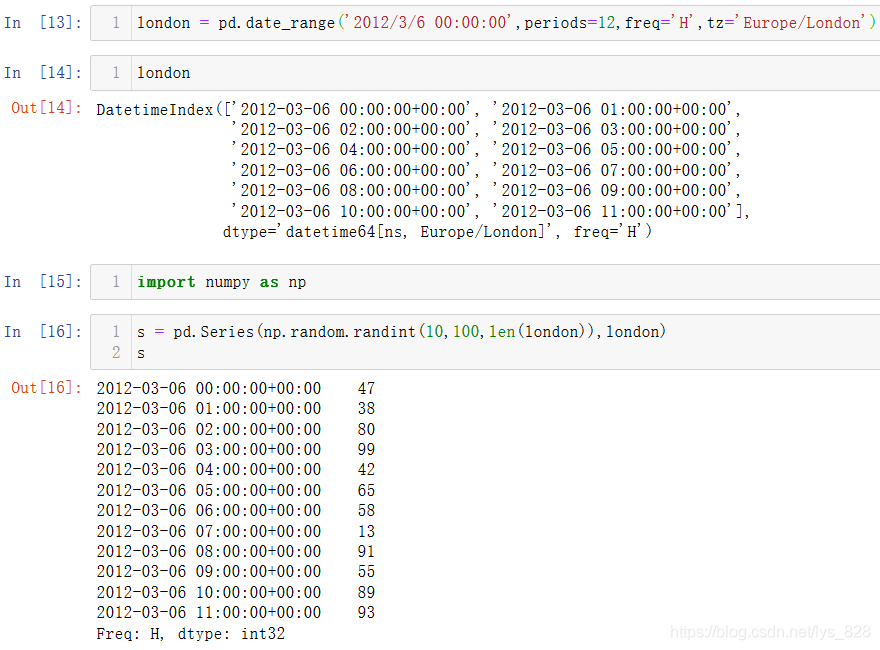
9.2 生成带有时区的数据
核心代码:pd.date_range(tz='某时区')
还是原来的date_range()方法,里面的一些参数之前已经介绍过,这次是添加了tz表示时区的参数,就会自动进行转换,结果中添加了相应的时区结果
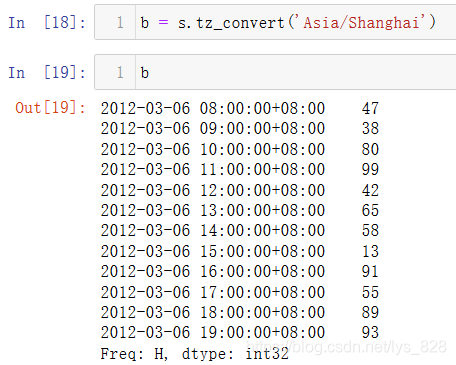
9.3 时区转换
核心代码:tz_convert()
将刚刚生成的时区数据转化为上海东8区数据,直接在括号里面加上要转换到的时区名称即可
9.4 不同时区间的数据计算
两个都是时期索引的时区数据,即便是不同的时区也可进行计算,计算的依据:就是按照时区时间转化为同等对应另一个时区的时间(比如伦敦零时区和上海东八区的时间对应相等)的时期索引进行运算。结合着具体事例进行查看,这里需要用到一个时间平移的函数shift(),下面括号里面填写了1,表示将原来的时间往下移动一个小时,第一个数据自然就被空值填充,其它的数据都是都上一个数据进行填充
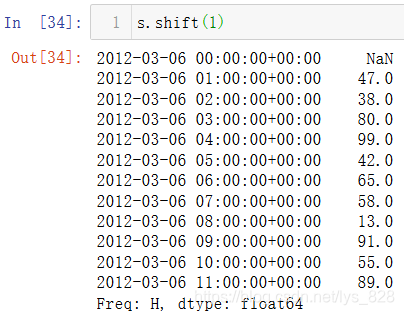
然后将变化后的s变量重新赋值,使得变化生效,然后在和b进行相加(b就是对应时间等同的东8区),输出结果如下
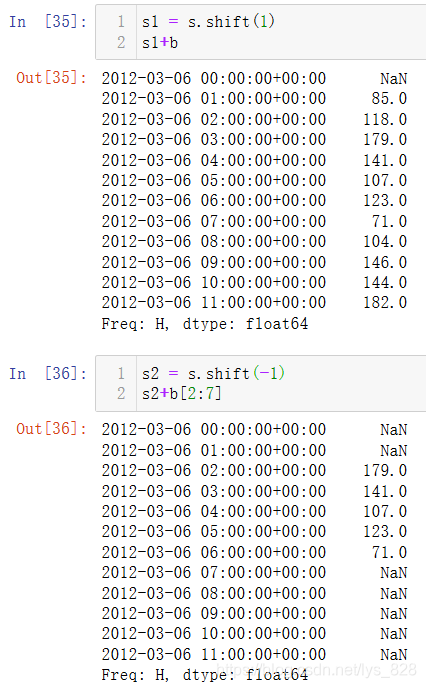
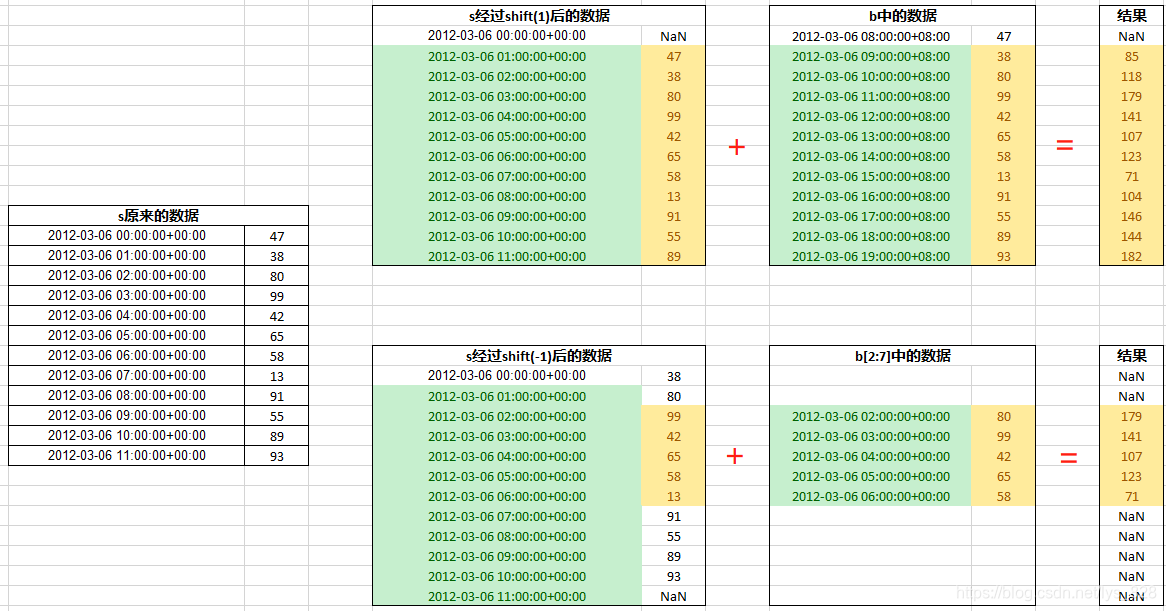
可能直接还搞不太清楚,配合这个Excel中的这个示例图进行理解会好一些,需要厘清出下面四点
s经过shift(1)后第一个数值为NaNs经过shift(-1)后最后一个数值为NaNb就是和s不同时区等同的对应时间,计算时会自动转化为零时区b[2:7]取数据后程序会把东八区的时间自动转化为零时区的时间进行计算- 有数据的索引行才进行计算,有一侧数据为空,程序不进行计算
10 时间平移
核心代码:DataFrame.shift()
两个重要的参数:periods参数指定移动的步幅,可以为正亦可为负(如上不同时区计算);axis参数指定移动的轴,1为行,0为列
首先进行测试数据读取(一共10行)
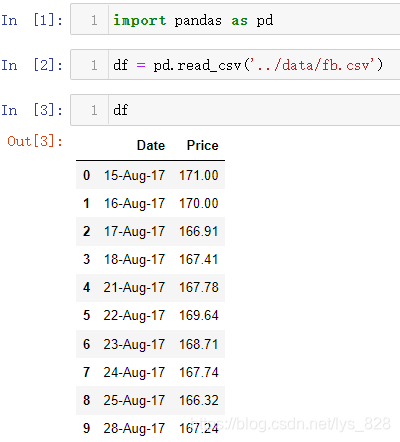
看到了有时间字段,那就重新读取数据并将时间指定为索引(养成习惯)
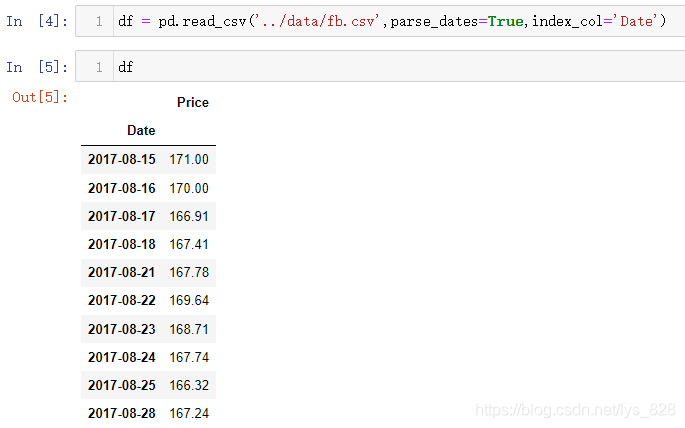
简单用图形看一下数据的情况(注意如果Pandas的版本过低执行可能会报错,可以升级一下)
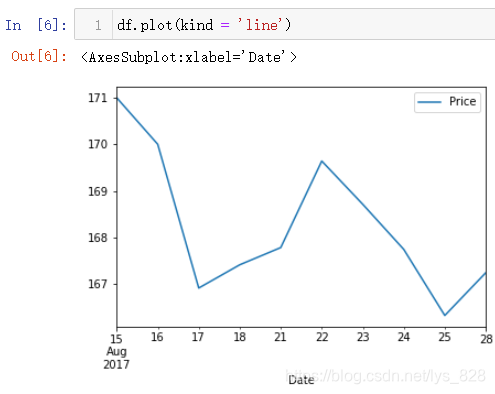
10.1 shift数据平移
前面已经用到了这个功能,这里通过图示来进行说明。如果shift()括号里面的periods指定为1,通过结果图中可以发现最终的图像向右移动一天的长度,超出的部分和第一天也就是15号的数据就不显示了(里面还有一个参数freq,没有指定就会根据时间索引数据来进行推断取值,比如这里的时间索引就是针对的每天,自然移动1就是指1天)
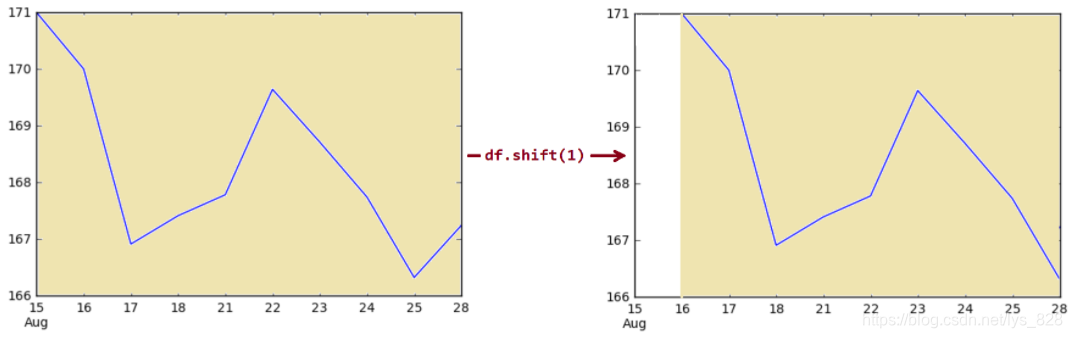
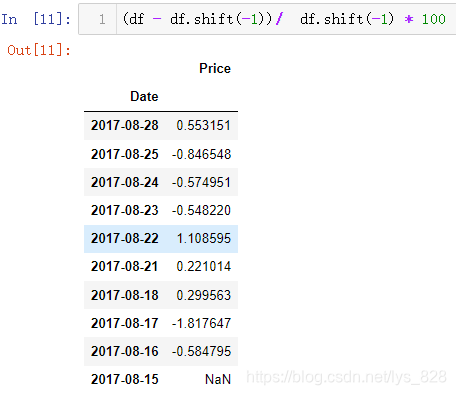
shift()功能具体应用,举一个很常用的实例,就是计算价格每天的增长率。为了防止被搞晕,统一按照如下步骤或者说规范进行:
- (1)最近时间放在最前面,可以通过
sort_index()方法中的ascending参数进行设置, - (2)使用
df.shift(-1)将时间对应的数据上移一个时间周期 - (3)使用
df-df.shift(-1)求解出当天相较于上一个时期的增量数据 - (4)如果要进一步求解每日增长率,上一步得到的结果再除以
df.shift(-1)即可
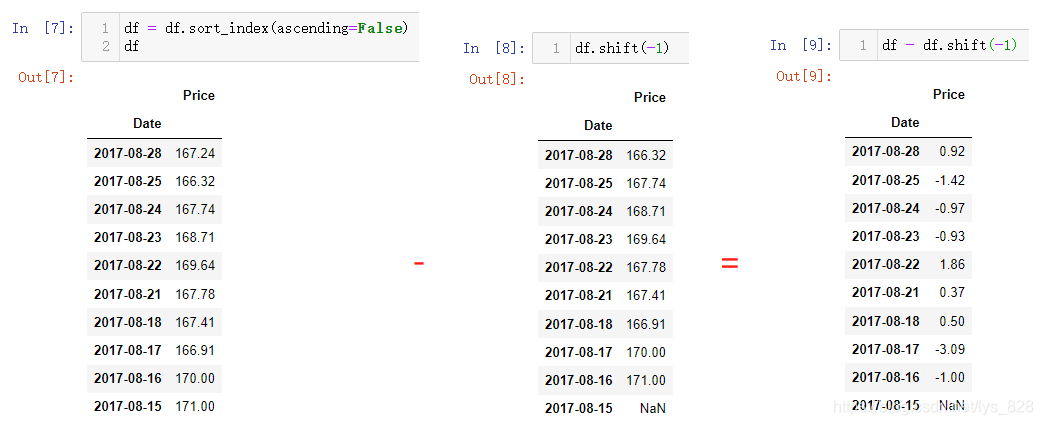
求解的每日增长率如下:(同理利用前面学过的时期频率转换和时间重采样,就可以求解出类似的每月增长率,每季度增长率等等)
10.2 tshift时间索引平移
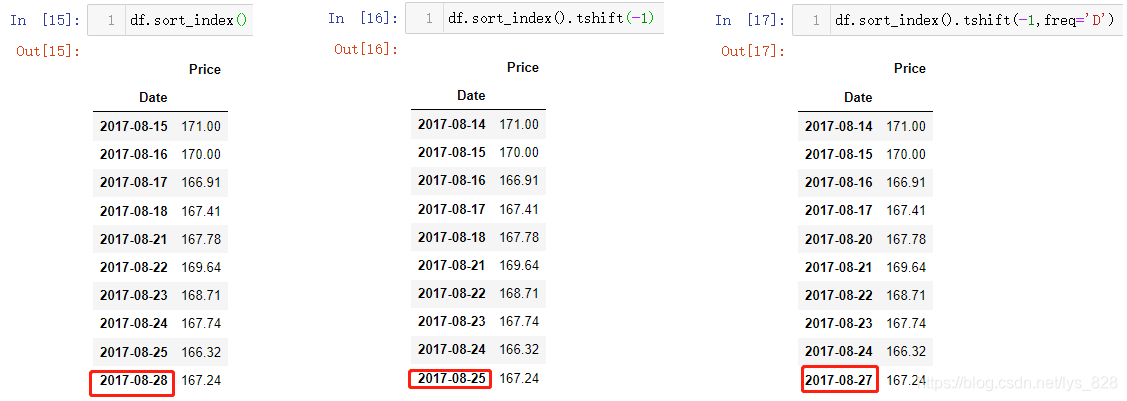
前面shift()方法操作的是时间索引对应的数据进行平移,tshift()方法则是对应着时间索引本身的平移,两个方法中的参数都是一致的
这里面有一个坑需要注意一下:指定freq和不指定freq是有所区别。
- 当只传递
periods参数时,系统默认根据时间索引解析freq,比如这里指定-1,所有的时间索引都是往下移动一个单元格,最上面的一个单元格使用原来单元格的前一天进行填充 - 如果指定
freq参数,那么整个时间索引是在原来索引的基础上全部减去1天
对比最后一行的时间索引的值,发现最初的时间为2017-08-28,不指定频率freq参数时,上一个单元格的时期数据向下移到到此单元格,然而指定频率freq为D,所有的时间索引值均减1
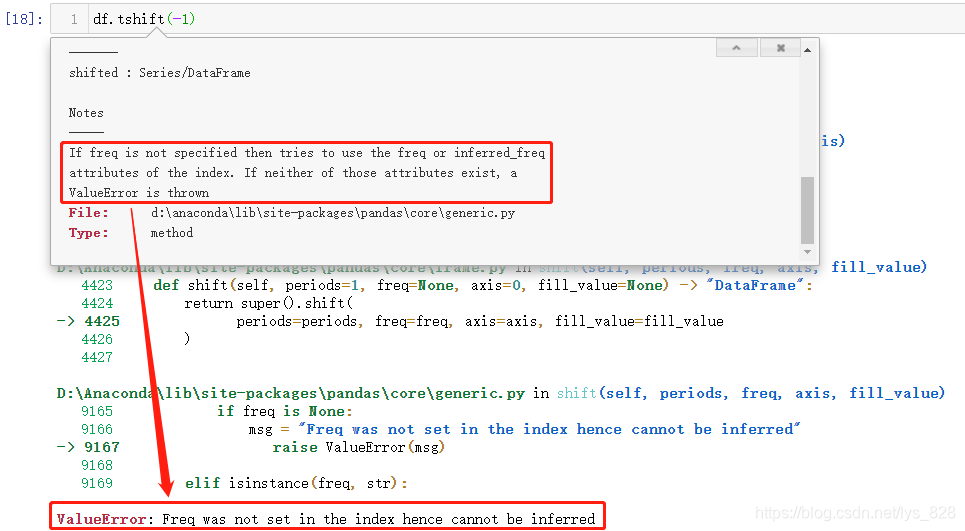
读到这里可能有所疑惑,为啥前面使用降序,这里有改成升序了呢?因为tshift()会根据时间索引,自动推断出相对应的freq,但是进行降序后,程序推断不出来直接报错,进行指定freq='D'才发现上面的这个坑。直接使用df.thift(-1)结果如下
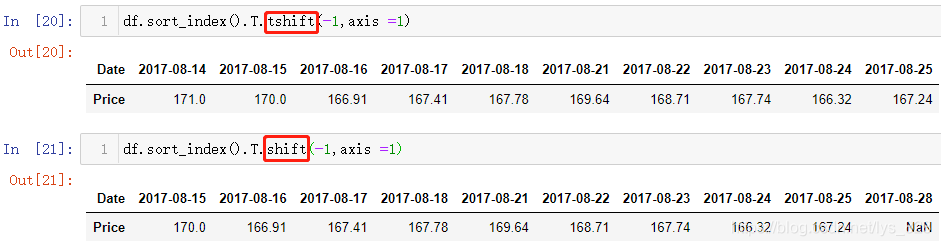
补充点:shift()和tshift()函数中都有一个axis的参数,就是把执行的方向变了,那么对应时间索引的方向也需要变,将原数据转置即可(默认axis=0,时间索引是在列方向上;axis=1,时间索引需要在行方向上)
10.3 diff 差值运算
先创建一个示例数据,代码如下
df =pd.DataFrame(
{
'a':[1,2,3,4,5,6,7],
'b':[11,21,31,41,51,61,71],
'c':[13,23,33,43,53,63,73],
}
)
数据输出结果如下:
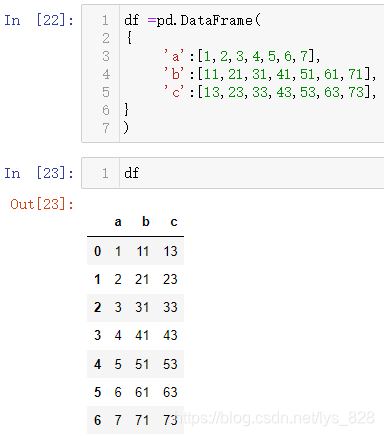
然后使用diff()方法看看最终的输出结果如何,结合这输出来理解函数的功能。输出结果中的内容正是实现df-df.shift(1)的操作:下一行的值减去上一行的值
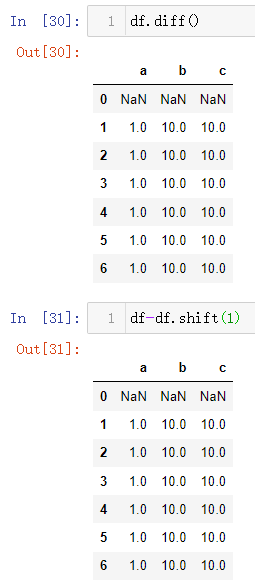
该方法也有axis的参数,默认就是axis=0,针对于行操作,当指定axis = 1时候就是针对列操作
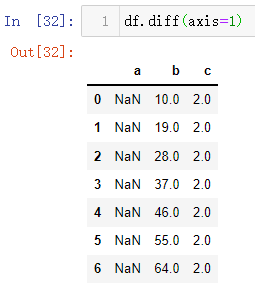
diff()函数中的参数相较于之前的两个方法,少了freq参数,就只有periods和axis两个参数,periods表示数据平移幅度和上下方向,axis表示了数据计算方向(横轴还是纵轴,即行还是列)
11 常用数据类型和数据类型转化
11.1 常用的7种数据类型
| 数据类型 | 介绍 |
|---|---|
| object | 字符串数据 |
| int64 | 64位整数 |
| float64 | 浮点数,常用于表示带有小数的数值 |
| bool | 逻辑值,取值有True/False |
| datetime64 | 时间和时期类型 |
| timedelta | 表示两个时间的差值 |
| category | 分类数据 |
11.2 数据类型转化
Pandas中常用的数据类型转换有如下两种方式:
- (1)
df.字段名.astype('目标数据类型')/df.字段名.map('目标数据类型') - (2)
pd.to_numeric() / pd.to_datetime()/ pd.to_timedelta()
第一种比较常用对于基础数据类型之间的转换,比如字符串,整型,浮点等,第二种主要处理时间,而且这类转换函数里面还有一个errors参数,可以指定erros='ignore'就会自动忽略转换中的错误
11.2.1 餐馆销售数据实操
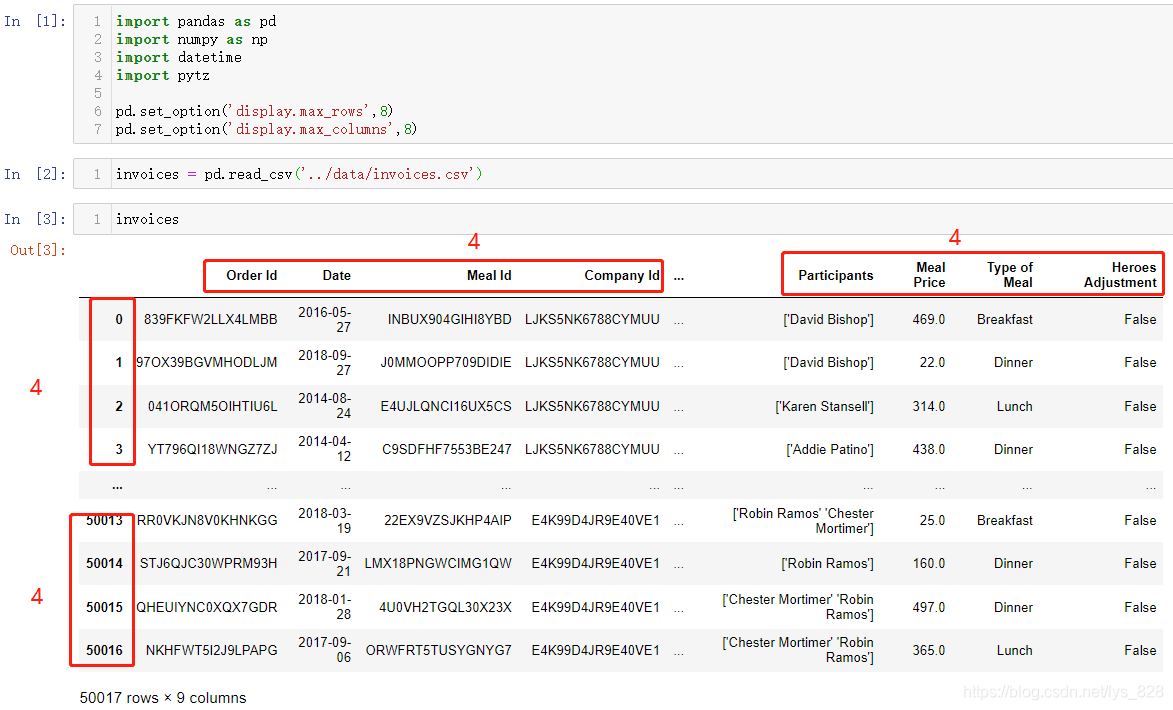
首先导入需要使用的模块,并进行Csv文件的读取,总共有50017条数据,9个字段
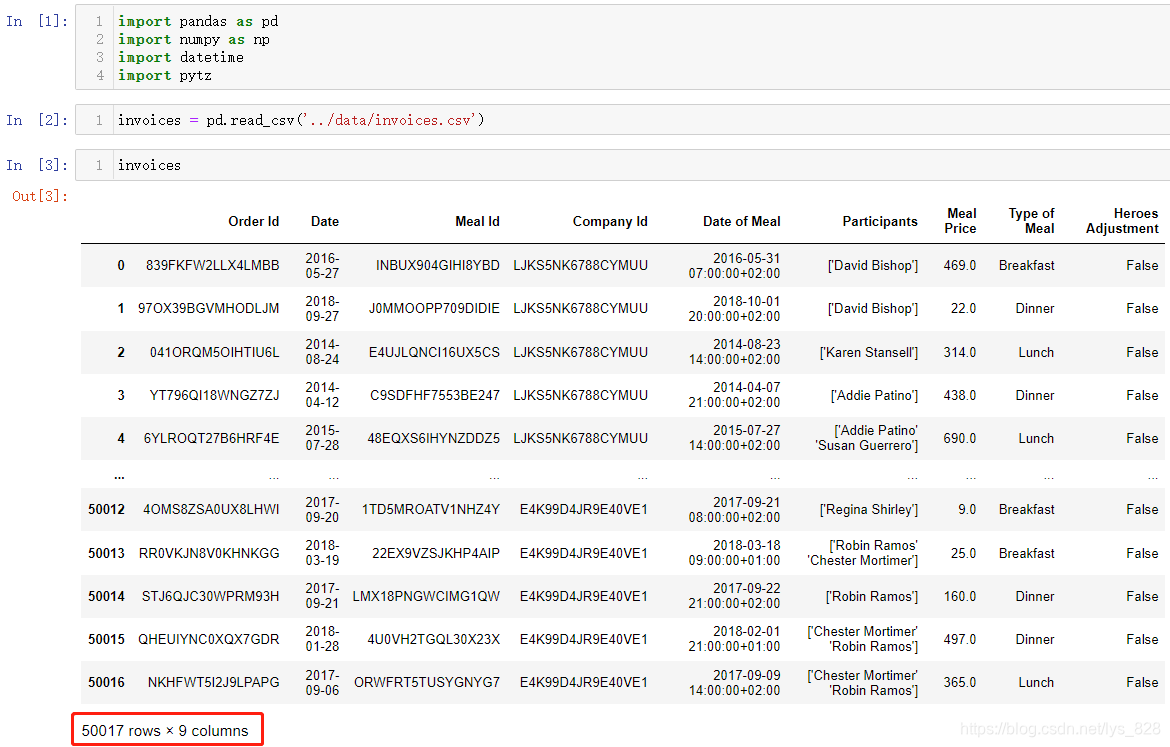
在第二部分缺失值处理的开始就介绍了如何查看字段的数据类型,这里可以再复习回顾一下,使用info()方法会输出数据的基本详情,包含了所有字段的数据类型
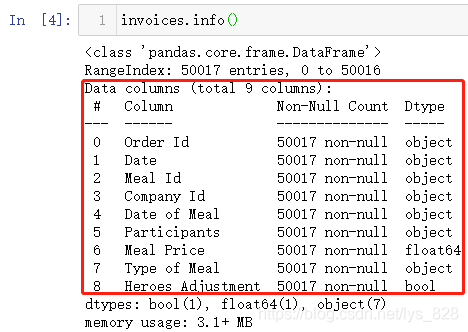
红框上面的两行分别输出变量的数据类型为DataFrame,总索引数量以及索引开始和结束的范围;红框中的内容就是各字段的情况,包含了字段总数,字段名称,缺失值计数和对应的字段数据类型;红框下面会把个数据类型进行汇总,给出使用的内存大小
进一步观察各字段的数据类型发现很多的字段都不是应该处于的数据类型,比如带有ID的字段,这种一般就是整型数据(有的可能是字母和数字混用),包含date的字段也明显是时间或者时期数据,还有一种就是带有Type也应该归为分类数据。使用第一种数据类型的转化方式操作部分字段
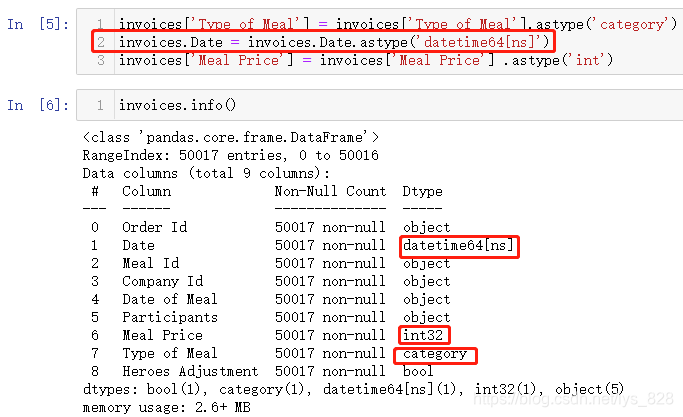
注意上面第五步中invoices.Date的使用,因为这个字段名称中间没有空格,可以直接使用,如果包含就不能直接用这种方式去一个字段,比如第五步中它上下的两个字段中都含有空格,所以只能使用中括号的方式进行字段选取。再次调用info()查看数据类型发现已经进行转化完毕了
第一种方式练习完成后,可以尝试第二种方式的使用,由于都是完整数据没有缺失值,故需要我们手动来定义一些异常值方便进行验证。之前定位具体的单元格信息是通过iloc[]方法,同样也可以使用loc[]位置定位的方式,但是注意中括号中填写的内容必须是先行后列(两种方法的相同点也都是先行后列,具体的差别是在于,iloc[]要求的是先对行坐标,再进列坐标;loc[]要求是先指定行索引,再确定列字段名称)
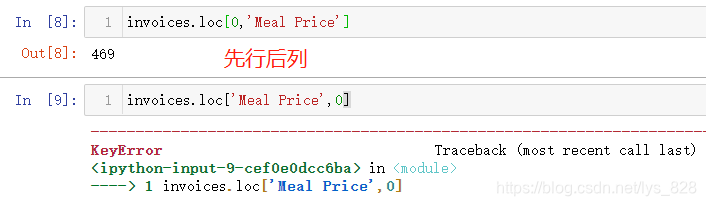
比如将行索引为35612,字段名称为Meal Price的值修改为hello,操作如下。只需要定位到这个单元格进行赋值,和iloc[]坐标定位赋值一致
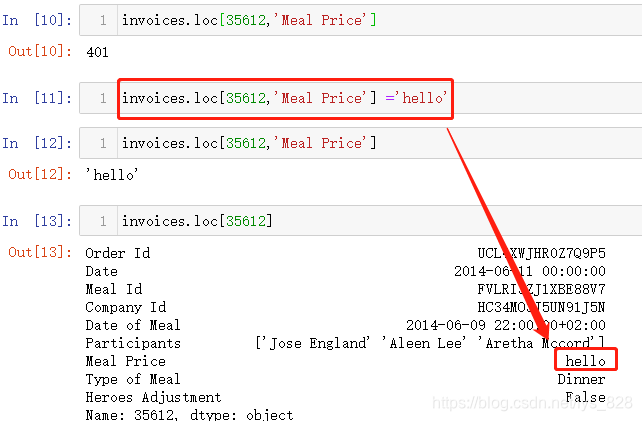
这里就属于我们手动给字段里面增添了异常数据类型,原本是价钱字段,自然为数值类型,刚刚添加的hello为字符串,用第一种方式读取看看结果,最终会把这个不能解析的数据给提示出来(这个数据是程序第一次解析错误提示的数据,如果这个数据处理过后,字段下面还有异常数据,会接着报错提醒直至所有的数据类型转化一致)
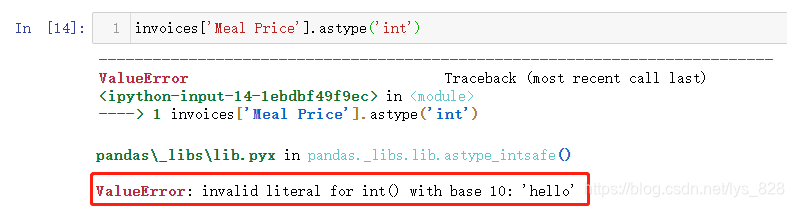
既然第一种方式没有办法了,就尝试一下第二种方法,输出结果没有报错,但是整体上这个字段的数据类型还是显示为object

然后查看一下刚刚那个位置的数据状态,输出结果证明还是没有发生变化,上面的处理是遇到报错就跳过去了
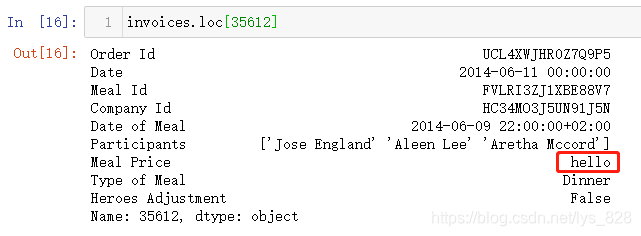
实际上遇到的数据并不会向我们刚刚操作一样可以直接知道异常数据类型的多少和具体的位置,因此要彻底解决数据转化的问题,就必须把这些异常数据都揪出来然后进行改正。首先解决异常数据数量的问题,模板代码如下
#中括号里面填写要查找的字段名称
invoices['Meal Price'].apply(lambda x: type(x) ).value_counts()
输出结果为:(最终会对字段中各类数据类型进行计数,并按照从大到小排序,另外下面的int64是指最后的这个计数结果Series的数据类型,不是指原有的字段数据类型,不要搞混)
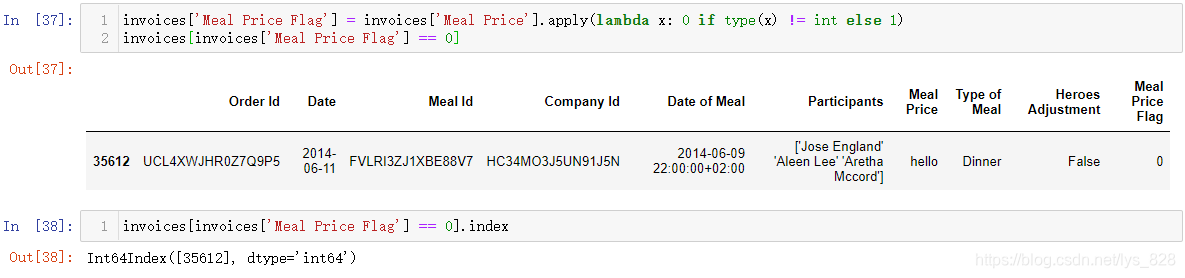
解决第一个问题后,再着手解决第二个问题,找出异常数据对应的位置,模板代码如下
invoices['Meal Price Flag'] = invoices['Meal Price'].apply(lambda x: 0 if type(x) != int else 1)
invoices[invoices['Meal Price Flag'] == 0]
invoices[invoices['Meal Price Flag'] == 0].index
输出结果为:(这个过程分为两步,首先就是对数据进行标记,数据是自己要的数据类型标记为1,不是的就标记为0。为了避免破坏原数据,生成一个标记字段,然后根据该字段数据取值得到标记为0的数据或者数据所在的index就完成任务,剩下就是要自己手动一个个把错误数据纠正了)
如果觉得这些异常数据类型的数据不需要进行处理,那问题就简单了,之前介绍时期操作时候也有errors这个参数,对应取值可以为errors='coerce',这个参数赋值也适用第二种方式的处理,表示将异常数据类型直接填充为空值
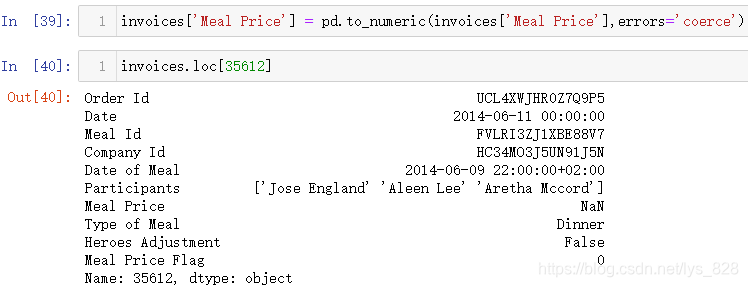
空值不影响程序对于数值的运算,但是会影响数值运算的结果,上述处理完毕后一般要以某个统计量进行缺失值的填充,多为中值,均值等,比如这里就以中值填充
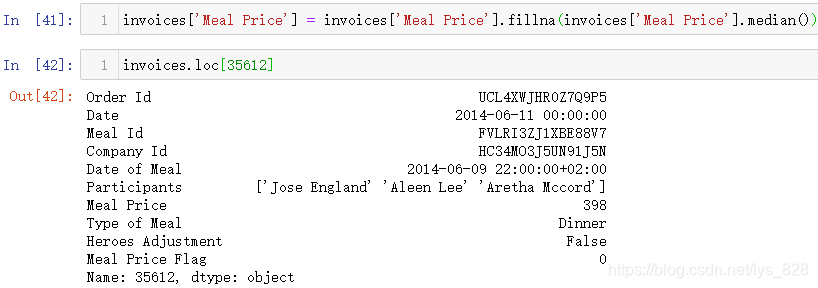
填充完毕后,再看一下这个字段的数据类型,自动变成了float64的数值类型
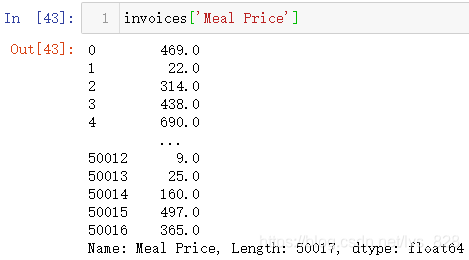
既然都是数值了,那这时候再使用第一种方式操作就没有问题了,注意两个方法的使用上的差别

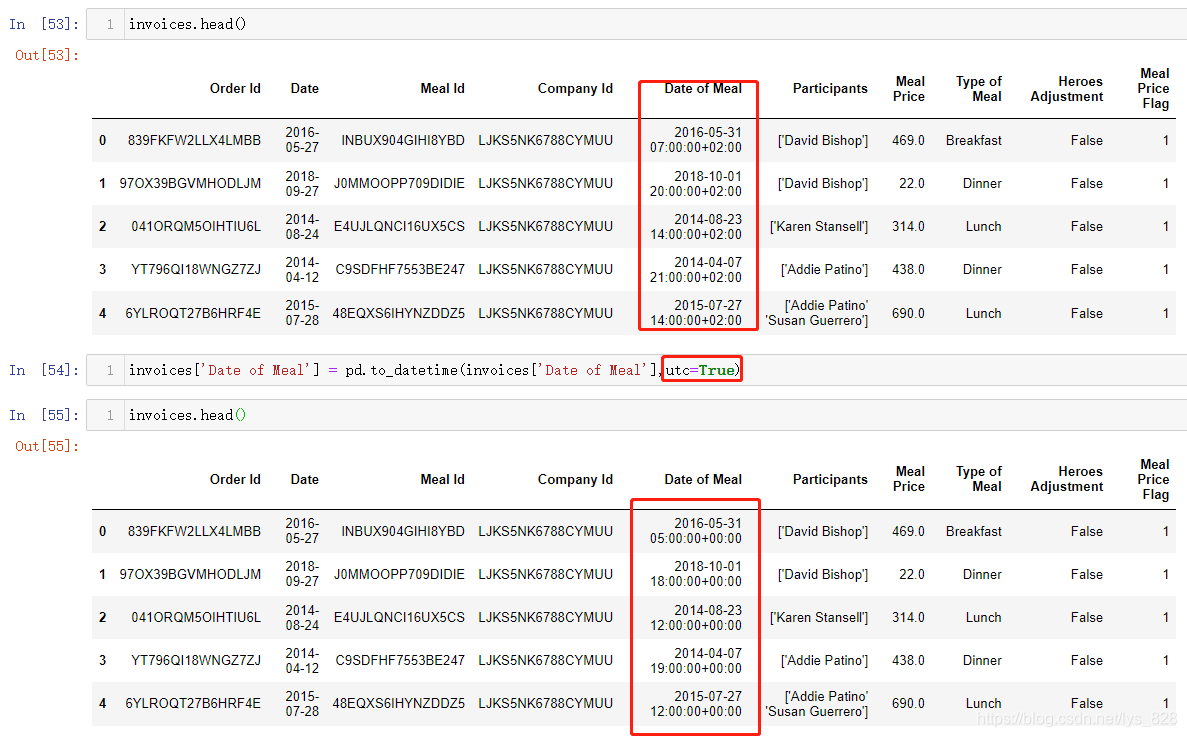
这份数据中还有一个特殊的字段就是Date of Meal,这个时间是时区时间,转化为标准时间,就是在原来时间的基础上减去两小时就可以了,但是不用自己操作,函数里面有个utc参数,指定为True即可
至此餐馆销售数据实操中常见数据类型转换的核心部分就全部梳理完毕了
11.2.2 时间数据类型转换
这里就补充一些加特技的时间数据类型转换,比如之前的自定义时间格式借助format的功能已经很强大了,但是还是有一个问题,format需要和输入的字符串里面的格式完全匹配,在一个字段中会出现很多噪音,我们想提取的时间就是在噪音数据中,因此就不存在一个固定的格式,比如下面进行时间格式转化的过程
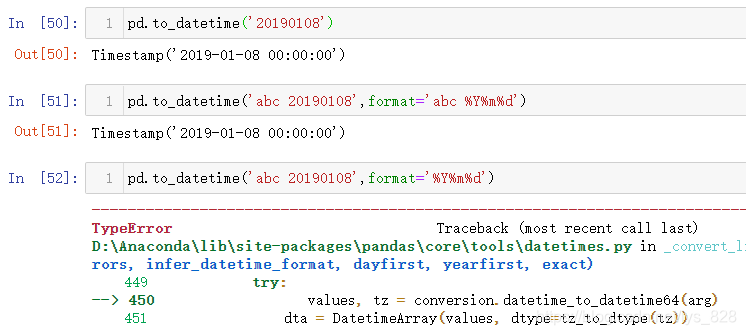
要想解决这个问题就是要把匹配的定位点只盯准我们要的时间格式就可以,周围的噪音数据就直接忽略掉,有点类似正则匹配中的分组。实现的具体方式是借助exact参数,设定exact=False表示模糊匹配,只要有就行的那种
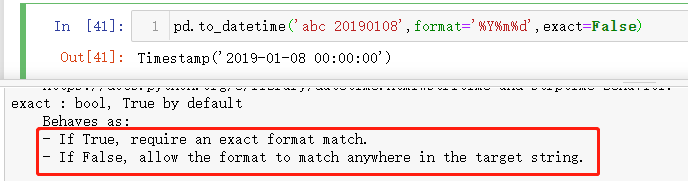
12 数据访问转换器
Pandas 中的转换器(accessor)功能很强大,可以理解为一种属性接口,通过它获取额外的方法,常用的转换器有三类:
.cat:用于分类数据.str:用于字符串数据.dt:用于时间
12.1 指定显示的行数和列数
还是以餐馆销售数据为例,读取数据,显示指定的行和列数,如果第二个参数指定为None就是表示显示全部的数据
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
之前读取的数据,要么是全部加载,但是中间的数据会被隐藏,要么就是指定head()查看前5行的数据,特别是有些时候字段过多时候会自动隐藏,需要了解如何显示指定的行数和列数,操作如下(第二个参数就是指定显示的长度)
12.2 时间转换器
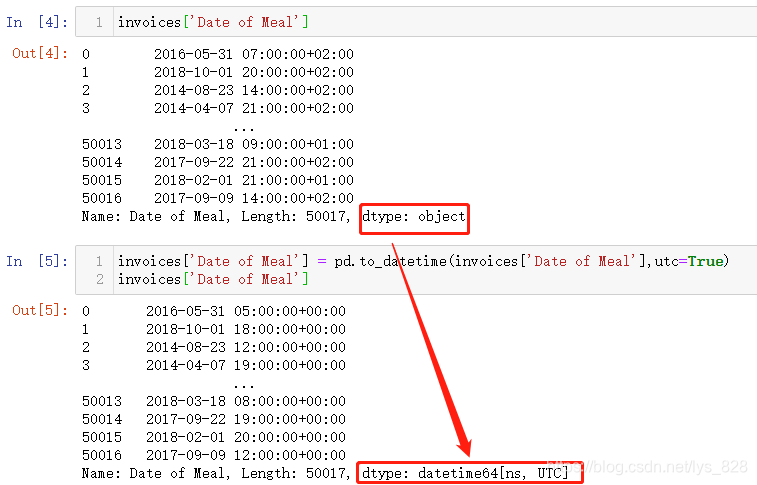
使用的前提是该字段的数据类型为时间或者时期数据,比如将Date of Meal字段转化为时间数据类型
然后惊奇的操作就要出来了,直接使用.dt方式就可以获得很多实用的功能,如下:
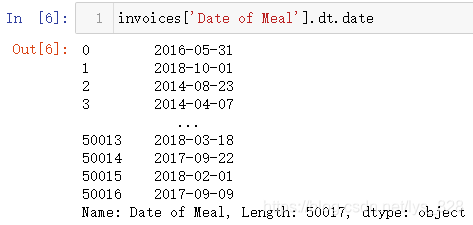
(1)获取日期信息
(2)获取年信息
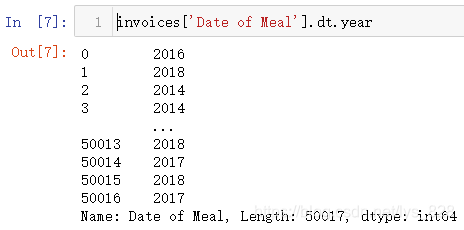
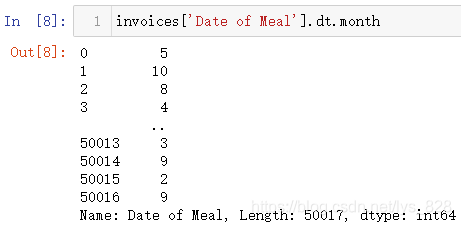
(3)获取月信息
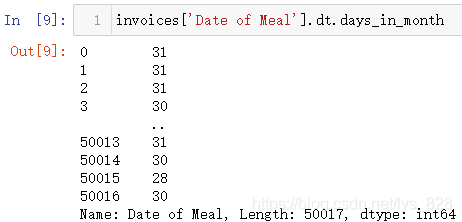
(4)获取时间对应当月的天数
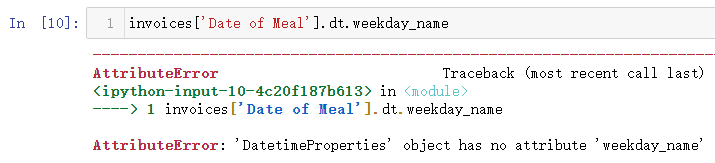
(5)获取星期信息
这个需要注意,老版本是有weekday_name这个属性,但是新的版本中会报错,如果前面装的是0.25.3版本的Pandas这里是可以正常运行
直接在输入的cell代码区安装指定版本的Pandas,然后在用这个方法显示正常
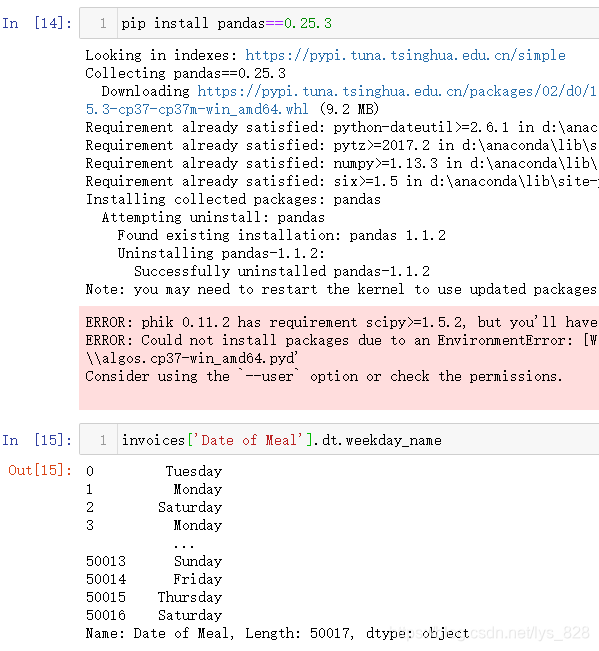
1.x版本中查看周信息,6.4部分核实自定义时间已经介绍过了,就是weekday()和isoweekday(),最终都是返回星期的信息只是返回的数字代表着星期不同,这里就不再赘述
(6)获取季度信息
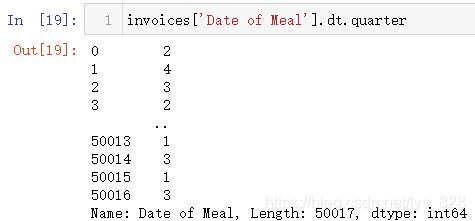
.dt时间接口中的函数和属性很多,可以根据dir(DataFrame['字段名'].dt)进行查看,下面就是0.25.3版本的输出,如果是1.x版本输出的内容会有所不同

12.3 类别转换器
前提要求字段数据类型为字符串,且数据里面的类别是有限的,比如性别、教育水平等。反应在测试的数据中就是吃饭的类型属于早、中、晚三种类别
unique()函数可以输出字段中数据的唯一值,value_counts()函数就是统计这些唯一值出现的次数

将数据转化为类别数据
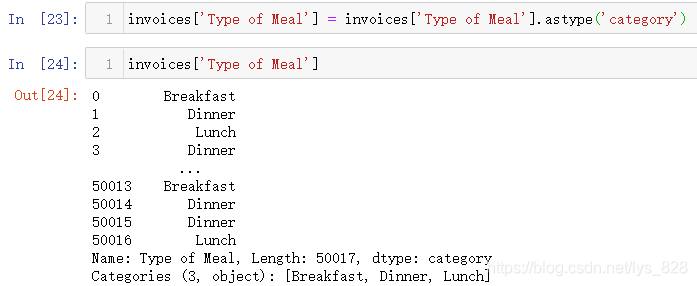
该转化器今后主要用在编码问题上,可用的方法或者属性相较于时间转化器较少,比如查看类别数据是否有序(类别数据分为有序和无序两种,有序的比如小杯、中杯、大杯、超大杯;无序就比如男、女等)

也可以查看类别数据里面总共有哪些类别,这个其实就和前面的unique()函数功能类似
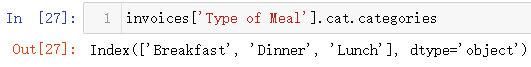
最后介绍一下自动编码的功能,就是利用codes属性,就一一对应各个类别
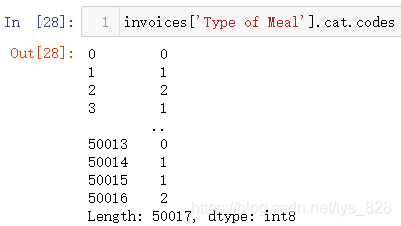
此外还有部分其它的方法,可以通过dir(DataFrame['字段名'].cat)进行查看
12.4 字符串转换器
也是需要字段数据类型为字符串数据类型,然后不要求数据分类是有限的,可以很多,就是很杂乱的那种
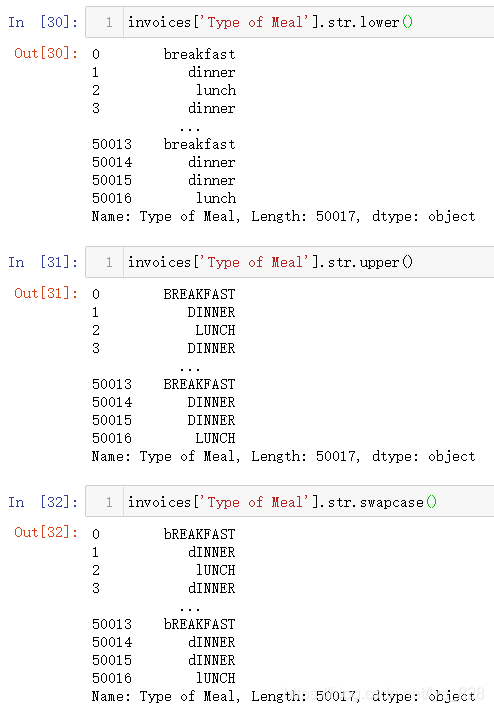
(1)改变大小写及大小写转换
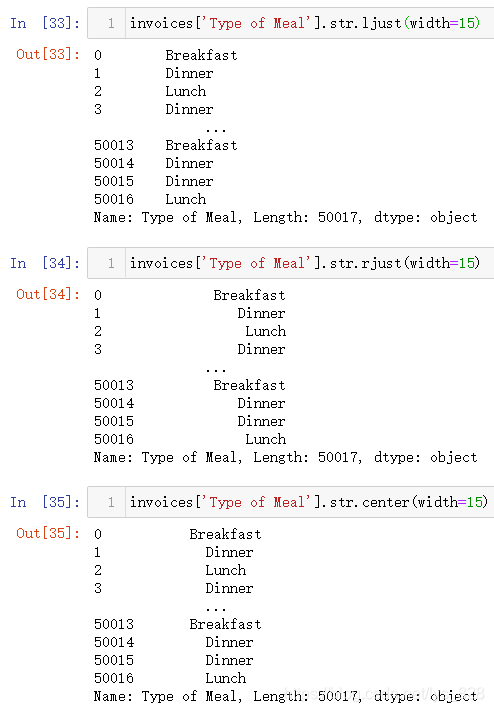
(2)调整左右居中对齐
(3)重复字符

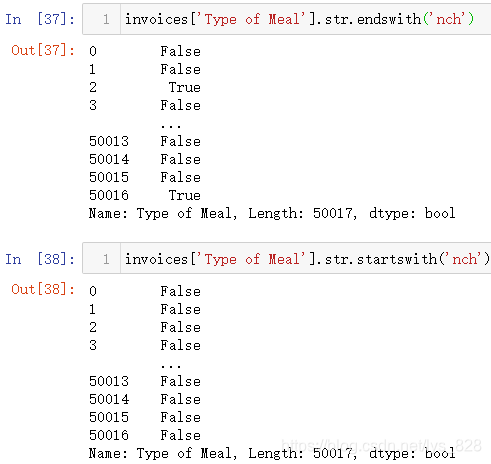
(4)判断字符串开始和结束字符
(5)判断字符串中是否包含某一字符
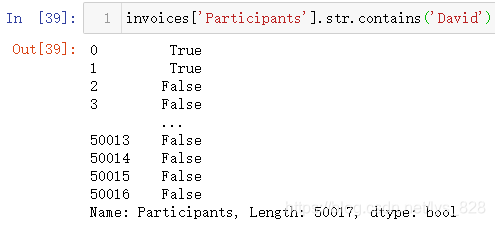
(6)判断字符串长度
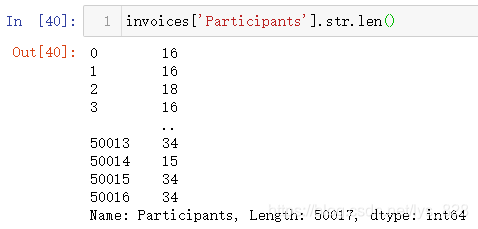
(7)首字母大写
这个还是要单独拿出来讲一下,有时候单词可能因为拼写大小不统一,后续作图时候为了避免出图尴尬,应该尽量把格式化为一致,常见就是首字母大写。操作的步骤是先将所有的字母小写之后再进行首字母大写,这样就不会混乱了(会自动忽略括号)

还有其它的一些字符串的操作,基本上python基础字符串类型的操作,这里都可以用,具体还有哪些方法和属性可以通过dir(DataFrame['字段名'].str)获取,至此关于转换器的功能就介绍完毕了
13 DataFrame合并功能
13.1 concat函数
函数使用参数:pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
第一个参数obj就是预合并的对象,一般是列表数据,包含了多个待合并的数据,剩下的几个常用参数会进行依次介绍
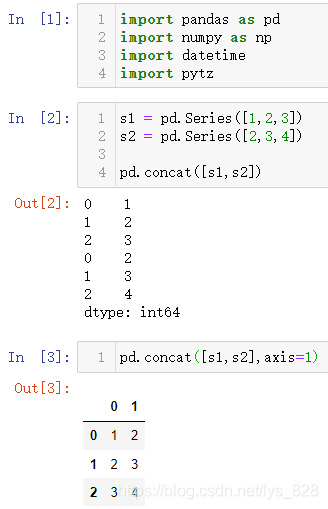
13.1.1 纵横向连接
核心参数axis,默认赋值为0,表示纵向连接,如果赋值为1,表示横向连接,操作示例如下
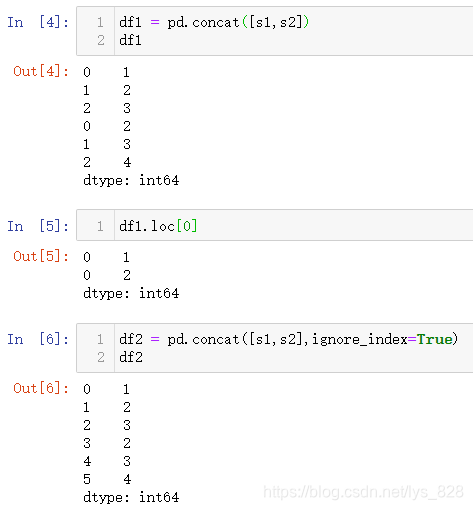
13.1.2 索引重置
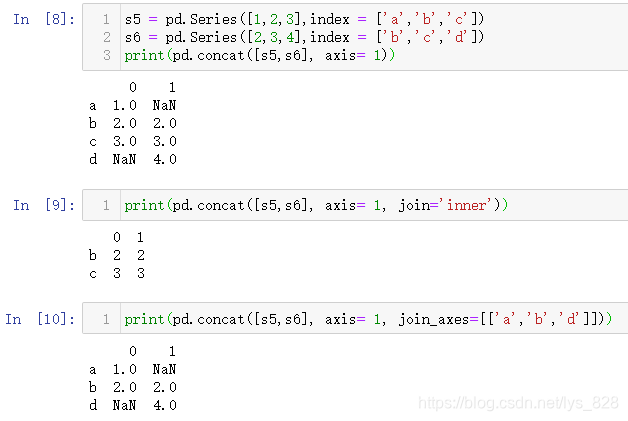
经过纵向连接会有一个问题就是原来的索引也会默认当做合并后的索引,比如进行loc[0],就会出来两个结果,为了保证结果的唯一性,就需要使用到ignore_index这个参数,默认是为False,要完成索引重置需指定ignore_index=True,操作如下
13.1.3 连接方式
核心参数:join和join_axes
join默认赋值参数为outer,就是相当于全连接,只有一方有的数据都会列举出来,另一方没有的会以空值显示,如第8步的输出。如果join='inner',表示两个要合并的数据取交集,有相同索引的数据才会保留下来,参考第9步输出。最后join_axes代表着联合索引,就是你可以自定义指定连接的方式,结果就会按照你指定的索引数据进行合并,见第10步
13.1.4 多层次索引标签
再进行合并数据后,有时需要知道合并后的数据属于原来哪一类数据,相当于要在原来的数据前面加一列或者一行对数据进行分组标号,这样就涉及到了多层次索引标签,借助keys参数完成,该参数默认为None。配合着axis使用会有不同的效果,如果axis=0,就是指定外层索引名称;如果axis=1,就是指定外层字段名称
给出测试数据,创建两个示例的DF
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df2 = pd.DataFrame({
'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7']})
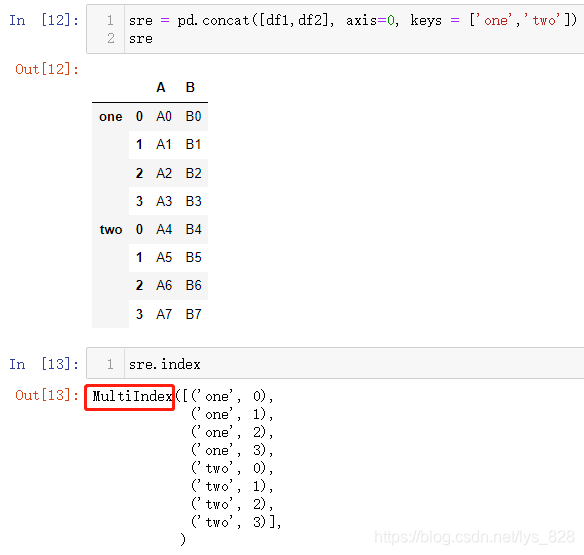
首先配合着axis=0,进行输出,结果如下(最后直接获取合并后的DF的索引,会告诉我们这个索引已经变成了多层索引)
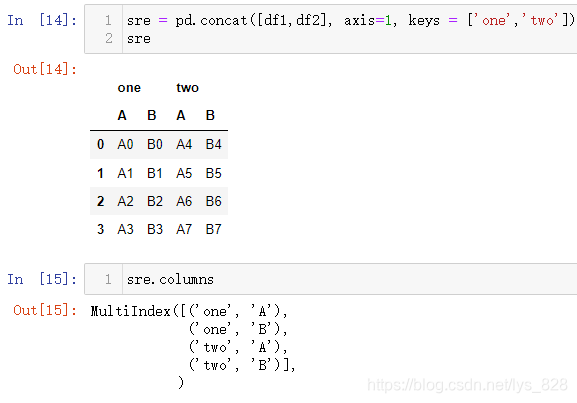
类似设定axis=1,测试结果输出(最终DF的原来的字段也变成多层索引)
补充知识点:多层索引下的行列取值(分步取或者直接索引取值)
比如,取行数据
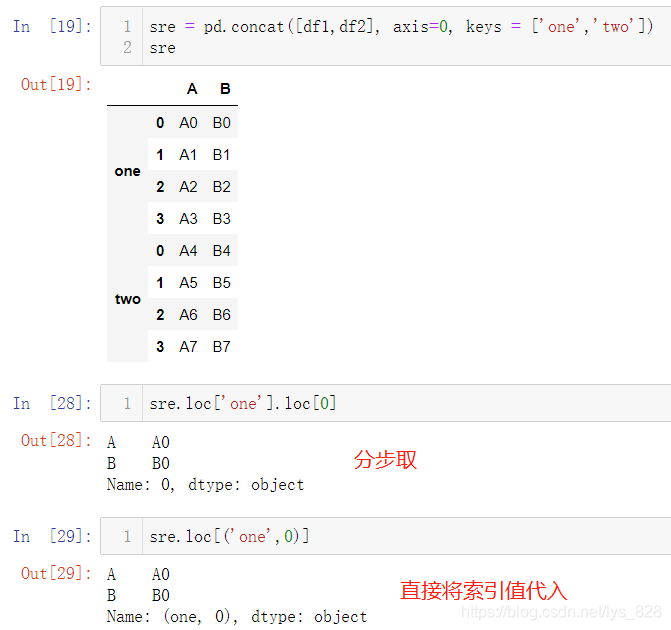
再取列数据(注意分步取和直接按照索引值取两者取到的结果最后数据的名称是不同的,也就是下方的Name会不同)
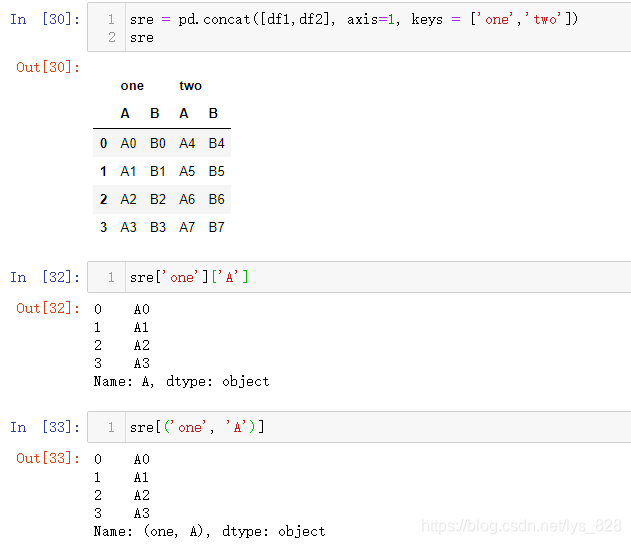
13.1.5 多层索引命名
核心参数names,需要配合着keys使用,如果没有多层索引,单独指定names参数没有效果显示,还有就是names传递的列表元素数量应该和多层索引的层数一致
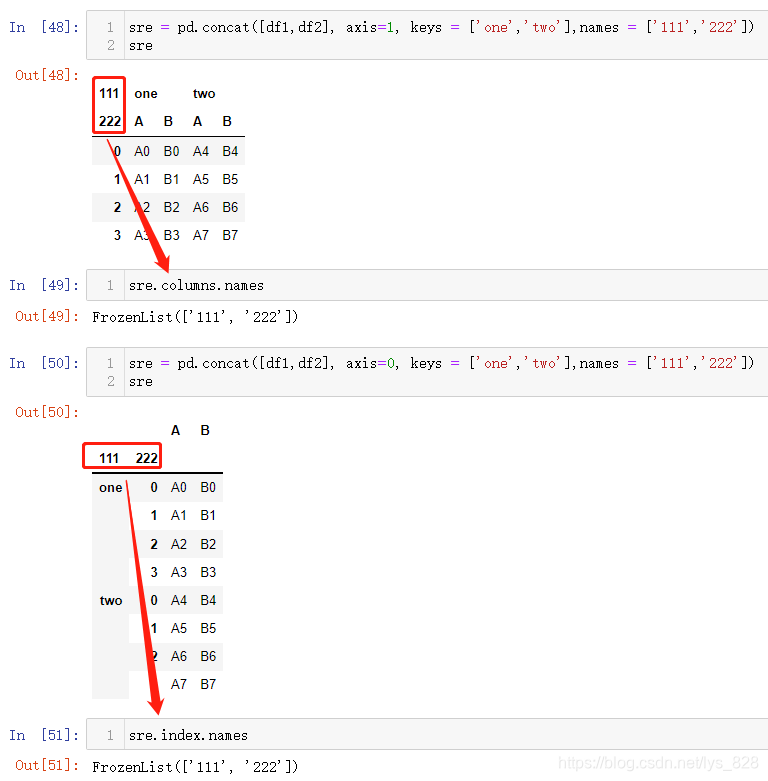
如果单独指定names参数,看看结果(在生成的DF中没有任何效果)
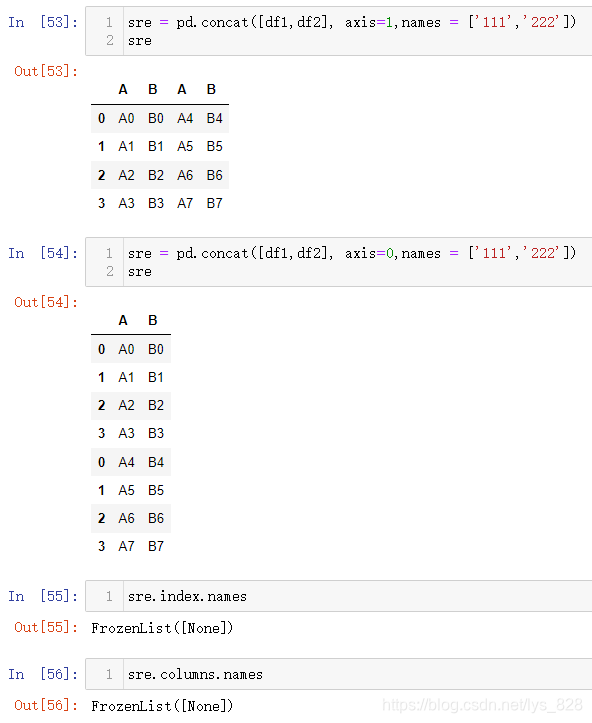
至此关于concat函数的使用常用参数的介绍就完毕了,剩下的几个参数如果有兴趣可以自行摸索一下
13.2 merge函数
函数使用参数:pd.merge( left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False,right_index=False,sort=False, suffixes=('_x', '_y'),copy=True,indicator=False,validate=None)
left参数必须是DF,right可以是DF也可以是Series数据类型,how参数表示默认的链接方式是取交集,这些内容前面都介绍过,接下来就是剩下的几个核心参数。但需要注意的是merge函数合并是只能横向,不能实现纵向
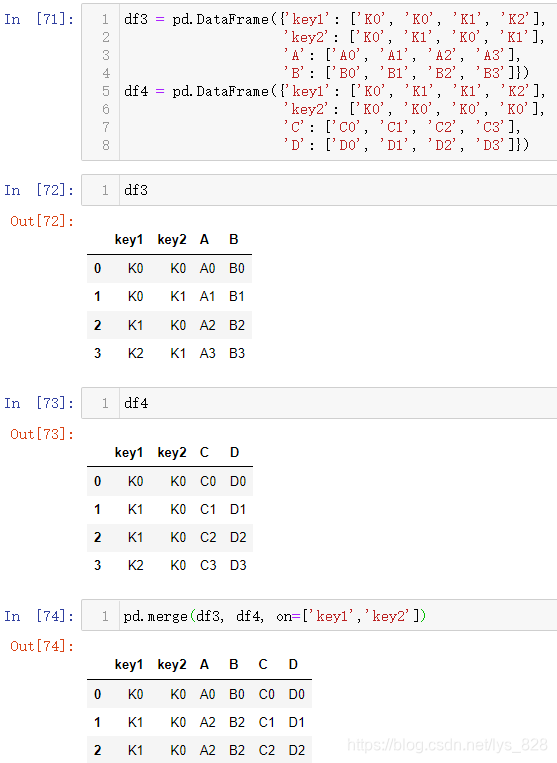
13.2.1 有公共字段
核心参数on=‘某字段’,使用后会按照指定的字段进行合并,操作如下
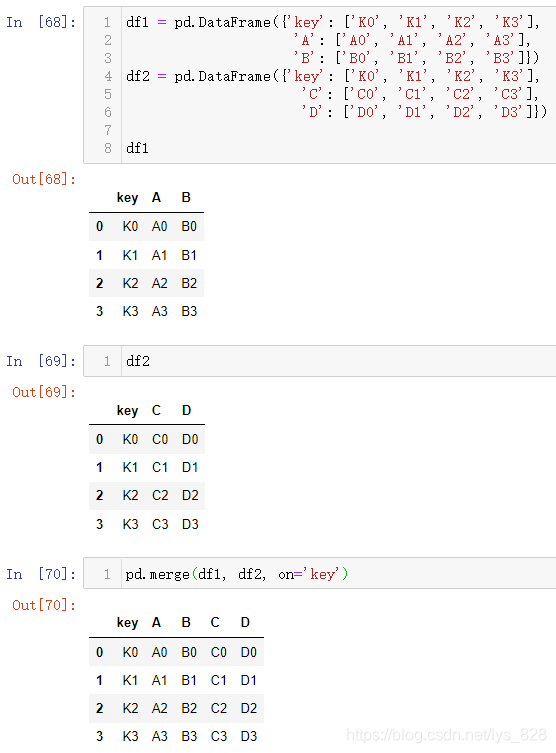
on除了指定一个字段外,还可以通过列表指定多个字段,把合并依据的字段放在列表中即可
13.2.2 无公共字段
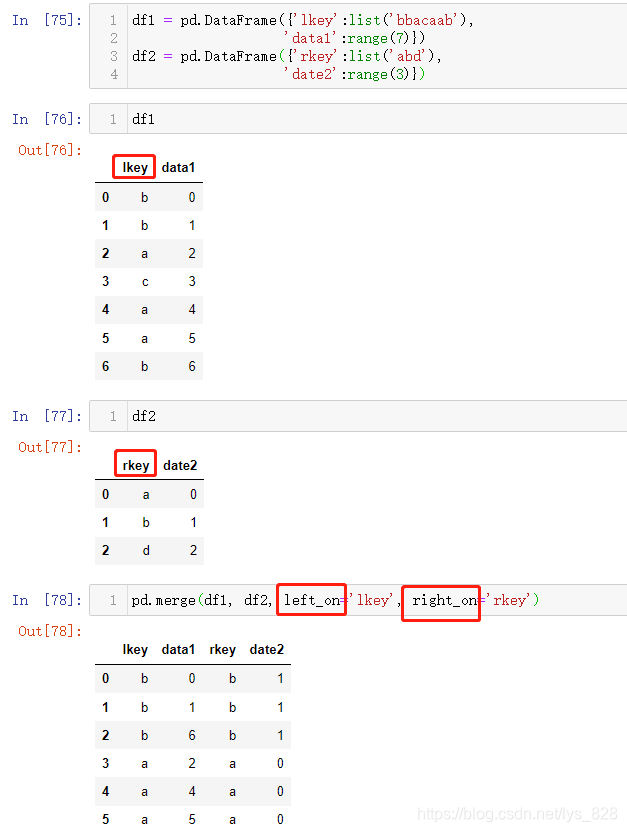
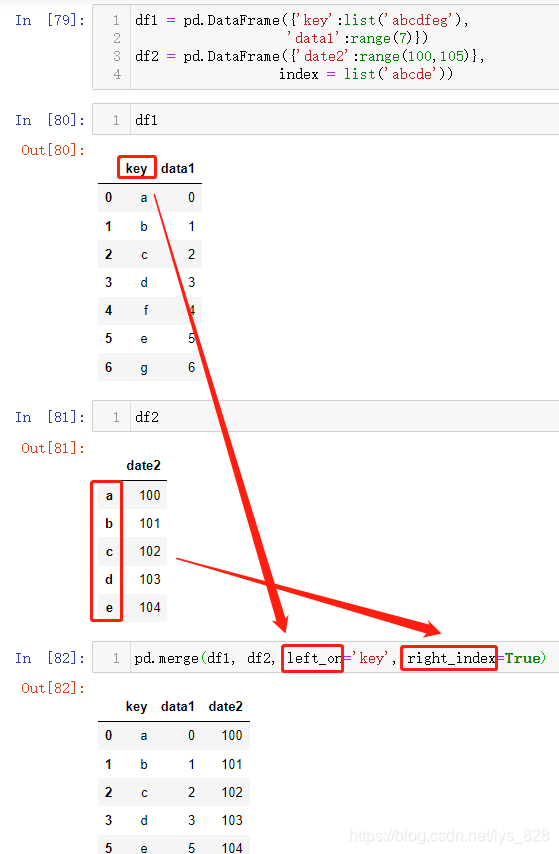
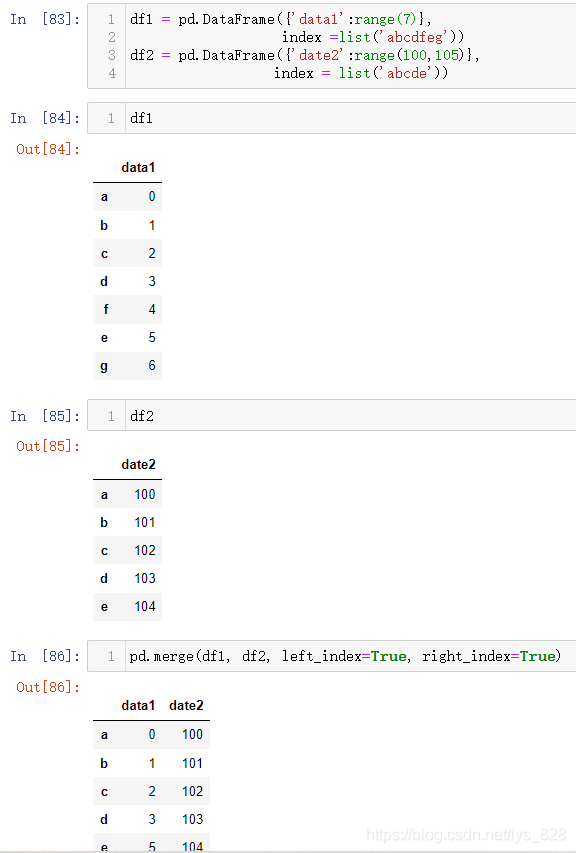
当没有一样的字段时候,on参数就失效了,需要使用到left_on, right_on, left_index, right_index四个参数,顾名思义,以_on结尾的两个是针对字段,_index就是针对索引
(1)都是以字段进行合并
(2)一侧为字段,一侧为索引
可以有两种搭配left_index + right_on或者left_on + right_index,下面只举例一种,另一种使用也是类似
(3)都是以索引进行合并
13.2.3 重复字段
当合并时存在了其他重复字段,系统会默认以_x,_y作为后缀重新命名对应的重复字段,也可以使用suffixes参数自定义,比如使用_base和_join作为后缀进行区分
当不使用suffixes参数,_x后缀的是做为原来基础表中的字段,代表df1,_y后缀的作为欲合并表中的字段,代表df2。顺便加了一个sort参数,表示将最后的结果进行排序
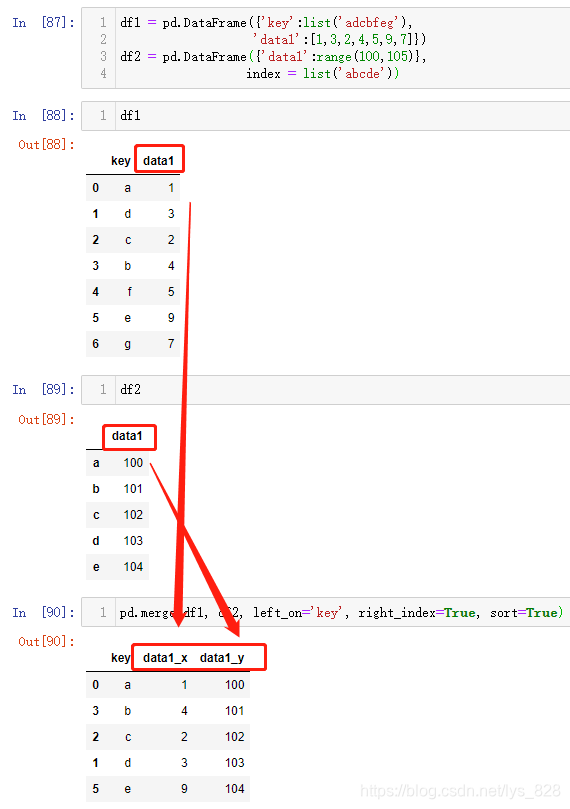
也可以自定义后缀名,操作如下

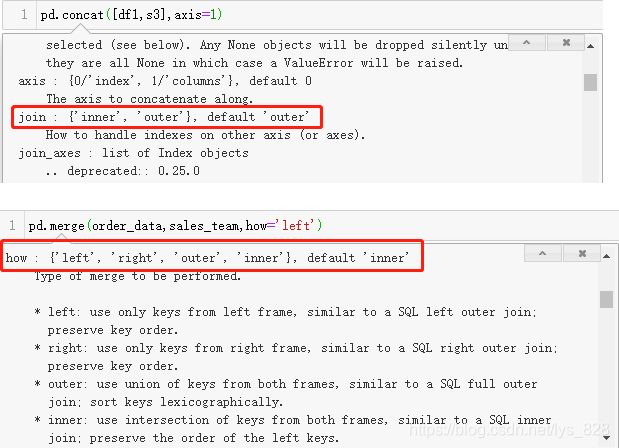
12.2.4 连接方式
merge函数里面的how参数和前面的concat函数的join参数连接方式有所区别,调出两者的使用手册进行对比。其中join参数只支持取交集和取并集,也就是inner和outer,how参数还增添了两种方式,就是以左边的DF为准还是以右边的DF为准
至于inner和outer两个参数就不再进行举例,看一下left和right的使用效果,测试数据如下
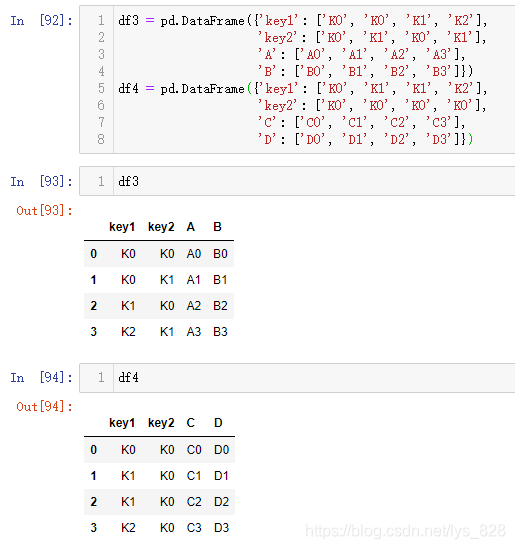
对比一下以左为标准和以右为标准输出结果的差别。当指定how='left'时,左侧的df3的数据会全部保留,df4会依照指定的字段或者索引进行合并,没有匹配的地方会用空值进行填充,同理也适用与how='right'的情况,此时右侧df4会保留全部数据
至此常用的一些参数使用就梳理完毕,剩下的三个参数保持默认即可,日常使用中基本上不用进行设置,有兴趣的话可以调出使用手册了解一下
13.3 使用map方法进行合并
又一次见到字段的map()方法了,这里要实现的就是数据的合并。其实原理也和之前的一样,就是按照一列的数据进行映射,同等的数据添加到新的一列
测试数据如下
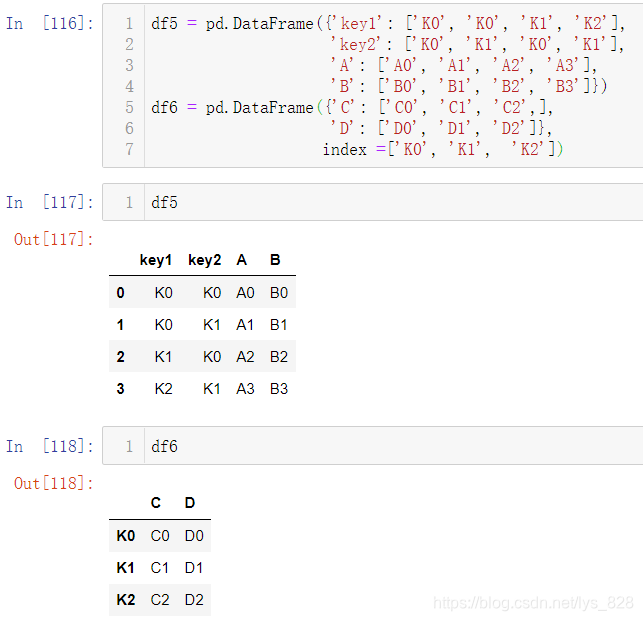
比如将按照df5中的key1字段将df6中的C列和D列单独合并。这里的原理就和之前使用map方法传递字典本质上是一致的,只不过字典是无序的,这里通过获取DF中的一列属于Series数据类型是有序的

13.4 数据修补
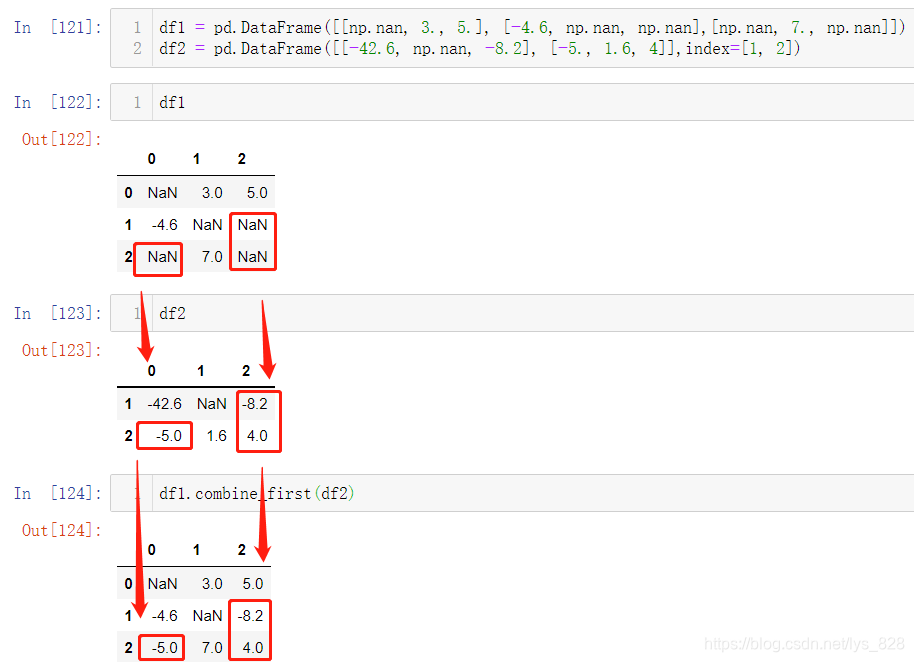
主要介绍两个函数:df1.combine_first(df2) 和df1.update(df2)
13.4.1 只填补缺失值
df1.combine_first(df2) 就是指针对df1数据中的空值部分,使用df2数据进行填补,非缺失值部分不做改变。注意不是按照形状位置进行填充,而是严格的索引和字段两者结合。输出结果如下,如果df1中有缺失值的地方(下面红框的地方),df2中有数据(红框标出),填补之后原空白的地方就会被填充(红框标出),其它非空白的地方不变
13.4.2 全部更新
使用上面的df1和df2数据,用到df1.update(df2)函数,具体实现就是把df1同索引同字段的数据用df2中数据替换。比如原来df1中(1,0)位置的数据为-4.6,直接被更新为-42.6,(2,1)位置的数据原来是7.0,被更新为1.6,同时最后一列的两个缺失值也被更新为df2中的数据
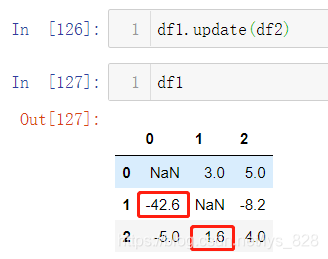
注意这两种方法除了上面介绍的区别外,还有一个就是df1.combine_first(df2)操作后不会改变df1的值,需要重新赋值为df1,才会修改df1,而df1.update(df2)执行后df1中的数据已经发生改变了,可以对比python基础数据类型中的列表和字符串方法使用的区别进行理解,列表直接使用方法后对应的变量数据就发生变化,字符串还需要重新赋值
14 数据重塑
测试数据为餐饮销售数据
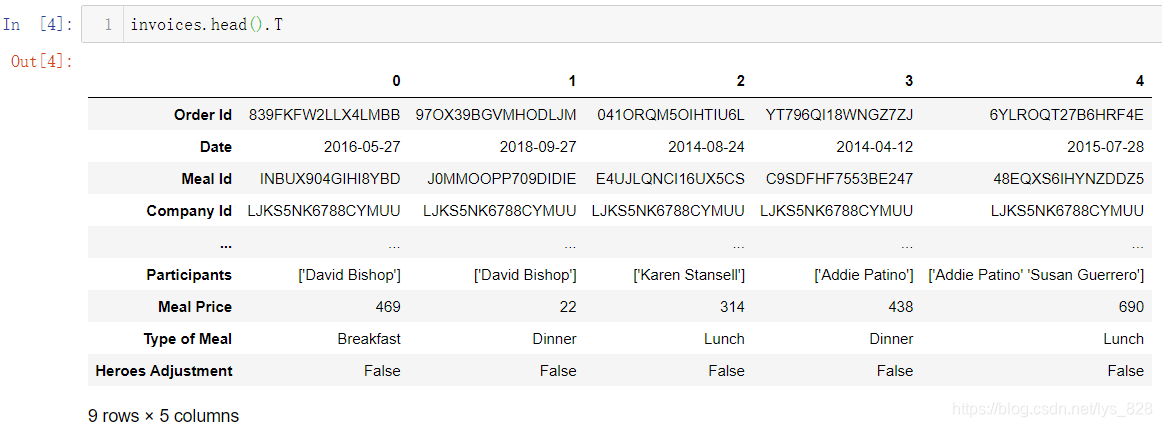
14.1 DF转置
就是将原本DF的行和列进行对换,相当于原有的结构转换了90度。比如将读入的数据前5行进行转置,输出如下(前面在介绍时间索引的时候已经使用过转置的方法,这里就当做复习)
14.2 宽数据变长数据
核心代码:melt()函数
先给出一个简单的测试数据帮助理解
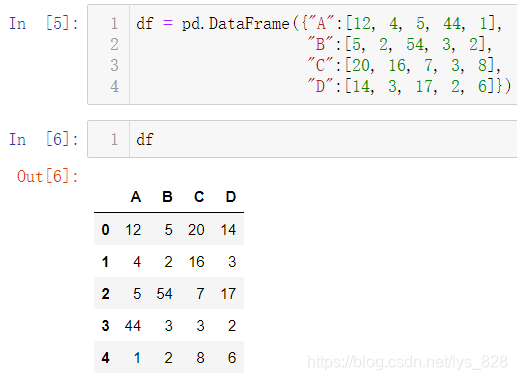
使用melt()函数进行数据转化,比如保留A字段,其他的字段作为数据。输出结果中原来的B,C,D字段都会变成variable字段下的内容,然后对应值也就一一对应在了value字段下,从而实现宽数据到长数据的转化

列表中还可以填多条数据,比如保留A,B,C字段,仅以D字段做转化

除了指定保留字段外,还可以指定保留的转化字段,比如只保留A字段,对D字段进行转化
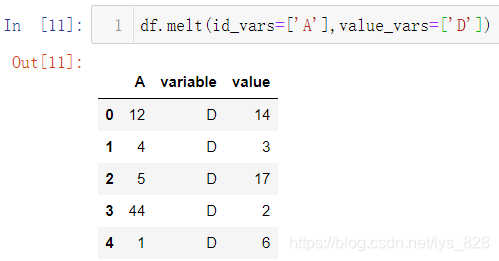
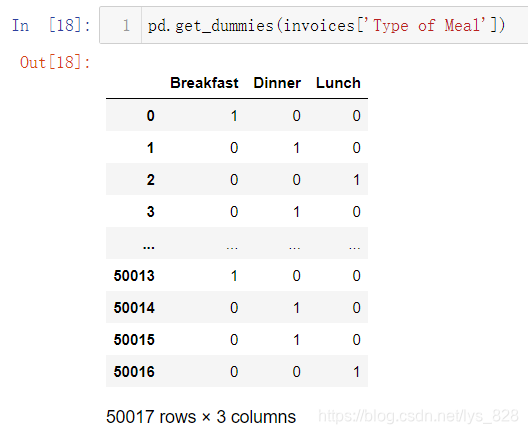
将此方法应用在餐饮销售上,比如想把发票信息对应早中晚餐和价格信息,首先需要将早中晚餐这三个类型分别作为三个字段,然后价格与三个字段结合。将一个字段的多个类别数据转化为多个字段需要使用到get_dummies()方法
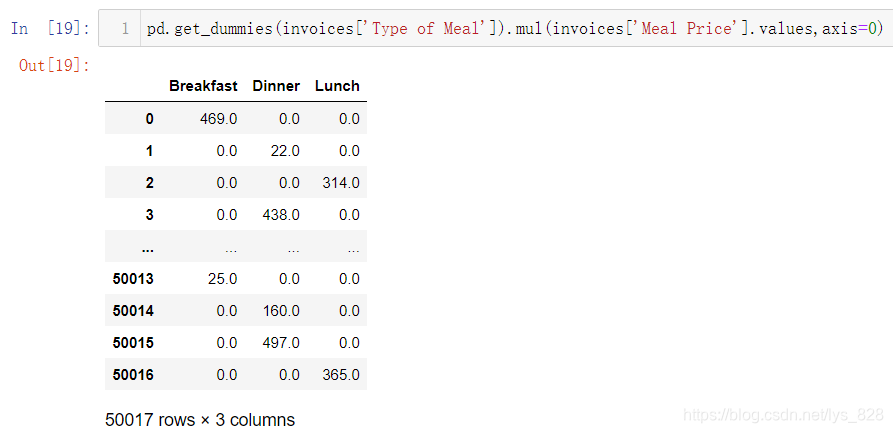
接着借助矩阵乘法,将价钱字段与这三个字段结合
以上就构成目标形式了,下一步就是利用melt方法进行操刀,只保留发票和时间信息字段,早中晚餐及价格信息作为variable和value字段,操作步骤如下
(1)将原数据与矩阵计算的结果进行合并
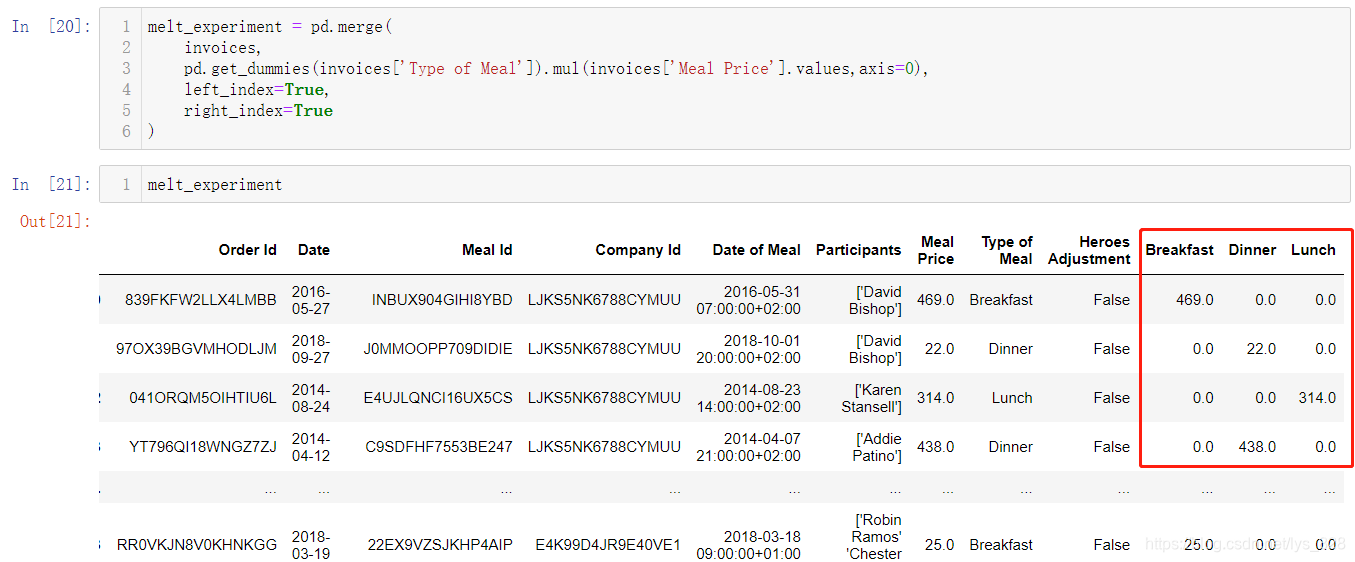
(2)指定保留的字段和转化的字段
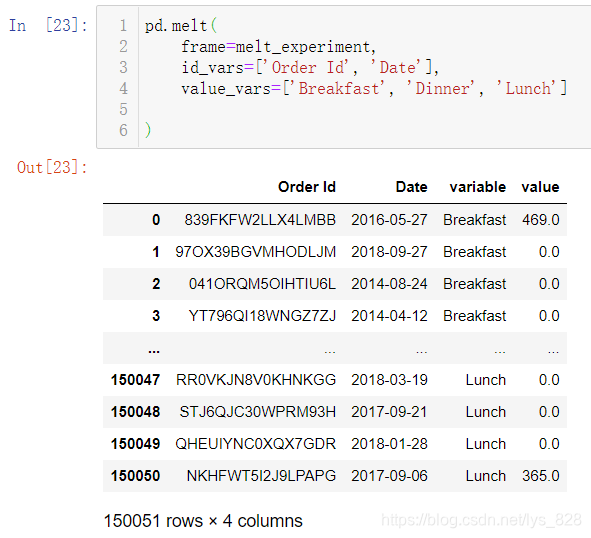
14.3 长数据变宽数据
核心代码pd.poivot()和pd.pivot_table()
先进行一个简单的示例,测试数据如下
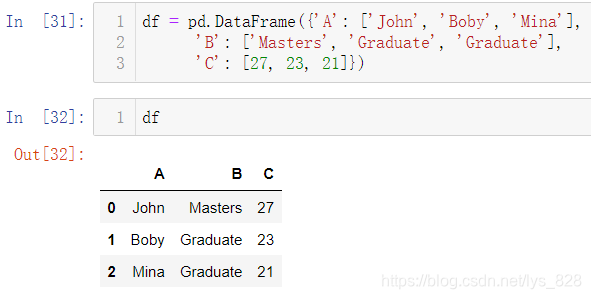
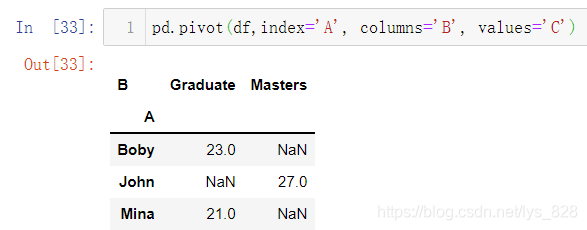
然后调用pivot()函数,指定相关参数对应的值,比如将A作为索引,B最为字段名称,C作为值
要想更进一步,比如设定value的计算方式,还有缺失值处理方式,可以使用pd.pivot_table(),直接应用在餐饮销售数据上,比如按照公司作为索引,早中晚餐作为字段,价钱作为值,计算的方式按照平均值结算
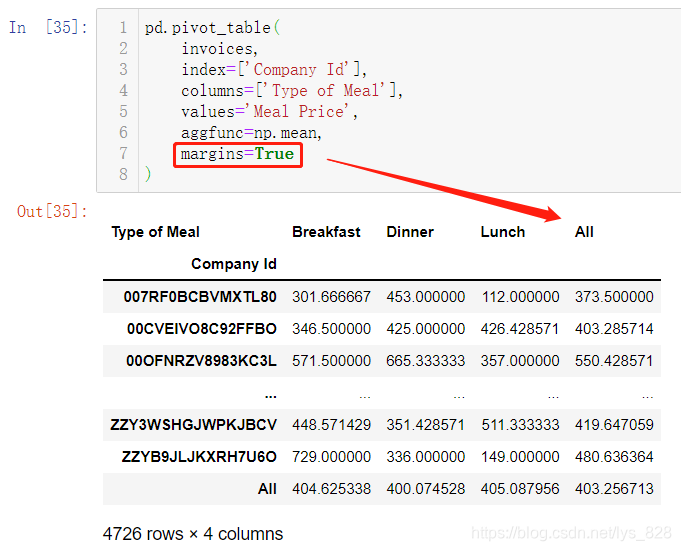
aggfunc参数就是指定计算的方式,因为每个公司吃饭不止一次,这样汇总数据就按照吃饭的均值进行统计,然后里面的margins参数就是最下和最右的ALL对应的数据,分别对行和列数据进行统计,也是按照均值进行。至此就可以知道每个公司的早中晚餐的平均价格,已经一天吃饭的平均价格,还有就是所有公司早中晚餐的平均价格和一天的伙食消费水平
14.4 数据分组汇总
核心代码:groupby().agg({'字段名':[方法]})
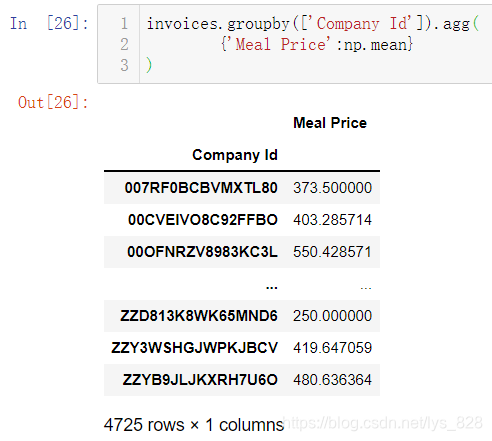
直接应用在餐饮销售数据上,比如按照公司进行汇总统计,输出每个工司早中晚餐的价格平均值
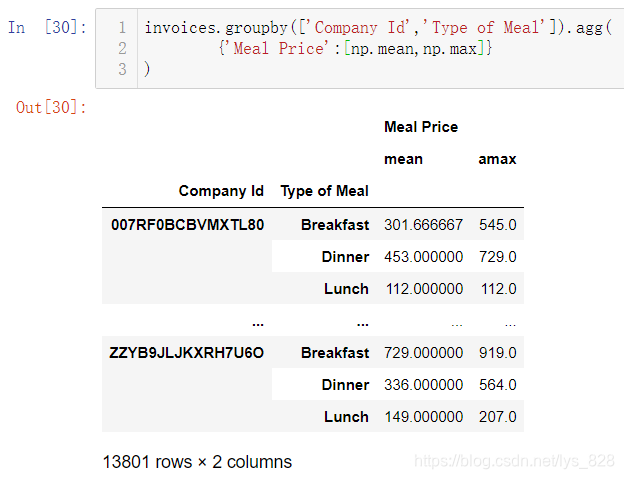
如果是按照多字段进行会汇总,列表里面可以填入多个数据,且汇总后会以列表中默认的顺序作为层次索引,比如按照公司和餐饮时间类别分组,并计算均值和最大值。
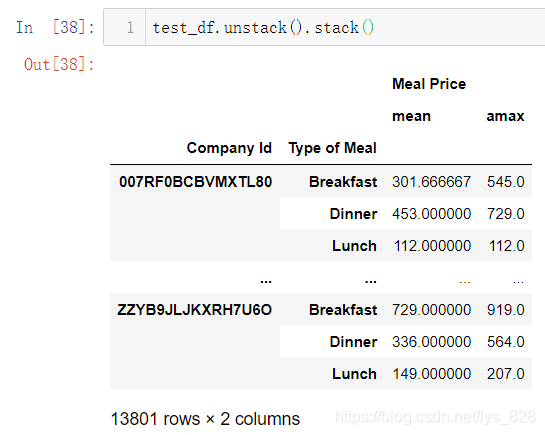
14.5 多层索引拆分与重塑
核心代码:unstack()/stack()
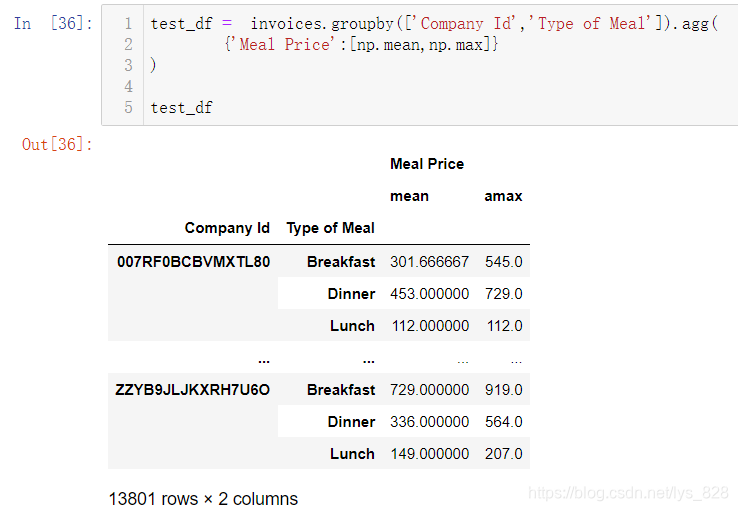
前面进行groupby()分组操作时候,如果列表指定多个字段作为依据,就会产生多层索引。就用上面的输出结果重新赋值作为测试数据如下
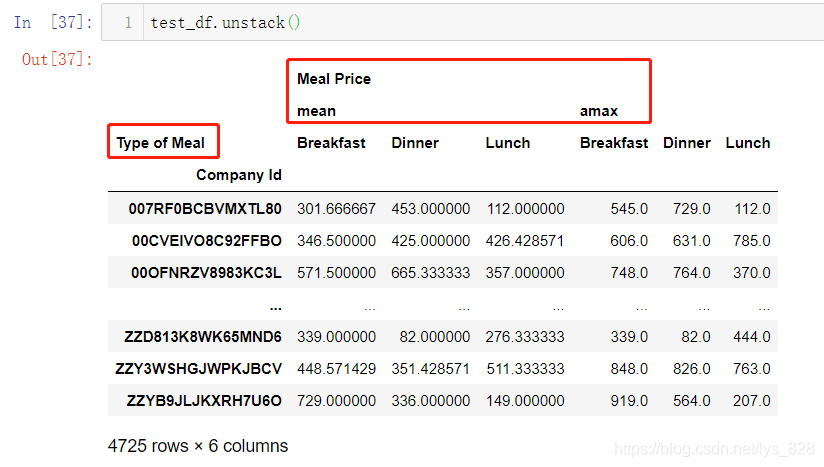
使用方式也超级简单,直接test_df.unstack(),输出结果就会把多层索引变少,比如这里数据是双层索引,unstack()之后就变成了单层索引
如果还要重新变回双层索引就很简单,直接stack()就可以
15 Pandas的SQL功能
除了之前介绍的Csv、Excel类数据外,数据库也是可以利用Pandas直接操作的数据来源。
Pandas.read_sql 可以在数据库中执行指定的SQL语句查询或对指定的整张表进行查询,以DataFrame 的类型返回查询结果,这是在跟数据库进行交互操作时很重要的一步,既读取数据,还返回DataFrame方便处理。
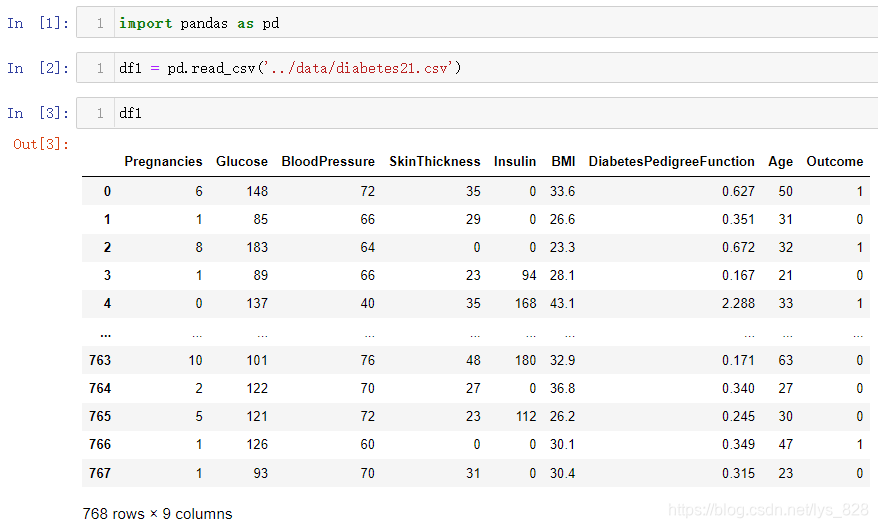
由于可能有些人没有接触过数据库,这里就从无到有进行介绍,先读取本地的数据,一份类似体检报告的成绩,读取如下
15.1 写数据
数据有了,接着就是用代码创建一个数据库文件,把df1中的数据存放进去。最开始先介绍一个极其小型的数据库,就是sqlite,在python中也是内置的数据库模块,直接导入,通过下面的代码可以直接创建一个数据库文件。核心代码:sqlite3.connect()

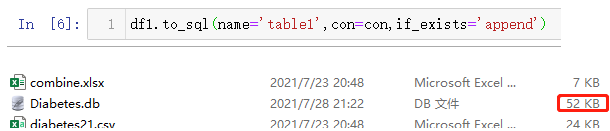
输出结果如下:(执行步骤5后,这时候在指定路径下会生成这个数据库文件,最后面的大小提醒文件只用0kb,还没有存入任何数据)

接着就把df1中的数据存入到数据库文件中。核心代码:df1.to_sql(name='table1',con=con,if_exists='append')其中name是指定数据库中表的名称,con参数就是连接上刚刚创建的那个数据库文件,if_exists='append'表示如果表名称重名了,就以追加的方式把数据写入到数据库文件中
15.2 读数据
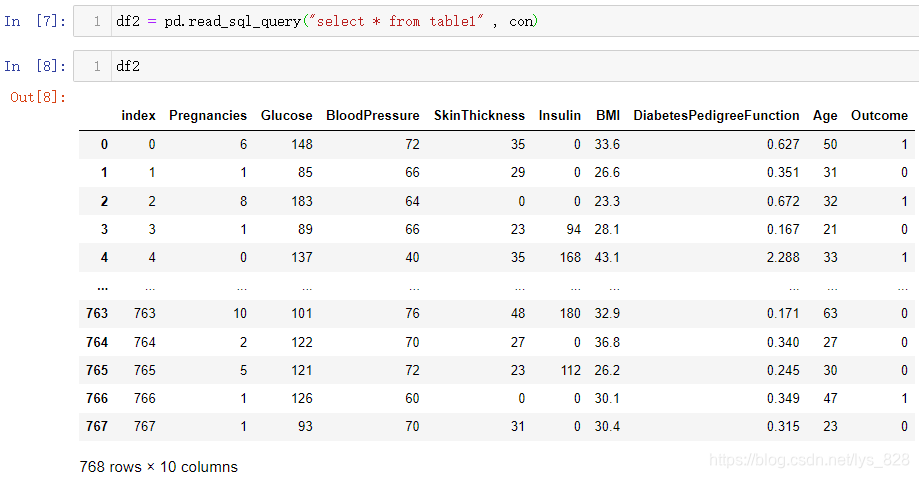
查看数据库文件信息可以通过下载sqlite软件,也可以使用代码进行查询,先说进行代码查询,核心代码:df2 = pd.read_sql_query("select * from table1" , con)
如果使用软件进行查看,可以用的软件很多,这里用的是SQLiteStudio,打开这个文件后,双击table1表,然后再点击右上方“数据”菜单栏就可以查看到具体数据了
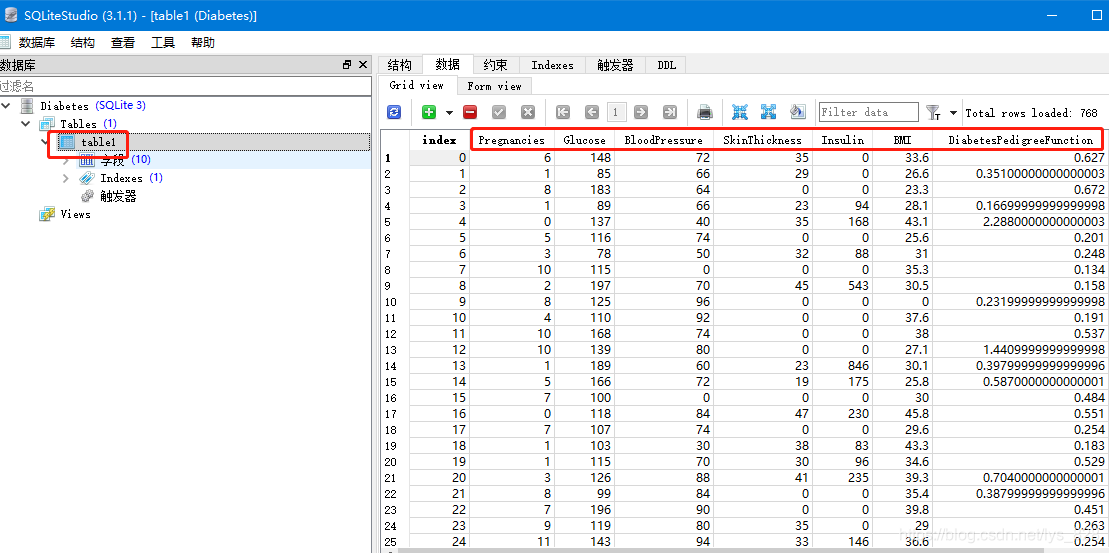
15.3 添加多个表数据
最后再随便找一个之前的文件存放到数据库中看一下,比如天气数据。注意这里没有新建数据库文件,而是直接选择的刚刚的con
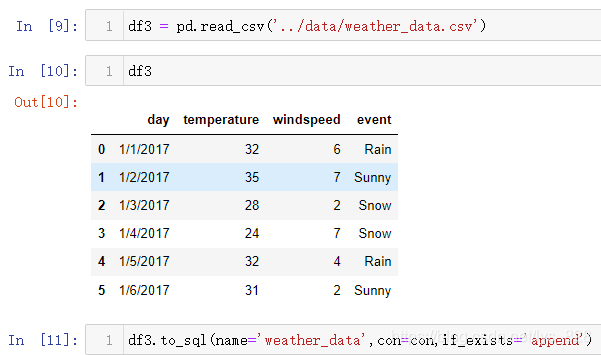
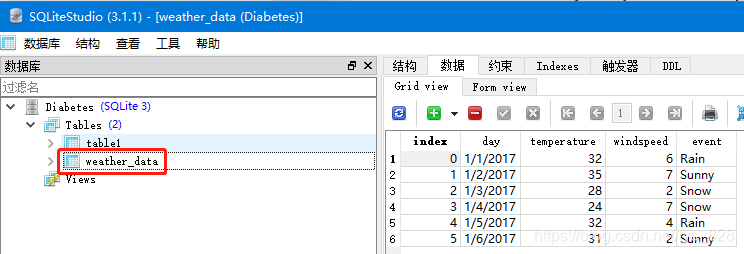
通过软件看一下是否真的添加进去了另外一个表数据(核实无误,数据库就相当于多个csv文件的仓库,可以集合多份文件在一块,而且打开浏览时候也超级方便)
至此使用Pandas功能介绍及应用的全部内容就梳理完毕了,完结撒花✿✿ヽ(°▽°)ノ✿