模型维度变化: 输入onehot-到-embedding 768维 ===》输入成转512维 经过self attention 再输出768维 ===》输入 768维 经过 FFN 输出768维
参考:https://github.com/google-research/bert/blob/master/modeling.py#L863
参考:https://zhuanlan.zhihu.com/p/422533717
https://blog.csdn.net/sunyueqinghit/article/details/105157609
transformer 最后一层输出的结果
last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态
pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化通常更好。
hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)
attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值
这里用transformers包进行演示
transformers安装需要安装好tf和torch,tf这里选择2X
tensorflow 2.2.0
torch 1.9.0
transformers 4.10.2
***需要输出hidden_states和attentions,需要指定output_hidden_states=True, output_attentions=True
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("peterchou/simbert-chinese-base")
model = AutoModel.from_pretrained("peterchou/simbert-chinese-base",output_hidden_states=True, output_attentions=True)
outputs = model(**tokenizer("语言模型", return_tensors='pt'))
每一层的cls向量,共12层网络[1:]
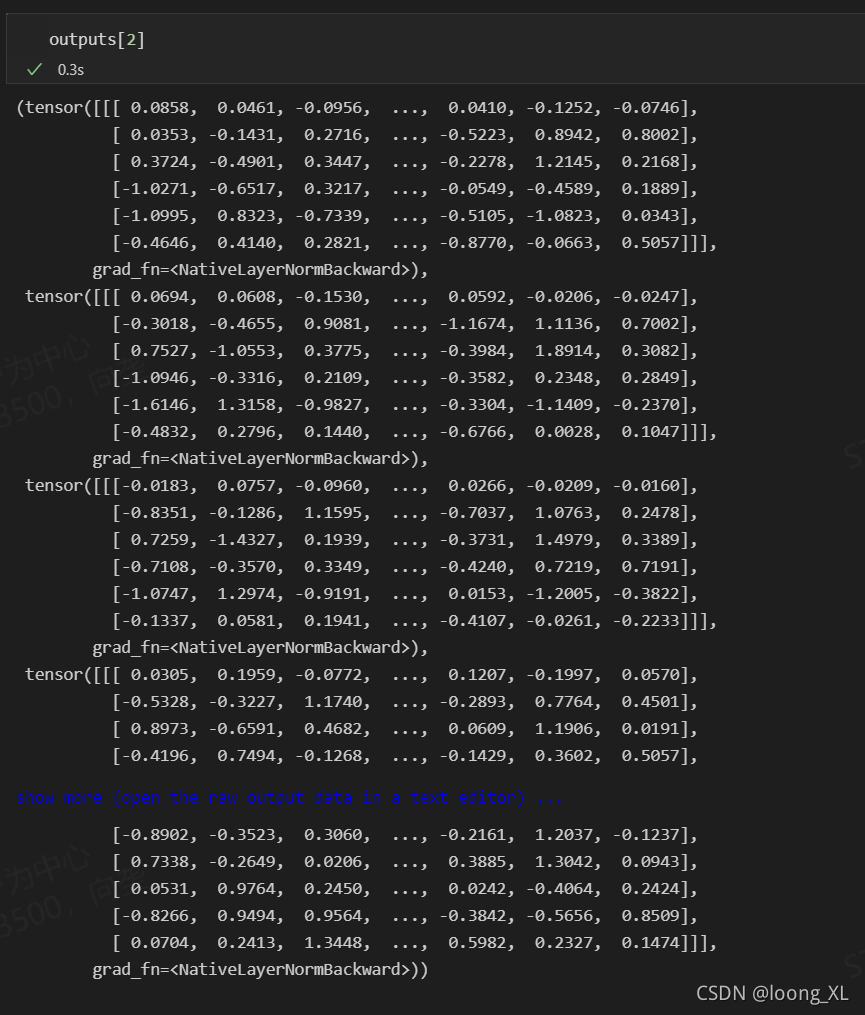
bert4keras 获取最后一层
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = '/Us***l/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/Us**/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/Us**/chinese_L-12_H-768_A-12/vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
# 编码测试
token_ids, segment_ids = tokenizer.encode('语言模型')
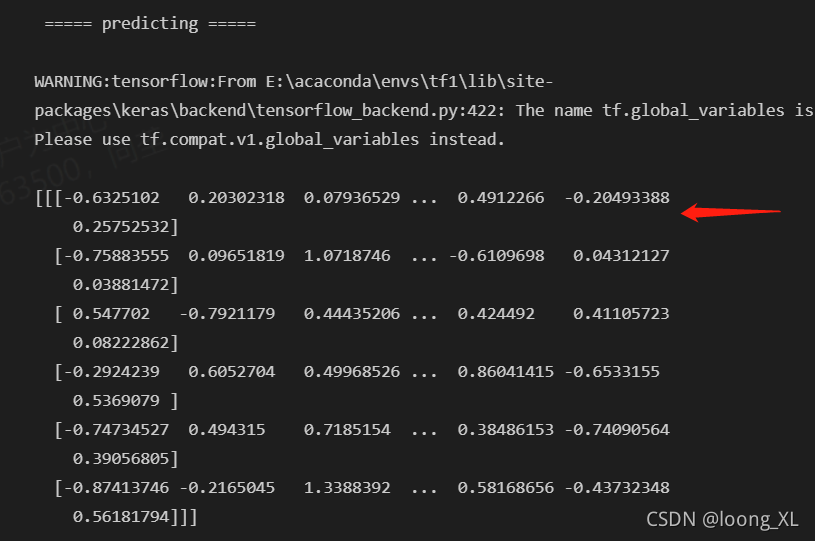
print('\n ===== predicting =====\n')
print(model.predict([np.array([token_ids]), np.array([segment_ids])]))
第一个是cls句向量
也可以这样获取cls:
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = '/Us***l/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/Us**/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/Us**/chinese_L-12_H-768_A-12/vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
from bert4keras.backend import keras
from keras.layers import Lambda, Dense
from keras import Model
cls_output = Lambda(lambda x: x[:, 0], name='CLS-token')(model.output) ##获取最后cls向量
# all_token_output = Lambda(lambda x: x[:, 1:-1], name='ALL-token')(model.output) ##获取最后除cls和最后终止符的其他向量
model1 = Model(
inputs=model.input,
outputs=cls_output
)
output1 = model1.output
token_ids, segment_ids = tokenizer.encode('语言模型')
res = model1.predict([np.array([token_ids]), np.array([segment_ids])])
res
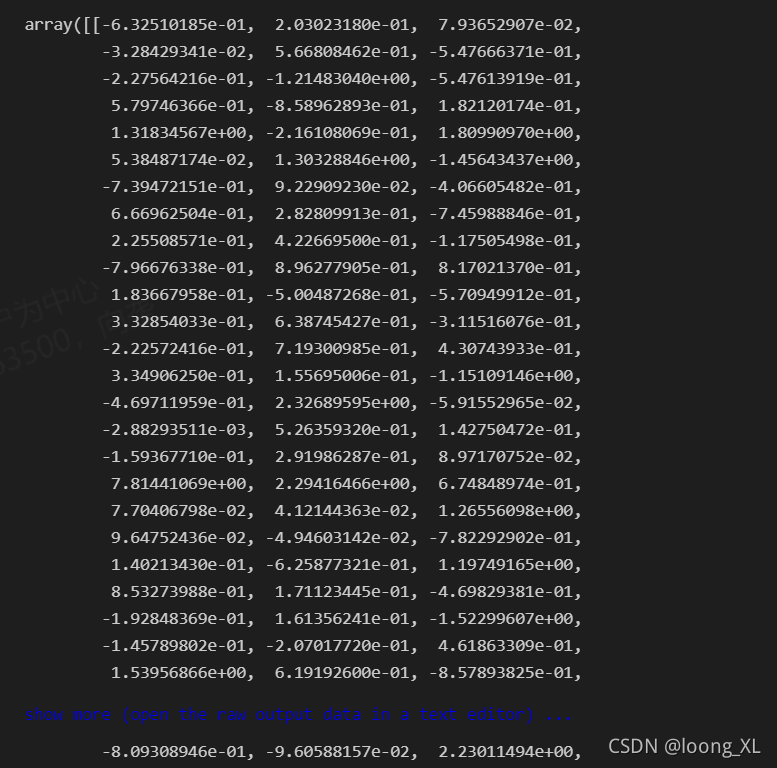
这是最后层cls后的每个token结果
from bert4keras.backend import keras
from keras.layers import Lambda, Dense
from keras import Model
# keras.layers.Lambda(lambda x:x[:,0])(model.output)
#cls_output = Lambda(lambda x: x[:, 0], name='CLS-token')(model.output) ##获取最后cls向量
all_token_output = Lambda(lambda x: x[:, 1:-1], name='ALL-token')(model.output) ##获取最后除cls和最后终止符的其他向量
model1 = Model(
inputs=model.input,
outputs=all_token_output
)
output1 = model1.output
token_ids, segment_ids = tokenizer.encode('语言模型')
res = model1.predict([np.array([token_ids]), np.array([segment_ids])])
res
bert4keras 获取每一层案例
参考:
https://github.com/bojone/bert4keras/issues/68
https://blog.csdn.net/weixin_43557139/article/details/116573558
https://www.jb51.net/article/189638.htm
**bert4keras包需要自己通过Keras Model接口取每一层,把全部100来层取出来,需要自己选择挑选
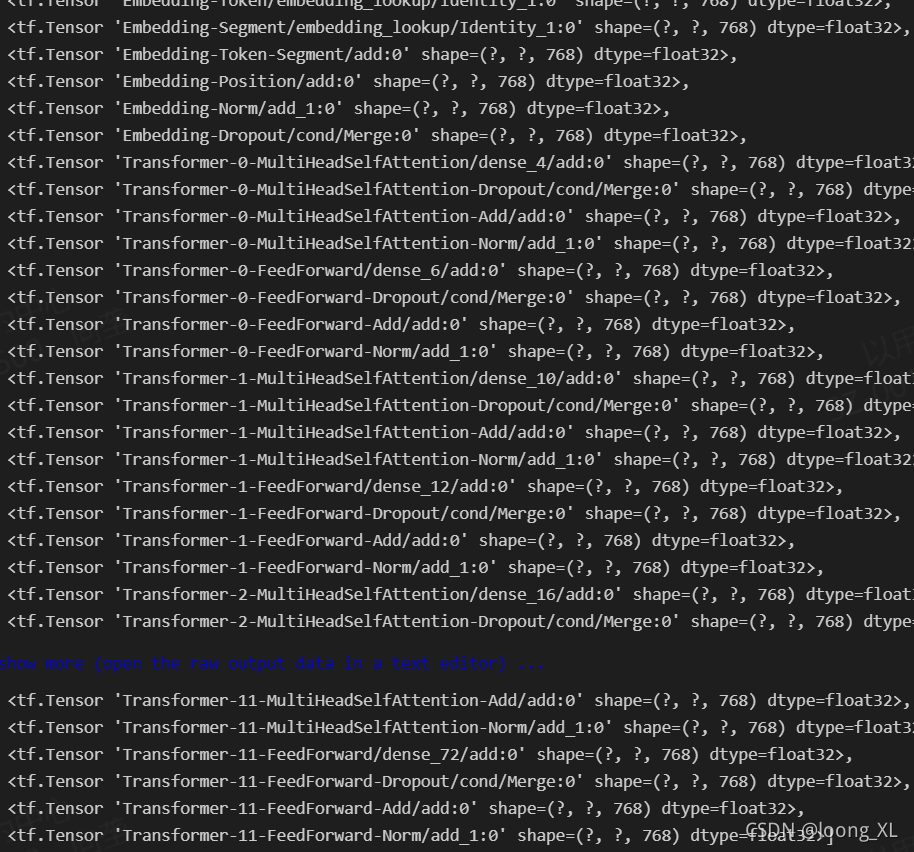
***报错:InvalidArgumentError: Input-Segment:0 is both fed and fetched.
解决:[layer.output for layer in model.layers][2:] 从2开始截取
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = r'D:***chinese_L-12_H-768_A-12\bert_config.json'
checkpoint_path = r'D***chinese_L-12_H-768_A-12\bert_model.ckpt'
dict_path = r'D***chinese_L-12_H-768_A-12\vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
#取每一层网络向量
from keras import Model
outputs = [layer.output for layer in model.layers][2:]
model1 = Model(
inputs=model.input,
outputs=outputs
)
token_ids, segment_ids = tokenizer.encode('语言模型')
res = model1.predict([np.array([token_ids]), np.array([segment_ids])])
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = r'D:***chinese_L-12_H-768_A-12\bert_config.json'
checkpoint_path = r'D***chinese_L-12_H-768_A-12\bert_model.ckpt'
dict_path = r'D***chinese_L-12_H-768_A-12\vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
# 模型参数,取最后一层网络向量
last_layer = 'Transformer-%s-FeedForward-Norm' % (model.num_hidden_layers - 1)
from keras import Model
output = model.model.get_layer(last_layer).output
model1 = Model(
inputs=model.input,
outputs=outputs
)
token_ids, segment_ids = tokenizer.encode('语言模型')
res = model1.predict([np.array([token_ids]), np.array([segment_ids])])