第1关:
-
1、以下两幅图说明了什么?
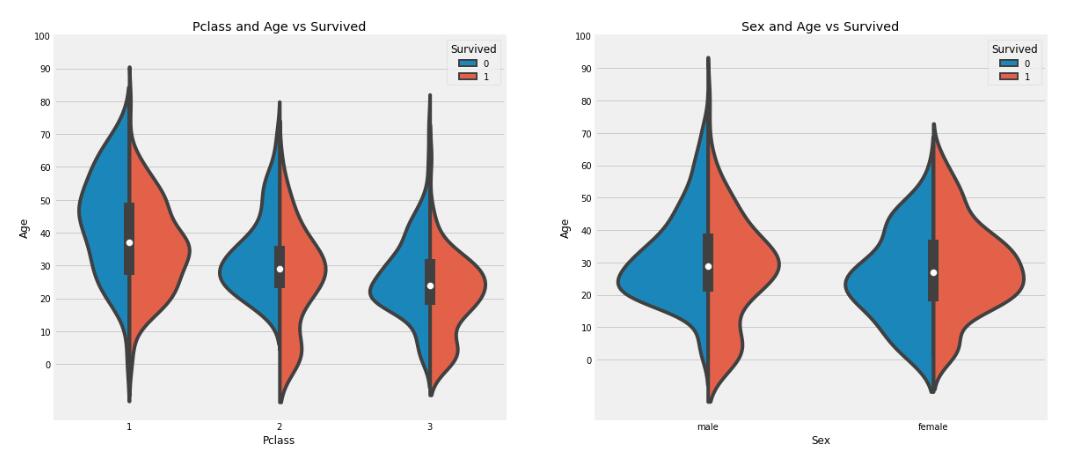 A、
A、10岁以下的小朋友的存活率比较高,跟船舱等级没有太大关系
B、一等舱的20-50岁的人群的存活率较高
C、对于男性来说,越老,存活率越低
D、女性的生还率较高
答案:BCD
-
2、
这副图说明了什么?
A、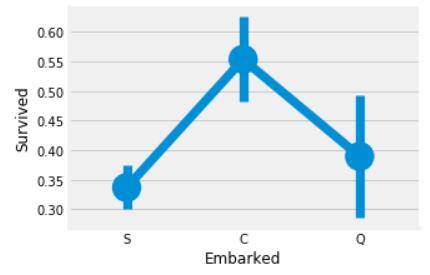
在C号口岸上船的船客的生还率高于55%
B、在S号口岸上船的船客的存活率最低
C、上船人数最多的是C号口岸
D、上船人数最少的是S号口岸
答案:AB
-
3、
以下四幅图说明了什么?
A、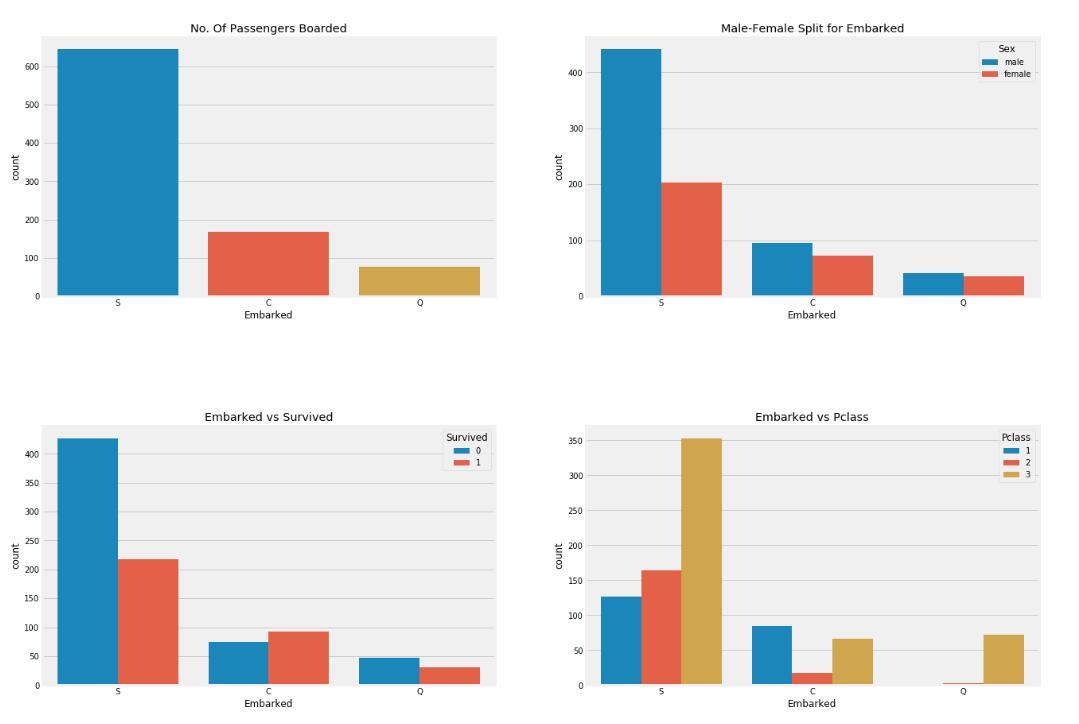
虽然有很多一等舱的土豪们基本都是在S号口岸上船的,但是S号口岸的生还率最低,可能是因为S口岸上船的人中有很多都是三等舱的船客
B、在S号口岸上船的人大多数是二等舱的船客
C、Q号口岸上船的人中有90%多都是三等舱的船客
D、在C号口岸上船的生还率最高
答案:ACD
-
4、
以下两幅图说明了什么
A、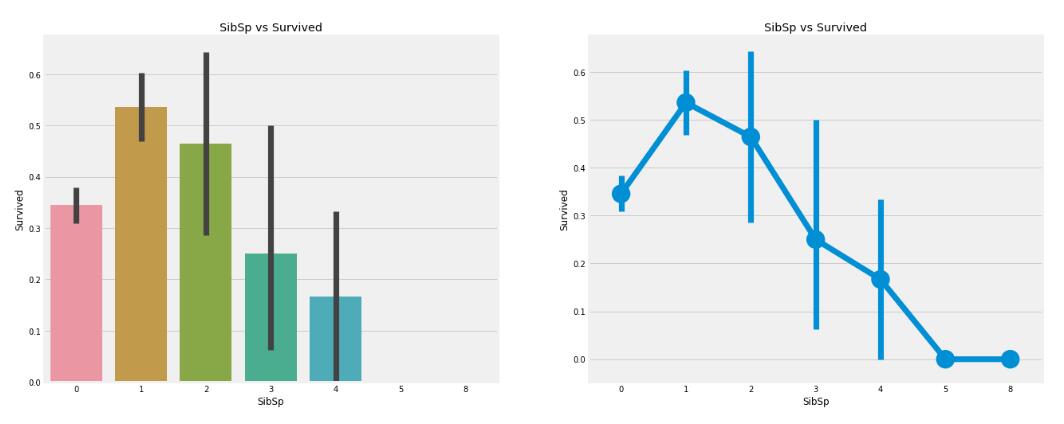
一个人在船上旅游的人的存活率约为34%
B、有一个兄弟姐妹或者爱人也在船上的话,生还率最高
C、兄弟姐妹或者爱人的数量比较多的时候,生还率呈下降趋势
答案:ABC
第2关:填充缺失值
import pandas as pd
import numpy as np
def process_nan_value(data):
'''
处理data中缺失值,有缺失值的特征为`Age`,`Cabin`,`Embarked`。
:param data: 训练集的特征,类型为DataFrame
:return:处理好缺失值后的训练集特征,类型为DataFrame
'''
#********* Begin *********#
data['Age'].replace(np.nan,np.nanmedian(data['Age']),
inplace=True)
#data['Age'].replace(np.nan,np.nanmedian(data['Age']),inplace=True)
data.drop(labels='Cabin',axis=1,inplace=True)
data['Embarked'].replace(np.nan,'S',inplace=True)
return data
#********* End *********#
第3关:特征工程与生还预测
import pandas as pd
import numpy as np
import sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
#********* Begin *********#
titanic = pd.read_csv('./train.csv')
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df
titanic = set_missing_ages(titanic)
dummies_Embarked = pd.get_dummies(titanic['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic['Pclass'], prefix= 'Pclass')
df = pd.concat([titanic, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
# print(df)
train_label = df['Survived']
train_titanic = df.drop('Survived', 1)
titanic_test = pd.read_csv('./test.csv')
titanic_test = set_missing_ages(titanic_test)
dummies_Embarked = pd.get_dummies(titanic_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(titanic_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(titanic_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([titanic_test,dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
#model = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
model = RandomForestClassifier(n_estimators=10)
model.fit(train_titanic, train_label)
predictions = model.predict(df_test)
result = pd.DataFrame({'Survived':predictions.astype(np.int32)})
result.to_csv("./predict.csv", index=False)
#********* End *********#