9.JUC
Semaphore
为什么需要用到Semaphore?
限流
Sdmaphore的场景?
秒杀商品的时候,不能够让那些没有秒杀成功的线程进入,只有占了坑位的才可以使用,这里可以用redis来记录这个Semaphre
Semaphore的原理?
AQS+state进行分析
定义
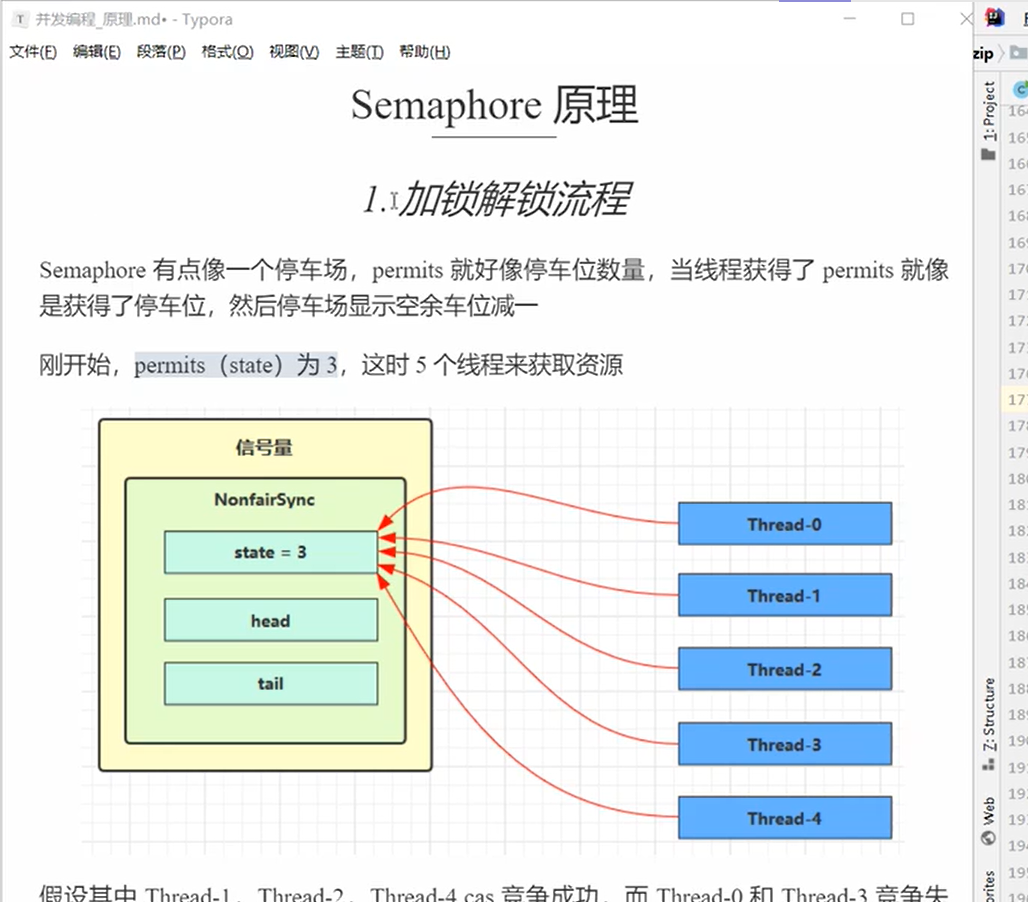
信号量,相当于就是停车位限制流量。
- acquire:拿到位置
- release:释放位置
@Slf4j(topic = "c.test")
public class MyTestSemaphore {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for(int i=0;i<10;i++){
new Thread(()->{
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("running");
Sleeper.sleep(1);
log.debug("end");
semaphore.release();
}).start();
}
}
}
原理
其实都是AQS的原理
acquire
- acquire调用了sync(nonfairSync)的acquireSharedInterruptibly(1);尝试上锁tryAcquireShared(arg)
- 调用nonfairTryAcquireShared(int acquires),每次都是-1,直到信号量小于1的时候(相当于就是AQS的state==0的时候)直接返回这个remaining。
- 如果得到返回值是<0,那么就把对应线程送进阻塞队列。基本和lock操作一样。
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -2694183684443567898L;
NonfairSync(int permits) {
super(permits);
}
//尝试获取锁
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
//非公平获取锁
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;//直接就是-1
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
release
- release->调用releaseShare(包括了tryReleaseShared和doReleaseShared)
- 处理逻辑相似,但是tryReleaseShared是把state+1而不是-1,原因就是信号量的state的意思是有多少坑位可以使用,也就是只要有坑位,那么线程就能获取锁。(代码非常简洁)
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
int next = current + releases;//坑位+1《释放了一个
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}

总结:acquire调用acquireSharedInterruptibly(可被中断)。然后就是模板tryAcquireShare和doAcquireSharedInterruptibly(和doAcquire差不多的逻辑,但是多了一个唤醒共享setHeadAndProgation)锁的方法(读锁)。
CountDownLatch
为什么需要用到CountDownLatch?
应用场景:一个线程需要等待多个线程结果的时候。或者需要等待其它线程运行完之后
定义
他就是一个倒计时锁,await之后需要等待countDown到0的时候才会解锁。
@Slf4j(topic = "c.test")
public class TestCountDownLock {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(3);
new Thread(()->{
log.debug("begin1");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t1").start();
new Thread(()->{
log.debug("begin2");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t2").start();
new Thread(()->{
log.debug("begin3");
Sleeper.sleep(2);
log.debug("end3");
countDownLatch.countDown();
},"t3").start();
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("结束");
}
}
join同样可以完成功能,但是万一线程阻塞了,那么就会导致最后的join一直处于等待,需要进行特殊的处理。但是CountDownLatch能够进行倒计时,只要倒计时结束,那么就会结束主线程的阻塞
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(4);
CountDownLatch countDownLatch=new CountDownLatch(3);
service.submit(()->{
log.debug("begin1");
Sleeper.sleep(1);
log.debug("end1");
countDownLatch.countDown();
},"t1");
service.submit(()->{
log.debug("begin2");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t2");
service.submit(()->{
log.debug("begin3");
Sleeper.sleep(1);
log.debug("end3");
countDownLatch.countDown();
},"t3");
service.submit(()->{
log.debug("await");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("解锁");
},"t4");
}
游戏案例
为什么加载的时候需要使用到countDownLock?
原因就是多方面,多文件需要加载,需要全部文件和配置初始化之后才能够进行开始,所以可以使用CountDown来记录最终需要等待的文件以及线程数。在谷粒商城的获取商品信息、快递信息的时候都会用到这种方式来提高访问的速度,并发执行,并且通过countDown来记录要执行完任务的个数才能够继续往下面执行。也可以使用join或者是future的getAll来进行阻塞。
public static void test6(){
String[] a=new String[10];
Random random = new Random();
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch=new CountDownLatch(10);
for(int j=0;j<10;j++){
int k=j;
service.submit(()->{
for(int i=0;i<=100;i++){
try {
Thread.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
a[k]=i+"%";
System.out.print("\r"+Arrays.toString(a));
}
countDownLatch.countDown();
},"t"+j);
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("游戏开始");
}
商品问题如果并发执行完且获取结果再继续执行?
还是需要future的get处理。没有结果通常使用countdownlatch
那么CountDownLatch有什么问题?
问题就是它不能够重置countdown的数量,也就是多次循环的话每次都要new一个,而不能够重用对象。
解决办法就是CyclicBarrier,能够重用,而且可以执行最终的方法。
线程数有什么要求?
必须和循环任务数相同,不然就会多个任务被线程开启。假设3线程,3次循环,两个任务,那么就会取出第一次,第二次任务执行,还会取出循环的下一次任务执行。因为线程多。
@Slf4j(topic = "c.test")
public class TestCycleBarrier1 {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(2,()->{
log.debug("结束");
});
ExecutorService service = Executors.newFixedThreadPool(2);
for(int i=0;i<3;i++){
service.submit(()->{
log.debug("开始....");
Sleeper.sleep(1);
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},"t1");
service.submit(()->{
log.debug("开始....");
Sleeper.sleep(2);
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},"t1");
}
}
}
10.线程安全类
分类
有什么分类?
blocking:阻塞+锁
copyAndWrite:拷贝方式保证安全,但是代价太大
Concurrent:并发CAS来进行修改,fast-fail一旦修改立刻停止,fast-still修改仍然遍历,有弱一致性(数据是脏的)。
HashTable和Vector是以前的安全类,方法上加锁,还有一个修饰synchronizedMap这个是把map放进去之后加锁,调用的仍然是map的方法。
ConcurrentMap就能保证原子性了吗?
很明显就是不能,原因map内部安全的源码实际上就是拿出了map的一行出来锁住,但是问题就是仅仅只是一个方法的时候是可以保证线程安全, 两个的话那么完全就是不行。比如两个线程computeIfAbsent同时computeIfAbsent,都是获取到同一个值,最后put以最后修改的为主。
那么怎么把getvaqlue修改value变成一个原子操作?
可以通过computeIfAbsent,相当于就是直接取出那一行锁住一行,并且如果没有这个key就会新创建一个,然后再通过累加器LongAdder来完成原子累加。那么为什么不能put?很简单同一个map两个方法交错就会出现线程安全的问题。但是LongAdder和map已经分开,那么就算交错了,也需要获取到锁的时候才能够对value进行修改。而且Longadder是get和put基本上是一个原子操作CAS。
(map, words) -> {
for (String word : words) {
// 如果缺少一个 key,则计算生成一个 value , 然后将 key value 放入 map
// a 0
LongAdder value = map.computeIfAbsent(word, (key) -> new LongAdder());
// 执行累加
value.increment(); // 2
/*// 检查 key 有没有
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
// 没有 则 put
map.put(word, newValue);*/
}
}
源码部分
//computeIfAbsent部分
Node<K,V> r = new ReservationNode<K,V>();//取出一行
synchronized (r) {
//锁上
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K,V> node = null;
try {
if ((val = mappingFunction.apply(key)) != null)//null就创建
node = new Node<K,V>(h, key, val, null);
} finally {
setTabAt(tab, i, node);
}
}
}
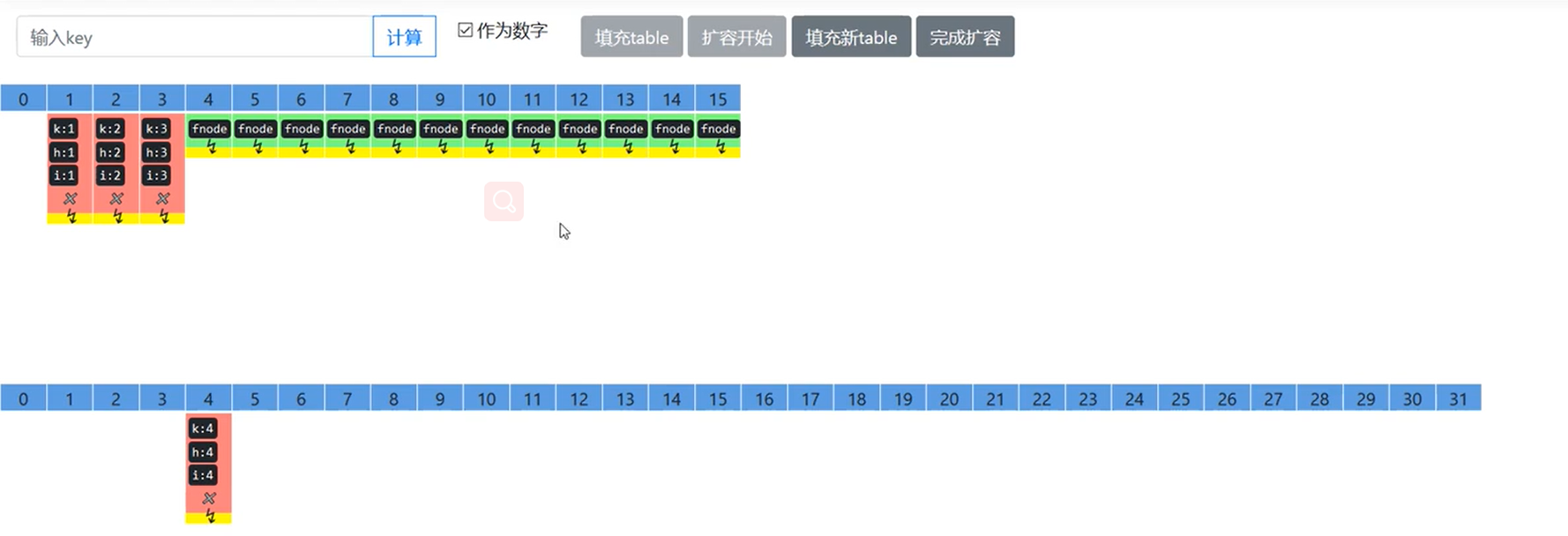
Hashmap并发死链
为什么会造成并发死链?
(只有jdk7下面才会出现,why?)
因为每次数据数据数量到达容量的3/4的时候,那么这个时候出现拉链情况的次数就会越来越多,导致比较次数增加,查找速度减慢,就会进行扩容,分散数据到各个位置。桶下标会重新进行计算。
案例的意思其实就就是扩容的时候16去了别地方,而且1和35的位置发生了变化。导致第二个同时进来扩容的线程无法正确转移。
- 第一个线程和第二个线程都是,现在第一个线程执行扩容,e是1->35>16 ->null,e.next是35->16->null扩容之后16走了,而且1先进新的数组,35后进,因为e是一个引用,e一直指向的都是1节点,但是节点1变成了1->null而不是1->35->16。所以e现在指向的是是1->null,e.next很自然就是35->1->null,切换到线程2就会死链,为什么会这样?
- 原因就是把1送到新链之后,接着下一个e赋值35,35节点后面的next还是1,相当于就是1和35反复交换位置。

JDK8版本ConcurrentHashMap重要源码
属性分析
- sizeCtl下一次扩容的阈值,初始是-1,扩容为-(1+线程数)
- Node:链表节点
- TreeNode:红黑树节点
- TreeBin:红黑树节点头,防止hash攻击
- ForwardingNode:表示节点已经被迁移到新的数组
- table:数组
- nextTable:迁移的新数组
重要方法
- tabAt:获取某个节点
- casTabAt:CAS方式修改节点的值
- setTableAt:直接修改

构造方法
- 懒惰式初始化,就算是计算了size,但是不用到那么也还是不会进行对数组的初始化
- 而且size的计算是initalCapacity(初始化容量)/loadFacor(负载因子)。但是最后还是会通过tableSizeFor(size)来把size改成2^n。并且不能超过最大的容量
- 容量必须>=并发度。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) //容量必须大于等于并发度 ,不然就需要修改
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);//计算实际容量大小,因为初始化容量必须只能占3/4或者是loadFactor
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);//计算最后的容量
this.sizeCtl = cap;
}
get
- 首先就是重新计算传过来的key的hash为正整数(因为要在数组上遍历)spread
- 接着就是如果table不是空,那么就取出对应h与n-1相与下标的节点(保证不超过n-1,二进制分析),接着对比节点hash是不是等于key计算出来的那个,如果是那么就再次比较key是不是和节点相等,如果是那么就返回val。(获取新h(hash),取出节点,对比节点的hash(数组同一个位置的h相同,因为计算的h就是数组的下标,也叫作数组的hash),然后对比key是不是相同)
- 如果key也不相同那么查看是不是ForwardingNode(不能访问,只能去新数组nextTable中访问),或者是Treebin
- 最后如果都不是那么说明节点可能在链表中,再次遍历链表。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());//key的hash取正整数(数组下标)
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//取出节点
if ((eh = e.hash) == h) {
//判断取出节点的hash是不是和h相同
if ((ek = e.key) == key || (ek != null && key.equals(ek)))//对比key成功返回
return e.val;
}
else if (eh < 0)//如果是负数,可能就是fnode或者是treebin
return (p = e.find(h, key)) != null ? p.val : null;//去到对应位置查找
while ((e = e.next) != null) {
//如果都不是那么就遍历链表看看在不在下面
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put
- onlyIfAbsent是表示要不要覆盖写新值,false就是要new一个新的
- ConcurrentHashMap的key和value都不能为空
- 计算数组hash值,然后看看table存不存在,如果不存在那么就调用initTable。如果存在那么就取出数组的hash位置节点
- 取出的第一个节点是头结点,如果是空的,那么就new一个,并且赋值
- 如果头结点不是null,且节点是一个正在迁移的节点,那么线程就会调用helpTranfer来帮助正在迁移的线程迁移点。
- 如果头节点不是空,那么就上锁(锁就是头结点本身),然后再次取出头结点,看看头结点有没有被其它线程修改
- 然后就是for循环遍历链表对比key和hash,如果有那么就CAS更新节点,如果没有那么就new一个节点放到链表尾
- 如果头结点是红黑树节点,那么就去查询红黑树。
- 如果节点数量大于8那么就构建红黑树
- 最后就是addCount与容量相关
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();//key和value不能为空
int hash = spread(key.hashCode());//计算正整数hash(数组下标)
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
//进入无限循环
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)//如果是null那么就初始化table
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//取出头结点,如果是null
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))//CAS创建头结点
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//如果是forwardingNode,那么线程帮助其他线程去转移节点,帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
//锁上当前行
if (tabAt(tab, i) == f) {
//再次取出数组的节点看看有没有被改变。
if (fh >= 0) {
//如果fh是正数说明是链表里面的
binCount = 1;//记录节点个数
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
//如果key和hash相同那么赋值新值。
oldVal = e.val;
if (!onlyIfAbsent)//如果是onlyIfAbsent=false直接覆盖旧值
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//如果找不到那么就接到后面去。
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
//如果是红黑树节点,那么就遍历红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//如果binCount>=8那么就进行树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
initTable初始化table
- 从第二个判断开始说,先把sizeCtl修改为-1,告诉其他线程正在创建表
- 再次判断表是不是空的,如果是空的,那么就创建表,并且设置好下次扩容的阈值交给sizeCtl
- 第一次判断的意思是如果还有其他线程想要进来,那么发现乐观锁(U.compareAndSwapInt(this, SIZECTL, sc, -1)已经被使用了,那么就进入下一次循环,发现sizeCtl是-1也就是有线程正在创建表,那么就yield放弃cpu使用权相当于就进入阻塞,下一次苏醒进入创建的时候发现这个时候table已经不是null了,再次回到循环,然后回到while循环的时候结束。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//防止多个线程进来创建表。所以在第一个线程创建之后,其它线程都会判断table是不是空,如果不是那么就去到while结束循环
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//如果sc旧值不是-1那么就直接使用原来的sizeCtl,如果是-1那么就使用默认的容量
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);//超过阈值扩容的阈值
}
} finally {
sizeCtl = sc;//阈值赋值给sizeCtl
}
break;
}
}
return tab;
}
addCount
作用是什么?就是给hashMap的baseCount+1。并且检查是否需要扩容
为什么会有竞争?因为put方法里面是以节点为单位的上锁,也就是每次锁住一行提高锁的粒度,并且增加并发度
- 首先判断就是cells是否存在,cell是否存在,如果其中一个不存在都要调用fullAddCount来创建
- 如果存在,且发现有竞争,那么直接修改cellValue相当于就是通过cells数组来组合计算最后的cell值。因为这个时候可能会有很多线程同时想要修改对应的baseCount,那么就可以先计算到一个cell里最后再汇总。(知识来源LongAdder的累加处理)
- 如果没有竞争可以直接修改baseCount的值。
- 接着就是s=sumCount()计算节点有多少个,如果发现节点大于阈值那么就会进行扩容操作,并且把sizeCtl设置为负数,然后transger来创建新数组扩容。其它线程进入发现sizeCtl是负数那么就帮助扩容。
拓展
compareAndSwapLong(a,b,c,d)
a:对象
b:对象的偏移值,也就是属性的位置,比如Long里面的long x属性的位置
c:旧值
d:想要赋予的值
基本上可以在c中看出来偏移的位置的属性,比如U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)中第三个参数就是baseCount,那么我们修改的就是baseCount的值
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||//发现有竞争那么就要通过Cells来计算baseCount
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
//没有竞争直接加给当前对象的baseCount的偏移值,也就是对象的size的位置
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||//如果发现cells是空的那么就要创建
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||//如果发现节点是空那么就创建cell
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
//如果都有那么就直接赋值给cellvalue这里的cellvalue是a里面的偏移值,因为a是个Long类。相当于就是其中一个cell
fullAddCount(x, uncontended);//创建cells和cell
return;
}
if (check <= 1)
return;
s = sumCount();//计算节点个数
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&//如果大于阈值那么就要进行扩容
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
//如果线程发现其它线程正在扩容那么就帮助扩容
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,//设置sizeCtl为负数也就是扩容或者创建状态
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);//进行扩容转移。
s = sumCount();
}
}
}
size
- 这里就可以size调用的是sumCount
- 而且sumCount()调用的是baseCount,然后进行累加的操作。
- 但它并不是一个精确的值,在多线程下可能有线程减,有线程增加节点。
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
trantsfer
作用?扩容转移节点
- 首先就是创建扩容数组*2
- 然后就是遍历数组,如果发现tab节点是null说明处理完,那么就设置为forwardingNode也就是迁移节点标签
- 如果本来就是forwardingnode那么就跳过下面的锁定头结点f执行迁移
- 锁定
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) {
// initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//扩容数组
nextTab = nt;
} catch (Throwable ex) {
// try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
//遍历数组,进行处理。
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)//如果头结点处理完,那么就把原来的节点设置为forWardingNode
advance = casTabAt(tab, i, null, fwd);//fwd就是forWardingNode
else if ((fh = f.hash) == MOVED)//如果是forwarding那么就跳过
advance = true; // already processed
else {
synchronized (f) {
//锁定首节点进行转移处理
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
//如果是普通节点那么就扩容
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
//红黑树节点处理转移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
JDK7版本
初始化
- 第一个就是Segment存储着HashEntry也就是一个键值对,而且每次都会先初始化Segment。占用很大的内存。
- 然后segmentShift和segmentMask的作用是什么?其实就是shift用来记录要hash右移的位数,mask就像是子网掩码那样与hash右移之后的高位进行相与,得到的那个值就是数组segment上面的下标。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;//hash高位保留多少位
int ssize = 1;//数组大小
while (ssize < concurrencyLevel) {
//初始化大小是16
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;//hash右移多少位
this.segmentMask = ssize - 1;//对应多少个hash的高位
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}

put
和JDK8有什么不同?这里加锁使用的是Segment,因为segment就是ReentrantLock。而且锁里面就是小哈希表,可以通过hash在数组中找到节点。问题是segment和hashEntry使用同一个Entry?很明显不是,segment使用的是hash右移segmentShift位然后与segmentMask进行相与得到的位置,但是小hash表使用的是直接hash。
- 调用的是segment内部的put操作放进小hash
- 然后segment调用tryLock尝试锁住并且修改小hash。并且只会尝试64次,失败就进行阻塞,期间会创建新节点
- lock成功之后就会获取table和对应的头结点,并且对比key和hash看看是不是对应的节点,如果是那么就设置新值
- 如果不是那么就继续循环下去访问下一个节点,并且对比设置
- 如果访问到最后发现没有,那么就看看tryLock期间有没有创建节点,如果有那么node.next=first相当于就是连接上链表头部,没有就自己创建连接到头部
- 然后检查节点个数是不是大于阈值如果是那么就进行扩容rehash
- 最后就是解锁
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;//求segment的位置
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);//调用segment的put方法设置key和value
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null ://尝试加锁
scanAndLockForPut(key, hash, value);//失败还可以尝试64次并且创建要加入的节点
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//求小hash表对应的下标
HashEntry<K,V> first = entryAt(tab, index);//取出该节点
for (HashEntry<K,V> e = first;;) {
//遍历链表
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
//对比hash和key
oldValue = e.value;//赋值新值
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//如果链表没有,那么就创建新节点加入
if (node != null)//在tryLock期间创建
node.setNext(first);//直接加入
else//没有创建那么就创建节点
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)//如果大于阈值那么就要扩容
rehash(node);
else
setEntryAt(tab, index, node);//修改头结点为新的节点
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//解锁
unlock();
}
return oldValue;
}
rehash
- 这里扩容并不是直接搬运节点,先遍历数组
- 然后得到头结点,如果没有下一个节点那么就直接搬运
- 如果那么就要遍历下面的节点,然后找到那些hash已经发生变化的最后有一个节点,然后把这个节点搬运到lastIdx的位置上。其它节点根据hash创建新节点搬运到其它位置,把链表拆散。那么为什么计算出来的k是不同的呢?原因是扩容之后二进制+1,那么相当于就是2->4从10到11那么hash&size是不是也就发生了改变。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;//扩容操作
threshold = (int)(newCapacity * loadFactor);//重新计算阈值
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
//遍历旧table
HashEntry<K,V> e = oldTable[i];
if (e != null) {
//如果节点不是null,那么进行迁移
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask ;
if (next == null) //如果节点的下一个节点是空的,那么可以直接搬运
newTable[idx] = e;
else {
// 如果有多个节点,就要判断哪些节点的hash值发生了改变
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
//如果下标发生改变,那么就记录下来
lastIdx = k;//记录最后改变的那个节点的值
lastRun = last;//记录最后一个节点
}
}
newTable[lastIdx] = lastRun;//把最后改变的节点赋值给新表的同一个位置,说明剩下来的这些节点的hash没有发生改变
// Clone remaining nodes
//创建数组新的位置来保存不同的节点
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; //扩容之后加入新的节点
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
那么什么时候加入新节点?
扩容之后.
get
和jdk8的异同?都是没有加锁,但是遍历方式不同。先找到锁,然后再找到锁的table,最后计算出hash找到table中的节点,取出并且遍历链表找到对应节点。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&//取出segment,使用unsafe方法保证可见性
(tab = s.table) != null) {
//取出table
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);//取出节点并且进行遍历
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;//如果有对应的key那么就返回
}
}
return null;
}
size
和jdk8的不同?jdk8使用的是cells方式来进行的累加保证弱一致性。jdk7是使用的多次循环,2次之内如果结果相同那么就返回,否则继续遍历,超过遍历三次之后加锁之后再进行元素大小计算。
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
//如果超过3次加锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
//遍历segment获取count和modCount修改次数
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
//如果sum等于前一个值那么就结束相当于两次结果相同
if (sum == last)
break;
last = sum;//记录当前sum
}
} finally {
//解锁
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
LinkedBlockingQueue
入队
- 直接就是last=last.next=node,意思就是连接新节点,然后last指向新节点
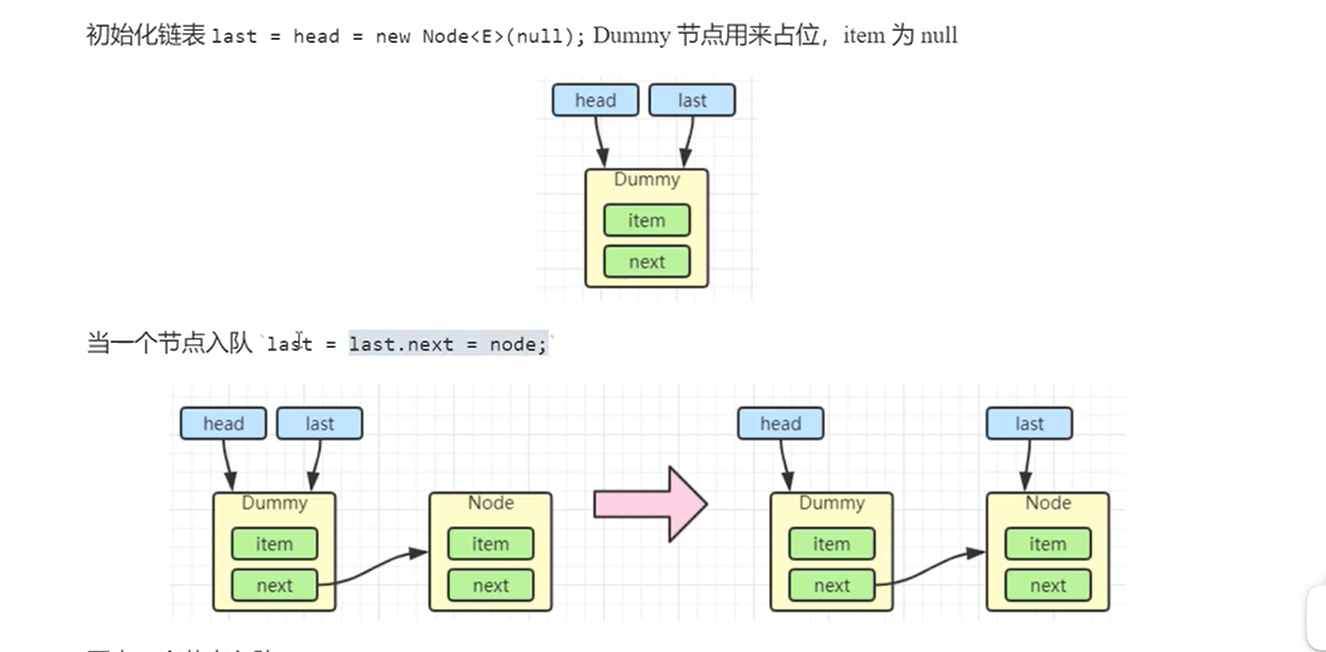
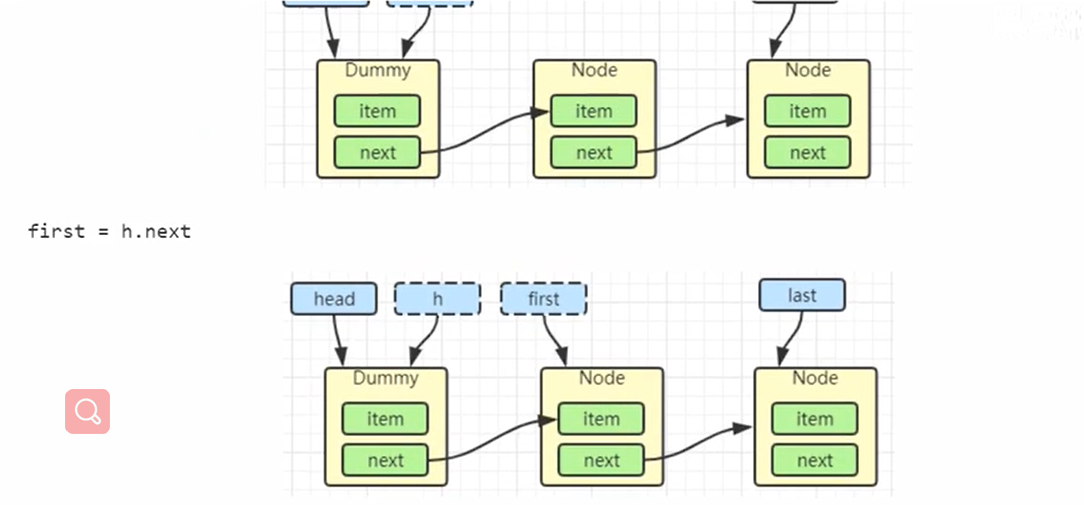
出队
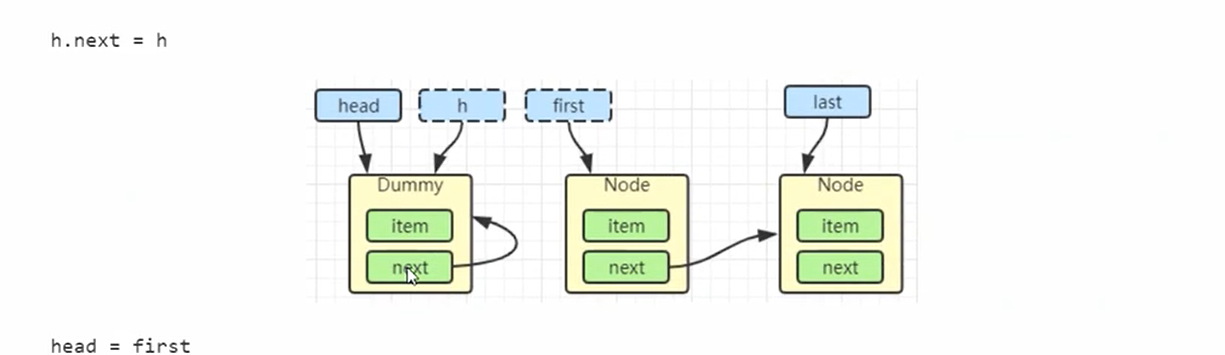
- 先是h临时指向head,然后first=h.next指向下一个节点
- 然后就是h.next=h指向自己方便垃圾回收
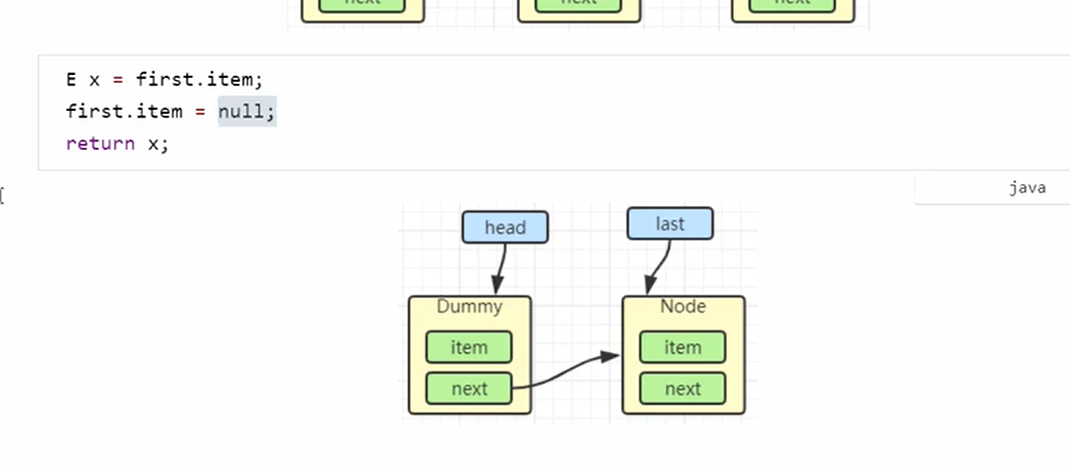
- 然后head=first相当于就是重新设置头结点
- 然后head的item设置为为空,因为head是一个占位点

好处在哪?
- 使用了两把锁一个占位节点
- 生产者一把,消费者一把保证两个不同操作的并发度高
- 而且只有两个节点的时候或者是大于两个节点的时候,putLock保护last节点,takeLock保护head节点,主要就是防止put和take这些操作的并发性问题。
- 只有一个节点的时候take会被阻塞
阻塞队列会出现什么并发性问题?
如果队列只剩下一个位置的时候刚好两个线程通过判断,那么就会导致溢出或者是取不出的问题。
put
- 不能加入空节点
- 如果满了就阻塞
- 如果消费品小于容量最大值的时候就唤醒一个生产者,如果还有空位可以生产,那么就唤醒生产者
- 如果是只有一个消费品的时候那么就是唤醒消费者线程
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
take
分析一样,基本上
- 当没有消费品的时候阻塞
- 当消费品大于1的时候继续唤醒消费者,也就是如果还有消费品那么就唤醒消费者
- 当消费品到达容量的时候唤醒生产者
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
总结:消费者叫醒自己的队列,生产者也是。每次只叫醒一个,防止竞争的消耗。而且只要生产满了,那么就会阻塞。用完了阻塞消费者。但是总有一边会有一个生产者或者是消费者
Linked和Array的比较
链表 数组
有界限 强制有界限
懒惰 初始化好了
每次需要new节点 需要提前初始化节点
2把锁 1把
dummy的好处?
可以让两把锁锁住不同对象防止竞争
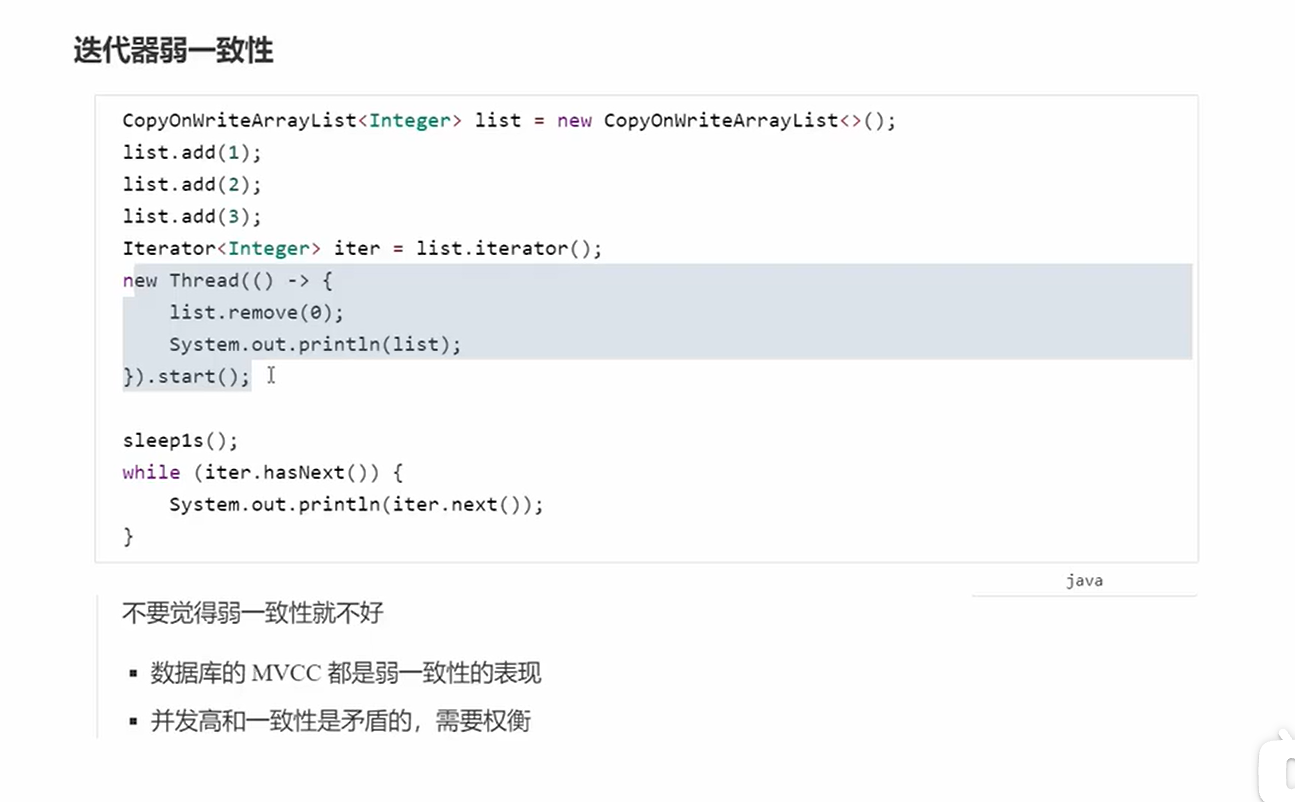
CopyOnWriteArrayList
原理
其实就是每次写的时候都copy一份新的在新的上面改变,然后赋值给当前。
put的问题是什么?
如果这个时候有读线程get,但是切换到写线程把旧的给换成新的数组,那么get就会获取到错误的数据
get并不会加锁。但是写的时候就会加锁。而且写能和读一起进行。实现了弱一致性。